
基于k8s Deployment的弹性扩缩容及滚动发布机制
k8s第一个重要设计思想:控制器模式。k8s里第一个控制器模式的完整实现:Deployment。它实现了k8s一大重要功能:Pod的“水平扩展/收缩”(horizontal scaling out/in)。该功能从PaaS时代开始就是一个平台级项目必备编排能力。
若你更新了Deployment的Pod模板(如修改容器的镜像),则Deployment就需遵循“滚动更新”(rolling update),来升级现有容器。
该能力的实现,依赖k8s一个很重要的概念(API对象):
1 ReplicaSet
// ReplicaSet ensures that a specified number of pod replicas are running at any given time.
type ReplicaSet struct {
metav1.TypeMeta
// +optional
metav1.ObjectMeta
// Spec defines the desired behavior of this ReplicaSet.
// +optional
Spec ReplicaSetSpec
// Status is the current status of this ReplicaSet. This data may be
// out of date by some window of time.
// +optional
Status ReplicaSetStatus
}
ReplicaSet结构简单,可通过YAML查看:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
一个ReplicaSet对象组成:
- 副本数目的定义
- 一个Pod模板
其定义就是Deployment的一个子集。Deployment控制器实际操纵的,正是这样的ReplicaSet对象,而非Pod对象。
对一个Deployment所管理的Pod,其ownerReference是谁?就是ReplicaSet。
2 案例
如下Deployment(常用的nginx-deployment):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
# 定义Pod副本的个数
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
具体实现上,该Deployment与ReplicaSet及Pod的关系:

一个定义了replicas=3的Deployment,与它的ReplicaSet及Pod的关系,是“层层控制”关系。
ReplicaSet负责通过“控制器模式”,保证系统中Pod个数永远=指定个数。这也是Deployment只许容器的restartPolicy=Always主要原因:只有在容器能保证自己始终是Running态的前提,ReplicaSet调整Pod个数才有意义。
Deployment同样通过“控制器模式”操作ReplicaSet的个数和属性,实现如下编排:
- 水平扩展/收缩
- 滚动更新
3 水平扩展/收缩
Deployment Controller只需修改所控制的ReplicaSet的Pod副本个数。
如把值从3改到4,那Deployment所对应的ReplicaSet,就会根据修改后的值自动创建一个新Pod,即“水平扩展”;“水平收缩”则反之。
$ kubectl scale deployment nginx-deployment --replicas=4
deployment.apps/nginx-deployment scaled
FAQ
如果水平收缩的过程中,某个pod中的容器有正在运行的业务,而业务如果中断的话可能会导致数据库数据出错,该怎么办?如何保证把pod的业务执行完再收缩?
业务需要优雅处理sig term。
scale down时,k8s是对pod里的容器发送kill 信号吗?所以应用需要处理好这个信号?
先term 再kill。需要处理。如果有prestop,先执行prestop。再发term,graceperiod到了后发kill。收到term后应用就要graceful stop了,处理完老的请求,不再接受新的请求。
4 滚动更新
先创建该nginx-deployment:
$ kubectl create -f nginx-deployment.yaml --record
–record参数:记录每次操作所执行的命令。
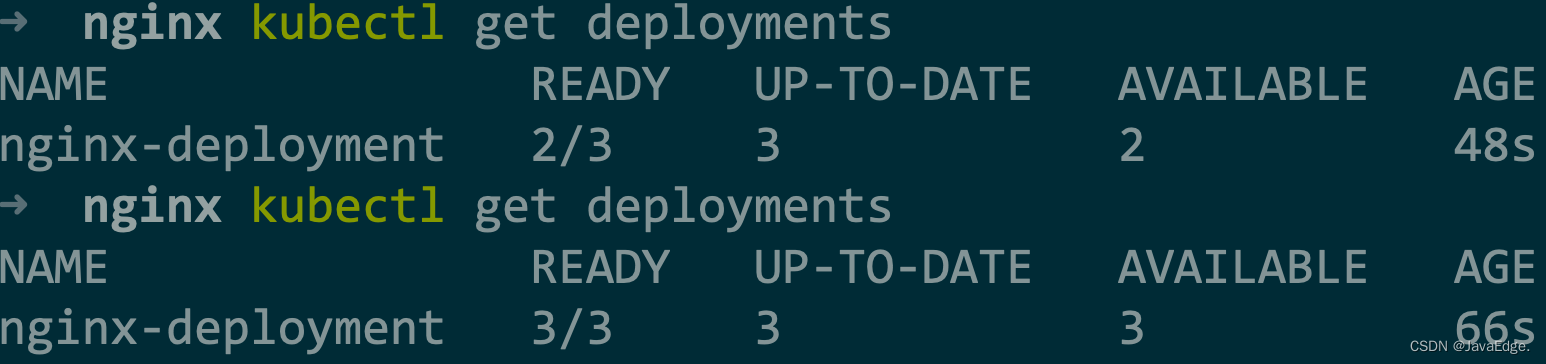
检查nginx-deployment创建后的状态信息:
$ kubectl get deployments
4.1 状态字段
① DESIRED
用户期望的Pod副本个数(spec.replicas值)
② CURRENT
当前处Running态的Pod的个数
③ UP-TO-DATE
当前处最新版本的Pod的个数。最新版本:Pod的Spec部分与Deployment里Pod模板里定义一致
④ AVAILABLE
当前已可用的Pod的个数,即:既是Running态,又是最新版本,且已处于Ready(健康检查正确)态的Pod的个数。
可见,只有AVAILABLE描述的才是用户期望的最终状态。而k8s提供一条指令,可实时查看Deployment对象状态变化
4.2 kubectl rollout status
$ kubectl rollout status deployment/nginx-deployment
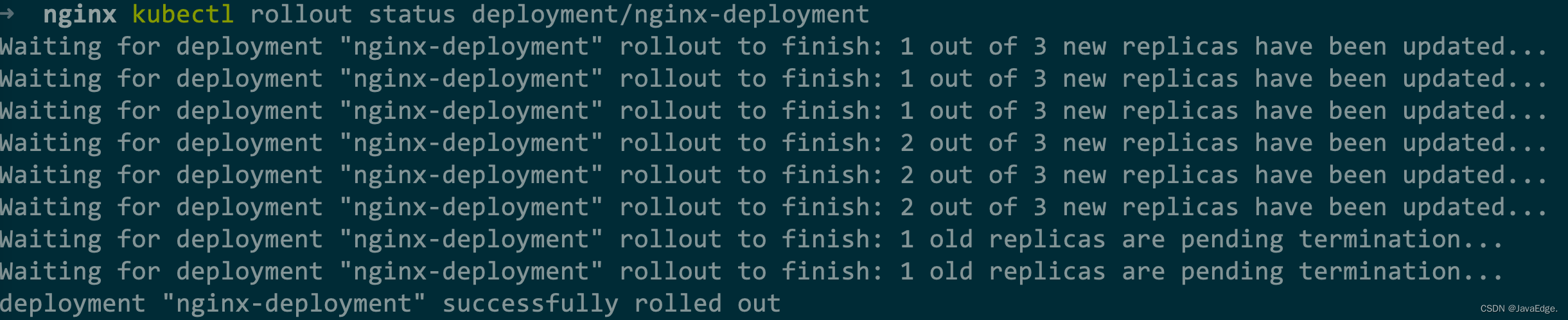
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
“2 out of 3 new replicas have been updated”即已有2个Pod进入UP-TO-DATE态。
稍后,就能看到该Deployment的3个Pod都进入AVAILABLE态:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 20s
查看该Deployment所控制的ReplicaSet:
$ kubectl get rs

在用户提交一个Deployment对象后,Deployment Controller就会立即创建一个Pod副本个数为3的ReplicaSet。该ReplicaSet名字=Deployment名字+一个随机字符串。
这随机字符串是pod-template-hash,该例里就是:7759cfdc55。ReplicaSet会把该随机字符串加在它所控制的所有Pod标签,保证这些Pod不会和集群里其他Pod混淆。
而ReplicaSet的DESIRED、CURRENT和READY字段含义和Deployment一致。所以,相比之下,Deployment只是在ReplicaSet基础上,添加了UP-TO-DATE这版本有关的状态字段。
这时,若修改Deployment的Pod模板,“滚动更新”就会被自动触发。
4.3 修改Deployment
有很多方法。如kubectl edit指令编辑Etcd里的API对象。
$ kubectl edit deployment/nginx-deployment
...
spec:
containers:
- name: nginx
# 将nginx镜像的版本升级到1.9.1
image: nginx:1.9.1 # 1.7.9 -> 1.9.1
ports:
- containerPort: 80
...
deployment.extensions/nginx-deployment edited
该指令会帮你直接打开nginx-deployment的API对象。然后,你就能修改这里的Pod模板部分。
kubectl edit是把API对象的内容下载到本地文件,让你修改完成后再提交上去。
kubectl edit指令编辑完成后,保存退出,k8s就会立刻触发“滚动更新”过程。
通过kubectl rollout status查看nginx-deployment的状态变化:
$ kubectl rollout status deployment/nginx-deployment
查看Deployment的Events,看到“滚动更新”流程:
$ kubectl describe deployment nginx-deployment
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0

首先,当你修改Deployment的Pod定义后,Deployment Controller会使用这个修改后的Pod模板,创建一个新ReplicaSet(hash=1764197365),这新ReplicaSet的初始Pod副本数是:0。
然后,Age=24s,Deployment Controller开始将这个新的ReplicaSet所控制的Pod副本数从0个变成1个,即“水平扩展”出一个副本。
Age=22s,Deployment Controller又将旧ReplicaSet(hash=3167673210)所控制的旧Pod副本数减少一个,即:“水平收缩”成两个副本。
如此交替进行:
- 新ReplicaSet管理的Pod副本数,从0=》1=》2=》3个
- 旧ReplicaSet管理的Pod副本数则从3个变成2个,再变成1个,最后变成0
这就完成这组Pod的版本升级过程。
将一个集群中正在运行的多个Pod版本,交替地逐一升级的过程,就是“滚动更新”。
“滚动更新”完成后,查看新、旧两个ReplicaSet的最终状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 3 3 3 6s
nginx-deployment-3167673210 0 0 0 30s

旧ReplicaSet(hash=3167673210)已被“水平收缩”成了0个副本。
4.4 滚动更新的好处
如升级刚开始时,集群里只有1个新版本的Pod。若这时,新版本Pod有问题启动不起来,则“滚动更新”就会停止,从而允许开发、运维介入。而在这过程中,由于应用本身还有两个旧版Pod在线,所以服务不会受到太大影响。
这也就要求你一定要使用Pod的Health Check机制检查应用的运行状态,而非简单依赖容器的Running状态。不然,虽容器已Running,但服务很有可能尚未启动,“滚动更新”效果就达不到了。
为保证服务连续性,Deployment Controller还会确保:
- 任何时间窗口内,只有指定比例的Pod处离线态
- 任何时间窗口内,只有指定比例的新Pod被创建出来
这两个比例的值都是可配置,默认都是DESIRED值的25%。
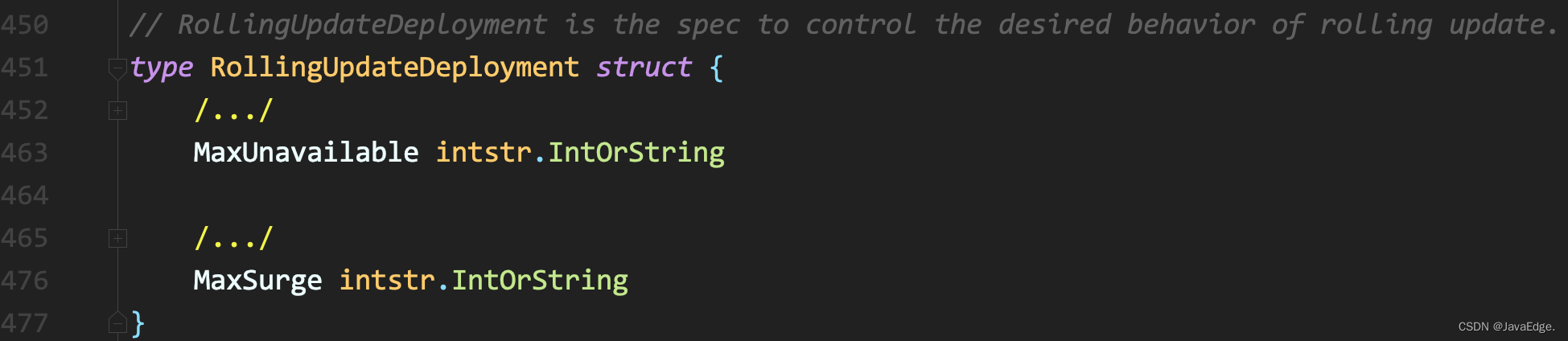
所以,上面的Deployment案例有3个Pod副本,则控制器在“滚动更新”的过程中永远都会确保至少有2个Pod处可用状态,至多4个Pod同时存在于集群中。该策略是Deployment对象的一个字段,名叫RollingUpdateStrategy
如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
该RollingUpdateStrategy配置中:
- maxSurge 除了DESIRED数量之外,在一次“滚动”中,Deployment控制器还可以创建多少个新Pod
- maxUnavailable指的是,在一次“滚动”中,Deployment控制器可以删除多少个旧Pod。
同时,这两个配置还可以用百分比形式表示,如:maxUnavailable=50%,指的是我们最多可以一次删除“50%*DESIRED数量”个Pod。
4.5 FAQ
滚动更新时控制的是副本集,对于上层的service,什么时候切换到新的pod,期间会涉及到外部请求负载到旧版本的pod吗?
理论上分析肯定有这个情况,不然就不会抛出金丝雀发布和蓝绿发布的概念了。只要pod是就绪状态,不管版本老旧,都会被访问到,老版本在滚动更新过程中被下线,状态变为不可用后,才会从service里面剔除掉。
如果不修改镜像名称和tag,如何做到强制拉取镜像,触发更新?
imagepullpolicy=always
公司准备试水k8s,我看网上很多文章都在说跨主机容器间通信的解决方案,如果我们的服务分批容器化,需要解决宿主机网络和容器网络的互通,我用flannel或者calico目前都只能做到宿主机能访问容器网络或者容器能访问宿主机网络,不能做到双向通讯,能指点一下吗?
为什么是 或者?宿主机和容器网络互通是基本假设。如果跟宿主机共享网络, 可以用hostNetwork: true。
在滚动更新的过程中,Service的流量转发会有怎样的变化呢?
service只会代理readiness检查返回正确的pod。
如果我直接edit rs,将image修改成新的版本,是不是也能实现pod中容器镜像的更新?我试了一下,什么反应也没有。既然rs控制pod,为什么这样改不能生效呢?
因为rs controller 不处理rollout逻辑
5 应用版本和ReplicaSet一一对应
扩展Deployment、ReplicaSet和Pod关系图:

Deployment的控制器实际控制的是:
- ReplicaSet的数目
- 及每个ReplicaSet的属性
而一个应用的版本,对应一个ReplicaSet;该版本应用的Pod数量,由ReplicaSet通过它自己的控制器(ReplicaSet Controller)保证。通过多个ReplicaSet对象,k8s实现对多个“应用版本”的描述。
6 Deployment对应用进行版本控制
6.1 kubectl set image
直接修改nginx-deployment使用的镜像。不用像kubectl edit需打开编辑器。
把该镜像名字修改成为一个错误名字,如nginx:1.91。这个Deployment就会出现一个升级失败的版本。
[root@javaedge-monitor-platform-dev k8s]# kubectl set image deployment/nginx-deployment nginx=nginx:1.91
deployment.apps/nginx-deployment image updated
[root@javaedge-monitor-platform-dev k8s]#
由于这nginx:1.91镜像在Docker Hub不存在,所以这个Deployment的“滚动更新”被触发后,会立刻报错并停止。
检查ReplicaSet状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 2 2 2 24s
nginx-deployment-3167673210 0 0 0 35s
nginx-deployment-2156724341 2 2 0 7s
- 新版本的ReplicaSet(hash=2156724341)的“水平扩展”已停止。此时,它已创建两个Pod,但都没有进入READY态。因为这两个Pod都拉不到有效镜像
- 旧版本的ReplicaSet(hash=1764197365)的“水平收缩”,也自动停止了。此时,已有一个旧Pod被删除,还剩下两个旧Pod
如何让该Deployment的3个Pod都
7 回滚到旧版本
执行kubectl rollout undo,就能把整个Deployment回滚到上一版本:
$ kubectl rollout undo deployment/nginx-deployment
deployment.extensions/nginx-deployment
Deployment的控制器就是让这个旧ReplicaSet(hash=1764197365)再“扩展”成3个Pod,而让新ReplicaSet(hash=2156724341)重“收缩”到0个Pod。
7.1 回滚到指定版本
① 查看每次变更对应版本
先使用kubectl rollout history,查看每次Deployment变更对应的版本。
而由于我们在创建这Deployment时,指定了–record参数,所以创建这些版本时执行的kubectl命令,都会被记录:
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl create -f nginx-deployment.yaml --record
2 kubectl edit deployment/nginx-deployment
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
- 前面执行的创建和更新操作,分别对应了版本1、2
- 那次失败的更新操作是版本3
② Deployment API对象细节
还能看到每个版本对应的Deployment的API对象的细节
$ kubectl rollout history deployment/nginx-deployment --revision=2
就能在kubectl rollout undo命令行最后,加上要回滚到的指定版本的版本号,就能回滚到指定版本:
$ kubectl rollout undo deployment/nginx-deployment --to-revision=2
deployment.extensions/nginx-deployment
Deployment Controller还会按“滚动更新”,完成对Deployment的降级操作。
FAQ
有人说:一般生产环境回滚不会用什么 rollout 吧 ?直接把 yaml 文件的 镜像改回之前的 不就回滚了嘛?
改yaml又执行一遍rolling update了,而且因为应用版本不仅仅只有代码或者镜像,还有包括内存和cpu资源等。
在 deployment rollout undo 的时候,是也会创建一个新的rs对象吗?如果是的话那么这个rs的template hash不就重复了?如果不是得话又是如何处理的呢?
deployment 关注的应该是自身的api对象和rs的api对象,但是我看deployment controller 的源码中也关注了pod的变更,这是为了处理哪种情况?
回滚又不是创建新版本,版本与rs一一对应,怎么会出现新的rs呢?滚动升级反向操作即可。 它只关心pod被全删除的情况,因为有一种滚动更新策略是这时候重新创建新的deployment。
8 ReplicaSet资源节约
对Deployment进行的每一次更新操作,都会生成一个新的ReplicaSet对象,是不是有些多余,甚至浪费资源?
是的!所以,k8s项目还提供指令,让我们对Deployment的多次更新操作,最后只生成一个ReplicaSet。
更新Deployment前,先执行
8.1 kubectl rollout pause
$ kubectl rollout pause deployment/nginx-deployment
deployment.extensions/nginx-deployment paused
让这个Deployment进入“暂停”状态。然后,就能随意使用kubectl edit或kubectl set image,修改该Deployment内容。
由于此时Deployment正处“暂停”态,所以我们对Deployment的所有修改,都不会触发新的“滚动更新”,也不会创建新ReplicaSet。
而等到我们对Deployment修改操作都完成之后,再执行
8.2 kubectl rollout resume
就能把这个Deployment“恢复”:
$ kubectl rollout resume deploy/nginx-deployment
deployment.extensions/nginx-deployment resumed
而在这个kubectl rollout resume指令执行之前,在kubectl rollout pause指令之后的这段时间里,我们对Deployment进行的所有修改,最后只会触发一次“滚动更新”。
检查ReplicaSet状态的变化,验证kubectl rollout pause和kubectl rollout resume指效果:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-1764197365 0 0 0 2m
nginx-3196763511 3 3 3 28s
只有一个hash=3196763511的ReplicaSet被创建。
即使小心控制了ReplicaSet的生成数量,随应用版本不断增加,k8s还是会为同一Deployment保存很多很多不同ReplicaSet,如何控制这些“历史”ReplicaSet的数量?Deployment对象有一个字段spec.revisionHistoryLimit,即k8s为Deployment保留的“历史版本”个数。所以,把它设置为0,就再也不能做回滚操作。
9 总结
Deployment这个k8s项目中最基本的编排控制器的实现原理和使用方法。
Deployment实际上是个两层控制器:
- 先通过ReplicaSet的个数来描述应用的版本
- 再通过ReplicaSet的属性(比如replicas的值),保证Pod的副本数量
Deployment控制ReplicaSet(版本),ReplicaSet控制Pod(副本数)。
k8s项目对Deployment的设计,实际是代替我们完成了对“应用”的抽象,使得我们可以使用这个Deployment对象来描述应用,使用kubectl rollout命令控制应用的版本。
可实际场景,应用发布的流程往往千差万别,也可能有很多定制需求。如我的应用可能有会话黏连(session sticky),这就意味着“滚动更新”的时候,哪个Pod能下线,不能随便选择。这光靠Deployment自己就很难应对了。
k8s本身也提供另外一种抽象方式,应对其他一些用Deployment无法处理的应用编排场景。
10 FAQ
金丝雀发布(Canary Deployment)和蓝绿发布(Blue-Green Deployment)啥东西?
金丝雀部署:优先发布一台或少量机器升级,等验证无误后再更新其他机器。优点是用户影响范围小,不足之处是要额外控制如何做自动更新。
蓝绿部署:2组机器,蓝代表当前的V1版本,绿代表已经升级完成的V2版本。通过LB将流量全部导入V2完成升级部署。优点是切换快速,缺点是影响全部用户。
有了Deployment的能力之后,可非常轻松用它实现金丝雀发布、蓝绿发布及A/B测试等很多应用发布模式。这些问题答案都在GitHub库
kubectl get deployments得到的 available 字段表示的是处于Running状态且健康检查通过的Pod, 这里有一个疑问: 健康检查不是针对Pod里面的Container吗? 如果某一个Pod里面包含多个Container, 但是这些Container健康检查有些并没有通过, 那么此时该Pod会出现在 available里面吗? Pod通过健康检查是指里面所有的Container都通过吗?
都通过!
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都国企技术专家兼架构,多家大厂后台研发和架构经验,负责复杂度极高业务系统的模块化、服务化、平台化研发工作。具有丰富带团队经验,深厚人才识别和培养的积累。
参考:
#我的成功项目解析#


