强化学习基础篇[3]:DQN、Actor-Critic详解
强化学习基础篇[3]:DQN、Actor-Critic详细讲解
1.DQN详解
1.1 DQN网络概述及其创新点
在之前的内容中,我们讲解了Q-learning和Sarsa算法。在这两个算法中,需要用一个Q表格来记录不同状态动作对应的价值,即一个大小为 的二维数组。在一些简单的强化学习环境中,比如迷宫游戏中(图1a),迷宫大小为4*4,因此该游戏存在16个state;而悬崖问题(图1b)的地图大小为 4*12,因此在该问题中状态数量为48,这些都属于数量较少的状态,所以可以用Q表格来记录对应的状态动作价值。但当我们需要应用强化学习来解决实际问题时,比如解决国际象棋问题或围棋问题,那么环境中就会包含 个state或 个state,如此庞大的状态数量已经很难用Q表格来进行存储,更不要说在3D仿真环境中,机器人手脚弯曲的状态是完全不可数的。由此可以看到Q表格在大状态问题和不可数状态问题时的局限性。同时,在一个强化学习环境中,不是所有的状态都会被经常访问,其中有些状态的访问次数很少或几乎为零,这就会导致价值估计并不可靠。

图1: 不同强化学习环境对应的状态量
为解决上述两个问题,一种解决方案即为Q表格参数化,使用深度神经网络拟合动作价值函数 。参数化可以解决无限状态下的动作价值函数的存储问题,因为算法只需记住一组参数,动作价值函数的具体值可根据这一组参数算出。同时,参数化也有助于缓解因某些状态访问次数少而导致的估值不准问题。因为对于一个处在连续空间内的状态价值函数,如果要对访问次数较多的状态小临域内的状态进行价值估计,其估计结果也是有一定保障的。
但是动作价值函数的参数化也会带来一些新的问题,首先,因为相邻样本来自同一条轨迹,会导致样本间关联性过强,而集中优化关联性过强的样本会导致神经网络处理其他样本时无法取得较好的结果。举一个例子来说明这个问题,比如:假设一个agent的action有上下左右四种选择,神经网络采用一条轨迹为 的训练样本进行训练,而当该网络处理轨迹 的样本进行预测时,就不会取得很好的效果。另一个问题是,当参数 被同时用来计算动作价值函数的目标值和预测的Q值时,对 的更新会同时影响这两个值,使得损失函数中的优化目标变得不明确,算法收敛不稳定。
为了解决如上两个问题,Mnih 等人提出了深度Q网络 (Deep Q-Network,DQN),其本质上是Q-learning算法,但使用深度学习网络拟合Q函数,解决了无限状态下的动作价值函数存储问题,同时采用经验重现(Experience Replay)和固定Q目标(Fixed-Q-Target)两个创新点来解决上述两个问题。
- 经验重现(Experience Replay):使用一个经验池存储多条经验 , 再从中随机抽取一批用于训练,很好的解决了样本关联性的问题,同时,因为经验池里的经验可以得到重复利用,也提升了利用效率。
- 固定Q目标(Fixed-Q-Target):复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值,这样在原来的Q网络中,target Q就是一个固定的数值,不会再产生优化目标不明确的问题。
1.2. 算法流程
在DQN算法中,智能体会在与所处环境 进行交互后,获得一个环境提供的状态 。 接收状态后,智能体会根据深度学习网络预测出在该状态下不同行动 对应的Q值,并给出一个行动 ,当行动反馈给环境后,环境会给出对应的奖励 、新的状态 ,以及是否触发终止条件 。每一次交互完成,DQN算法都会将 作为一条经验储存在经验池中,每次会从经验池中抽取一定量的经验作为输入数据训练神经网络。
DQN算法流程:
- 初始化经验池,随机初始化Q网络;
- for episode = 1, M do:
- 重置环境,获得第一个状态;
- for t = 1, T do:
- 用 策略生成一个action:其中有 的概率会随机选择一个action,即为探索模式;其他情况下,则,选择在 状态下使得Q最大的action,即为经验模式;
- 根据动作与环境的交互,获得反馈的reward 、下一个状态 和是否触发终止条件done;
- 将经验 存入经验池;
- 从经验池中随机获取一个minibatch的经验;
- 根据 和 求loss,梯度下降法更新Q网络
- end for
- 每隔固定个episode,更新Qtarget网络
- end for
2.Actor-Critic
在 REINFORCE 算法中,每次需要根据一个策略采集一条完整的轨迹,并计算这条轨迹上的回报。这种采样方式的方差比较大,学习效率也比较低。我们可以借鉴时序差分学习的思想,使用动态规划方法来提高采样的效率,即从状态 开始的总回报可以通过当前动作的即时奖励 和下一个状态 的值函数来近似估计。
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,包括两部分,演员(Actor)和评价者(Critic),跟生成对抗网络(GAN)的流程类似:
- 演员(Actor)是指策略函数 ,即学习一个策略来得到尽量高的回报。用于生成动作(Action)并和环境交互。
- 评论家(Critic)是指值函数 ,对当前策略的值函数进行估计,即评估演员的好坏。用于评估Actor的表现,并指导Actor下一阶段的动作。
借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
在Actor-Critic算法 里面,最知名的方法就是 A3C(Asynchronous Advantage Actor-Critic)。
- 如果去掉 Asynchronous,只有 Advantage Actor-Critic,就叫做
A2C。 - 如果加了 Asynchronous,变成Asynchronous Advantage Actor-Critic,就变成
A3C。
2.1 Actor-Critic
2.1.1 Q-learning
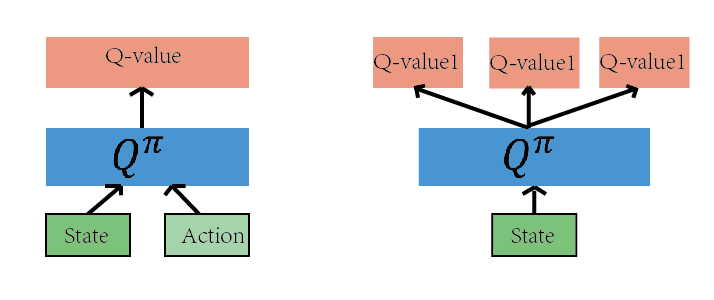
如上图的网络都是为了近似 Q(s,a)函数,有了 Q(s,a),我们就可以根据Q(s,a)的值来作为判断依据,作出恰当的行为。
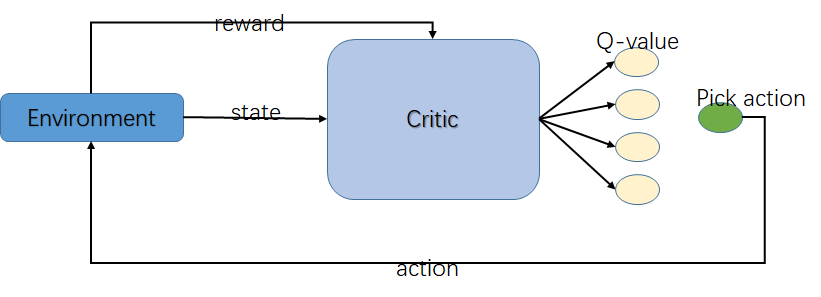
Q-learning算法最主要的一点是:决策的依据是Q(s,a)的值。即算法的本质是在计算 当前状态s, 采取某个动作 a 后会获得的未来的奖励的期望,这个值就是 Q(s,a)。换句话说,我们可以把这个算法的核心看成一个评论家(Critic),而这个评论家会对我们在当前状态s下,采取的动作a这个决策作出一个评价,评价的结果就是Q(s,a)的值。
Q-learning 算法却不怎么适合解决连续动作空间的问题。因为如果动作空间是连续的,那么用Q-learning算法就需要对动作空间离散化,而离散化的结果会导致动作空间的维度非常高,这就使得Q-learning 算法在实际应用起来很难求得最优值,且计算速度比较慢。
2.1.2 Policy Gradient
Policy Gradient 算法的核心思想是: 根据当前状态,直接算出下一个动作是什么或下一个动作的概率分布是什么。即它的输入是当前状态 s, 而输出是具体的某一个动作或者是动作的分布。
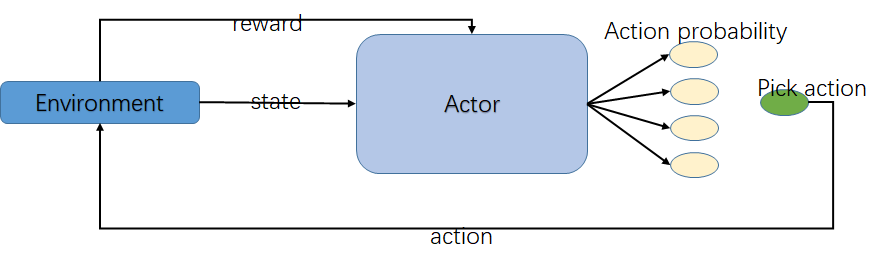
我们可以想像,Policy Gradient 就像一个演员(Actor),它根据某一个状态s,然后作出某一个动作或者给出动作的分布,而不像Q-learning 算法那样输出动作的Q函数值。
2.1.3 Actor Critic
Actor-Critic 是Q-learning 和 Policy Gradient 的结合。 为了导出 Actor-Critic 算法,必须先了解Policy Gradient 算法是如何一步步优化策略的。
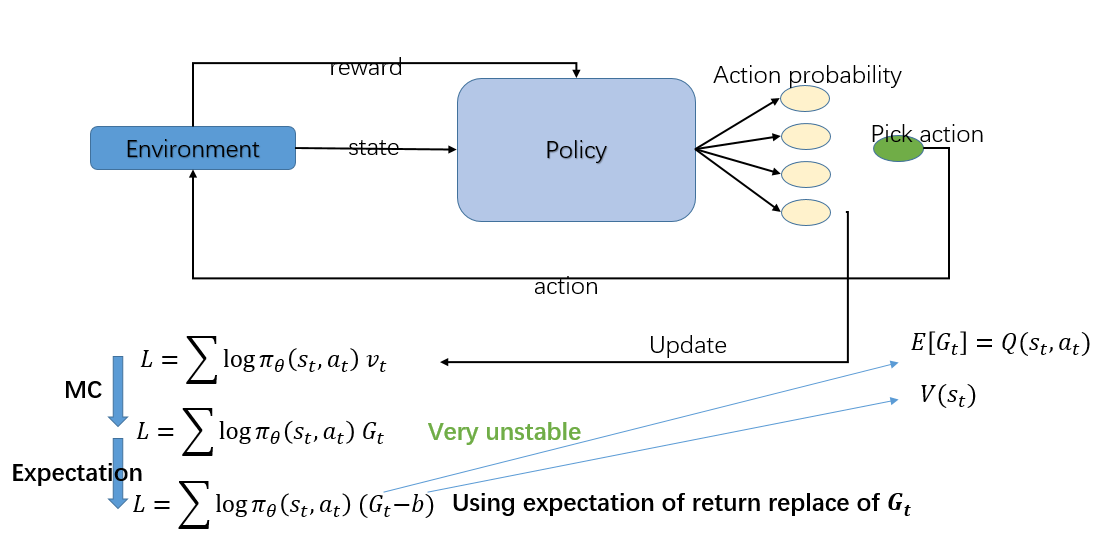
如上图所示, 最简单的Policy Gradient 算法要优化的函数如下:
其中要根据 Monte-Carlo 算法估计,故又可以写成:
但是这个方差会比较大,因为是由多个随机变量得到的,因此,我们需要寻找减少方差的办法。
一个方法就是引入一个 baseline 的函数 b, 这个 b 会使得的期望不变,但是方差会变小,常用的 baseline函数就是。再来,为了进一步降低的随机性,我们用替代,这样原式就变成:
因为,故进一步变成:
照上面的式子看来,我们需要两个网络去估计和,但是考虑到贝尔曼方程:
弃掉期望:
在原始的A3C论文中试了各种方法,最后做出来就是直接把期望值拿掉最好,这是根据实验得出来的。 最终的式子为:
这样只需要一个网络就可以估算出V值了,而估算V的网络正是我们在 Q-learning 中做的,所以我们就把这个网络叫做 Critic。这样就在 Policy Gradient 算法的基础上引进了 Q-learning 算法了
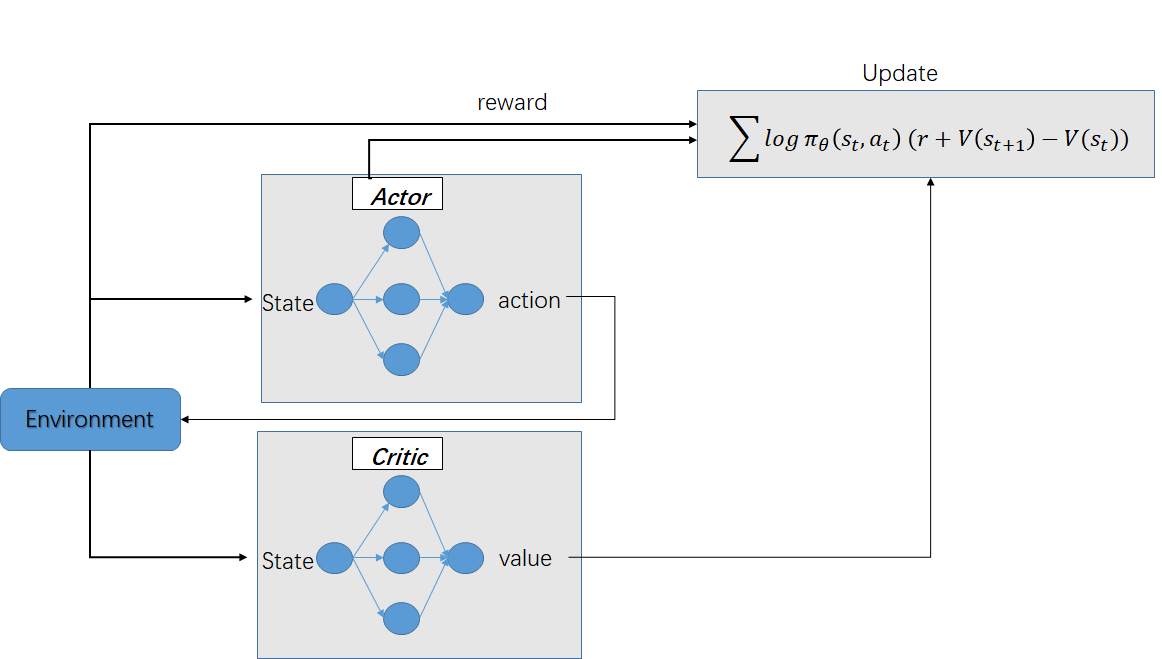
2.2 Actor-Critic算法流程
评估点基于TD误差,Critic使用神经网络来计算TD误差并更新网络参数,Actor也使用神经网络来更新网络参数
输入:迭代轮数T,状态特征维度n,动作集A,步长,,衰减因子,探索率, Critic网络结构和Actor网络结构。
输出:Actor网络参数,Critic网络参数
- 随机初始化所有的状态和动作对应的价值Q;
- for i from 1 to T,进行迭代:
- 初始化S为当前状态序列的第一个状态,拿到其特征向量
- 在Actor网络中使用作为输入,输出动作A,基于动作A得到新的状态S',反馈R;
- 在Critic网络中分别使用,作为输入,得到Q值输出V(S),V(S');
- 计算TD误差
- 使用均方差损失函数作Critic网络参数w的梯度更新;
- 更新Actor网络参数:
对于Actor的分值函数,可以选择softmax或者高斯分值函数。
2.3 Actor-Critic优缺点
-
优点
- 相比以值函数为中心的算法,Actor - Critic 应用了策略梯度的做法,这能让它在连续动作或者高维动作空间中选取合适的动作,而Q-learning 做这件事会很困难甚至瘫痪。、
- 相比单纯策略梯度,Actor - Critic 应用了Q-learning 或其他策略评估的做法,使得Actor Critic 能进行单步更新而不是回合更新,比单纯的Policy Gradient 的效率要高。
-
缺点
- 基本版的Actor-Critic算法虽然思路很好,但是难收敛
-
目前改进的比较好的有两个经典算法:
-
DDPG算法,使用了双Actor神经网络和双Critic神经网络的方法来改善收敛性。
-
A3C算法,使用了多线程的方式,一个主线程负责更新Actor和Critic的参数,多个辅线程负责分别和环境交互,得到梯度更新值,汇总更新主线程的参数。而所有的辅线程会定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用,但是效果更好。
-
更多文章请关注公重号:汀丶人工智能
#深度学习##人工智能##强化学习##DQN#强化学习单智能体、多智能体原理应用介绍以及码源项目实战,后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。


 查看21道真题和解析
查看21道真题和解析
