异常检测:探索数据深层次背后的奥秘《上篇》
异常检测:探索数据深层次背后的奥秘《上篇》
1、什么是异常检测
异常检测(Outlier Detection),顾名思义,是识别与正常数据不同的数据,与预期行为差异大的数据。
识别如信用卡欺诈,工业生产异常,网络流里的异常(网络侵入)等问题,针对的是少数的事件。
1.1 异常的类别
点异常(point anomalies)指的是少数个体实例是异常的,大多数个体实例是正常的,例如正常人与病人的健康指标;
条件异常(conditional anomalies),又称上下文异常,指的是在特定情境下个体实例是异常的,在其他情境下都是正常的,例如在特定时间下的温度突然上升或下降,在特定场景中的快速信用卡交易;
群体异常(group anomalies)指的是在群体集合中的个体实例出现异常的情况,而该个体实例自身可能不是异常,在入侵或欺诈检测等应用中,离群点对应于多个数据点的序列,而不是单个数据点。例如社交网络中虚假账号形成的集合作为群体异常子集,但子集中的个体节点可能与真实账号一样正常。
1.2 异常检测任务分类
有监督:训练集的正例和反例均有标签
无监督:训练集无标签
半监督:在训练集中只有正例,异常实例不参与训练
1.3 异常检测场景
-
故障检测:主要是监控系统,在故障发生时可以识别,并且准确指出故障的种类以及出现位置。主要应用领域包括银行欺诈、移动蜂窝网络故障、保险欺诈、医疗欺诈。
-
医疗日常检测:在许多医疗应用中,数据是从各种设备收集的,如磁共振成像(MRI)扫描、正电子发射断层扫描(PET)扫描或心电图(ECG)时间序列。这些数据中的异常模式通常反映疾病状况。
-
网络入侵检测:在许多计算机系统中,都会收集有关操作系统调用、网络流量或其他用户操作的不同类型的数据。由于恶意活动,此数据可能显示异常行为。对此类活动的识别称为入侵检测。
-
欺诈检测:信用卡欺诈越来越普遍,因为信用卡号码等敏感信息更容易被泄露。在许多情况下,未经授权使用信用卡可能表现出不同的模式,例如从特定地点疯狂购买或进行非常大的交易。这种模式可用于检测信用卡交易数据中的异常值。
-
工业异常检测
-
时间序列异常检测
-
视频异常检测
-
日志异常检测
1.4 异常检测的难点
1.数据量少。异常检测任务通常情况下负样本(异常样本)是比较少的,有时候依赖于人工标签,属于样本不平衡问题。
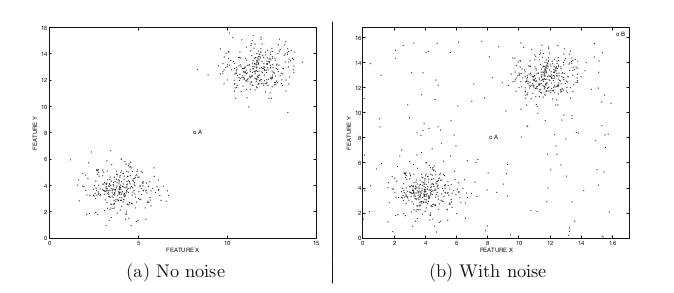
2.噪音。异常和噪音有时候很难分清,如下图,图a的A点位于数据的稀疏区域,与其他数据非常不同,因此可以断定为异常,但是像图b的A点,周围有也有很多点分布,我们很难把A点识别出来。
2、异常检测方法简介
2.1 基础方法
2.1.1 基于统计学的方法
统计学方法对数据的正常性做出假定。**它们假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。**统计学方法的有效性高度依赖于对给定数据所做的统计模型假定是否成立。
异常检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。
即利用统计学方法建立一个模型,然后考虑对象有多大可能符合该模型。
假定输入数据集为,数据集中的样本服从正态分布,即
,我们可以根据样本求出参数
和
。
2.1.2 线性模型
典型的如PCA方法,Principle Component Analysis是主成分分析,简称PCA。它的应用场景是对数据集进行降维。降维后的数据能够最大程度地保留原始数据的特征(以数据协方差为衡量标准)。其原理是通过构造一个新的特征空间,把原数据映射到这个新的低维空间里。PCA可以提高数据的计算性能,并且缓解"高维灾难"。
2.1.3 基于邻近度的方法
这类算法适用于数据点的聚集程度高、离群点较少的情况。同时,因为相似度算法通常需要对每一个数据分别进行相应计算,所以这类算法通常计算量大,不太适用于数据量大、维度高的数据。
基于相似度的检测方法大致可以分为三类:
- 基于集群(簇)的检测,如DBSCAN等聚类算法。
聚类算法是将数据点划分为一个个相对密集的“簇”,而那些不能被归为某个簇的点,则被视作离群点。这类算法对簇个数的选择高度敏感,数量选择不当可能造成较多正常值被划为离群点或成小簇的离群点被归为正常。因此对于每一个数据集需要设置特定的参数,才可以保证聚类的效果,在数据集之间的通用性较差。聚类的主要目的通常是为了寻找成簇的数据,而将异常值和噪声一同作为无价值的数据而忽略或丢弃,在专门的异常点检测中使用较少。
-
基于距离的度量,如k近邻算法。
k近邻算法的基本思路是对每一个点,计算其与最近k个相邻点的距离,通过距离的大小来判断它是否为离群点。在这里,离群距离大小对k的取值高度敏感。如果k太小(例如1),则少量的邻近离群点可能导致较低的离群点得分;如果k太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使模型更加稳定,距离值的计算通常使用k个最近邻的平均距离。
-
基于密度的度量,如LOF(局部离群因子)算法。
局部离群因子(LOF)算法与k近邻类似,不同的是它以相对于其邻居的局部密度偏差而不是距离来进行度量。它将相邻点之间的距离进一步转化为“邻域”,从而得到邻域中点的数量(即密度),认为密度远低于其邻居的样本为异常值。
2.2 集成方法
集成是提高数据挖掘算法精度的常用方法。集成方法将多个算法或多个基检测器的输出结合起来。其基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。
常用的集成方法有Feature bagging,孤立森林等。
**feature bagging **:
与bagging法类似,只是对象是feature。
孤立森林:
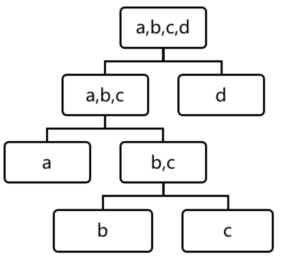
孤立森林假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
用四个样本做简单直观的理解,d是最早被孤立出来的,所以d最有可能是异常。
2.3 机器学习
在有标签的情况下,可以使用树模型(gbdt,xgboost等)进行分类,缺点是异常检测场景下数据标签是不均衡的,但是利用机器学习算法的好处是可以构造不同特征。
- 参考资料
[1] 《Outlier Analysis》——Charu C. Aggarwal
[2] https://zhuanlan.zhihu.com/p/260651151
3.异常检测——基于统计学的方法
主要内容包括:
- 高斯分布
- 箱线图
- HBOS
统计学方法对数据的正常性做出假定。**它们假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。**统计学方法的有效性高度依赖于对给定数据所做的统计模型假定是否成立。
异常检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。
即利用统计学方法建立一个模型,然后考虑对象有多大可能符合该模型。
根据如何指定和学习模型,异常检测的统计学方法可以划分为两个主要类型:参数方法和非参数方法。
参数方法假定正常的数据对象被一个以为参数的参数分布产生。该参数分布的概率密度函数
给出对象
被该分布产生的概率。该值越小,
越可能是异常点。
非参数方法并不假定先验统计模型,而是试图从输入数据确定模型。非参数方法通常假定参数的个数和性质都是灵活的,不预先确定(所以非参数方法并不是说模型是完全无参的,完全无参的情况下从数据学习模型是不可能的)。
3.1、参数方法
2.1 基于正态分布的一元异常点检测
仅涉及一个属性或变量的数据称为一元数据。我们假定数据由正态分布产生,然后可以由输入数据学习正态分布的参数,并把低概率的点识别为异常点。
假定输入数据集为,数据集中的样本服从正态分布,即
,我们可以根据样本求出参数
和
。
求出参数之后,我们就可以根据概率密度函数计算数据点服从该分布的概率。正态分布的概率密度函数为
如果计算出来的概率低于阈值,就可以认为该数据点为异常点。
阈值是个经验值,可以选择在验证集上使得评估指标值最大(也就是效果最好)的阈值取值作为最终阈值。
例如常用的3sigma原则中,如果数据点超过范围,那么这些点很有可能是异常点。
这个方法还可以用于可视化。箱线图对数据分布做了一个简单的统计可视化,利用数据集的上下四分位数(Q1和Q3)、中点等形成。异常点常被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的那些数据。
用Python画一个简单的箱线图:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
data = np.random.randn(50000) * 20 + 20
sns.boxplot(data=data)
2.2 多元异常点检测
涉及两个或多个属性或变量的数据称为多元数据。许多一元异常点检测方法都可以扩充,用来处理多元数据。其核心思想是把多元异常点检测任务转换成一元异常点检测问题。例如基于正态分布的一元异常点检测扩充到多元情形时,可以求出每一维度的均值和标准差。对于第维:
计算概率时的概率密度函数为
这是在各个维度的特征之间相互独立的情况下。如果特征之间有相关性,就要用到多元高斯分布了。
1.3 多个特征相关,且符合多元高斯分布
ps:当多元高斯分布模型的协方差矩阵为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
3.使用混合参数分布
在许多情况下假定数据是由正态分布产生的。当实际数据很复杂时,这种假定过于简单,可以假定数据是被混合参数分布产生的。
3.2、非参数方法
在异常检测的非参数方法中,“正常数据”的模型从输入数据学习,而不是假定一个先验。通常,非参数方法对数据做较少假定,因而在更多情况下都可以使用。
例子:使用直方图检测异常点。
直方图是一种频繁使用的非参数统计模型,可以用来检测异常点。该过程包括如下两步:
步骤1:构造直方图。使用输入数据(训练数据)构造一个直方图。该直方图可以是一元的,或者多元的(如果输入数据是多维的)。
尽管非参数方法并不假定任何先验统计模型,但是通常确实要求用户提供参数,以便由数据学习。例如,用户必须指定直方图的类型(等宽的或等深的)和其他参数(直方图中的箱数或每个箱的大小等)。与参数方法不同,这些参数并不指定数据分布的类型。
步骤2:检测异常点。为了确定一个对象是否是异常点,可以对照直方图检查它。在最简单的方法中,如果该对象落入直方图的一个箱中,则该对象被看作正常的,否则被认为是异常点。
对于更复杂的方法,可以使用直方图赋予每个对象一个异常点得分。例如令对象的异常点得分为该对象落入的箱的容积的倒数。
使用直方图作为异常点检测的非参数模型的一个缺点是,很难选择一个合适的箱尺寸。一方面,如果箱尺寸太小,则许多正常对象都会落入空的或稀疏的箱中,因而被误识别为异常点。另一方面,如果箱尺寸太大,则异常点对象可能渗入某些频繁的箱中,因而“假扮”成正常的。
3.3、基于角度的方法
基于角度的方法的主要思想是:数据边界上的数据很可能将整个数据包围在一个较小的角度内,而内部的数据点则可能以不同的角度围绕着他们。如下图所示,其中点A是一个异常点,点B位于数据内部。
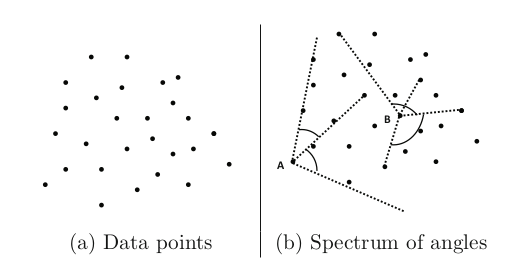
如果数据点与其余点离得较远,则潜在角度可能越小。因此,具有较小角度谱的数据点是异常值,而具有较大角度谱的数据点不是异常值。
考虑三个点X,Y,Z。如果对于任意不同的点Y,Z,有:
其中代表L2范数 ,
代表点积。
这是一个加权余弦,因为分母包含L2-范数,其通过距离的逆加权进一步减小了异常点的加权角,这也对角谱产生了影响。然后,通过改变数据点Y和Z,保持X的值不变计算所有角度的方法。相应地,数据点X的基于角度的异常分数(ABOF)∈ D为:
3.4、HBOS
HBOS全名为:Histogram-based Outlier Score。它是一种单变量方法的组合,不能对特征之间的依赖关系进行建模,但是计算速度较快,对大数据集友好。其基本假设是数据集的每个维度相互独立。然后对每个维度进行区间(bin)划分,区间的密度越高,异常评分越低。
HBOS算法流程:
1.为每个数据维度做出数据直方图。对分类数据统计每个值的频数并计算相对频率。对数值数据根据分布的不同采用以下两种方法:
-
静态宽度直方图:标准的直方图构建方法,在值范围内使用k个等宽箱。样本落入每个桶的频率(相对数量)作为密度(箱子高度)的估计。时间复杂度:
-
2.动态宽度直方图:首先对所有值进行排序,然后固定数量的
个连续值装进一个箱里,其中N是总实例数,k是箱个数;直方图中的箱面积表示实例数。因为箱的宽度是由箱中第一个值和最后一个值决定的,所有箱的面积都一样,因此每一个箱的高度都是可计算的。这意味着跨度大的箱的高度低,即密度小,只有一种情况例外,超过k个数相等,此时允许在同一个箱里超过
时间复杂度:
2.对每个维度都计算了一个独立的直方图,其中每个箱子的高度表示密度的估计。然后为了使得最大高度为1(确保了每个特征与异常值得分的权重相等),对直方图进行归一化处理。最后,每一个实例的HBOS值由以下公式计算:
推导过程:
假设样本p第 i 个特征的概率密度为 ,则p的概率密度可以计算为:
两边取对数:
概率密度越大,异常评分越小,为了方便评分,两边乘以“-1”:
最后可得:
- 小结
1.异常检测的统计学方法由数据学习模型,以区别正常的数据对象和异常点。使用统计学方法的一个优点是,异常检测可以是统计上无可非议的。当然,仅当对数据所做的统计假定满足实际约束时才为真。
2.HBOS在全局异常检测问题上表现良好,但不能检测局部异常值。但是HBOS比标准算法快得多,尤其是在大数据集上。
- 参考资料
[1] Goldstein, M. and Dengel, A., 2012. Histogram-based outlier score (hbos):A fast unsupervised anomaly detection algorithm . InKI-2012: Poster and Demo Track, pp.59-63.
[2] http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
[3] http://cs229.stanford.edu/
[4] 《Outlier Analysis》——Charu C. Aggarwal
更多优质内容请关注:汀丶人工智能;
#机器学习##数据挖掘##异常检测#主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等。同时重丶讲解模型验证、特征优化、模型融合等。 助力你快速数学建模baseline实现,拿奖稳稳的!





