
使用veth和bridge模拟容器网络
随着虚拟化技术、容器化技术的发展,我们在工作中会使用到虚拟化网络技术。简单来说,以往的网卡、交换机、路由器,当前可以通过操作系统使用程序来进行模拟。
通常使用最为广泛的是下面的虚拟设备:
| veth | 一对相互连接的网卡,常用于连接两个namespace |
| bridge | 相当于一个二层交换机,如果配置了ip地址,则是一个三层交换机 |
| tun/tap | 虚拟网卡,常用于实现vpn |
在本文搭建容器网络的过程中,主要使用到了veth和bridge。下面将介绍这两种虚拟设备。
veth和brdige
veth
veth pair 全称是 Virtual Ethernet Pair,是一个成对的端口,所有从这对端口一 端进入的数据包都将从另一端出来,反之也是一样。
引入 veth pair 是为了在不同的 Network Namespace 直接进行通信,利用它可以直接将两个 Network Namespace 连接起来。
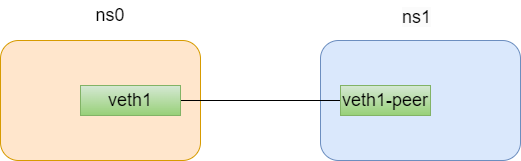
使用下面的命令可以创建一个veth pair。
ip link add <p1-name> type veth peer name <p2-name>
bridge
veth pair 打破了 Network Namespace 的限制,实现了不同 Network Namespace 之间的通信。但 veth pair 有一个明显的缺陷,就是只能实现两个网络接口之间的通信。
如果我们想实现多个网络接口之间的通信,就可以使用下面介绍的网桥(Bridge)技术。
简单来说,网桥就是把一台机器上的若干个网络接口 “连接” 起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。
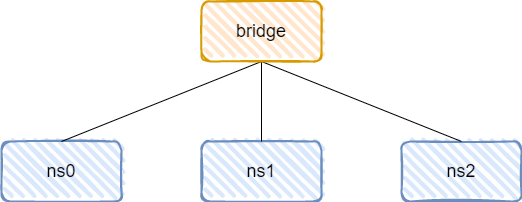
实践
在本文中,将创建三个Network namespace,使得这三个namesapce可以实现:
- 1.ping通其它namespace
- 2.ping通主机
- 3.ping通外网
如果把容器想象成真实的机器,则其网络拓扑图可能是下面这样的:
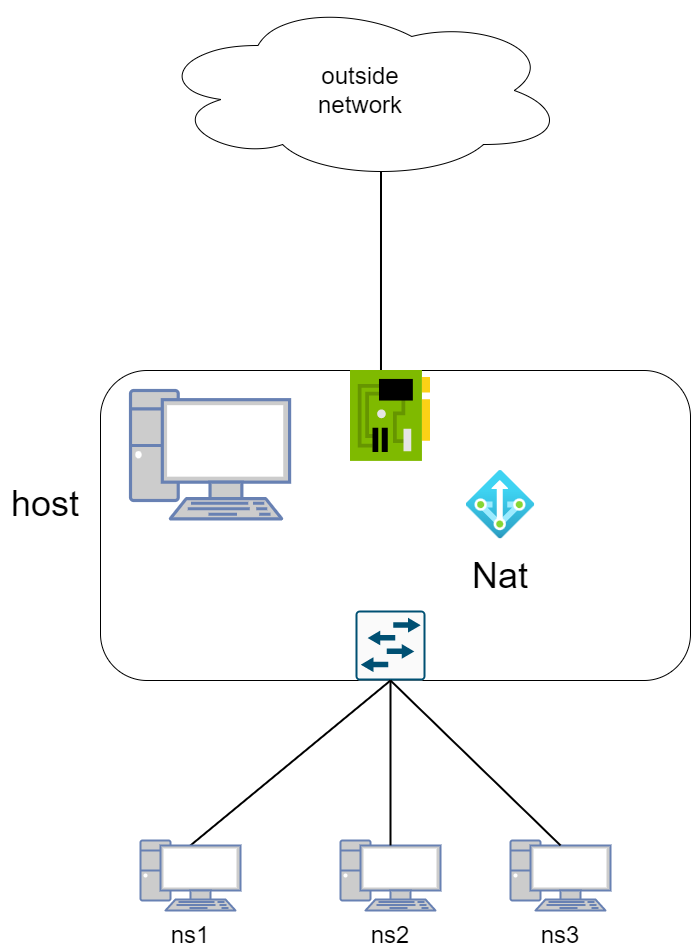
下面便一步一步的去实现。
步骤1:创建三个network namespace
linux中的ip命令可以对network namespace进行操作, 例如使用下面的命令就可以创建一个名叫test的network namespace。
ip netns add <ns>
使用下面的命令可以用于查看已经创建的network namespace。
ip netns ls
有了上述基础,我们分别创建red/blue/green三个network namespace。
ip netns add ns1
ip netns add ns2
ip netns add ns3
ip netns ls查看namespace
[root@localhost ~]# ip netns ls
ns3
ns2
ns1
每个ns都和主机网络一样,有自己的网卡,路由表,ARP表, iptabls等等。
可以使用下面的命令查看ns内部的信息
ip netns exec <namespace> <command>
下面使用下面的命令查看我们刚刚创建的ns1空间的路由表,网卡和arp缓存。
# ns1 中的路由表
[root@localhost ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
#ns1 中的网卡, 目前只有lo
[root@localhost ~]# ip netns exec ns1 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
#ns1 中的arp缓存
[root@localhost ~]# ip netns exec ns1 arp
step2:创建虚拟交换机
由于我们需要将3个namespace互相连接,因此我们需要使用bridge进行连接。
使用下面的命令可以创建一个虚拟交换机。虽然它的type是bridge,但其实是一个二层交换机。当然如果为其添加ip地址,那么其就是一个三层交换机。这里我们暂时不用设置ip地址,当后面实现和主机进行通讯时,再配置。
创建完毕之后,顺便启动该设备。
ip link add vbridge type bridge
ip link set dev vbridge up
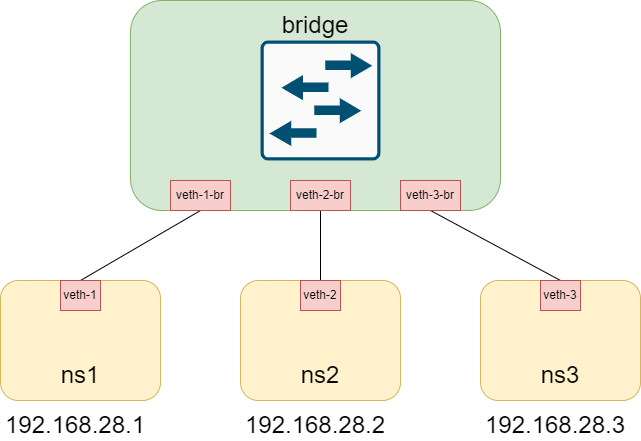
接下来要做的是将3个namespace都接入到该vbrdige中。因此我们需要创建3个veth pair。 这里的命令同样是ip link add, 只不过设备的type是veth。
这里需要注意的是, Linux内核对网络接口的名字长度有限制,不能超过15个字符。
ip link add veth-1 type veth peer name veth-1-br
ip link add veth-2 type veth peer name veth-2-br
ip link add veth-3 type veth peer name veth-3-br
有了这些veth-pair,下面要做的是将其安装在合适的地方。
- 将veth-1连接到namespace ns1, 另一端veth-1-br连接到vbridge
- 将veth-2连接到namespace ns2, 另一端veth-2-br连接到vbridge
- 将veth-3连接到namespace ns3, 另一端veth-3-br连接到vbridge
ip link set veth-1 netns ns1
ip link set veth-1-br master vbridge
ip link set veth-2 netns ns2
ip link set veth-2-br master vbridge
ip link set veth-3 netns ns3
ip link set veth-3-br master vbridge
使用bridge link可以查看目前vbridge上所连接的设备。
[root@localhost ~]# bridge link
11: veth-1-br@if12: <BROADCAST,MULTICAST> mtu 1500 master vbridge state disabled priority 32 cost 2
13: veth-2-br@if14: <BROADCAST,MULTICAST> mtu 1500 master vbridge state disabled priority 32 cost 2
15: veth-3-br@if16: <BROADCAST,MULTICAST> mtu 1500 master vbridge state disabled priority 32 cost 2
下面我们需要给veth-1,veth-2,veth-3添加ip地址,ip需要在同一个网段内。
ip netns exec ns1 ip addr add 192.168.28.1/24 dev veth-1
ip netns exec ns2 ip addr add 192.168.28.2/24 dev veth-2
ip netns exec ns3 ip addr add 192.168.28.3/24 dev veth-3
接下来就是将veth启动。
ip netns exec ns1 ip link set veth-1 up
ip link set dev veth-1-br up
ip netns exec ns2 ip link set veth-2 up
ip link set dev veth-2-br up
ip netns exec ns3 ip link set veth-3 up
ip link set dev veth-3-br up
这一些系列操作之后,三个namespace就已经都过vbridge互联在了一起,可以通过ping命令来测试三个namepsace的连通性。
ip netns exec ns1 ping 192.168.28.2
ip netns exec ns1 ping 192.168.28.3
ip netns exec ns2 ping 192.168.28.3
ip netns exec ns2 ping 192.168.28.3
ip netns exec ns3 ping 192.168.28.1
ip netns exec ns3 ping 192.168.28.2
这里是ns1去ping 192.168.28.2的结果,可以看到可以ping通。
ip netns exec ns1 ping 192.168.28.2
[root@localhost ~]# ip netns exec ns1 ping 192.168.28.2
PING 192.168.28.2 (192.168.28.2) 56(84) bytes of data.
64 bytes from 192.168.28.2: icmp_seq=1 ttl=64 time=0.059 ms
64 bytes from 192.168.28.2: icmp_seq=2 ttl=64 time=0.056 ms
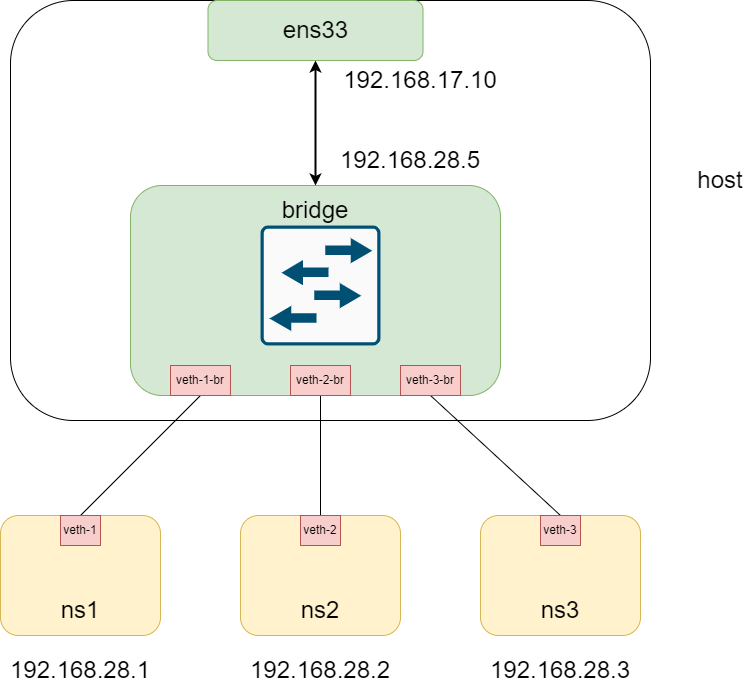
到这里为止,我们完成了下面的拓扑图。已经实现了容器之间的相互访问。接下来,我们将实现容器和主机网络的相互访问。
step3: 实现可以和主机之间通讯
首先尝试在ns1的namespace下直接ping主机,例如我的主机地址是192.168.17.10。从结果可知,目前网络是无法联通的。
[root@localhost ~]# ip netns exec ns1 ping 192.168.17.10
ping: connect: Network is unreachable
这里无法ping通,原因是容器网络和主机网络处在两个网段,因此二层设备无法实现这样的要求。于是我们需要为bridge添加ip地址。使用下面的命令为bridge添加ip地址。
ip addr add 192.168.28.5/24 dev vbridge
添加完之后,使用route -n查看本机的路由表,可以发现此时192.168.28.0已经有了路由的项,其将被发送给vbridge设备。
0.0.0.0 192.168.17.2 0.0.0.0 UG 100 0 0 ens33
192.168.17.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 vbridge
实际上,此时宿主机已经可以ping通namespace了。
[root@localhost ~]# ping 192.168.28.1
PING 192.168.28.1 (192.168.28.1) 56(84) bytes of data.
64 bytes from 192.168.28.1: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 192.168.28.1: icmp_seq=2 ttl=64 time=0.099 ms
^C
--- 192.168.28.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1026ms
rtt min/avg/max/mdev = 0.037/0.068/0.099/0.031 ms
[root@localhost ~]# ping 192.168.28.2
PING 192.168.28.2 (192.168.28.2) 56(84) bytes of data.
64 bytes from 192.168.28.2: icmp_seq=1 ttl=64 time=0.047 ms
64 bytes from 192.168.28.2: icmp_seq=2 ttl=64 time=0.057 ms
^C
--- 192.168.28.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1008ms
rtt min/avg/max/mdev = 0.047/0.052/0.057/0.005 ms
[root@localhost ~]# ping 192.168.28.3
PING 192.168.28.3 (192.168.28.3) 56(84) bytes of data.
64 bytes from 192.168.28.3: icmp_seq=1 ttl=64 time=0.094 ms
64 bytes from 192.168.28.3: icmp_seq=2 ttl=64 time=0.153 ms
^C
--- 192.168.28.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1056ms
rtt min/avg/max/mdev = 0.094/0.123/0.153/0.029 ms
不过遗憾的是namespace还不能ping通宿主机。
这是由于创建的三个ns的路由表中还没有默认路由。例如ns1中使用route -n,可以看到目前只有往192.168.28.0/24的路由表。而主机的地址无法匹配上,因此数据包无法发送。
[root@localhost ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 veth-1
下面要做的就是为3个namespace添加默认路由
ip netns exec ns1 ip route add default via 192.168.28.5
ip netns exec ns2 ip route add default via 192.168.28.5
ip netns exec ns3 ip route add default via 192.168.28.5
下面通过ping命令测试连通性,可以看到现在已经可以ping通主机地址了。
[root@localhost ~]# ip netns exec ns1 ping 192.168.17.10
PING 192.168.17.10 (192.168.17.10) 56(84) bytes of data.
64 bytes from 192.168.17.10: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 192.168.17.10: icmp_seq=2 ttl=64 time=0.105 ms
到这里为止,我们完成了下面的拓扑图。已经实现了容器之间的相互访问。
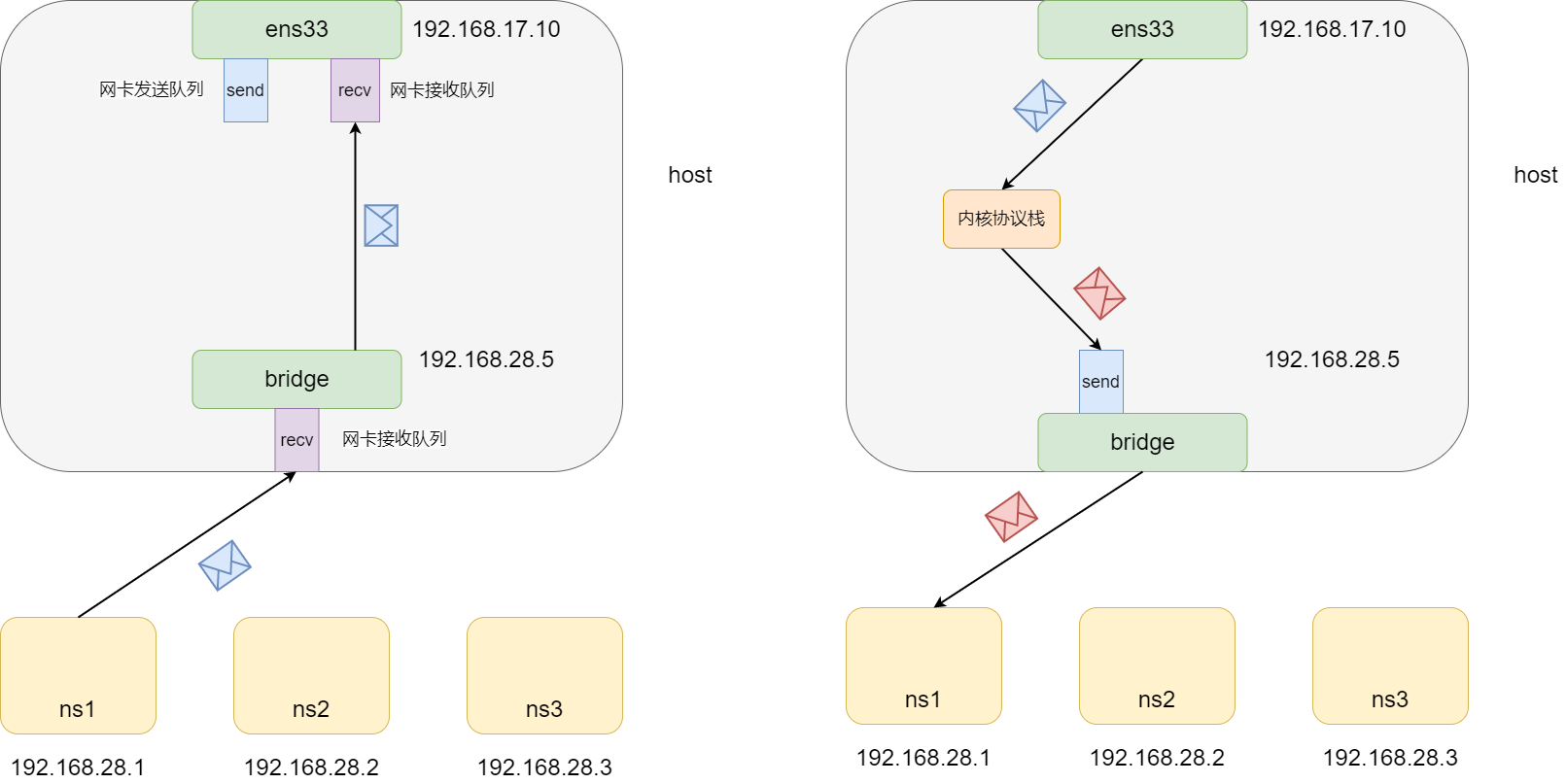
这里还有一个细节需要讨论。从ns1去ping主机时,ns1首先根据查找路由表发现目的网段匹配了默认路由,于是将数据包发送给了veth-1网卡,从而发送到了vbridge上。vbridge本身的ip地址是192.168.28.5,而目的地址是192.168.17.10,与自身不一致。那么这个时候会如何处理呢?
这里首先会判断目的地址是否是一个本机地址。如果不是,则意味着数据包需要往外部转发。这里时候就会检查ip_forward参数和本机路由表,决定是否转发和从哪个网卡转发。如果可以转发,则将数据包发送发网卡的发送队列上。
如果是目的地址是一个本机地址,则直接将数据包放置到目的地址对应的网卡的接收队列上交由内核协议栈处理。
这里主要讨论了当网卡接收到了目的地址与网卡本身ip地址不同的处理。
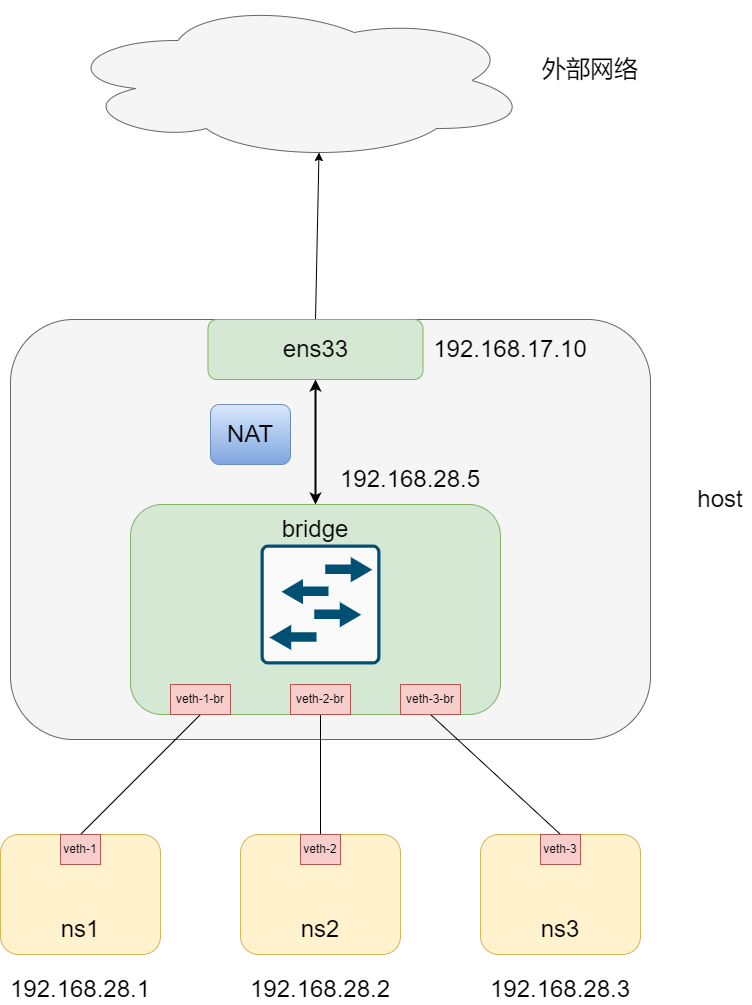
下面,为了容器可以访问外网,我们需要将主机设置成路由模式,并为其设置nat映射表。
step4: namespace实现可以和外网通讯
目前,创建的namespace还无法ping通外网,
ip netns exec ns1 ping 8.8.8.8
PING 8.8.8.8 56(84) bytes of data.
此时数据包是可以通过网卡发送出去的,但是由于数据包的源地址是一个内网地址,因此无法回数据包。
这就需要我们配置nat,使得ns可以通过主机的ip地址发送数据包。
这里首先需要开机主机的数据包转发功能。可以使用sysctl修改ip_forward的内核参数使得主机可以支持数据包转发。
sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
在这之后,通过iptables增加SNAT规则,将源ip为192.168.28.0/24内的数据包的源ip修改为ens33的ip:
$ iptables -t nat -A POSTROUTING -s 192.168.28.0/24 -j MASQUERADE
再次ping 8.8.8.8,可以看到现在已经可以ping通了。
[root@localhost ~]# ip netns exec ns1 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=175 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=127 time=175 ms
这里,宿主机已经相当于一个router, 而ens33和bridge则是router的两个接口。
至此为止,我们实现的网络拓扑图如下所示:
总结
本文通过创建network namespace,并使用veth和bridge虚拟设备构建出了容器网络的雏形,实现了下面的功能:
- ns之间可以互相访问
- ns与主机之间可以互相访问
- ns访问公网
本实验主要用于帮助理解docker网络实现的原理。
#面试#


