
MySQL基础语句
主要参考here整理
1. 数据库基本语句
1.1. 创建数据库
语法格式:
CREATE DATABASE [IF NOT EXISTS] <数据库名> [[DEFAULT] CHARACTER SET <字符集名>] [[DEFAULT] COLLATE <校对规则名>];
实例:
CREATE DATABASE IF NOT EXISTS test_db_char DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
1.2. 查看数据库定义声明
SHOW CREATE DATABASE test_db_char;
1.3. 查看数据库
语法格式:
SHOW DATABASES [LIKE '数据库名'];
实例
查看所有的数据库 SHOW DATABASES; 查看数据库名为test_db_char SHOW DATABASES LIKE 'test_db_char'; 查看数据库名字中包含st的数据库 SHOW DATABASES LIKE '%st%'; 查看数据库名字中以s开头的数据库 SHOW DATABASES LIKE 's%'; 查看数据库名字中以s结尾的数据库 SHOW DATABASES LIKE '%s';
Note:DATABSES,也就是注意最后的字母“S”。
1.4. 修改数据库
ALTER DATABASE [数据库名] {
[ DEFAULT ] CHARACTER SET <字符集名> |
[ DEFAULT ] COLLATE <校对规则名>}ALTER DATABASE test_db_char DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; 只修改字符集 ALTER DATABASE test_db_char DEFAULT CHARACTER SET utf8;
1.5. 删除数据库
DROP DATABASE [ IF EXISTS ] <数据库名>
DROP DATABASE IF EXISTS test_db_char;
1.6. 使用数据库
USE <数据库名> USE test_db_char;
2. 表
2.1. 创建表
CREATE TABLE tb_empl( id INT(11), name VARCHAR(255), deptId INT(11), salary FLOAT ); 注意最后的分号,注意创建表的时候,右括号前面不能包含逗号,不然会出错
2.2. 查看表结构
DESC tb_empl; 或者 DESCRIBE tb_empl;
Note:DESC和SHOW使用上的区别。
2.3. 显示创建表的语句
SHOW CREATE TABLE tb_empl; 可以查看到字符引擎和字符编码 CREATE TABLE `tb_empl` ( `id` int(11) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `deptId` int(11) DEFAULT NULL, `salary` float DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.4. 修改表结构
ALTER TABLE <表名> [修改选项]
修改选项的语法格式如下:
{ ADD COLUMN <列名> <类型>
| CHANGE COLUMN <旧列名> <新列名> <新列类型>
| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT }
| MODIFY COLUMN <列名> <类型>
| DROP COLUMN <列名>
| RENAME TO <新表名> }增加一列 ALTER TABLE <表名> ADD <新字段名> <数据类型> [约束条件] [FIRST|AFTER 已存在的字段名]; ALTER TABLE tb_empl ADD COLUMN col1 INT FIRST; 修改数据类型 ALTER TABLE <表名> MODIFY <字段名> <数据类型> ALTER TABLE tb_empl MODIFY COLUMN name VARCHAR(30); 同时修改多行 ALTER TABLE tb_empl MODIFY COLUMN name VARCHAR(30), MODIFY COLUMN col2 VARCHAR(100); 删除字段(列) ALTER TABLE <表名> DROP <字段名>; ALTER TABLE tb_empl DROP col2; 修改字段名 ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型>; ALTER TABLE tb_empl CHANGE col3 age CHAR(4); 修改表名 ALTER TABLE <旧表名> RENAME [TO] <新表名>; 其中,TO 为可选参数,使用与否均不影响结果。 ALTER TABLE tb_empl RENAME TO tb_empl1
关键词: ADD-增加列,MODIFY-修改列类型,DROP-删除列,CHANGE-修改列名,RENAME-修改表名。
2.5. 删除数据表
DROP TABLE [IF EXISTS] 表名1 [ ,表名2, 表名3 ...] DROP TABLE tb_empl1;
2.6. 主键约束
在定义列的同时设置主键 CREATE TABLE tb_empl2( id INT(11) PRIMARY KEY, name VARCHAR(255), deptId INT(11), salary FLOAT ); 在定义完所有列之后指定主键 [CONSTRAINT <约束名>] PRIMARY KEY [字段名] CREATE TABLE tb_empl( id INT(11), name VARCHAR(255), deptId INT(11), salary FLOAT, PRIMARY KEY(id) ); 在创建完表时设置组合主键 CREATE TABLE tb_empl3( id INT(11), name VARCHAR(255), deptId INT(11), salary FLOAT, PRIMARY KEY(id, deptId) ); 修改表的时候增加主键约束 ALTER TABLE <数据表名> ADD PRIMARY KEY(<列名>); ALTER TABLE tb_empl ADD PRIMARY KEY(id); 删除主键约束 ALTER TABLE tb_empl3 DROP PRIMARY KEY;
2.7. 外键
创建表的时候设置外键 [CONSTRAINT <外键名>] FOREIGN KEY 字段名 [,字段名2,…] REFERENCES <主表名> 主键列1 [,主键列2,…] CREATE TABLE tb_empl1( id INT(11) PRIMARY KEY, name VARCHAR(22) NOT NULL, location VARCHAR(50) ); CREATE TABLE tb_empl2( id INT(11) PRIMARY KEY, name VARCHAR(25), deptId Int(11), salary FLOAT, CONSTRAINT fk_emp_dept1 FOREIGN KEY(deptId) REFERENCES tb_empl1(id) ); 修改表时添加外键约束 ALTER TABLE <数据表名> ADD CONSTRAINT <索引名> FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>); CREATE TABLE tb_empl3( id INT(11) PRIMARY KEY, name VARCHAR(25), deptId Int(11), salary FLOAT ); ALTER TABLE tb_empl3 ADD CONSTRAINT fk_tb_dept2 FOREIGN KEY(deptId) REFERENCES tb_empl1(id); 删除外键约束 ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>; ALTER TABLE tb_empl3 DROP FOREIGN KEY fk_tb_dept2; 接着通过SHOW CREATE TABLE tb_empl3;可以查看到里面不存在FOREIGN KEY,但是还存在KEY,不清楚原因。 CREATE TABLE `tb_empl3` ( `id` int(11) NOT NULL, `name` varchar(25) DEFAULT NULL, `deptId` int(11) DEFAULT NULL, `salary` float DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_tb_dept2` (`deptId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.8. 唯一性约束
要求该列值唯一,允许为空,但只能出现一个空值。比如邮件,用户名等。
在创建表的时候设置唯一性约束 CREATE TABLE tb_empl3( id INT(11) PRIMARY KEY, name VARCHAR(25) UNIQUE, deptId Int(11), salary FLOAT ); 修改表时增加唯一性约束 ALTER TABLE <数据表名> ADD CONSTRAINT <唯一约束名> UNIQUE(<列名>); ALTER TABLE tb_empl3 ADD CONSTRAINT unique_name UNIQUE(name) 删除唯一性约束 ALTER TABLE tb_empl3 DROP INDEX unique_name
2.9. 数据表查询语句
SELECT
{* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
{*|<字段列名>}包含星号通配符的字段列表,表示查询的字段,其中字段列至少包含一个字段名称,如果要查询多个字段,多个字段之间要用逗号隔开,最后一个字段后不要加逗号。
FROM <表 1>,<表 2>…,表 1 和表 2 表示查询数据的来源,可以是单个或多个。
WHERE 子句是可选项,如果选择该项,将限定查询行必须满足的查询条件。
GROUP BY< 字段 >,该子句告诉 MySQL 如何显示查询出来的数据,并按照指定的字段分组。
[ORDER BY< 字段 >],该子句告诉 MySQL 按什么样的顺序显示查询出来的数据,可以进行的排序有升序(ASC)和降序(DESC)。
[LIMIT[<offset>,]<row count>],该子句告诉 MySQL 每次显示查询出来的数据条数。
SELECT id, name, salary, deptId FROM tb_empl;3. 查询
顺序: select 查询结果 from 从哪张表中查找数据 where 查询条件 group by 分组 having 对分组结果指定条件 order by 对查询结果排序(降序 DESC 升序 ASC)
3.1. 去重
id name deptId salary 1 Tom 1001 5000 2 Mary 1002 4000 3 Jack 1003 4000 4 Tim 1004 4000 SELECT DISTINCT salary FROM tb_empl; 得到的结果: salary 5000 4000
3.2. 设置别名
语法格式: <表名> [AS] <别名> 例子: SELECT id, name, salary, deptId FROM tb_empl AS te;
3.3. 限制查询结果的记录条数
<LIMIT> [<位置偏移量>,] <行数> 第一个参数“位置偏移量”指示 MySQL 从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是 0,第二条记录的位置偏移量是 1,以此类推);第二个参数“行数”指示返回的记录条数。 查询3条记录 SELECT id, name, salary, deptId FROM tb_empl LIMIT 3; 从偏移量为1的开始查询3条记录。 SELECT id, name, salary, deptId FROM tb_empl LIMIT 1,3; OFFSET表示的是偏移量,LIMIT表示3条记录。 SELECT id, name, salary, deptId FROM tb_empl LIMIT 3 OFFSET 1;
3.4. 查询结果排序
ORDER BY {<列名> | <表达式> | <位置>} [ASC|DESC]
关键字 ASC 表示按升序分组,关键字 DESC 表示按降序分组,其中 ASC 为默认值。这两个关键字必须位于对应的列名、表达式、列的位置之后。
使用 ORDER BY 子句应该注意以下几个方面:
ORDER BY 子句中可以包含子查询。
当排序的值中存在空值时,ORDER BY 子句会将该空值作为最小值来对待。
当在 ORDER BY 子句中指定多个列进行排序时,MySQL 会按照列的顺序从左到右依次进行排序。
查询的数据并没有以一种特定的顺序显示,如果没有对它们进行排序,则将根据插入到数据表中的顺序显示。使用 ORDER BY 子句对指定的列数据进行排序。
ORDER BY 默认是升序
SELECT id, name, salary, deptId
FROM tb_empl
ORDER BY salary;
完整:
SELECT id, name, salary, deptId
FROM tb_empl
ORDER BY salary DESC, name ASC;3.5. 条件查询
WHERE <查询条件> {<判定运算1>,<判定运算2>,…}
单一条件查询
SELECT id, name, salary, deptId
FROM tb_empl
WHERE salary=4000;
多条件查询
SELECT id, name, salary, deptId
FROM tb_empl
WHERE salary=4000 AND deptId>1003;
使用LIKE的模糊查询
%可以表示任何字符并且该字符可以出现人一次。百分号不匹配控制。
SELECT id, name, salary, deptId
FROM tb_empl
WHERE name LIKE '%m%';
下划线通配符和百分号通配符用途一样,下划线只匹配单个字符,而不是多个字符或者0个字符。下面匹配name中以m结尾,前面包含2两个字符的信息。
SELECT id, name, salary, deptId
FROM tb_empl
WHERE name LIKE '__m';
日期作为条件的查询
SELECT id, name, salary, deptId, jobtime
FROM tb_empl
WHERE jobtime<'2016-01-01';
BETWEEN...AND...
SELECT id, name, salary, deptId, jobtime
FROM tb_empl
WHERE jobtime
BETWEEN '2016-01-01'
AND '2016-03-01';3.6. 汇总查询,比如SUM,COUNT,AVG,MAX,MIN等
参考here
3.6.1. COUNT
求某列的行数,比如
# 从teacher表中统计不同name的行数 SELECT COUNT(DISTINCT name) FROM teacher; # 查看名字中包含'孟'的老师的个数(no是唯一的) SELECT COUNT(no) FROM teacher WHERE name like '%孟%';
3.6.2. SUM
对某列数据求和
# 数据表score中score列的所有数据的和。 SELECT SUM(score) FROM score; # 查询某个同学的总成绩,查询数据表中学生编号为0001的score列的所有值的和。 SELECT SUM(score) FROM score WHERE stu_no = '0001';
3.7. 分组查询
分组查询一般和HAVING同时使用,GROUP BY语句根据一个或多个列队结果集进行分组,在分组的列上可以使用COUNT,SUM,AVG等函数。
3.7.1. 查询平均分大于60分的学生的学号和平均分。
分析: 要计算每个学生的平均成绩,因此这里的“每个”就涉及到分组 SELECT 学号,avg(分数) FROM table WHERE 无 GROUP BY 学号 HAVING avg(分数)>60 SELECT stu_no, avg(score) FROM score GROUP BY stu_no HAVING avg(score) > 60;
3.7.2. 查询选课数量大于2的学生学号
分析:首先,要对每个学生的选课情况进行统计,然后筛选出选课数目大于2的学号 SELECT stu_no FROM score GROUP BY stu_no HAVING count(cour_no) >2;
3.7.3. 统计重名的学生名单和个数
SELECT name, count(*) FROM student GROUP BY `name` HAVING count(name) >=2
Note:使用count来查询重复的名字以及存在重复名字的个数。
3.7.4. 查询课程平均成绩,并将平均成绩按照升序排列,如果成绩相同,就按照课程编号排列
SELECT cour_no, avg(score) FROM score GROUP BY cour_no ORDER BY avg(score) asc, cour_no desc;
3.8. IN子查询
3.8.1. 查询所有成绩小于90分的学号和姓名
分析:首先,最终结果是查询学号和姓名,这个需要从表student中查找。同时要查找成绩小于90分的,这个需要从表score中查找。因此需要了解两个表之间的联系(通过stu_no)联系在一起,所以可以首先查询到成绩小于90分的学号,然后根据这个学号查询对应的名字。 子查询: SELECT stu_no FROM score WHERE score < 90; 最终结果 SELECT no, name FROM student WHERE no in( SELECT stu_no FROM score WHERE score < 90 );
子查询的功能也可以通过连接查询实现,也可以这样写:
SELECT s.name, s.no FROM student s LEFT OUTER JOIN score c ON s.no = c.stu_no WHERE c.score < 90; 此时得到的结果中会出现很多重复的内容,这是因为右表中关于每个stu_no会存在多个记录,因此出现重复。 解决方法 1. distinct 可以用来过滤重复数据 此时,结果集中不会出现s.name和s.no完全相同的记录 SELECT DISTINCT s.name, s.no FROM student s LEFT OUTER JOIN score c ON s.no = c.stu_no WHERE c.score < 90; 2. GROUP BY,首先对结果进行分组。这里注意,是采用RIGHT JOIN,主要是使用右边的表作为主表,然后在主表的基础上增加左表的数据 SELECT s.name, s.no FROM student s RIGHT JOIN (SELECT stu_no FROM score GROUP BY stu_no HAVING min(score)<90) as c ON s.no = c.stu_no;
3.9. 连接查询(共包含4种)
参考here
内连接,左外连接,右外连接,全外连接。
这里的图可以比较清楚的观察每种连接的查询结果。here
连接查询是一种多表查询,对多个表进行JOIN运算。简单来说,就是先确定一个主表作为结果集,然后把其他表的行有选择地“连接”在主表上。
首先,创建两个表,student和class,其中class的主键是student的外键,两个表的数据如下:
student中: id name class_id gender score 1 Mary 1001 female 99 2 Tom 1001 male 98 3 Jack 1002 male 95 4 Tim 1002 male 89 class中: id name 1001 一班 1002 二班 1003 三班
3.9.1. 内连接
首先,我们想要查询出所有的学生信息,可以使用下面的语句
SELECT s.id, s.name, s.class_id, s.gender, s.score from Student s # 结果 1 Mary 1001 female 99 2 Tom 1001 male 98 3 Jack 1002 male 95 4 Tim 1002 male 89
接着,如果想在查询结果中显示班级的名称,而班级的名称包含在class表中,student中只包含class_id。
SELECT s.id, s.name, s.class_id, c.name, s.gender, s.score FROM Student s INNER JOIN class c ON s.class_id = c.id # 结果 1 Mary 1001 一班 female 99 2 Tom 1001 一班 male 98 3 Jack 1002 二班 male 95 4 Tim 1002 二班 male 89
总结
- 确定主表,然后使用SELECT ... FROM table1查询
- 确定要连接的表, 使用INNER JOIN table2
- 确定连接条件,使用 ON 条件, 上面的条件表示student的id与class的id连接起来。
- 可选:增加where子句, order by子句。
3.9.2. 外连接
包括LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN
LEFT OUTER JOIN 会返回左表都存在的行,自动把右表不存在的列填充为NULL。返回左表中所有记录和右表中连接字段相等的记录。
select s.id, s.name, s.gender, s.score, c.name from class c
left join student s
ON c.id = s.class_id
结果如下:
1 mary female 99 一班
2 Tom male 98 一班
3 Jack male 95 二班
4 Tim male 89 二班
三班从上面可以看出,左表是class,右表是student,此时会返回class中所有记录,包含一班,二班,三班,而右表是student,此时可以发现右表中没有三班,此时对应的就会填充为NULL。
RIGHT OUTER JOIN则返回右表都存在的行,如果有一行在右表中存在,而左表中不存在,此时就以NULL填充剩下字段。
FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL。返回两张表的并集。
select s.id, s.name, s.gender, s.score, c.name from student s
right join class c
ON c.id = s.class_id
1 mary female 99 一班
2 Tom male 98 一班
3 Jack male 95 二班
4 Tim male 89 二班
三班 从结果可以看出,左表是student,右表是class。采用右连接时,此时会显示class中所有记录。class中有一个三班,而student中没有,通过使用右连接,从结果中可以看出,最后一行除了显示“三班”,其余数据为NULL。
4. 插入、删除和更新
4.1. 插入数据
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
INSERT INTO student VALUES (3, 'Jack', 'male', 95, 1002); INSERT INTO student VALUES (4, 'Tim', 'male', 89, 1002);
4.2. 删除一条记录
DELETE FROM table_name
WHERE some_column=some_value
delete from tb_empl where id=1;
4.3. 更新记录
UPDATE table_name
SET column1=value1, column2=value2
WHERE some_column=some_value
UPDATE tb_empl SET name='mary', salary=4500 WHERE id=2;
5. 面试常考的50道SQL题目
参考here
5.1. 创建对应的数据表
CREATE TABLE student( no varchar(4) PRIMARY KEY, name varchar(20) NOT NULL, birth DATE, gender varchar(1) ); CREATE TABLE teacher( no varchar(4) PRIMARY KEY, name varchar(20) NOT NULL ); CREATE TABLE course( no varchar(20) PRIMARY KEY, name varchar(20), tea_no varchar(4), CONSTRAINT tea_course FOREIGN KEY(tea_no) REFERENCES teacher(no) ); CREATE TABLE score( stu_no varchar(4), cour_no varchar(20), score FLOAT, PRIMARY KEY(stu_no, cour_no), CONSTRAINT stu_score FOREIGN KEY(stu_no) REFERENCES student(no), CONSTRAINT cour_score FOREIGN KEY(cour_no) REFERENCES course(no) )
表数据如下图所示: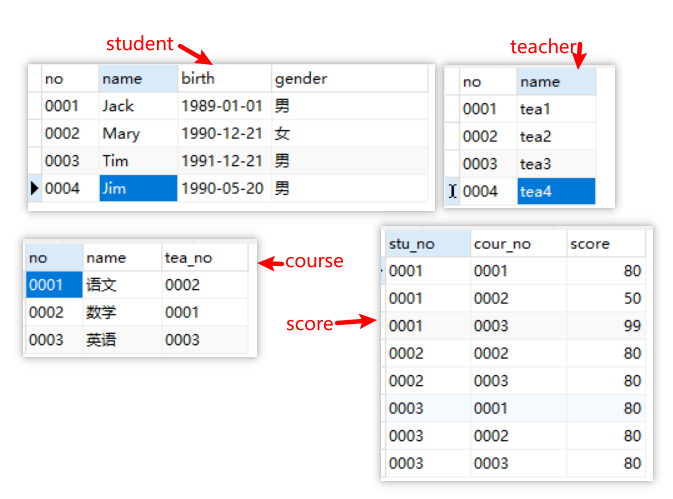
表之间的关系如下图(引用自here):
5.2. 查询
select [查询结果] from table where [查询条件] group by 分组 having order by desc,asc
- 汇总分析
查询某个学生的总成绩 select sum(score) from score where score.stu_no='0001' 查询选择某个课程的学生总数 select count(stu_no) from score where cour_no='0001'
- 分组查询
理解:将数据按照某个字段分组,然后在每个分组类进行一些统计,比如分组的最大值、最小值等。分诅咒分为多少组,查询就会返回多少条记录。
查询各科成绩最高和最低分 select cour_no, max(score), min(score) from score group by cour_no 分析:从“各科”可以看出需要进行分组,分组的依据就是每科目的编号cour_no。查询结果就是首先根据cour_no分组得到0001,0002,0003这3个组,然后在每个组内统计max,min值并输出。 查询每门课程被多少学生选 select cour_no, count(stu_no) from score group by cour_no 分析:从“每门课程”看出需要进行分组。 查询平均成绩大于60分学生的学号和平均成绩 select stu_no, avg(score) from score group by stu_no having avg(score) > 60 #分析:平均成绩表示的是每个学生的平均成绩,因此需要对学生进行分组,分组的字段就是stu_no;接着对分组结果指定条件,比如这里就是平均成绩大于60分。 查询至少选择两门课程的学生学号和课程数量。 select stu_no, count(cour_no) from score group by stu_no having count(cour_no) >= 2
5.3. 复杂查询
- IN查询
具体的过程理解可以参考here.
我的理解:要查询的结果是外查询,比如下面例子中要查询的学号和姓名;子查询和外查询之间的连接字段no和stu_no存在对应关系。
查询课程成绩小于90分学生的学号、姓名
select name,no from student
where no IN (
select stu_no from score
where score>90
)
注意where后面的字段no和子查询中的结果字段stu_no是对应的
查询没有学全所有课的学生的学号和姓名
select no,name from student
where no IN(
select stu_no from score
group by stu_no
having count(cour_no) < (select count(no) from course)
)- exists查询
具体过程可以参考here。查询过程是:首先执行外部查询,得到查询结果。然后根据表中的每一条记录,执行子查询,以此判断where后面的条件是否成立,如果成立则返回true否则返回False。如果返回true,就保留该行结果,如果返回false,则删除该行。
查询课程成绩小于90分学生的学号、姓名
select no,name from student
where exists(
select * from score
where score > 90 and student.no = score.stu_no
)
与IN不同的地方就是将比较条件放到了子查询里面的where子句里面。
也可以使用这种方式实现
select no,name from student,score
where student.no=score.stu_no and score.score>90- 连接查询
查询所有学生的学号、姓名、课程、成绩 select stu.no, stu.name, score.cour_no, score.score from student stu left join score on stu.no = score.stu_no 查询所有学生的学号、姓名、选课数、总成绩 select stu.no, stu.name, count(score.cour_no), sum(score.score) from student stu left join score on stu.no = score.stu_no group by stu.no 可以简单理解为两张表的查询结果先进行笛卡尔积,然后再进行分组。
6. 问题
6.1. INT(11) VARCHAR(255)含义
INT参考here
11表示的是显示宽度,在字段类型为int时,无论显示宽度设置为多少,int类型能够存储的最大值和最小值永远是固定的。
比如:int(1),int(5),int(10),这里的1和5和10 只是显示宽度,即如果我存储了一个9, 则在mysql中,其实int(1)的字段存储的是9,而int (5)存储的是00009,而int(10)存储的是00000000009.
VARCHAR参考here
VARCHAR(M) M表示数据所允许保存的字符串的最大长度。如果分配给该列的值超过M,则对值进行裁剪以使其适合。如果被裁掉的字符是空格,则会产生一条警告。如果裁剪非空格字符,则会造成错误。

