
AIGC时代算法工程师的面试秘籍(第二十式)3.1万字内容
写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,增强技术基本面。也欢迎大家提出宝贵的优化建议,一起交流学习💪
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
Rocky最新发布Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章,点击链接直达干货知识:https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期阅读《三年面试五年模拟》文章的时候了!本周期共更新了80多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:**https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main**,本周期更新的80+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第二十式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年8月5号-2024年8月18号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
当然的,本项目中的内容难免有疏漏与错误之处,欢迎大家在文末评论进行补充优化,Rocky将及时更新完善到Github上!
希望《三年面试五年模拟》能陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy:
正文开始
目录先行
AI绘画基础:
-
Midjourney的提示词格式是什么样的?
-
Stable Diffusion 3中数据标签工程的具体流程是什么样的?
AI视频基础:
-
为什么说Sora等AI视频大模型具备世界模拟器(world simulator)的潜质?
-
AI视频领域的数据工程是什么样的?
深度学习基础:
-
什么是3D卷积?
-
深度学习中图像数据和文本数据的本质区别是什么?
机器学习基础:
-
介绍一下机器学习中的目标函数、代价函数和损失函数的概念
-
KL散度和交叉熵的区别是什么?
Python编程基础:
-
介绍一下如何使用Python中的flask库搭建AI服务
-
python中对透明图的处理大全
模型部署基础:
-
什么是稀疏模型?
-
模型量化有哪些主流的方法?
计算机基础:
-
Linux中如何创建软连接?
-
Linux中如何查看CPU的使用率?
开放性问题:
-
AIGC、传统深度学习、自动驾驶这三个方向上有哪些可以超越周期沉淀下来的技术?
-
AIGC、传统深度学习、自动驾驶这三个方向上有哪些可以超越周期沉淀下来的业务逻辑?
AI绘画基础
【一】Midjourney的提示词格式是什么样的?
Midjourney的整体提示词撰写逻辑可以遵循:风格(Style)+ 主题(Subject)+ 布景(Setting)+ 构图(Composition)+ 灯光(Lighting)+ 附加信息(Additional Info)这几个维度,我们可以从这几个维度入手,对提示词进行扩写、优化、完善:
- 风格:赛博朋克风格的照片(Cyberpunk style photos)
- 主题:一名穿着白色太空服的宇航员,头盔面罩反射着星星(An astronaut in a white space suit, helmet visor reflecting stars)
- 背景:站在星空中可见地球的月球上(Standing on a moon with Earth visible in the starry sky)
- 构图:以宇航员为中心,地球为背景(Astronaut centered, Earth in the background)
- 照明:明亮的阳光和柔和的月光反射(Bright sunlight with soft moonlight reflections)
- 附加信息:附近的月球岩石和小陨石坑(Moon rocks and small craters nearby)
下面是用上述提示词在Midjourney V6和NIJI V6生成的图像示例:

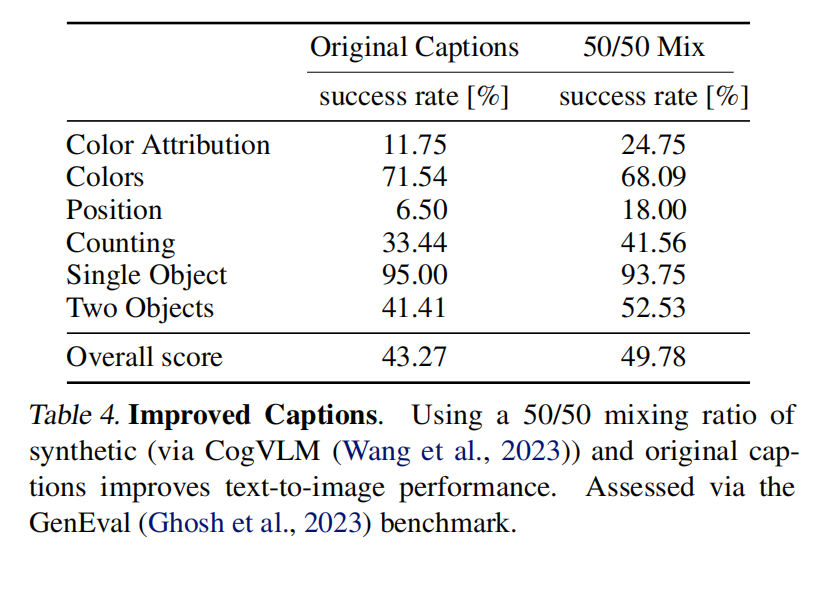
【二】Stable Diffusion 3中数据标签工程的具体流程是什么样的?
目前AI绘画大模型存在一个很大的问题是模型的文本理解能力不强,主要是指AI绘画大模型生成的图像和输入文本Prompt的一致性不高。举个例子,如果说输入的文本Prompt非常精细复杂,那么生成的图像内容可能会缺失这些精细的信息,导致图像与文本的内容不一致。这也是AI绘画大模型Prompt Following能力的体现。
产生这个问题归根结底还是由训练数据集本身所造成的,更本质说就是图像Caption标注太过粗糙。
SD 3借鉴了DALL-E 3的数据标注方法,使用多模态大模型CogVLM来对训练数据集中的图像生成高质量的Caption标签。
目前来说,DALL-E 3的数据标注方法已经成为AI绘画领域的主流标注方法,很多先进的AI绘画大模型都使用了这套标签精细化的方法。
这套数据标签精细化方法的主要流程如下:
- 首先整理数据集和对应的原始标签。
- 接着使用CogVLM多模态大模型对原始标签进行优化扩写,获得长Caption标签。
- 在SD 3的训练中使用50%的长Caption标签+50%的原始标签混合训练的方式,提升SD 3模型的整体性能,同时标签的混合使用也是对模型进行正则的一种方式。
具体效果如下所示:
AI视频基础
【一】为什么说Sora等AI视频大模型具备世界模拟器(world simulator)的潜质?
Sora能够根据文本提示词生成逼真或富有创意的场景视频,展现出强大的模拟物理世界的潜力。
OpenAI一直以来有一个宏大愿景:开发出能够让计算机理解我们物理世界的AI算法技术,目前最有可能的技术之一就是AIGC模型。
也正因此,Sora的技术报告中对Sora的定位正是“作为世界模拟器的视频生成模型”。
当前世界的物理信息与数字信息都呈爆发式增长,如此庞大的信息量,包括图像、视频、文本、语音、3D等多种模态,我们需要为AIGC时代之后即将到来的元宇宙初级阶段与AGI初级阶段构建一个AI模型基底,来理解上述的多模态信息,能够有逻辑的分析表达这些信息。
**因此Rocky也认为,AIGC模型是朝向这个目标迈进的最有希望的技术之一。**正如理查德·费曼的一句名言:
我所无法创造的,我也不能理解。
这句话的潜台词就是要真正理解一个事物,我们就需要去创造它。
这正与AIGC时代的核心思想耦合,我们要训练一个AIGC模型,我们首先要构建海量的数据集库,然后配置充足算力去训练AIGC模型去创造生成无穷无尽的内容。
Sora等AI视频大模型是能够理解和模拟现实世界的模型基础,是AI技术向前迈进的重要一步,2024年也将成为AIGC时代早期的一个重要时间节点。
总的来说,Rocky认同OpenAI乃至AI行业的这个愿景与观点,未来的元宇宙时代和AGI时代,以AI视频大模型为基座的多模态AI会给我们创造出无穷无尽的价值。
【二】AI视频领域的数据工程是什么样的?
不管是传统深度学习时代,还是现在的AIGC时代,数据质量都是决定AI模型性能上限的关键一招,在AI视频领域也不例外。
所以在AI视频数据的处理优化上,不管投入多少都是有价值的,因为这是AI模型这个黑盒系统中反馈最为显著的优化方式。
接下来,Rocky以经典的AI视频数据处理工作流为例,向大家详细介绍我们该如何制作出高质量的AI视频数据。
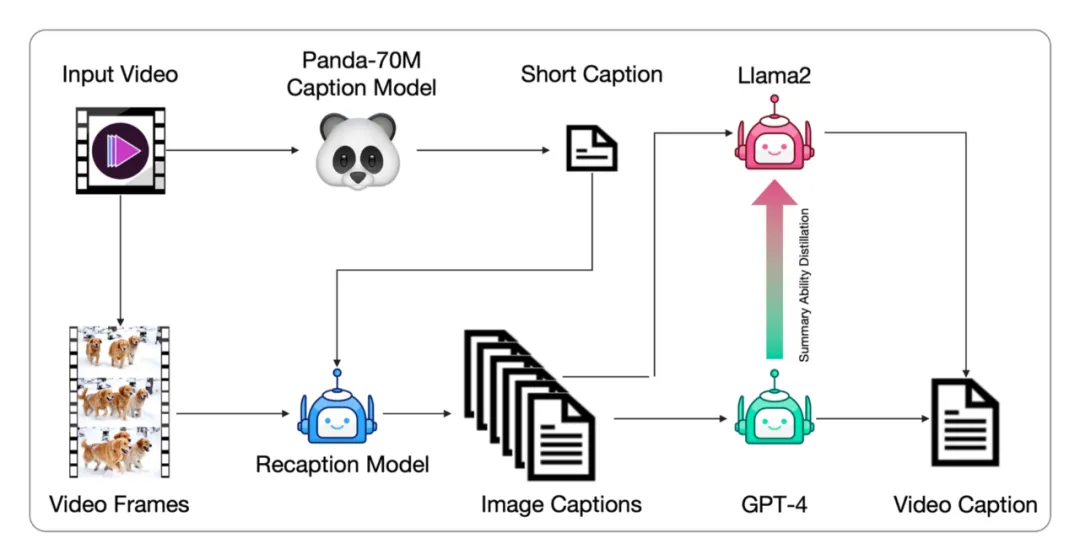 AI视频大模型的训练数据必须是经过筛选的高质量视频数据集,才能让AI视频达模型深刻学习真实世界内容。
AI视频大模型的训练数据必须是经过筛选的高质量视频数据集,才能让AI视频达模型深刻学习真实世界内容。
首先,我们需要识别和排除低质量视频,如过度编辑、运动不连贯、质量低下、讲座式、文本主导和屏幕噪声等视频。我们可以通过基于video-llama训练的视频过滤器来筛选视频数据。同时基于光流计算和美学分数等指标,动态调整阈值来确保视频数据集的质量。
接着,我们需要对视频数据进行标注,由于视频数据通常没有对应的文本描述,同时现有的视频字幕较短,无法全面描述视频的内容。所以需要从生成图像字幕到生成视频字幕的完整工作流,并微调端到端的视频字幕模型以获得更详细的字幕标签。
整体的标注工作流程如下:
- 将视频数据输入Panda-70M模型(Caption Model)先生成简短的字幕标注(Short Caption)。
- 再将视频数据逐帧(Video Frames)和简短的字幕标注一起输入到CogView3模型(Recaption Model)中,生成密集详细的每一帧图像字幕标签。
- 然后使用GPT-4模型对这些图像字幕标签进行总结,生成最终的视频数据标签。与此同时,基于GPT-4的总结标签微调训练Llama 2模型,来为GPT-4分担压力,加速视频数据集完整字幕标签的生成。
深度学习基础
【一】什么是3D卷积?
3D卷积(3D Convolution)是一种用于处理三维数据的卷积运算。与我们常见的2D卷积不同,3D卷积不仅在图像的宽和高两个空间维度上滑动,还在第三个维度上滑动,通常是时间或深度维度。因此,3D卷积通常用于处理如视频、医学影像(如MRI或CT扫描)或任何具有时间、深度信息的三维数据。
3D卷积的基本原理
要理解3D卷积的原理,我们可以从2D卷积入手。假设我们有一个2D卷积核(kernel),它在图像上滑动,生成一个特征图(Feature Map)。这个过程可以类比为在图片上用滤镜移动,提取特定的特征,例如边缘、纹理等。
现在,想象一下,我们不仅在图像的宽度和高度方向滑动卷积核,还在第三个维度上滑动,这个维度可以是时间(如视频中的帧)、深度(如CT扫描中的层)、或者颜色通道的组合。
3D卷积的过程
-
输入数据:
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
(帧数, 高度, 宽度),或一个立体图像(如3D医疗图像)表示为(深度, 高度, 宽度)。
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
-
卷积核(Filter/Kernels):
- 3D卷积核是一个三维的小块。例如,一个
的卷积核在三个维度上分别有3个单元。
- 卷积核在输入数据的三个维度上滑动,在每一个位置进行点积运算(每个元素相乘再整体相加),生成一个输出值。
- 3D卷积核是一个三维的小块。例如,一个
-
输出特征图:
- 输出特征也是一个三维特征图,它记录了卷积核在输入数据上每个位置滑动时的运算结果。输出的深度由输入数据的深度和卷积核的深度决定。
类比:用模具制作巧克力
想象一下,我们在制作巧克力,模具就是我们的卷积核。我们有一个厚厚的巧克力板(3D输入数据),你要在这块板上用模具压出不同形状的巧克力(输出特征图)。
-
2D卷积:就像在一块平面的巧克力上用模具压出形状,我们只能在平面上移动模具(左右、上下),每次我们都会得到一个平面巧克力的形状。
-
3D卷积:现在我们不仅可以在平面上移动模具,还可以把模具往巧克力的厚度方向压进去。这样,我们每次压出的是一个立体的巧克力块。这块立体巧克力反映了我们在厚度方向(如时间、深度)上也进行了一次处理。
3D卷积的应用场景
-
AI视频领域:
- 在AI视频领域中,3D卷积的作用非常明显,Sora、CogVideoX等主流AI视频大模型中都用到了3D卷积。视频数据通常是多个连续的帧序列,通过在时间维度上进行卷积,AI视频模型可以捕捉到动作的动态特征。
-
医学影像:
- 在医学影像中,如MRI或CT扫描,3D卷积可以在扫描的多个切片上滑动,以捕捉人体内部结构的三维特征,这对于诊断和分析非常重要。
-
人体姿态估计:
- 3D卷积可以用于从多帧图像中提取人体的姿态,帮助模型理解姿态变化和动作。
3D卷积的计算公式
3D卷积的输入通常是一个四维张量,形状为 (D, H, W, C),其中:
D是深度(例如视频中的帧数或医学图像中的切片数)。H是高度。W是宽度。C是通道数(例如,RGB图像的通道数为3)。
假设我们有一个输入张量 X,其形状为 (D_in, H_in, W_in, C_in),其中 C_in 是输入的通道数。我们还有一个卷积核 W,其形状为 (D_k, H_k, W_k, C_in, C_out),其中 C_out 是输出的通道数。
计算过程步骤如下:
-
滑动卷积核:
- 卷积核
W在输入张量X上按步长(stride)滑动。在每个位置,卷积核的每个元素与对应位置的输入数据相乘,并将这些乘积相加得到一个输出值。
- 卷积核
-
点积运算:
-
在每个滑动位置,对输入张量与卷积核进行点积运算。具体地,对于某个位置
(i, j, k)的输出值,计算公式为:其中:
Y(i, j, k, m)是输出张量在位置(i, j, k)和通道m上的值。X(i+d, j+h, k+w, c)是输入张量X在位置(i+d, j+h, k+w)和通道c上的值。W(d, h, w, c, m)是卷积核W在位置(d, h, w)和输入通道c、输出通道m上的权重。
-
-
应用偏置:
-
对于每个输出通道,可以添加一个偏置
b[m],使得最终的输出为:
-
-
输出张量:
- 经过上述操作后,得到的输出张量
Y的形状为(D_out, H_out, W_out, C_out),其中D_out、H_out和W_out分别是深度、高度和宽度方向上的输出尺寸。
- 经过上述操作后,得到的输出张量
举例说明:
假设我们有一个输入张量 X,其形状为 (4, 4, 4, 1),即深度、高度、宽度均为4,且有一个输入通道。我们有一个卷积核 W,其形状为 (2, 2, 2, 1, 1),即大小为2x2x2的立方体卷积核,有1个输入通道和1个输出通道。步长为1,无填充(padding)。
-
卷积核在输入张量上滑动:
- 卷积核首先覆盖输入张量的前2x2x2部分,与这部分的输入数据进行点积运算,得到一个输出值。
- 然后,卷积核滑动到下一个位置,重复上述过程,直到覆盖所有可能的位置。
-
计算每个位置的输出:
-
例如,对于第一个位置(顶点)上的输出值,计算公式为:
-
-
得到最终输出:
- 经过所有位置的计算后,得到的输出张量
Y的形状为(3, 3, 3, 1)。
- 经过所有位置的计算后,得到的输出张量
3D卷积的优缺点
优点:
- 能够捕捉到输入数据的三维特征,尤其适合处理视频数据和3D图像数据。
- 能够捕捉时间维度(或深度维度)的变化,适用于动态特征提取。
缺点:
- 计算复杂度更高,训练时间更长。
- 需要更多的内存和计算资源。
【二】深度学习中图像数据和文本数据的本质区别是什么?
从深度学习的角度来看,图像数据和文本数据有许多本质上的区别。这些区别源于图像和文本的不同性质,以及它们在实际应用中的不同处理方式。
1. 数据表示方式
图像数据:
- 像素表示:图像是通过像素网格表示的,每个像素通常包含颜色信息。对于灰度图像,一个像素表示一个亮度值;对于彩色图像(如RGB图像),每个像素由三个通道(红、绿、蓝)组成。
- 高维度:图像数据是二维的(宽度×高度),或者在彩色图像中是三维的(宽度×高度×颜色通道)。
文本数据:
- 字符/单词表示:文本是由字符或单词序列组成的,具有一维结构。文本的数据表示通常是一个序列,这个序列可以是字符序列(如 "hello")或者单词序列(如 "hello world")。
- 离散性:文本是离散的,单词与单词之间的关联性在序列中体现,但单词本身并不具有连续性(不像图像中的像素)。
2. 数据的结构
图像数据:
- 空间结构:图像具有明确的空间结构,邻近像素之间通常有很强的相关性。例如,一张人脸图像中,眼睛和鼻子的像素往往靠得很近,且颜色和纹理上也会有一定的连续性。
- 局部性:图像的局部区域通常包含有用的信息,某个特定区域的特征可以代表整个图像的一部分内容(如眼睛可以代表人脸)。
文本数据:
- 顺序结构:文本是由顺序结构决定的,单词的顺序非常重要,不同的顺序可能表达完全不同的含义(如 "I love you" 和 "You love I")。
- 依赖性:文本中的单词或字符之间具有长距离依赖性。例如,在一句话中,句首的主语可能与句尾的动词或宾语紧密相关。
3. 数据处理方式
图像数据:
- 卷积操作:图像通常通过卷积操作来处理,卷积神经网络(CNN)是处理图像的主要模型结构。CNN利用了图像的局部性,通过共享权重的卷积核提取图像的特征。
- 数据增强:为了增加数据的多样性,图像通常会进行数据增强,如旋转、裁剪、翻转、颜色调整等。这些操作不会改变图像的标签,但会丰富训练数据。
文本数据:
- 嵌入表示:文本数据通常先转化为嵌入表示(如词嵌入或字符嵌入),即将离散的单词或字符映射到连续的向量空间中。这些向量可以捕捉单词之间的语义关系。
- 序列建模:处理文本时,序列模型(如Transformer、RNN、LSTM等)常用于捕捉文本的顺序依赖性。模型需要记住前面的上下文来正确理解后面的内容。
4. 应用场景
图像数据:
- 图像生成:AIGC时代的图像生成任务等。
- 图像分类:识别图像中的主体物体并分类,如识别猫、狗等。
- 目标检测:在图像中检测出目标物体的位置和类别,如自动驾驶中的行人检测。
- 图像分割:将图像划分为不同的区域,每个区域代表不同的类别,如医学图像中的器官分割。
文本数据:
- 文本对话:AIGC时代的文本对话、问答等任务。
- 自然语言处理(NLP):涵盖了文本分类、情感分析、机器翻译、自动摘要、问答系统等任务。
- 文本生成:基于给定的上下文生成自然语言文本,如聊天机器人或写作辅助工具。
- 语义分析:理解文本的深层含义,如分析文章的主题或情感倾向。
机器学习基础
【一】介绍一下机器学习中的目标函数、代价函数和损失函数的概念
在机器学习中,目标函数(Objective Function)、代价函数(Cost Function)和损失函数(Loss Function)是几个非常重要的概念。
- 损失函数(Loss Function):评估单个样本的误差,是模型预测与真实值之间差异的度量。
- 代价函数(Cost Function):评估整个模型在所有训练样本上的整体误差,是所有损失函数的平均值或总和。
- 目标函数(Objective Function):包括代价函数和其他优化目标(如正则化项),指导模型的整体优化过程。
1. 损失函数(Loss Function)
定义
损失函数用于衡量单个训练样本的预测值与真实值之间的误差。它度量了模型对单个样本的预测效果。
数学表示
对于一个单一训练样本 ,其损失函数
可以表示为:
其中:
是模型的预测值。
是样本的真实值。
是用于度量预测值和真实值差异的损失函数。
常见损失函数
- 均方误差(Mean Squared Error, MSE):
- 对数损失(Log Loss):
- 绝对误差(Mean Absolute Error, MAE):
2. 代价函数(Cost Function)
定义
代价函数是一个整体的度量,用于评估整个模型的性能。它通常是所有训练样本的损失的平均值或总和。代价函数反映了模型在所有训练数据上的整体表现。
数学表示
假设我们有一个包含 个样本的数据集,每个样本的损失函数为
。那么代价函数
可以表示为:
其中:
表示模型的参数。
是第
个样本的损失函数。
作用
代价函数用于评估整个模型在训练集上的整体误差,并作为优化算法的目标。模型训练的目标是通过调整参数 来最小化代价函数
。
3. 目标函数(Objective Function)
定义
目标函数是一个更广义的概念,它不仅包括代价函数,还可以包括正则化项或其他需要优化的目标。目标函数的目的是指导模型的优化过程,确保模型不仅在训练集上表现良好,还具备良好的泛化能力。
数学表示
目标函数可以表示为代价函数和正则化项的组合:
其中:
是代价函数。
是正则化系数,用于控制正则化项的影响。
是正则化项,用于防止过拟合。
作用
目标函数用于指导模型的整体优化过程。通过最小化目标函数,可以确保模型在训练数据和新数据上都表现良好。
三者的关系与区别
-
损失函数(Loss Function):
- 衡量单个样本的误差。
- 是代价函数的组成部分。
-
代价函数(Cost Function):
- 衡量所有训练样本的整体误差(通常是损失函数的平均值或总和)。
- 用于评估模型的整体性能。
-
目标函数(Objective Function):
- 包括代价函数和其他优化目标(如正则化项)。
- 指导模型的整体优化过程。
通俗易懂的示例讲解
假设我们有一个线性回归模型,目标是预测房价。数据集包含三个样本,每个样本的损失函数为均方误差(MSE)。具体如下:
- 样本1:真实房价
,预测房价
- 样本2:真实房价
,预测房价
- 样本3:真实房价
,预测房价
计算每个样本的损失函数:
计算代价函数(均方误差的平均值):
假设我们加上L2正则化项,正则化项 计算如下:
最终目标函数为:
【二】KL散度和交叉熵的区别是什么?
KL散度(Kullback-Leibler Divergence)和交叉熵(Cross-Entropy)是机器学习中用于衡量概率分布之间差异的两个重要概念。
KL散度
定义
KL散度是一种用于衡量两个概率分布 和
之间差异的非对称度量。它表示分布
与分布
在信息上的不同。公式如下:
对于连续分布则如下所示:
特性
- 非对称:
- 非负性:
,且当且仅当
时等于0
- 度量了信息损失:
可以被理解为使用分布
近似分布
时的信息损失
交叉熵
定义
交叉熵用于衡量一个分布 相对于目标分布
的不确定性。公式如下:
对于连续分布则如下所示:
特性
- 包含了熵(Entropy):
,其中
是分布
- 非负性:
- 衡量不确定性: 交叉熵越小,表示分布
KL散度和交叉熵的区别
数学关系
交叉熵可以表示为熵和KL散度的和:
其中:
实际应用
- KL散度: 常用于变分推断、信息论和测量两个概率分布之间的差异。
- 交叉熵: 常用于分类任务中的损失函数(例如逻辑回归、神经网络中的Softmax损失),用于评估模型预测与真实分布之间的差异。
具体例子
假设我们有一个二分类问题,其中真实分布 和预测分布
如下:
- 真实分布
- 预测分布
我们计算交叉熵和KL散度:
交叉熵
KL散度
通过计算,我们可以量化预测分布 相对于真实分布
的不确定性和信息损失。
Python编程基础
【一】介绍一下如何使用Python中的flask库搭建AI服务
搭建一个简单的AI服务,我们可以使用 Flask 作为 Web 框架,并结合一些常用的Python库来实现AI模型的加载、推理等功能。这个服务将能够接收来自客户端的请求,运行AI模型进行推理,并返回预测结果。
下面是一个完整的架构和详细步骤,可以帮助我们搭建一个简单明了的AI服务。
1. AI服务结构
首先,我们需要定义一下项AI服务的文件结构:
ai_service/
│
├── app.py # 主 Flask 应用
├── model.py # AI 模型相关代码
├── requirements.txt # 项目依赖
└── templates/
└── index.html # 前端模板(可选)
2. 编写模型代码 (model.py)
在 model.py 中,我们定义 AI 模型的加载和预测功能。假设我们有一个训练好的 PyTorch 模型来识别手写数字(例如使用 MNIST 数据集训练的模型)。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
class AIModel:
def __init__(self, model_path):
self.model = SimpleCNN()
self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
self.model.eval()
def predict(self, image_array):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
image_tensor = transform(image_array).unsqueeze(0) # 添加批次维度
with torch.no_grad():
output = self.model(image_tensor)
prediction = output.argmax(dim=1, keepdim=True)
return prediction.item()
3. 编写 Flask 应用 (app.py)
在 app.py 中,我们使用 Flask 创建一个简单的 Web 应用,可以处理图像上传和模型推理请求。
from flask import Flask, request, jsonify, render_template
from model import AIModel
from PIL import Image
import io
# 创建一个AI服务的APP对象
app = Flask(__name__)
# 实例化模型,假设模型保存为 'model.pth'
model = AIModel('model.pth')
@app.route('/')
def index():
return render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict():
# 检查是否有文件上传
if 'file' not in request.files:
return jsonify({'error': 'No file part'})
file = request.files['file']
if file.filename == '':
return jsonify({'error': 'No selected file'})
if file:
# 将图像转换为PIL格式
img = Image.open(file).convert('L') # 假设灰度图像
img = img.resize((28, 28)) # 调整到模型输入尺寸
# 调用模型进行预测
prediction = model.predict(img)
# 返回预测结果
return jsonify({'prediction': int(prediction)})
if __name__ == '__main__':
app.run(debug=True)
4. 运行服务
在命令行中运行以下命令启动 Flask 应用:
python app.py
默认情况下,Flask 应用将运行在 http://127.0.0.1:5000/。我们可以打开浏览器访问这个地址并上传图像进行测试。
5. 完整流程讲解
- 前端 (index.html):用户通过浏览器上传图像文件。
- Flask 路由 (
/predict):接收上传的图像,并将其传递给 AI 模型进行预测。 - AI 模型 (
model.py):加载预训练的模型,处理图像并返回预测结果。 - 响应返回:Flask 将预测结果以 JSON 格式返回给客户端,用户可以看到预测的类别或其他结果。
6. 细节关键点讲解
上面代码中的@app.route('/predict', methods=['POST']) 是 Flask 中的路由装饰器,用于定义 URL 路由和视图函数。它们决定了用户访问特定 URL 时,Flask 应用程序如何响应。
@app.route('/predict', methods=['POST']) 的作用
@app.route('/predict', methods=['POST'])的含义:- 这是一个路由装饰器,Flask 使用它来将
/predict路由映射到一个视图函数。 '/predict'表示路径/predict,即当用户访问http://127.0.0.1:5000/predict时,这个路由会被触发。methods=['POST']指定了这个路由只接受POST请求。POST请求通常用于向服务器发送数据,例如表单提交、文件上传等。与之对应的GET请求则用于从服务器获取数据。
- 这是一个路由装饰器,Flask 使用它来将
作用:
- 当客户端(通常是浏览器或其他应用程序)发送一个
POST请求到http://127.0.0.1:5000/predict,并附带一个文件时,Flask 会调用predict()函数来处理这个请求。 predict()函数接收上传的图像文件,对其进行预处理,然后将图像传递给预训练的 AI 模型进行预测。- 预测结果以 JSON 格式返回给客户端,客户端可以使用这些数据来进行后续操作,如显示预测结果等。
【二】python中对透明图的处理大全
判断输入图像是不是透明图
要判断一个图像是否具有透明度(即是否是透明图像),我们可以检查图像是否包含 Alpha 通道。Alpha通道是用来表示图像中每个像素的透明度的通道。如果图像有 Alpha 通道,则它可能是透明图像。我们可以用下面的Python代码来判断图像是否是透明图:
from PIL import Image
def is_transparent_image(image_path):
# 打开图像
img = Image.open(image_path)
# 检查图像模式是否包含Alpha通道。`RGBA` 和 `LA` 模式包含 Alpha 通道,`P` 模式可能包含透明度信息(通过 `img.info` 中的 `transparency` 属性)。
if img.mode in ('RGBA', 'LA') or (img.mode == 'P' and 'transparency' in img.info):
# 如果图像有alpha通道,逐个像素检查是否存在透明部分
alpha = img.split()[-1] # 获取alpha通道
# 如果图像中任何一个像素的alpha值小于255,则图像是透明的
if alpha.getextrema()[0] < 255:
return True
# 如果图像没有Alpha通道或者所有像素都是不透明的
return False
# 示例路径,替换为我们的图像路径
image_path = "/本地路径/example.png"
if is_transparent_image(image_path):
print("这是一个透明图像。")
else:
print("这是一个不透明图像。")
判断输入图像是否是透明图,将透明图的透明通道提取,剩余部分作为常规图像进行处理
要判断输入图像是否是透明图,并且将透明部分分离,保留剩余部分用于后续处理,我们可以使用下面的Python代码完成这项任务:
from PIL import Image
def process_image(image_path, output_path):
# 打开图像
img = Image.open(image_path)
# 检查图像模式是否包含Alpha通道
if img.mode in ('RGBA', 'LA') or (img.mode == 'P' and 'transparency' in img.info):
# 如果图像有alpha通道,逐个像素检查是否存在透明部分
alpha = img.split()[-1] # 获取alpha通道
# 如果图像中任何一个像素的alpha值小于255,则图像是透明的
if alpha.getextrema()[0] < 255:
print("这是一个透明图像。")
else:
print("这是一个不透明图像。")
img.save(output_path)
return img
# 将图像的透明部分分离出来
# 分离alpha通道。如果图像是透明图像,将其拆分为红、绿、蓝和 Alpha 通道(透明度)。
r, g, b, alpha = img.split() if img.mode == 'RGBA' else (img.convert('RGBA').split())
# 创建一个完全不透明的背景图像
bg = Image.new("RGBA", img.size, (255, 255, 255, 255))
# 将原图像的透明部分分离
img_no_alpha = Image.composite(img, bg, alpha)
# 将结果保存或用于后续处理
img_no_alpha.save(output_path)
print(f"透明部分已分离,图像已保存为: {output_path}")
return img_no_alpha # 返回没有透明度的图像以便后续处理
else:
print("这不是一个透明图像,直接进行后续处理。")
# 直接进行后续处理
img.save(output_path)
return img
# 示例路径
image_path = "/本地路径/example.png"
output_path = "/本地路径/processed_image.png"
# 处理图像
processed_image = process_image(image_path, output_path)
将常规图像转换成透明图
要将一张普通图片转换成带有透明背景的图片,下面是实现这个功能的代码示例:
from PIL import Image
def convert_to_transparent(image_path, output_path, color_to_transparent):
# 打开图像
img = Image.open(image_path)
# 确保图像有alpha通道
img = img.convert("RGBA")
# 获取图像的像素数据
datas = img.getdata()
# 创建新的像素数据列表
new_data = []
for item in datas:
# 检查像素是否与指定的颜色匹配
if item[:3] == color_to_transparent:
# 将颜色变为透明
new_data.append((255, 255, 255, 0))
else:
# 保留原来的颜色
new_data.append(item)
# 更新图像数据
img.putdata(new_data)
# 保存带透明背景的图像
img.save(output_path, "PNG")
print(f"图像已成功转换为透明背景,并保存为: {output_path}")
# 示例路径,替换为你的图像路径和颜色
image_path = "/本地路径/example.jpg"
output_path = "/本地路径/transparent_image.png"
color_to_transparent = (255, 255, 255) # 白色背景
# 将图片转换成透明背景
convert_to_transparent(image_path, output_path, color_to_transparent)
读取透明图,不丢失透明通道信息
在 Python 中使用 OpenCV 或 Pillow 读取图像时,可以确保不丢失图像的透明通道。以下是如何使用这两个库读取带有透明通道的图像的代码示例。
使用 OpenCV 读取带透明通道的图像
默认情况下,OpenCV 读取图像时可能会丢失透明通道(即 Alpha 通道)。为了确保保留透明通道,我们需要使用 cv2.IMREAD_UNCHANGED 标志来读取图像。
import cv2
# 读取带透明通道的图像
image_path = "/本地路径/example.png"
img = cv2.imread(image_path, cv2.IMREAD_UNCHANGED)
# 检查图像通道数,确保Alpha通道存在
if img.shape[2] == 4:
print("图像成功读取,并且包含透明通道(Alpha)。")
else:
print("图像成功读取,但不包含透明通道(Alpha)。")
使用 Pillow 读取带透明通道的图像
在Python中使用Pillow 库在读取图像时默认保留透明通道,因此我们可以直接使用 Image.open() 读取图像并保留 Alpha 通道:
from PIL import Image
# 读取带透明通道的图像
image_path = "/本地路径/example.png"
img = Image.open(image_path)
# 确保图像是 RGBA 模式(包含透明通道)
if img.mode == "RGBA":
print("图像成功读取,并且包含透明通道(Alpha)。")
else:
print("图像成功读取,但不包含透明通道(Alpha)。")
PIL格式图像与OpenCV格式图像互相转换时,保留透明通道
要将 Pillow(PIL)格式的图像与 OpenCV 格式的图像互相转换,并且保留透明通道(即 Alpha 通道),我们可以按照以下步骤操作:
1. 从 Pillow 转换为 OpenCV
from PIL import Image
import numpy as np
import cv2
# 打开一个Pillow图像对象,并确保图像是RGBA模式
pil_image = Image.open('input.png').convert('RGBA')
# 将Pillow图像转换为NumPy数组
opencv_image = np.array(pil_image)
# 将图像从RGBA格式转换为OpenCV的BGRA格式
opencv_image = cv2.cvtColor(opencv_image, cv2.COLOR_RGBA2BGRA)
# 现在,opencv_image是一个保留透明通道的OpenCV图像,可以使用cv2.imshow显示或cv2.imwrite保存
cv2.imwrite('output_opencv.png', opencv_image)
2. 从 OpenCV 转换为 Pillow
import cv2
from PIL import Image
# 读取一个OpenCV图像,确保读取时保留Alpha通道
opencv_image = cv2.imread('input.png', cv2.IMREAD_UNCHANGED)
# 将图像从BGRA格式转换为RGBA格式。使用 `cv2.cvtColor` 将图像从 `BGRA` 格式转换为 `RGBA` 格式,因为 `Pillow` 使用的是 `RGBA` 格式。
opencv_image = cv2.cvtColor(opencv_image, cv2.COLOR_BGRA2RGBA)
# 将OpenCV图像转换为Pillow图像
pil_image = Image.fromarray(opencv_image)
# 现在,pil_image是一个保留透明通道的Pillow图像,可以使用pil_image.show()显示或pil_image.save保存
pil_image.save('output_pillow.png')
模型部署基础
【一】什么是稀疏模型?
稀疏模型(Sparse Model)的概念
稀疏模型(Sparse Model)是AI领域的一类模型,它通过减少模型的计算需求和存储需求来提高整体效率和可扩展性。这与传统的密集模型(Dense Model)形成对比,后者通常会使用所有可用的参数和计算资源。稀疏模型利用了一些关键的技术和策略,使得模型在保持或接近原有性能的情况下,大幅减少计算开销。
稀疏模型是深度学习领域的一种重要技术,通过减少模型的计算和存储需求,可以提高模型的效率和可扩展性。稀疏模型的方法多种多样,包括参数剪枝、激活稀疏化、结构化稀疏性以及专家混合模型等。尽管存在实现上的挑战,稀疏模型在处理超大规模数据和模型时具有重要的应用前景,是推动深度学习技术发展的重要方向之一。
为什么需要稀疏模型?
随着AI模型的规模越来越大,尤其是在像 GPT-3 或者基于Transformer架构的大模型的AI任务中,模型的计算和存储需求也急剧增加。这种情况带来了以下挑战:
- 计算资源的高需求:训练和推理大型模型需要大量的计算资源,通常超出了许多实际应用场景的承受能力。
- 高能耗:密集模型的计算过程通常伴随着高能耗,尤其在需要频繁推理的场景中(如实时系统)。
- 模型部署的困难:在内存和计算能力有限的设备上(如移动终端、手机或嵌入式系统),部署大型密集模型可能不切实际。
稀疏模型通过减少激活的参数数量或简化计算过程,能够在满足性能需求的同时减少计算负担。
稀疏模型的主要类型和技术
-
参数稀疏化(Parameter Sparsity):
- 剪枝(Pruning):剪枝是一种常见的稀疏化技术,指的是在训练过程中或训练结束后,移除那些对模型输出影响较小的参数(如权重接近零的连接)。通过剪枝,可以减少网络中参数的数量,使模型更加高效。
- 静态剪枝:在模型训练后进行剪枝,生成稀疏的参数矩阵。
- 动态剪枝:在训练过程中动态地调整网络结构,根据损失函数和梯度信息剪除或重连神经元。
- 量化(Quantization):量化是将模型的浮点数参数转换为低精度的表示形式(如8位整数),从而减少存储需求并加速计算。尽管参数被稀疏化,但量化后的模型仍能保持较好的性能。
- 剪枝(Pruning):剪枝是一种常见的稀疏化技术,指的是在训练过程中或训练结束后,移除那些对模型输出影响较小的参数(如权重接近零的连接)。通过剪枝,可以减少网络中参数的数量,使模型更加高效。
-
激活稀疏化(Activation Sparsity):
- ReLU 和稀疏激活函数:一些激活函数如 ReLU(Rectified Linear Unit)会将负数输入置为零,导致激活的输出值变为零。这种情况下,只有部分神经元被激活(即非零输出),这种稀疏性可以用于优化计算。
- 稀疏编码(Sparse Coding):稀疏编码是指通过将输入数据表示为稀疏向量来进行特征提取或分类。这种技术在自然图像处理中广泛使用,通过稀疏的特征表示来提高模型的效率。
-
结构稀疏化(Structured Sparsity):
- 通道剪枝(Channel Pruning):这是剪枝的一种形式,针对卷积神经网络(CNN)的通道进行稀疏化。它通过删除整组卷积滤波器的输出通道来减少计算量。
- 分组卷积(Grouped Convolution):分组卷积将卷积操作分成多个组,每组操作仅使用部分输入通道。这减少了计算复杂度并在一定程度上引入了稀疏性。
-
专家混合模型(Mixture of Experts, MoE):
- 专家混合(MoE):MoE 是一种高效的稀疏模型结构,其中模型由多个专家(子模型)组成,但在每个推理步骤中,只激活一部分专家来处理给定的输入。这样可以极大地减少每次推理的计算需求。
- 路由机制(Routing Mechanism):MoE 模型使用路由器(Router)来决定哪些专家需要被激活。路由器根据输入数据选择合适的专家,而非所有专家同时工作。
- 专家混合(MoE):MoE 是一种高效的稀疏模型结构,其中模型由多个专家(子模型)组成,但在每个推理步骤中,只激活一部分专家来处理给定的输入。这样可以极大地减少每次推理的计算需求。
稀疏模型的优势
- 高效计算:稀疏模型通过减少不必要的计算步骤来提高计算效率。由于稀疏性,计算资源可以集中在对最终结果最重要的部分上。
- 显存节省:由于参数和激活值的稀疏性,模型需要的显存更少,尤其在需要大量推理的应用中,这一点尤为重要。
- 模型可扩展性:稀疏模型通常更容易扩展,因为随着模型规模的增长,增加的计算需求不会像密集模型那样线性增长。通过稀疏化,超大规模模型也可以在资源受限的环境中运行。
稀疏模型的面临的挑战
- 稀疏性实现的复杂性:尽管稀疏模型理论上可以提高效率,但实现高效的稀疏计算(特别是在硬件层面)并不容易。GPU 等硬件通常对稠密计算进行了优化,稀疏计算的硬件加速还在不断发展中。
- 稀疏性的引入可能影响性能:在某些情况下,过度稀疏化可能导致模型性能的下降。例如,如果剪枝过程中删除了重要的参数连接,模型的表现可能会受到负面影响。
- 训练的复杂性:稀疏模型的训练往往比密集模型更复杂,需要额外的策略来保持稀疏性,同时保持模型的泛化能力。
【二】模型量化有哪些主流的方法?
目前主要的量化方法包括后训练量化、量化感知训练、混合精度量化、训练时量化等。每种方法都有其独特的优点和适用场景,AI开发者可以根据具体的应用需求和硬件环境选择合适的量化策略。
1. 后训练量化(Post-Training Quantization, PTQ)
后训练量化是一种在模型训练完成后,对模型参数和激活进行量化的方法。它不需要在训练期间进行特殊处理,可以直接对已经训练好的模型进行量化。PTQ的方法通常包括以下几种:
a. 静态量化(Static Quantization)
- 原理:静态量化将模型的权重和激活值都量化为低精度格式(如8位整数)。在量化时,首先对模型的输入数据进行统计,以确定激活值的量化范围。然后,根据这个范围将模型中的参数和激活值进行量化。
- 过程:
- 采样一小部分代表性的数据,通过这些数据估计出模型每一层的激活值范围(最小值和最大值)。
- 将模型权重和激活值量化到整数范围(如 int8)。
- 在推理时使用量化后的模型进行推理。
- 优点:由于激活值范围在量化前已知,因此可以实现更高的量化精度。
- 缺点:需要通过代表性数据进行校准,量化后的模型在某些情况下可能会出现精度下降。
b. 动态量化(Dynamic Quantization)
- 原理:动态量化仅在推理过程中对激活值进行量化,而权重在模型加载时就已经量化。推理时,激活值会根据当前的最小值和最大值动态地进行量化。
- 过程:
- 模型权重在加载时被量化。
- 推理过程中,激活值根据实时的最小值和最大值动态量化到整数范围。
- 量化后的激活值参与推理,完成推理后再转换回浮点值。
- 优点:不需要进行数据校准,适用于需要低延迟推理的场景。
- 缺点:由于激活值在每次推理时动态量化,推理的计算开销会略高于静态量化。
c. 权重量化(Weight Quantization)
- 原理:仅对模型的权重进行量化,而激活值仍然保持高精度。这个方法简单直接,只需在模型推理过程中使用量化后的权重即可。
- 优点:实现简单,适合快速降低模型的存储需求。
- 缺点:相比同时量化激活值的模型,推理加速效果较小。
2. 量化感知训练(Quantization-Aware Training, QAT)
量化感知训练是指在模型训练的过程中,模拟量化操作以避免量化误差,从而提升最终量化模型的精度。QAT 通常在模型精度要求较高的场景中使用。
-
原理:在训练过程中,模型的前向传播阶段会插入量化操作,模拟推理时的量化效果,反向传播则基于量化的误差来更新模型参数。这种方式可以让模型在训练时逐渐适应量化带来的精度损失,从而在量化后的推理阶段仍能保持较高的精度。
-
过程:
- 在训练过程中,模型的每一层都会进行模拟量化。虽然权重和激活值在训练时仍然是浮点数表示,但它们的值会被模拟量化。
- 前向传播使用量化后的值进行计算,反向传播则通过浮点数计算误差,更新模型参数。
- 训练结束后,模型权重被量化为低精度格式(如int8),生成量化模型。
-
优点:QAT可以显著减少量化带来的精度损失,特别适合精度要求高的任务。
-
缺点:训练时间较长,计算资源消耗较高,因为每次前向传播和反向传播都需要进行量化模拟。
3. 混合精度量化(Mixed Precision Quantization)
混合精度量化是一种在模型中不同部分使用不同精度表示的方法。一般来说,对于计算敏感的层使用较高精度,而对于计算量大的部分使用较低精度。
-
原理:模型的不同层根据其对最终结果的影响程度,采用不同的量化精度。例如,模型的关键层(如首层卷积、最后的全连接层)可以使用高精度(如浮点数),而其他层使用低精度(如int8)。
-
优点:在保证模型精度的同时,尽量减少计算和存储需求。
-
缺点:实现复杂,需要针对不同模型和任务手动设计或自动搜索最佳的混合精度配置。
4. 训练时量化(Quantization during Training)
训练时量化是一种在训练过程中同时进行权重量化和激活量化的方法。这种方法有些类似于量化感知训练,但更加激进,因为它直接在训练过程中对浮点值进行量化。
-
原理:在训练时,模型参数和激活值都会被量化为低精度表示。整个训练过程就像在低精度硬件上运行一样。这样训练出的模型天然地适应了量化的硬件环境。
-
优点:可以直接得到高精度的量化模型,适合嵌入式设备或其他对资源有严格限制的场景。
-
缺点:训练过程更加复杂,训练稳定性可能较差,需要对量化和反量化的过程进行特别优化。
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】Linux中如何创建软连接?
在 Linux 中,创建软连接(符号链接)的方法非常简单,可以通过 ln 命令来实现。软连接类似于 Windows 系统中的快捷方式,它指向另一个文件或目录,而不占用实际的存储空间。
创建软连接的基本语法
ln -s [目标文件或目录] [软连接名称]
-s:表示创建的是软连接(符号链接),如果不加-s参数,创建的就是硬链接。目标文件或目录:我们想要创建软连接指向的原文件或目录。软连接名称:软连接的名称及路径。
具体示例
-
创建一个文件的软连接:
假设我们有一个文件
/home/user/documents/file.txt,我们想在/home/user/desktop/下创建一个指向这个文件的软连接,命令如下:ln -s /home/user/documents/file.txt /home/user/desktop/file_link.txt这个命令将在
/home/user/desktop/目录下创建一个名为file_link.txt的软连接,指向/home/user/documents/file.txt。 -
创建一个目录的软连接:
如果我们想要创建一个目录的软连接,比如将
/home/user/documents/目录链接到/home/user/desktop/docs_link,命令如下:ln -s /home/user/documents/ /home/user/desktop/docs_link这个命令将在
/home/user/desktop/目录下创建一个名为docs_link的软连接,指向/home/user/documents/目录。
查看软连接
创建软连接后,可以使用 ls -l 命令查看链接的信息。软连接的文件类型在 ls -l 输出中会显示为 l,并且会显示链接指向的目标路径:
ls -l /home/user/desktop/
输出示例:
lrwxrwxrwx 1 user user 20 Jan 1 00:00 file_link.txt -> /home/user/documents/file.txt
lrwxrwxrwx 1 user user 25 Jan 1 00:00 docs_link -> /home/user/documents/
删除软连接
删除软连接与删除普通文件相同,使用 rm 命令即可:
rm /home/user/desktop/file_link.txt
注意:删除软连接并不会删除它指向的目标文件或目录。
【二】Linux中如何查看CPU的使用率?
在 Linux 中,有多种方法可以查看 CPU 的使用率:
- 使用
top命令 - 使用
htop命令 - 使用
mpstat命令 - 使用
sar命令 - 使用
vmstat命令 - 使用
iostat命令 - 使用
dstat命令 - 使用
cat /proc/stat
top和htop:适用于实时监控系统资源使用情况,提供了详细的进程信息和使用率。mpstat、sar、vmstat和iostat:适合进行更细粒度的系统性能分析,可以定期收集和报告系统的 CPU 使用情况。dstat:是一个功能强大的多合一工具,适用于全面的系统资源监控。/proc/stat:提供了最底层的 CPU 使用信息,适合编写自定义脚本进行监控和分析。
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】AIGC、传统深度学习、自动驾驶这三个方向上有哪些可以超越周期沉淀下来的技术?
Rocky认为这是一个非常值得我们持续思考的问题,我们需要从AI技术的宏观角度切入,具备AI技术的大局观,才能有更多成长。
【二】AIGC、传统深度学习、自动驾驶这三个方向上有哪些可以超越周期沉淀下来的业务逻辑?
Rocky认为这是一个非常值得我们持续思考的问题,我们需要从AI业务的宏观角度切入,具备AI业务的大局观,才能有更多成长。
推荐阅读
2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、Transformer核心基础知识,核心网络结构,AIGC时代的Transformer新内涵,各AI领域Transformer的应用落地,Transformer未来发展趋势等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Transformer文章地址:https://zhuanlan.zhihu.com/p/709874399
9、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
10、50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
11、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
12、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
13、其他
[
 查看22道真题和解析
查看22道真题和解析