
二本26届大三Java实习准备 Day2
2025 年 2 月 25 日 Day 2
今日算法题
今日复习:
- java 基础
- java 集合基础
- 还复习了点并发和锁相关的知识
ConcurrentHashMap 的内容有点多明天再继续学 锁和并发的知识还是非常用要估计后面要话好几天的时间好好学习准备
语法基础
什么是反射? 他的优缺点有哪些?
反射机制可以实现在程序运行过程中动态获取类信息, 比如类中的构造方法、对象方法和成员变量等信息; 提高了代码的灵活性了; 在框架的应用场景中反射使用得比较多, 还可以实现动态代理, 但是反射依然有这一些问题, 比如反射会破坏类本身的抽象性和封装性; 还有就是反射是动态解析类对象这样就会导致不能被某些 java 虚拟机优化解析, 导致性能下降; 使用反射还会让代码的可读性下降
注解的作用是什么
注解为代码提供了性携带元数据的能力, 这些元数据不直接影响代码的执行; 他更多是作为一种标记手段, 比如在 AOP 编程中他就充当了标记哪些方法需要被增强的标志; 通过注解我们可以方便地实现很多的效果, 比如对代码的检查和约束, 比如 override 这个注解就可以在编译时期进行检查; 通过注解在框架的应用场景下还可以方便地进行配置, 比如切点表达式、定时任务中 Corn 表达式等配置就可以通过注解便捷地配置; 还有在文档生成等场景注解读大大提高了开发速度增强了代码的可读性
什么是序列化和反序列化? 如何实现?
程序运行时对象都是存储在 JVM 中的, 随着 JVM 的关闭对象也会随之被释放; 但是有时候我们需要将对象持久化的存储; 我们就可以通过将对象序列化成字节数组然后进行保存, 在需要的时候通过读取字节数组的方式放序列化成对象
要想实现序列化需要在类上实现 Serializable 接口, 然后就可以通过 ObjectInputStream 和 ObjectOutputStream 进行序列化和反序列化; 要想保证序列化和反序列化成功一个很重要的点就是类和对象中的序列化版本 ID 要一致
Java 中异常分哪两类,有什么区别?
两类分别是受检异常和非受检异常; 受检异常必须做出处理, 向上抛出或者捕获; 而非受检异常不强制处理, 如果运行时出现问题程序就会中断执行
//无异常情况
public static String getValue(){
try{
return "A";
}catch (Exception e){
return "B";
}finally {
return "C";
}
}
//有异常情况
public static String getValue(){
try{
System.out.println(1/0);
return "A";
}catch (Exception e){
return "B";
}finally {
return "C";
}
}
public static int getValue() {
int i = 1;
try {
i++;
return i;
} catch (Exception e) {
i = 66;
} finally {
i = 100;
}
return i;
}
---
static class Holder {
int value;
Holder(int v) { this.value = v; }
}
public static Holder getValue() {
Holder holder = new Holder(1);
try {
holder.value++;
return holder; // 返回对象引用
} finally {
holder.value = 100; // 修改对象属性
}
}
- 前两个的返回值都是 C, 因为 finally 中的返回值会覆盖之前的返回值; 而第方法的返回值则是 2; 第四个问题返回值则是 100, 因为返回的是对象的引用地址, 最终的值是地址上的值
介绍一下 BigDecimal
在项目中在需要高精度的地方都应该避免使用 Float 和 Double 而应该使用 BigDecimal 因为不论是 Float 还是 Double 都会出现精度丢失的问题因为他们都是近似值, 所以在涉及金额这种对精度十分敏感的数据一律使用 BigDecimal, BigDecimal 在进行运算的过程中可以很方便地指定精度和舍入规则; BigDecimal 使用的时候需要注意的是, 初始化应该避免使用 double, float 去初始化对象而应该使用字符串去初始化; 还有是在两个 BigDecimal 类型进行比较的时候应该使用 CompareTo 而不是 equal 因为 equal 出了比较大小外还会比较精度, 比如 0.1 和 0.10 使用 CompareTo 返回想等而 equal 则返回不想等
RPC 接口返回中,使用基本类型还是包装类?
应该使用包装类; 这涉及到基本数据类型和引用数据类型默认值的问题; 如果使用得是基本数据类型一个速度字段如果是 0.0 那么就无法判断他的速度本身是 0.0 还是 RPC 调用没有响应该字段的值, 但是使用包装类的话如果没有值默认值则为 null 和包装类中值 0.0 是完全不同的意思不会有歧义;
什么是函数式接口?
指只有一个抽象方法的接口 (可以通过
@FunctionalInterface来检测是否为函数式接口); 一般函数式接口一般通过匿名内部类实现,, 还可以通过 lambda 函数进行进一步简化
动态代理
所谓动态代理相对的就是静态代理, 不论动态还是静态他们的目的都是为目标方法进行功能增强; 常规的静态代理, 我们需要针对特定的类编写专门的代理类, 对于代理需求很大的场景明显不够灵活从而就出现了动态代理技术; 举个简单的例子, 在每次用户登陆和登出的前后都需要进行日志的记录, 这种场景就十分适合使用动态代理来简单实现; 动态代理的实现有 JDK 和 CGLib 两种; JDK 代理要求被代理类必须实现接口, 而 CGLib 则没有要求实现了无侵入式的功能增强; 动态代理也是 AOP 面向切面编程的基础; 我们可以使用动态代理和自定义注解的方式快速效率地做功能增强
枚举的特点和好处
枚举的本质是一个不可被修改的类; 枚举类相比于常量类来说更加灵活和安全; 灵活体现在枚举类可以在类中定义方法、实现接口、重写方法等拓展操作; 并且在数据有效性检测还有线程安全、序列化等方面效率和性能都强于常量类
Java 是值传递还是引用传递?
先说结论: Java 只有值传递; 我们任务的值传递和引用传递的区别就是在方法内参数改变后会不会影响到原参数; 如果是基本数据类型传入方法中, 变量在方法中进行修改是不会影响到原变量的符合值传递; 但是如果是引用数据类型, 将一个对象传入方法, 然后在方法中对这个对象修改, 会印象原始对象, 看似应该是引用传递, 但是其实这涉及到了 JVM 底层的存储, JVM 中对象都存在堆中, 而变量存在栈中, 一个变量指向的是对象在栈中的引用; 当实参向行参进行传递的时候并不是直接传递引用地址, 而是创建一个全新的形参副本同样指向同一个对象引用地址, 这样的传递是符合值传递的, 但由于地址相同才导致出现了似乎是引用传递的现象; 我们可以对将这个形参执行其他对象, 这样就不会影响到原对象复合值传递
UUID 和 SnowFlask
UUID 由时间戳、机器 MAC 地址、还有其他随机因子组成,提供超高的无重复性保证并且去中心化,无需通过一个中心节点来分配和协调各个机器的 UUID; 但是无法保证单调性如果需要在分布式场景下实现无重复并且有序的话可以使用 SnowFlask 雪花算法, 雪花算法由时间戳+机器 ID+序列号生成保证唯一性和单调性
为什么建议自定义一个无参构造函数
一般情况下, 如果编写完成类没有任何构造方法的情况下 JDK 会自动为我们创建一个无参的构造函数; 但是如果已经存在了构造函数就不会提供无参构造; 约定俗成创建类后要创建一个无参构造;不然即有可能出现一下问题; 框架中通过反射时会因为找不到无参构造而报错; 框架兼容问题; 序列化和反序列化问题; 子类无参构造默认会调用父类无参构造如果没有则会报错还有很多其他意外之外的问题; 所以约定俗成要常见无参构造
Java 中的 static 都能用来修饰什么?
static 关键字可以用于修饰类、方法、成员变量还有代码快
- 修饰类的时候一般用于创建静态内部类, 这样定义的内部类安全性高
- 修饰成员变量一般用于定义类中常量, 这些可以通过类名和实例对象直接引用他们共享的是同一份; 这些变量是在类被记载时就被创建的
- 修饰方法, 这些方法只能使用静态成员变量, 且不能被重写
- 静态代码块的执行时机是当类被加载时执行一次, 一般用于初始化静态变量静态资源
集合类
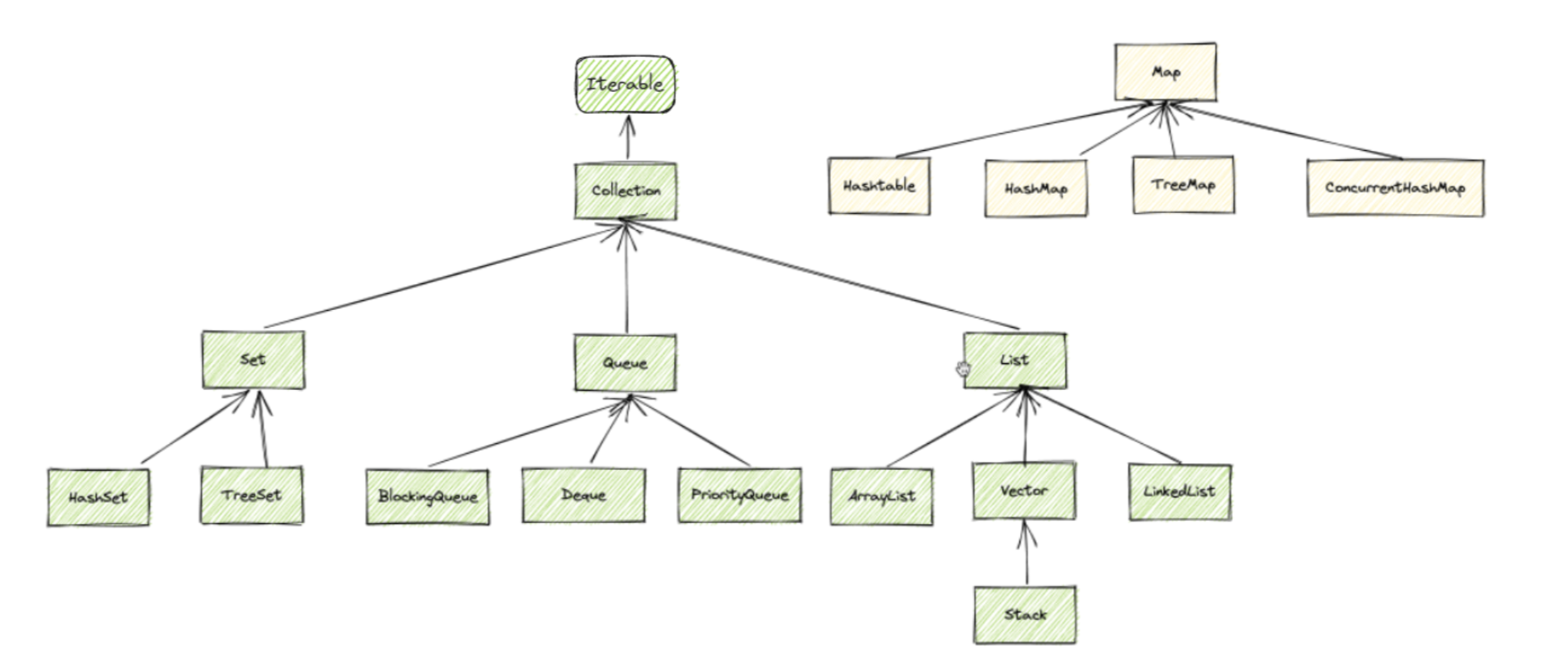
Java 中的集合类有哪些?如何分类的?
核心接口可以分为 Collection 和 Map 两大类; Collection 由分为 List、Set、Queue 三大类 Map 分为 HashMap, LinkListHashMap, TreeMap, HashTable, ConcurrentHashMap
说一下集合类如何进行排序
方法一: 可以在需要进行排序的类中实现 Comparable 接口并重写 compare 方法, 然后就可以直接调用集合工具类的排序方法了
方法二: 在调用工具类方法时通过函数式接口创建匿名内部类声明比较器, 也可以通过 lambda 表达式进行简化操作
方法三: 还可以通过 Stream 流的排序进行实现
解释一下 fail-fast 和 fail-safe
两者都是失败机制; 简单来说 fail-fast 在遇到失败信息时会立刻中断程序然后报告错误, 而 fail-safe 是一种容错机制; 两者主要针对的是在并发场景在集合面对错误的处理方式; fail-fast 机制如果出现在遍历集合过程中集合本身发生结构性的变换 (比如增加元素)就会立刻抛出错误并停止迭代 fail-safe 通过对集合进行复制, 实现在迭代过程中对集合修改不会影响到集合副本的迭代运行
在并发场景在一般使用 CopyOnWrireArrayList 和 ConcurrentHashMap 实现 fail-safe
如何避免 fail-fast
可以通过迭代起的 remove 方法实现 还可以转为线程安全的集合类 还可以通过 stream 的 filter 因为 stream 每次操作都会生成一个新的 stream 不会有并发问题
public void iteratorRemove() {
List<Student> students = this.getStudents();
Iterator<Student> stuIter = students.iterator();
while (stuIter.hasNext()) {
Student student = stuIter.next();
if (student.getId() % 2 == 0) {
//这里要使用Iterator的remove方法移除当前对象,如果使用List的remove方法,则同样会出现ConcurrentModificationException
stuIter.remove();
}
}
}
Set 如何保证元素不重复的?
Set 有两大分支 HashSet 和 TreeSet ; 他们的共同点都是通过本身数据结构的特性判断新插入的元素是否已经存在如果已经存在则禁止插入
- HashSet 是通过对元素进行 hash 运算计算出应该存储的位置, 然后看位置上是否已经有元素, 如果没有则证明不重复直接插入; 如果已经有元素了还需要考虑是不是因为 hash 冲突而导致多个不同元素被划分到同一个位置, 就需要对位置上的元素进行比较判断是否相同
- TreeSet 的的层是通过红黑树实现的, 红黑树的特点是有序, 所以在去重判断上新元素插入时时通过 compare 方法和根元素比较, 如果根为 null 则直接插入, 如果为负数那么就向左子树查询插入位置, 如果大于则向右子树查询插入位置, 如果为 0 则证明插入元素和当前元素相同则拒绝插入
ArrayList, LinkedList 和 Vector 的区别
- ArrayList 是使用得最多的, 连续的内存空间, 随机访问速度 O (1), 但是数组中插入和移除元素的时间复杂度是 O (n)
- LinkedList 底层是双向链表实现的, 对于元素的删除和插入效率 O (1), 但是数组的遍历效率为 O (n)
- 上面两个都是线程不安全的如果在并发环境下要使用那么就需要手动开启和释放锁来保证线程安全
- Vector 可以简单理解成 ArrayList 的线程安全版本, 但是因为实现了线程安全所以运行效率低于 ArrayList ;如果想追求更高的性能可以使用同样线程安全的 CopyOnWrireArrayList
ArrayList 的 subList 方法有什么需要注意的地方吗?
subList 执行后的返回值是 ArrayList 的一个内部类不能强转为 ArrayList, 他只是原数组的一段视图一段窗口; 对 subList 的结果进程操作会直接影响到原数组; 并且在 subList 执行后原数组发生改变那么视图也会失效
ArrayList 的自动扩容机制
ArrayList 默认的长度是 10, 可以在 new 的时候指定数组的大小; ArrayList 的大小不是固定的, 如果数组中的元素满了之后再进行插入那么就会触发自动扩容机制; 会创建一个大小是原数组 1.5 倍新数组然后通过 Arrays 工具类中的 copyOf 方法将旧数组拷贝到新数组最后再插入新元素释放旧数组空间
解决 Hash 冲突的方法
hash 冲突是由于我们将无限的输入要散列到有限的空间上, 就必然会出现两个不同的元素被计算到同一个位置上情况, 这就是 hash 冲突原因 解决 hash 冲突的常规方法有以下几种
- 线性探测法: 如果发现计算的位置上已经存在了元素那么就依次寻找一下空闲的位置进行存储
- 链地址法: 是值将散列到同一个位置上的元素通过一个链表串联起来; 这中方法的问题是如果一个位置上的链表过上那么查询效率就很低失去了 hash 运算查询 O (1) 的优势; 所以在 java 中如何一个 hash 冲突链表过长那么就会升级成红黑树
- 多次 hash 法: 如果经过一次 hash 发生了冲突那么就再次进行多次 hash 直到不冲突为止, 从而来降低冲突率;
- 建立公共溢出区: 统一将所有冲突的元素存储到溢出表中 一般来说除非存储的空间特别小, 否则冲突是很少发生的
HashMap 的底层数据结构是什么
数组 + 链表 + 红黑树 集成了数组快速随机访问、链表快速追加元素和链表升级为红黑树后强大的综合能力三者的优点 每个数组单元格存储的对象都是一个 node, 包括四个部分信息: hash 值、key、value、next 其中的 next 就是为了实现链表结构; 当链表长度≥8 且数组长度≥64 时就会将链表升级为红黑树
- 如果数组长度小于 64 那么则会触发扩容机制
- 如果红黑树的节点通过删除个数≤6 那么又会降级为链表
HashMap 的自动扩容机制
#java##面试#HashMap 的默认大小是 16, 我们也可以在创建 HashMap 的时候手动指定大小; 手动指定大小会会自动向上取最接近的 2 的幂; 比如指定为 7 那么 JDK 创建空间为 8 的 map 如果指定大小为 13 那么就会创建大小为 16 的 map;
有了一个明确的大小就需要解释一下扩容因子了; 扩容因子默认是 0.75 也就是 map 中 key 的使用操过了 75%那么就会触发扩容机制; 会首先创建一个大小为原 map 尺寸两倍的空间 (为了保证 2 的幂等性), 然后需要将原 map 中的数据移动到新的 map 中, 因为两个 map 的大小不一样对于同一个 key 散列的位置也不同, 在 1.8 之前是对所有 key 进行再次哈希运算得到在新表中的位置,然后存储;; 这样的方式缺点就是会浪费大量的运算在 rehash 这个步骤上; 所以在 jdk 1.8 之后会将原表中的一个位置上如果没有发生冲突 (元素 next == null)那么就直接进行再次 hash 计算新位置索引, 如果发生了冲突那么就会分成高位链表和低位链表两部分, 低位链表在新 map 中的索引不变, 而高位则需要在原索引基础上+旧 map 的容量大小; 如何计算高位和低位旧用元素的 hash 值和旧 map 长度进行逻辑与运算判断结果高位为 0 则为低位 1 则为高位;
- 1.7 中采用的是头插法在并发场景在可能出现链表成环的问题, 但是 1.8 开始采用的尾插法则不会出现这种问题
还有一种情况会发生自动扩容就是当数组长度小于 64 并且某个位置索引处因为冲突而导致链表长度≥8 那么此时就不会直接升级成红黑树而是触发自动扩容机制


 查看17道真题和解析
查看17道真题和解析