
DDD的函数式编程实现
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM Agent应用开发
- 区块链应用开发
- 大数据开发挖掘经验
- 推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
DDD是一种成熟的软件设计方法,旨在确保领域专家和开发人员能够有效合作,创造出高质量的软件。
本文介绍咋将FP(函数式编程)应用于DDD的实现,使其既优雅又简洁。C4模型中,软件架构图分为四个层次:“系统上下文”、“容器”、“组件”和“代码”。
“组件”是构成容器的基本单位,也是本文描述的层次。
1 代码组织结构
随应用程序复杂性增加,管理这种复杂性的一种方法是根据应用程序的职责或关注点将其拆分。分层架构是一种遵循这一原则的方法,它有助于保持不断增长的代码库的组织性,使开发人员能够轻松找到某个功能的实现位置。
在分层架构中,代码被水平拆分为不同的层次,每一层通过面向对象(OO)设计进行封装。请求从顶层进入,代码从上到下执行,输出从顶层产生。
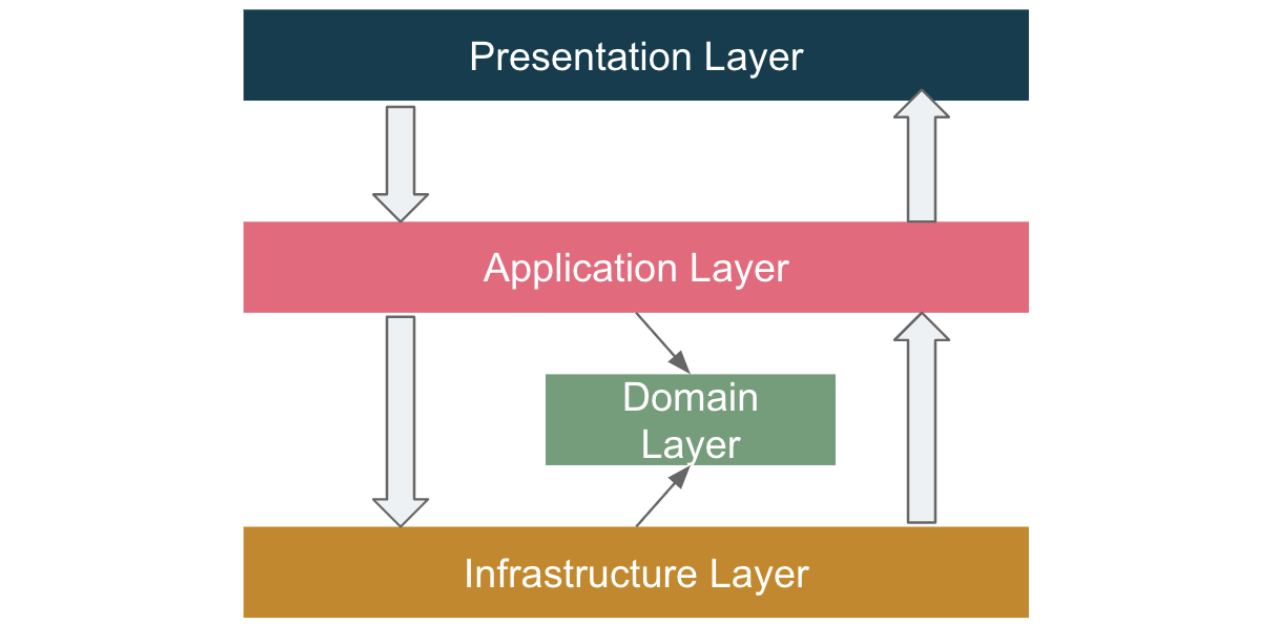
这种设计的一个问题是,多个层次不仅分离了关注点,还将同一业务功能的上下文分离到不同的位置,这意味着在修改同一业务功能时,可能需要同时修改多个层次。
另一个问题是,表示层和应用层通常被设计为外观模式,这易导致上帝对象的出现,而上帝对象被认为是一种反模式。
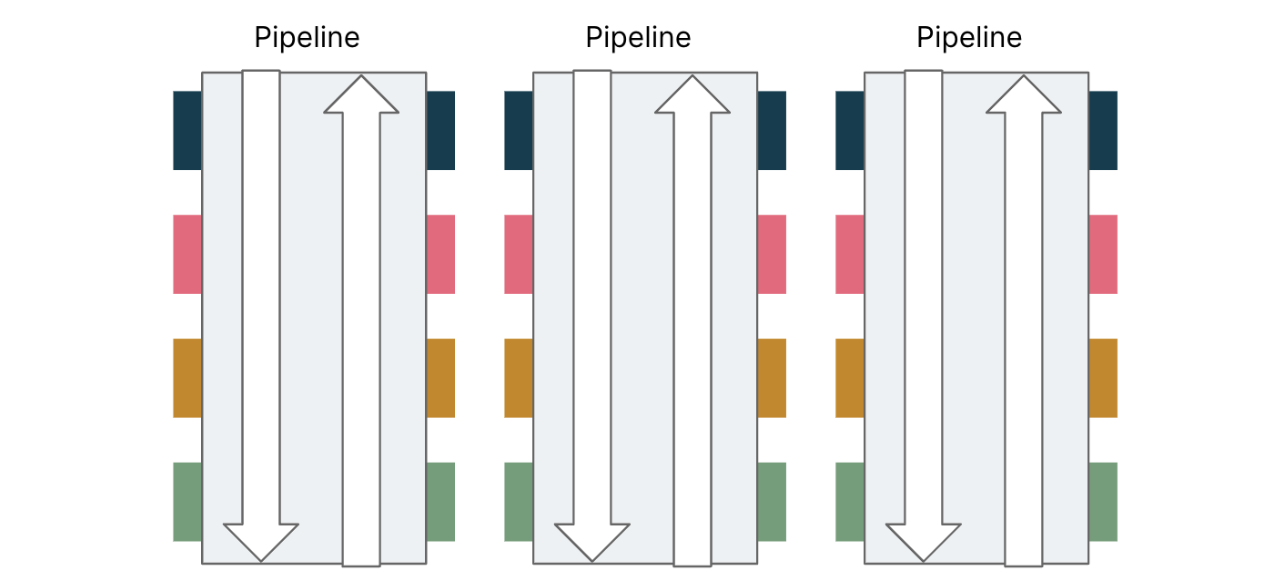
FP本质是组合。FP更倾向于垂直组织代码,而不是水平拆分代码。多个函数通过Monad组合成一个函数流水线来实现一个业务功能(通常是一个API)。
基于函数式编程的垂直代码结构:
2 信任边界
现实世界中,问题域之间的边界是模糊的。限界上下文是计算机系统中对现实世界问题的人工投影:
- 边界之外的世界不可信,因为它包括来自用户的各种输入
- 边界之内的世界则是可信的、合法的、共享的领域模型

这要求我们在限界上下文的边界处引入验证和转换,从而防止外部输入并验证输出的合法性。
常见的验证和转换包括:
- 将输入数据转换为领域模型
- 验证输入数据的有效性,例如确保用户名和电子邮件不为空
- 输出检查器,防止如用户密码等敏感信息被包含在输出数据中
在FP中,Applicative通常用于验证和转换输入数据为领域模型。一旦输入数据突破信任边界,你就无需担心用户名是否为空或电子邮件格式是否正确。你应专注于使用ADT进行领域建模,并通过纯函数处理业务规则。
3 使用状态机进行领域建模
业务模型可以通过不同状态的转换来建模。你总是可以通过联合类型(和类型)将领域建模为状态机。另一个好处是,在FP中,模式匹配迫使你处理联合类型的每个分支,以避免遗漏情况。
状态之间的转换
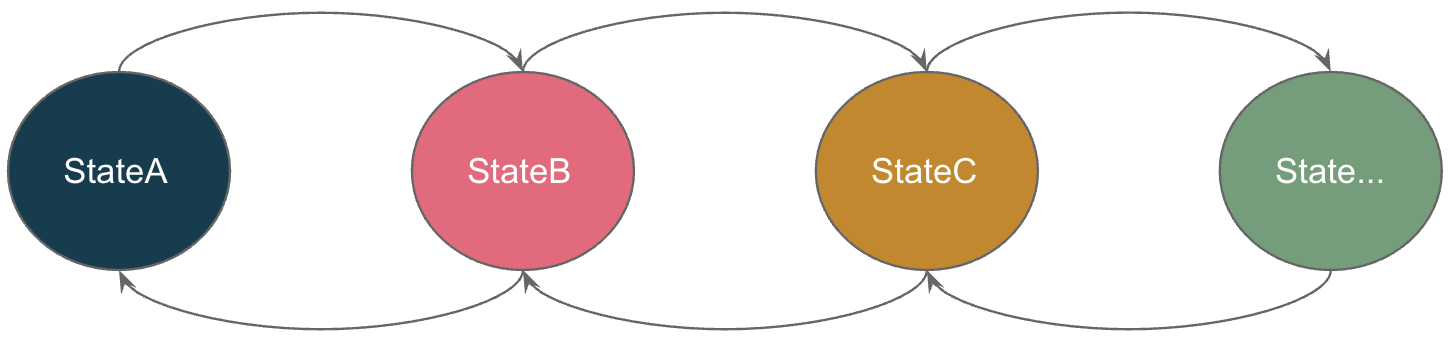
以用户注册为例:注册可以分为三个步骤:
- 输入用户名和密码
- 验证电子邮件
- 支付会员费
这三个步骤可以通过联合类型记录为三个明确的状态。诸如注册、添加电子邮件、验证电子邮件等行为可以通过对这个领域模型进行模式匹配设计为函数。
4 保持领域纯粹
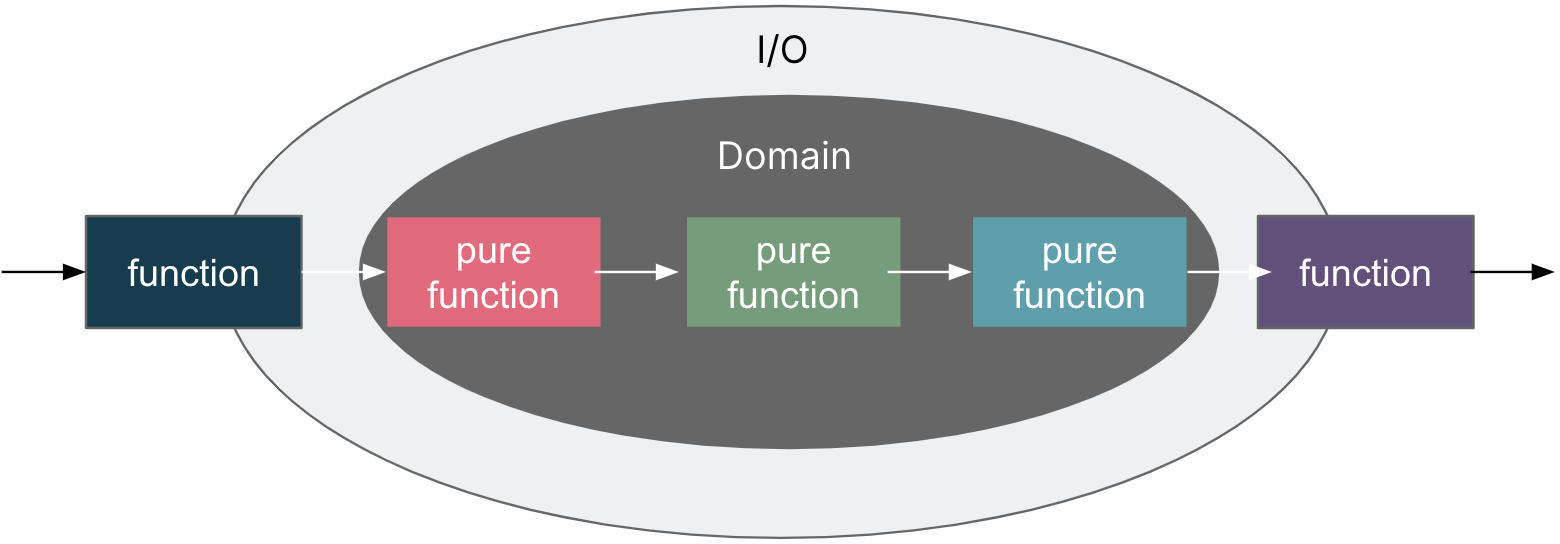
遵循依赖倒置原则的应用程序倾向于实现洋葱架构或整洁架构。其核心思想是将业务逻辑和领域模型置于应用程序的中心,而不是让业务逻辑依赖于数据访问或其他基础设施。依赖关系被倒置:基础设施和实现细节依赖于应用程序核心。
同样,在FP中,我们倾向于在每个API请求中将函数组合为流水线。与洋葱架构类似,我们尽可能将副作用置于领域之外,以保持领域的纯粹性。纯函数遵循持久性无知原则,它们专注于实现业务规则。
洋葱架构:
5 总结
通常,面向对象编程语言是实现DDD的首选,函数式编程则被认为适合数据科学的管道处理。实际上,DDD只是一个强调应专注于领域的思想,它并不依附于任何特定的编程范式。你可以利用FP的特性,如可组合性、Monad、Applicative和模式匹配,在“组件”架构层级上实现DDD。

