
面试八股文对校招的用处有多大?网络原理篇
前言 1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
网络原理
网络编程
mysql
redis
服务器
RPG
本文为第七篇,后续会陆续更新。 共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接: https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i 需要的同学自取即可。
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
七、网络原理
01.为什么握手是三次而挥手需要四次
TCP的三次握手是为了建立可靠的连接。具体来说,客户端发送一个SYN包到服务器,表示自己想要建立连接。服务器收到这个包后,回复一个SYN+ACK包,表示自己已经收到请求,并且同意建立连接。最后,客户端再发送一个ACK包,表示自己也已经收到了服务器的回复,并且同意建立连接。
这里之所以要进行三次握手,是因为TCP是面向连接的协议,需要确保双方都正确地接收到了对方的请求,才能建立可靠的连接。通过三次握手的方式,可以确保连接的双方都认可了对方的身份和可用性,从而避免了因为网络延迟等原因导致连接建立失败的情况。
四次挥手是为了关闭连接。具体来说,当客户端想要关闭连接时,发送一个FIN包到服务器,表示自己不再发送数据了。服务器收到这个包后,回复一个ACK包,表示自己已经收到了请求。但是服务器可能还没有发送完自己的数据,所以服务器在发送完数据后,会再次发送一个FIN包,表示自己也不再发送数据了。客户端收到这个包后,回复一个ACK包,表示自己已经收到了服务器的请求,同时也准备关闭连接了。
四次挥手之所以要比三次握手多一次,是因为在关闭连接时,双方都需要确认自己的数据已经全部传输完毕,才能安全地关闭连接。另外,因为TCP具有可靠传输的特点,所以在关闭连接时需要先停止数据的发送,等待对方完成传输后再关闭连接,从而避免数据丢失或被截断。
02.tcp和udp的原理、区别、应用场景
1.TCP
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
- 面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
- 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
- 字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。
2.UDP
用户数据报协议(UDP):UDP(用户数据报协议)是一个简单的面向数据报的传输层协议。
提供的是非面向连接的、不可靠的数据流传输。
UDP不提供可靠性,也不提供报文到达确认、排序以及流量控制等功能。它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。因此报文可能会丢失、重复以及乱序等。但由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
3.TCP优缺点
优点:可靠、稳定
TCP的可靠体现在TCP在传输数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完之后,还会断开连接用来节约系统资源。
缺点:慢,效率低,占用系统资源高,易被攻击
在传递数据之前要先建立连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞机制等都会消耗大量时间,而且要在每台设备上维护所有的传输连接。然而,每个链接都会占用系统的CPU、内存等硬件资源。因为TCP有确认机制、三次握手机制,这些也导致TCP容易被利用,实现DOS、DDOS、CC等攻击。
4.UDP优缺点
优点:快
比TCP稍安全UDP没有TCP拥有的各种机制,是一个无状态的传输协议,所以传递数据非常快,没有TCP的这些机制,被攻击利用的机制就少一些,但是也无法避免被攻击。
缺点:不可靠,不稳定
因为没有TCP的那些机制,UDP在传输数据时,如果网络质量不好,就会很容易丢包,造成数据的缺失。
5.区别
TCP和UDP有如下区别:
- 连接:TCP面向连接的传输层协议,即传输数据之前必须先建立好连接;UDP无连接。
- 服务对象:TCP点对点的两点间服务,即一条TCP连接只能有两个端点;UDP支持一对一,一对多,多对一,多对多的交互通信。
- 可靠性:TCP可靠交付:无差错,不丢失,不重复,按序到达;UDP尽最大努力交付,不保证可靠交付。
- 拥塞控制/流量控制:TCP有拥塞控制和流量控制保证数据传输的安全性;UDP没有拥塞控制,网络拥 塞不会影响源主机的发送效率。
- 报文长度:TCP动态报文长度,即TCP报文长度是根据接收方的窗口大小和当前网络拥塞情况决定的;UDP面向报文,不合并,不拆分,保留上面传下来报文的边界。
- 首部开销:TCP首部开销大,首部20个字节;UDP首部开销小,8字节(源端口,目的端口,数据长度,校验和)。
- 适用场景(由特性决定):数据完整性需让位于通信实时性,则应该选用TCP 协议(如文件传输、重要状态的更新等);反之,保证数据完整性则使用 UDP 协议(如视频传输、实时通信等)。
6.适用场景(网络稳定性要求)
6.1 TCP
TCP:当对网络通讯质量有要求时,比如HTTP、HTTPS、FTP等传输文件的协议, POP、SMTP等邮件传输的协议
对可靠连接有要求时,比如付费、加密数据等等方向都需要依靠TCP
6.2 UDP
UDP:对网络通讯质量要求不高时,要求网络通讯速度要快的场景。
所以主要使用在以下场景:
- 包总量较小的通信(DNS、SNMP)
- 视频、音频等多媒体通信(即时通信)
- QQ就是使用的UDP协议。
- 广播通信
所以,TCP对网络稳定性要求高,而UDP相对弱一些。
03.TCP慢启动,拥塞控制实现
TCP的拥塞控制
一、前言:什么是拥塞?什么是拥塞控制?
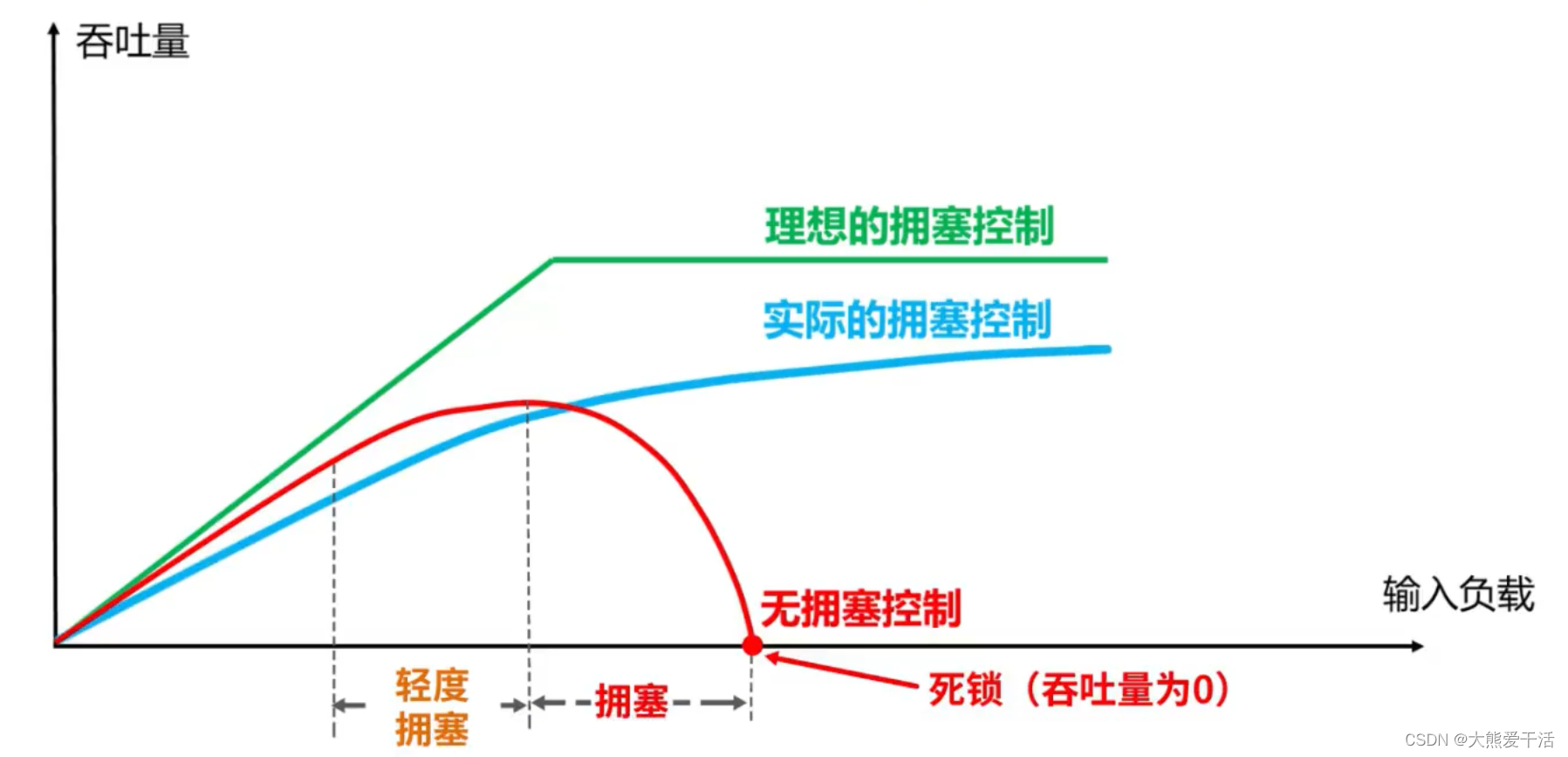
- 拥塞:随着网络中的主机增加其发送速率并使网络变得十分拥挤,此时会经常发生丢包现象,导致网络的传输效率急剧降低。分组的超时重传通常被作为网络拥塞的标志。
- 如果不对网络拥塞进行控制,整个网络的吞吐量将随着输入负荷的增大而下降,降低网络的传输效率,如下图:
二、TCP的4种拥塞控制算法(慢开始、拥塞避免、快重传、快恢复)
- 为了便于讨论做一下假设
- 数据是单方向传送的,另一个方向只传输确认
- 接收方的总是有足够大的缓冲区,因此发送方的发送窗口仅由网络的拥塞程度决定,事实上发送窗口的大小由拥塞窗口和接收方的接收窗口大小共同控制,也即发送窗口 = min[接收窗口, 拥塞窗口];
- 以最大报文段MSS的个数作为讨论单位,而不是以字节为单位
- 发送方维护一个叫做拥塞窗口cwnd(congestion window)的状态变量,其值取决于网络的拥塞状况,动态变化
- 拥塞窗户的维护原则:只要网络没有出现拥塞,cwnd就增大一些;但只要网络出现拥塞,拥塞窗口就减小一些
- 以分组发生超时重传作为发生网络拥塞的依据
- TCP还维护一个慢开始门限ssthresh状态变量
- 当cwnd < ssthresh时,使用慢开始算法
- 当cwnd > ssthresh时,使用拥塞避免算法
- 当cwnd = ssthresh时,既可以使用慢开始算法,也可以使用拥塞避免算法
- 当发生数据正常丢包,但又不是网络拥塞时,使用快重传算法和快恢复算法
- 如何判断是发生了正常丢包而不是网络拥塞呢?
- 当发送方连续接收到3次重复确认时,说明这网络不拥塞,只是正常丢包了
① 慢启动(慢开始) 传输轮次:指把发送窗口内可以发送的数据全部发送并接收到最后一个TCP报文的确认报文这样一个来回

- 通常在一条TCP连接开始时,cwnd被设置为1个MSS(最大报文段),也即cwnd=1
- 该阶段,每当TCP发送方将发送窗口的数据发送完,并顺利接收到所有的确认后,就会将拥塞窗口大小翻倍,也即慢启动阶段,cwnd以指数形式增长,如上图所示;注意这里忽略了接收窗口的影响,上文也提到了。
- 拥塞窗口会一直增长直到到达慢开始门限ssthresh,开始执行拥塞避免算法
② 拥塞避免
- 该阶段的拥塞窗口变为线性增长,每次cwnd+1,也即每次增加一个MSS
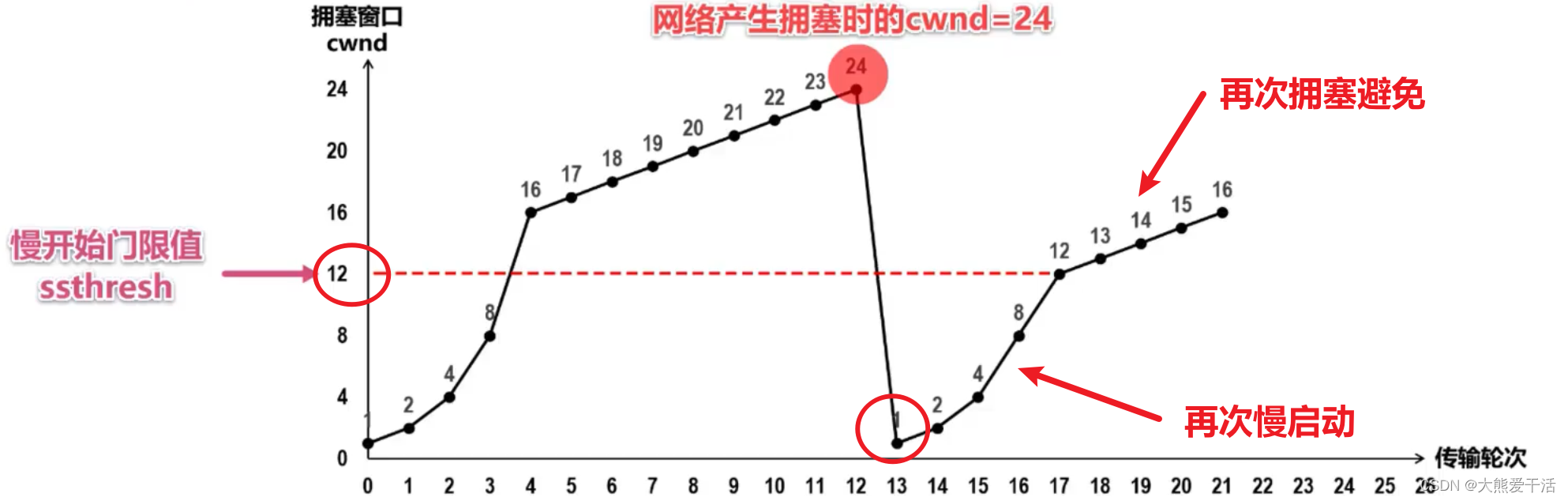
- 随着拥塞窗口的增加,发送速率不断提高,当TCP遇到分组超时重传时,即认为发生了网络拥塞
- 此时将更新ssthresh的值为当前拥塞窗口的一半,上图中是更新为24的一半即12
- 更新cwnd的值为1
- 然后继续执行慢启动—拥塞避免,如上图所示
- 如果TCP发送方接收到连续的3个重复确认,则认为是正常的网络包丢失,而不是网络拥塞造成的(这正是快重传算法的功劳)
- 重传丢失的分组
- 执行快恢复算法
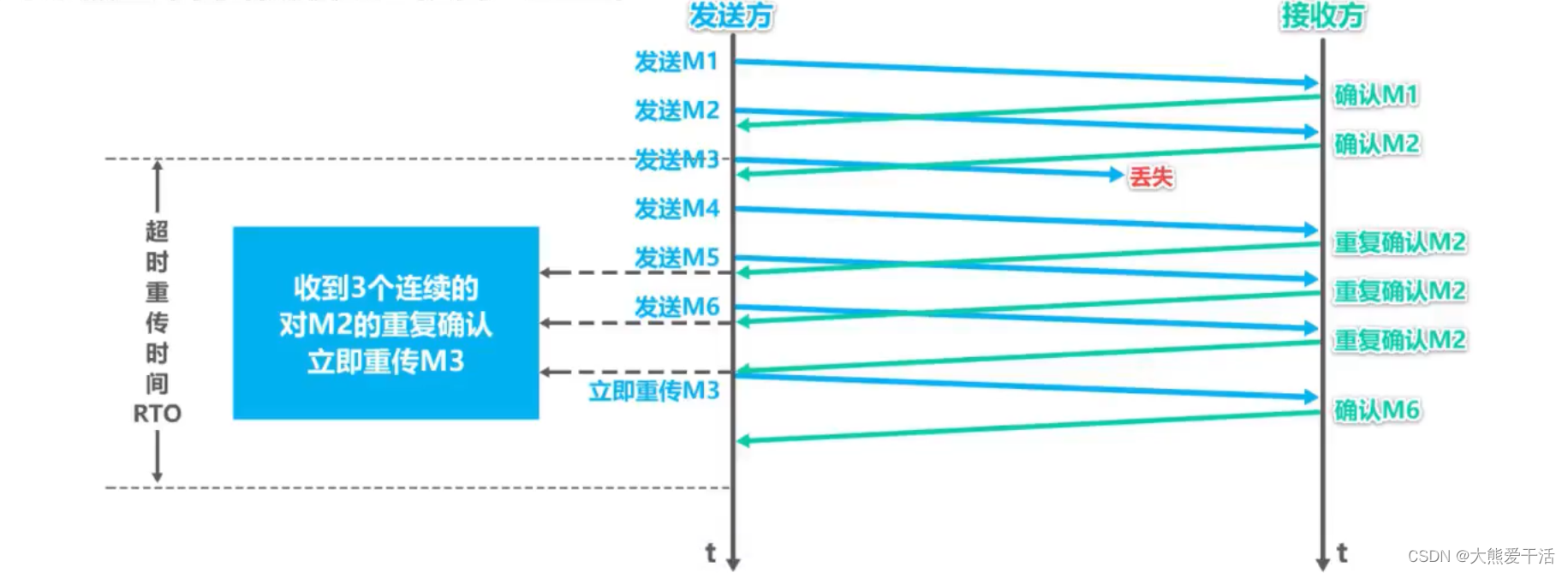
③ 快重传
- 所谓的快重传算法,就是让发送方尽快重传,而不是等待超时重传计时器超时再重传
- 要求接收方不要等待自己发送数据时才捎带确认,而是要立即发送确认
- 即使是失序的报文段,也要立即发送对已收到的报文段的重复确认
- 发送方一旦收到3个连续的重复确认,就将相应的报文段立即重传,而不是等待该报文的重传计时器超时再重传
如下图所示:
④ 快恢复
- 如果发送方收到了3个重复确认,就执行快恢复算法
- 将慢开始门限sstresh和拥塞窗口cwnd都设置为当前拥塞窗口的一半,然后执行拥塞避免算法
三、一个糅合了4种拥塞控制算法的例子
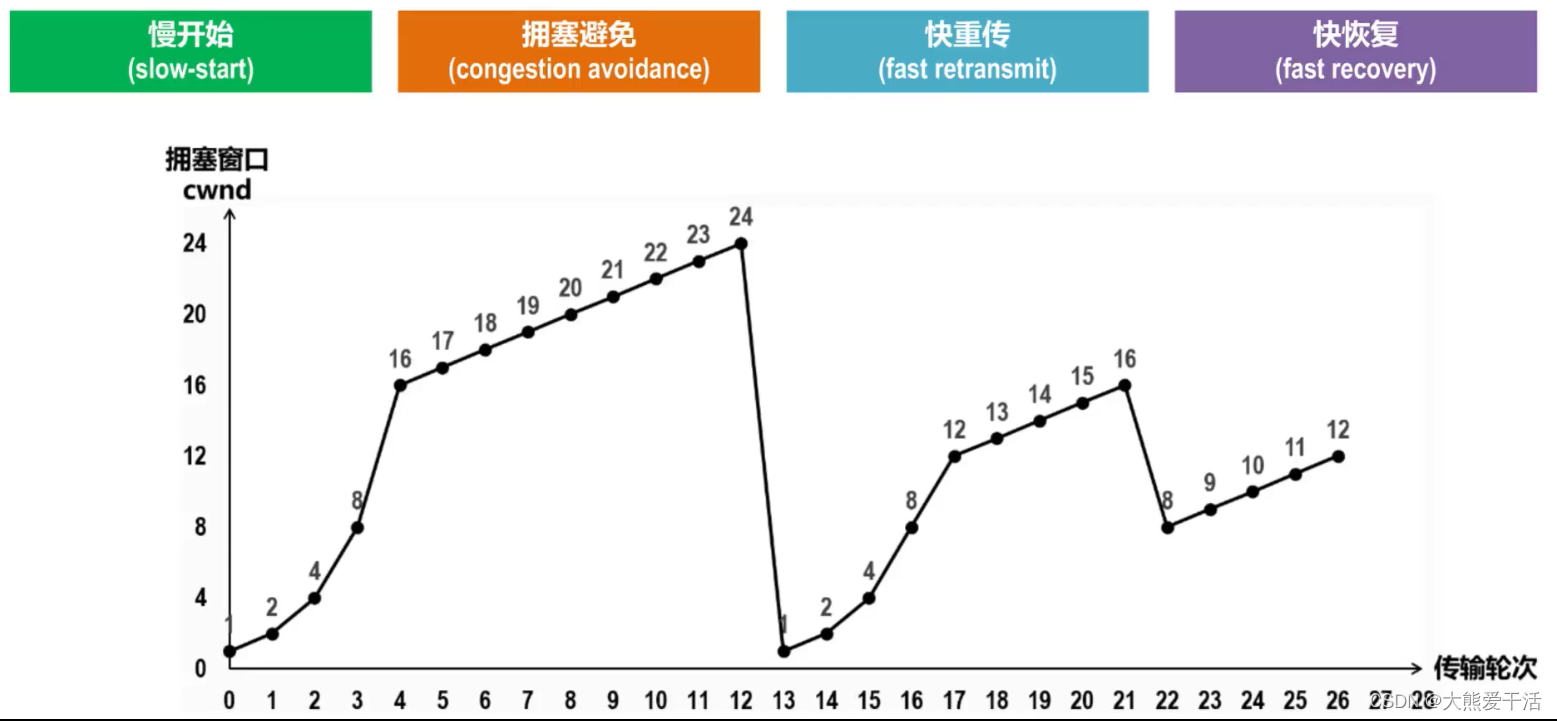
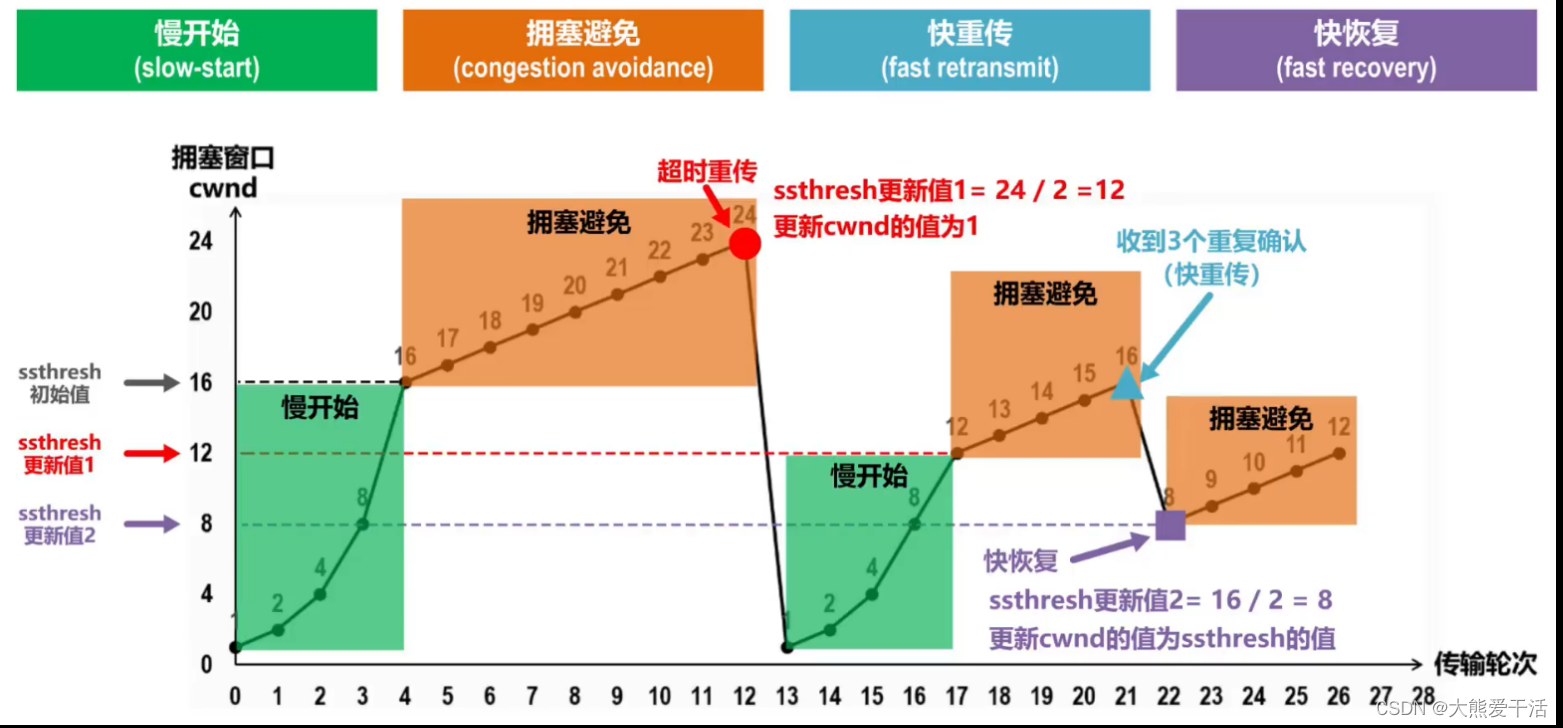
- 最初cwnd=1,ssthresh=16,执行慢开始算法,cwnd大小指数增长
- cwnd到达慢开始门限ssthresh后,转而执行拥塞避免算法,cwnd线性加一增长
- 随着发送速率的增加,若发生超时重传,则将慢开始门限ssthresh减小为当前拥塞窗口的一半、再将拥塞窗口cwnd设置为1,然后执行慢开始-–拥塞避免,重复1、2
- 若发送方收到3个重复确认,则表示分组丢失,发送方立刻重传相应分组;然后执行快恢复算法
- 将慢开始门限ssthresh和拥塞窗口cwnd重新设置为当前拥塞窗口的一半,然后执行拥塞避免算法
04.HTTP是在OSI模型的哪一层
HTTP(超文本传输协议)是应用层协议,它是在 OSI 模型的最高层,即第七层——应用层。HTTP 通过互联网来传输数据和信息,主要用于 Web 浏览器和 Web 服务器之间的通信,以及客户端与服务器之间的文件传输、查询和请求响应等操作。
05.HTTPS用到的是对称加密还是非对称加密?分别体现在哪里?
一、对称加密与非对称加密
HTTPS 的安全性是由 TLS 来保证的。
加密可以分为两大类:对称加密和非对称加密。
1.1 对称加密
对称加密的方法是,双方使用同一个秘钥对数据进行加密和解密。但是对称加密的存在一个问题,就是如何保证秘钥传输的安全性,因为秘钥还是会通过网络传输的,一旦秘钥被其他人获取到,那么整个加密过程就毫无作用了。 这就要用到非对称加密的方法。速度要比非对称加密快。
1.2 非对称加密
非对称加密的方法是,我们拥有两个秘钥,一个是公钥,一个是私钥。公钥是公开的,私钥是保密的。用私钥加密的数据,只有对应的公钥才能解密,用公钥加密的数据,只有对应的私钥才能解密。我们可以将公钥公布出去,任何想和我们通信的客户, 都可以使用我们提供的公钥对数据进行加密,这样我们就可以使用私钥进行解密,这样就能保证数据的安全了。但是非对称加密有一个缺点就是加密的过程很慢,因此如果每次通信都使用非对称加密的方式的话,反而会造成等待时间过长的问题。
二、混合加密
对称加密和非对称加密搭配使用。
基于以上两点原因,最终选择了一个更加完美的方案,那就是在传输数据阶段依然使用对称加密,但是对称加密的密钥我们采用非对称加密来传输。
https使用混合加密,并且还要配合数字证书来实现安全性。

从图中可以看出,改造后的流程是这样的:
- 首先浏览器向服务器发送对称加密套件列表、非对称加密套件列表和随机数 client-random;
- 服务器保存随机数 client-random,选择对称加密和非对称加密的套件,然后生成随机数 service-random,向浏览器发送选择的加密套件、service-random 和公钥;
- 浏览器保存公钥,并利用 client-random 和 service-random 计算出来 pre-master,然后利用公钥对 pre-master 加密,并向服务器发送加密后的数据;
- 最后服务器拿出自己的私钥,解密出 pre-master 数据,并返回确认消息。
到此为止,服务器和浏览器就有了共同的 client-random、service-random 和 pre-master,然后服务器和浏览器会使用这三组随机数生成对称密钥,因为服务器和浏览器使用同一套方法来生成密钥,所以最终生成的密钥也是相同的。
有了对称加密的密钥之后,双方就可以使用对称加密的方式来传输数据了。
需要特别注意的一点,pre-master 是经过公钥加密之后传输的,所以黑客无法获取到 pre-master,这样黑客就无法生成密钥,也就保证了黑客无法破解传输过程中的数据了
注:什么是加密套件?
加密套件(CipherList)是指在ssl通信中,服务器和客户端所使用的加密算法的组合。在ssl握手初期,客户端将自身支持的加密套件列表发送给服务器;在握手阶段,服务器根据自己的配置从中尽可能的选出一个套件,作为之后所要使用的加密方式。
其实就是服务器选择一个双方要使用的加密方法。
三、添加数字证书 + 混合加密
对称加密和非对称加密,以及两者结合起来的混合加密,实现了机密性。 但仅有机密性,离安全还差的很远。
黑客虽然拿不到会话密钥,无法破解密文,但可以通过窃听收集到足够多的密文,再尝试着修改、重组后发给网站。因为没有完整性保证,服务器只能“照单全收”,然后他就可以通过服务器的响应获取进一步的线索,最终就会破解出明文。
另外,黑客也可以伪造身份发布公钥。如果你拿到了假的公钥,混合加密就完全失效了。你以为自己是在和“某宝”通信,实际上网线的另一端却是黑客,银行卡号、密码等敏感信息就在“安全”的通信过程中被窃取了。
所以,在机密性的基础上还必须加上完整性、身份认证等特性,才能实现真正的安全。
3.1 https的真正请求流程
https使用混合加密,并且还要配合数字证书来实现安全性。
- 客户端向服务器发起请求,请求中包含使用的TLS版本号、生成的一个随机数、以及客户端支持的加密方法。
- 服务器端接收到请求后,确认双方使用的加密方法和TLS版本号、并给出服务器的证书、以及一个服务器生成的随机数。
- 客户端确认服务器证书有效后,生成一个新的随机数,并使用数字证书中解密拿到的服务器公钥,加密这个随机数,然后发给服务器。
- 服务器使用自己的私钥,来解密客户端发送过来的随机数。这样服务器就拿到了第三个随机数。而且只有客户端和服务器端知道这第三个随机数,因为第三个随机数是通过加密传输的。
- 客户端和服务器端根据约定的加密方法使用前面的三个随机数,生成会话秘钥,以后的对话过程都使用这个秘钥(即会话秘钥)来加密信息。
- 以后客户端和服务器端都使用这个会话秘钥来加密。

四、数字证书
服务器获取证书?

- 首先,服务器先用Hash算法将自己的公钥和其他信息(例如认证时长,服务器域名…)进行加密,生成一个信息摘要,传递给认证机构,并且认证机构也会有自己的公钥和私钥,并且认证机构会将自己的公钥给了浏览器。
- 然后认证机构会用自己的私钥对已经拿到的浏览器摘要进行加密,生成签名,签名和信息摘要合在一起称为数字证书,(认证机构生成的签名是证书的关键,有了这个认证机构的签名,证书就合法了)。
- 然后再把这个证书传递给服务器,服务器会保存自己的证书,服务器并且也会把证书传递给浏览器。
- 浏览器用认证机构传给自己的公钥对证书进行解密拿到摘要A,并读取证书中相关的明文信息,采用 CA 签名时相同的 Hash 函数来计算并得到摘要B,对比信息摘要 A 和信息摘要 B,如果一致,则可以确认证书是合法的,同时在摘要A中也拿到了服务器的公钥。
摘要 给计算机一篇文章,计算机用摘要算法(主要是哈希类算法)生成一个字符串,如果文章内容改变,哪怕是一个字,一个标点符号,摘要也会完全改变。和完全加密一篇文章相比,摘要的体积很小,因此非常有利于存储和传输。
通常对于一个给定的摘要算法,无论你的文章多大,有多少字节,最终生成摘要的字节数是固定的。
摘要是对原文的证明,从原文到摘要是一个不可逆的过程。
通过原文可以计算出摘要,一旦原文发生变化,哪怕是一个标点符号,摘要也会发生变化。而已知一个摘要,想要反推出原文,几乎是不可能的。因为摘要和原文并不是一对一的关系,是多个原文对应一个摘要。而且,想要找到两个摘要碰撞的原文是非常困难的发生概率相当于买彩票中大奖 。而且就算黑客找到了碰撞的原文,也未必可以起到作用。
签名 如果张三将合同生成摘要,再用自己的私钥加密摘要,得到一个密文串,那么这个串就是张三对合同的数字签名
06.http2和http1的区别
一、HTTP1和HTTP2的区别
1.新的二进制格式:HTTP2采用二进制格式而HTTP1使用文本格式。
2.多路复用:HTTP2是完全多复用的,而非有序并阻塞的,只需一个连接即可实现并行。HTTP1一个连接只能发送一个请求。
3.首部压缩:HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
4.服务器推送:HTTP2在客户端请求资源的时候,会把相关的资源一起发送给客户端,而不需要客户端再次发起请求获取资源。
二、什么是HTTP2.0
HTTP/2(超文本传输协议第2版,最初命名为HTTP 2.0),是HTTP协议的的第二个主要版本,使用于万维网。HTTP/2是HTTP协议自1999年HTTP 1.1发布后的首个更新,主要基于SPDY协议(是Google开发的基于TCP的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验)。
三、为什么需要头部压缩?
HTTP协议是不带有状态的,每次请求头部都会附上所有的信息,而且很多的信息都是重复的,这会浪费很多宽带也会影响速度,所以HTTP2对头部进行了压缩,一方面使用gzip或compress进行头部压缩,另一方面,客户端和服务器会同时维护同一张头信息表,所有的字段都会存入这张表中,生成一个索引号,以后就不需要再发送同样的字段了,只发送索引号,提示了速度。
07.http1.0 / 1.1 / 2 / 3
1.HTTP1.0

HTTP/1.0是无状态、无连接的应用层协议。
无连接
无连接:每次请求都要建立连接,需要使用 keep-alive 参数建立长连接、HTTP1.1默认长连接keep-alive 无法复用连接,每次发送请求都要进行TCP连接,TCP的连接释放都比较费事,会导致网络利用率低
队头阻塞
队头阻塞(head of line blocking),由于HTTP1.0规定下一个请求必须在前一个请求响应到达之前才能发送,假设前一个请求响应一直不到达,那么下一个请求就不发送,后面的请求就阻塞了。
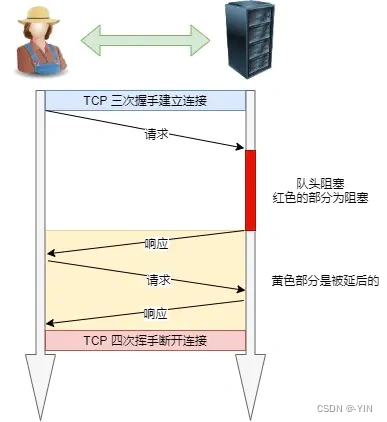
缓存
在HTTP1.0中主要使用header里的协商缓存 last-modified\if-modified-since,强缓存 Expires来做为缓存判断的标准
If-Modified-Since

Expires是RFC 2616(HTTP/1.0)协议中和网页缓存相关字段。用来控制缓存的失效日期。
Expires 字段声明了一个网页或 URL 地址不再被浏览器缓存的时间,一旦超过了这个时间,浏览器都应该联系原始服务器。RFC告诉我们:“由于推断的失效时间也许会降低语义透明度,应该被谨慎使用,同时我们鼓励原始服务器尽可能提供确切的失效时间。”
其他问题
HOST域:认为每个服务器绑定唯一一个IP地址,因此在请求消息的URL中没有主机名,HTTP1.0没有host域。而现在在一台服务器上可以存在多个虚拟主机,并且它们共享一个IP地址。
HTTP1.0不支持断点续传功能,每次都会传送全部的页面和数据。如果只需要部分数据就会浪费多余带宽
2.HTTP/1.1

特点
简单 HTTP 基本的报文格式就是 header + body,头部信息也是 key-value 简单文本的形式,易于理解
灵活、易扩展 各类请求方法、URL、状态码,等每个组成都没有固定死,开发者可以自定义与扩充 HTTP在应用层其下层可以灵活变化(https就是HTTP与TCP之间增加SSL/TSL安全传输协议)
应用广泛、支持跨平台
优缺点
1.无状态 好处:服务器不用额外资源记录,减轻服务器负担,提高CPU内存利用效率 坏处:每次都要确认验证信息;一般通过Cookie解决(Cookie 通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。) 2.明文传输: 传输过程中信息可以抓包直接获取,信息暴露、安全性差 3.不安全: 通信使用明文传输、信息泄露 不验证通信双方身份、有可能进入伪装网站 无法证明报文完整性都导致不安全的问题 解决方式:可以用 HTTPS 的方式解决,也就是通过引入 SSL/TLS 层,使得更安全。
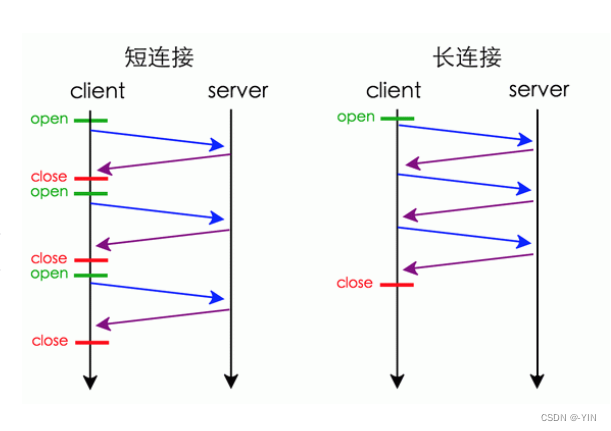
长连接
为了解决早期HTTP/1.0每次都要建立连接导致通信效率低的性能问题,因为HTTP基于TCP/IP协议 为了解决上述 TCP 连接问题,HTTP/1.1 提出了长连接的通信方式,也叫持久连接。这种方式的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。如果某个 HTTP 长连接超过一定时间没有任何数据交互,服务端就会主动断开这个连接。
短连接和长连接对比
管道传输
因为HTTP/1.1 采用了长连接的方式,这使得管道(pipeline)网络传输成为了可能。
即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。 但是服务器必须按照接收请求的顺序发送对这些管道化请求的响应。
如果服务端在处理 A 请求时耗时比较长,那么后续的请求的处理都会被阻塞住,这称为「队头堵塞」。
所以,HTTP/1.1 管道解决了请求的队头阻塞,但是没有解决响应的队头阻塞。
注意:实际上 HTTP/1.1 管道化技术不是默认开启,而且浏览器基本都没有支持,所以后面讨论HTTP/1.1 都是建立在没有使用管道化的前提。
3.HTTP/1.0 比较 HTTP/1.1
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
- 使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间
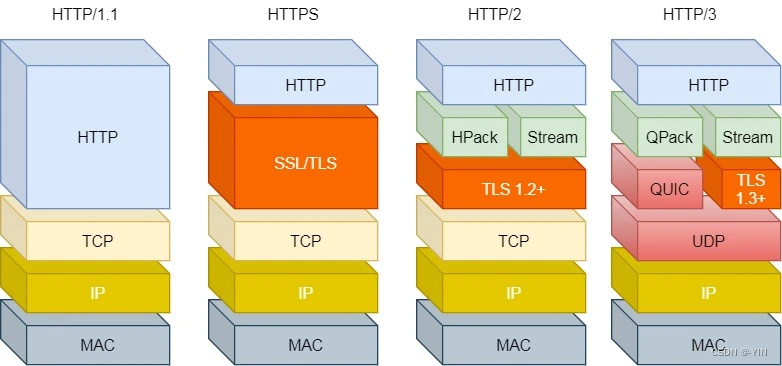
HTTP协议层次结构图
现在主流浏览器大部分使用的都是HTTP/1.1协议,也有部分支持HTTP/2.0;绝大部分网站都升级为HTTPS更保证安全性
4.HTTP/2.0
详见该文章:深入理解HTTP/2.0 HTTP/2.0协议是基于HTTPS的,更加安全
相比与HTTP/1.1,HTTP/2.0增加如下几点的重大优化
头部压缩
HTTP2.0会压缩(Header)部分;如果同时多个请求其头部一样或相似,那么协议会消除重复部分。 利用HPAK算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,就不用重复发送同样字段了,只发送索引号,减少数据量提高速度
二进制格式
HTTP/1.0和HTTP/1.1中,报文都是纯文本的格式简单易读;而在2.0中采用了二进制的格式 报头和数据体称为:帧(frame)-》头信息帧(Headers Frame)和数据帧(Data Frame)
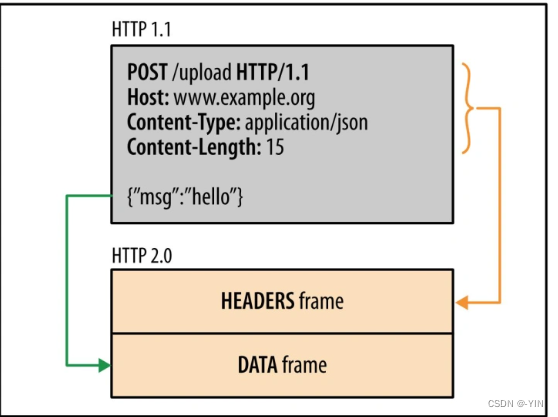
文本形式信息保存为一个一个字符,占用空间多,每个字符对应比特位多,接受方还需要将报文转换为二进制,而直接用二进制减少了传输数据量,提高数据传输效率
1.0: 2.0:
2.0:
数据以数据流(stream)的形式以字节单位发送,数据包可以不按顺序发送
在 HTTP/2 中每个请求或响应的所有数据包,称为一个数据流(Stream)。每个数据流都标记着一个独一无二的编号(Stream ID); 所有HTTP2.0通信都在一个TCP链接上完成,这个链接可以承载任意流量的双向数据流。每个数据流以消息的形式发送,而消息由一或多个帧组成。不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息
客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求
多路复用
HTTP2.0实现了真正的并行传输,它能够在一个TCP上进行任意数量的HTTP请求,由于其二进制分帧特性
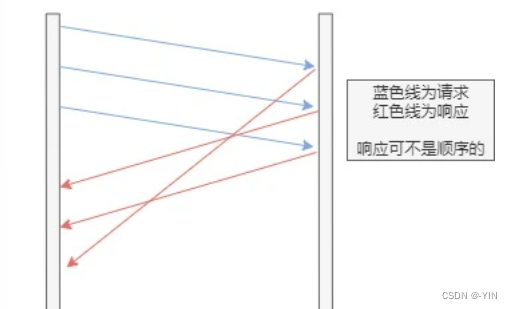
HTTP/2 是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。
移除了 HTTP/1.1 中的串行请求,不需要排队等待,彻底解决「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
服务端推送
HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务端不再是被动地响应,可以主动向客户端发送消息、推送额外的资源。
例如: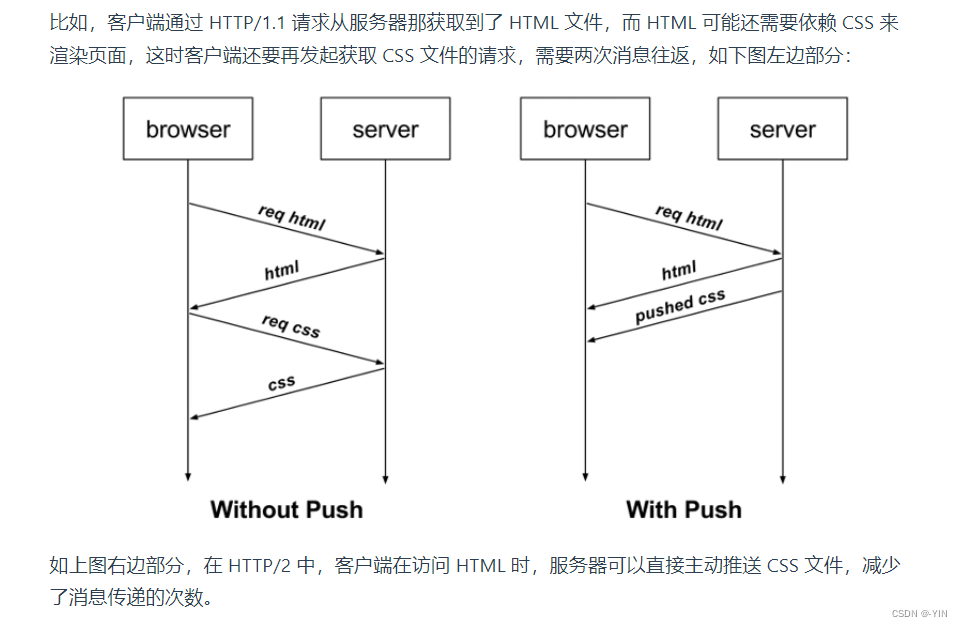
TCP导致队头阻塞
因为TCP面向字节流传输,而且保证传输可靠性和数据的完整性 只有TCP拿到完整连续的数据时,内核才会将数据从缓冲区交给HTTP应用,而只要前一个字节没有收到,HTTP就无法从内核缓冲区中得到数据,直到其到达,所以在此过程仍然会导致队头阻塞
图中发送方发送了很多个 packet,每个 packet 都有自己的序号,你可以认为是 TCP 的序列号,其中 packet 3 在网络中丢失了,即使 packet 4-6 被接收方收到后,由于内核中的 TCP 数据不是连续的,于是接收方的应用层就无法从内核中读取到,只有等到 packet 3 重传后,接收方的应用层才可以从内核中读取到数据,这就是 HTTP/2 的队头阻塞问题,是在 TCP 层面发生的。
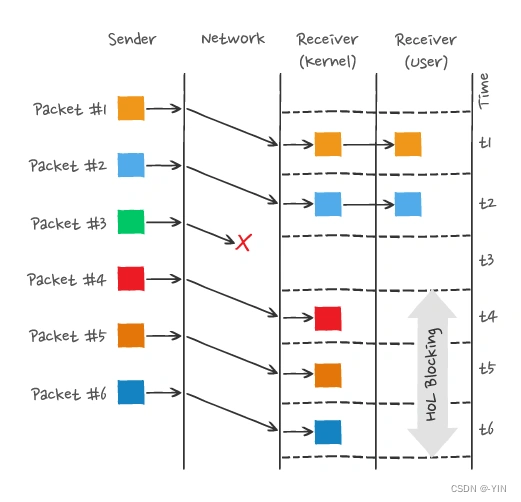
因此如果出现丢包就会触发TCP的超时重传,这样后续缓冲队列中所有数据都得等丢了的重传
5.HTTP/3.0
(仍在学习中…后续完善)
基于Google的QUIC,HTTP3 背后的主要思想是放弃 TCP,转而使用基于 UDP 的 QUIC 协议。
为了解决HTTP/2.0中TCP造成的队头阻塞问题,HTTP/3.0直接放弃使用TCP,将传输层协议改成UDP;但是因为UDP是不可靠传输,所以这就需要QUIC实现可靠机制
QUIC 也是需要三次握手来建立连接的,主要目的是为了确定连接 ID。
可以学一下这篇文章:QUIC详解(用UDP实现可靠协议)
在 UDP 报文头部与 HTTP 消息之间,共有 3 层头部:
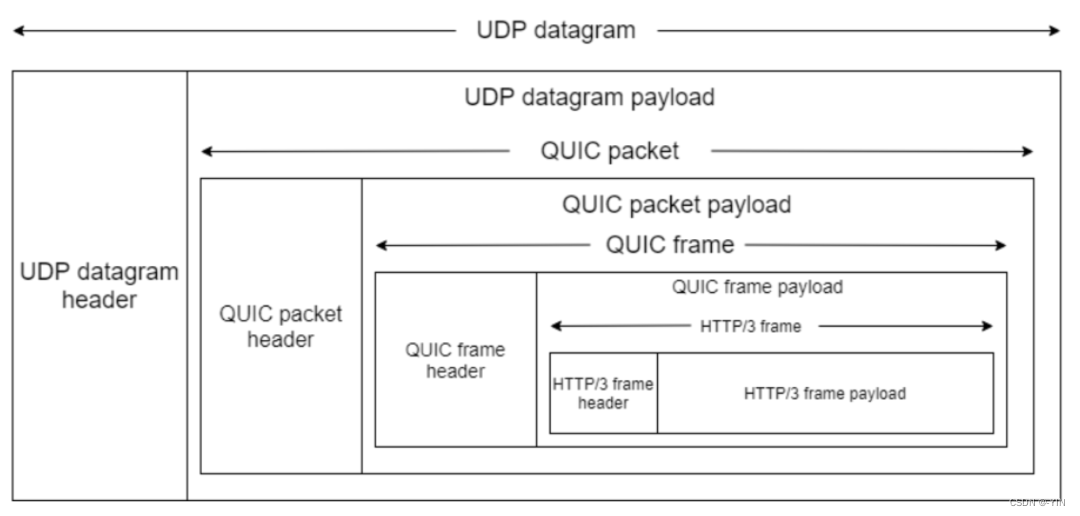
QUIC特点:
无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
连接建立
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
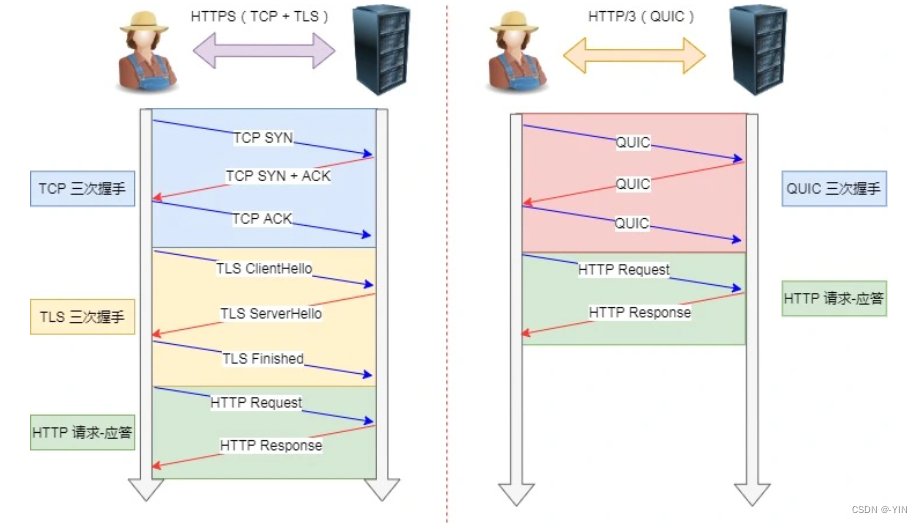
连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接,例如设备要连接wifi(IP地址改变)就必须要重新建立连接,而建立连接包含TCP三次握手和TSL四次握手,以及TCP慢启动所以会造成使用者卡顿的感觉
而QUIC通过连接ID标记自己,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
其实, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
08.get和post区别
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,在日常开发的 RESTful 接口中,都能看到它们的身影。而它们之间的区别,也是一道常见且经典的面试题,所以我们本文就来详细的聊聊。
HTTP 协议定义的方法类型总共有以下 10 种:
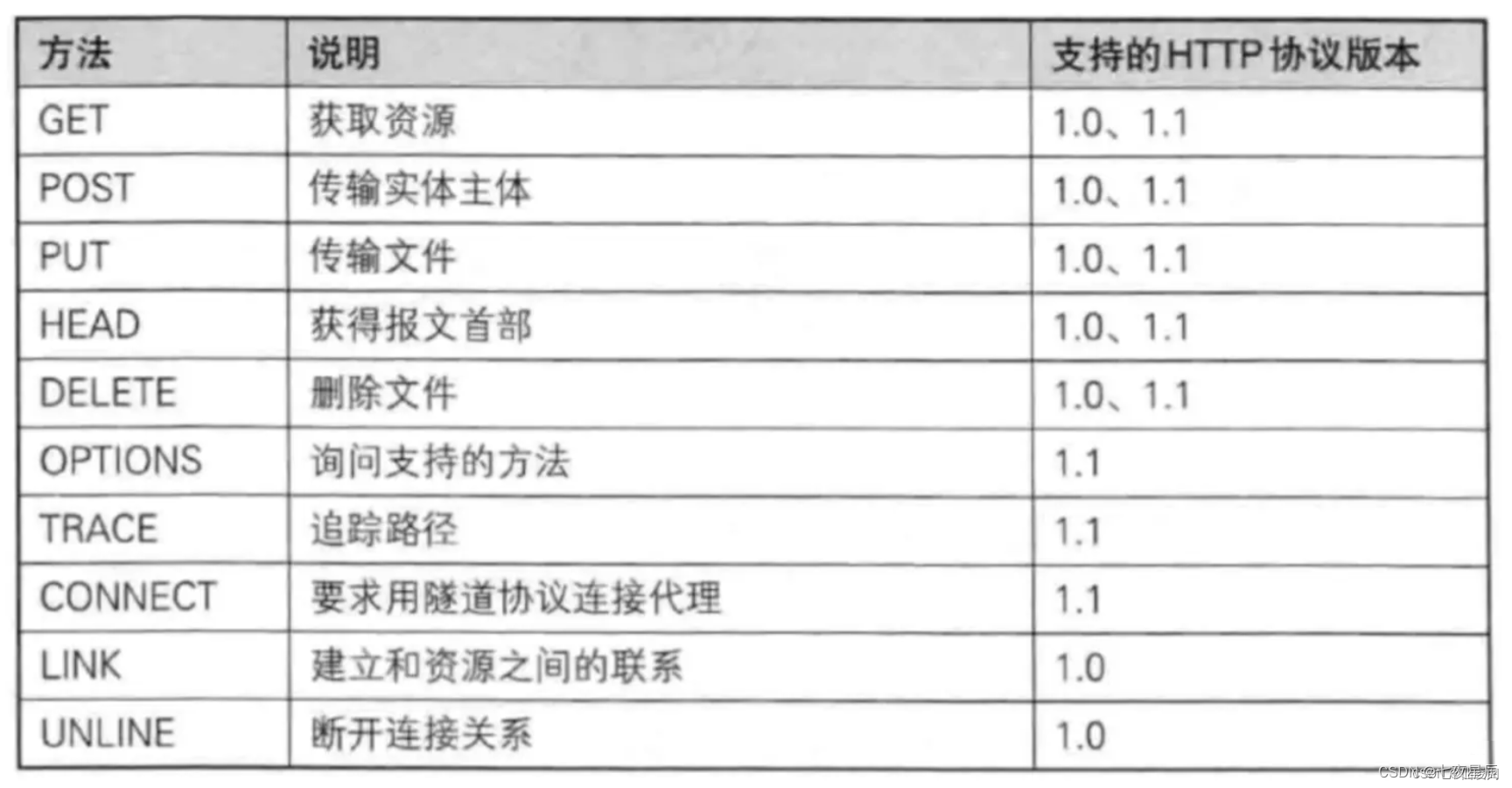
PS:目前大部分的网站使用的都是 HTTP 1.1 的协议。
但在日常开发中,使用频率最高的就属 GET 请求和 POST 请求了,尤其是在中、小型公司,基本只会使用这两种请求来实现一个项目。
1.相同点和最本质的区别
1.1 相同点
GET 请求和 POST 请求底层都是基于 TCP/IP 协议实现的,使用二者中的任意一个,都可以实现客户端和服务器端的双向交互。
1.2 最本质的区别
GET 和 POST 最本质的区别是“约定和规范”上的区别,在规范中,定义 GET 请求是用来获取资源的,也就是进行查询操作的,而 POST 请求是用来传输实体对象的,因此会使用 POST 来进行添加、修改和删除等操作。
当然如果严格按照规范来说,删除操作应该使用 DELETE 请求才对,但在实际开发中,使用 POST 来进行删除的用法更常见一些。
按照约定来说,GET 和 POST 的参数传递也是不同的,GET 请求是将参数拼加到 URL 上进行参数传递的,而 POST 是将请参数写入到请求正文中传递的,如下图所示:

2.非本质区别
2.1 缓存不同
GET 请求一般会被缓存,比如常见的 CSS、JS、HTML 请求等都会被缓存;而 POST 请求默认是不进行缓存的。
2.2 参数长度限制不同
GET 请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,通常为 2k,当然浏览器厂商不同、版本不同这个限制的大小值可能也不同,但相同的是它们都会对 URL 的大小进行限制;而 POST 请求参数是存放在请求正文(request body)中的,所以没有大小限制。
2.3 回退和刷新不同
GET 请求可以直接进行回退和刷新,不会对用户和程序产生任何影响;而 POST 请求如果直接回滚和刷新将会把数据再次提交,如下图所示:

2.4 历史记录不同
GET 请求的参数会保存在历史记录中,而 POST 请求的参数不会保留到历史记录中。
2.5 书签不同
GET 请求的地址可被收藏为书签,而 POST 请求的地址不能被收藏为书签。
3.总结
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,它们的底层都是基于 TCP/IP 实现的。它们的区别主要体现在 5 个方面:缓存不同、参数长度限制不同、回退和刷新不同、历史记录不同、能否保存为书签不同,但它们最大的区别是规范和约定上的不同,规范中定义 GET 是用来获取信息的,而 POST 是用来传递实体的,并且 GET 请求的参数要放在 URL 上,而 POST 请求的参数要放在请求正文中。
09.WebSockt
一、内容概览
WebSocket的出现,使得浏览器具备了实时双向通信的能力。本文由浅入深,介绍了WebSocket如何建立连接、交换数据的细节,以及数据帧的格式。此外,还简要介绍了针对WebSocket的安全攻击,以及协议是如何抵御类似攻击的。
二、什么是WebSocket
HTML5开始提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。
对大部分web开发者来说,上面这段描述有点枯燥,其实只要记住几点:
- WebSocket可以在浏览器里使用
- 支持双向通信
- 使用很简单
1、有哪些优点
说到优点,这里的对比参照物是HTTP协议,概括地说就是:支持双向通信,更灵活,更高效,可扩展性更好。
- 支持双向通信,实时性更强。
- 更好的二进制支持。
- 较少的控制开销。连接创建后,ws客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有2~10字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的4字节的掩码。而HTTP协议每次通信都需要携带完整的头部。
- 支持扩展。ws协议定义了扩展,用户可以扩展协议,或者实现自定义的子协议。(比如支持自定义压缩算法等)
对于后面两点,没有研究过WebSocket协议规范的同学可能理解起来不够直观,但不影响对WebSocket的学习和使用。
2、需要学习哪些东西
对网络应用层协议的学习来说,最重要的往往就是连接建立过程、数据交换教程。当然,数据的格式是逃不掉的,因为它直接决定了协议本身的能力。好的数据格式能让协议更高效、扩展性更好。
下文主要围绕下面几点展开:
- 如何建立连接
- 如何交换数据
- 数据帧格式
- 如何维持连接
三、入门例子
在正式介绍协议细节前,先来看一个简单的例子,有个直观感受。例子包括了WebSocket服务端、WebSocket客户端(网页端)。完整代码可以在 这里 找到。
这里服务端用了ws这个库。相比大家熟悉的socket.io,ws实现更轻量,更适合学习的目的。
1、服务端
代码如下,监听8080端口。当有新的连接请求到达时,打印日志,同时向客户端发送消息。当收到到来自客户端的消息时,同样打印日志。
var app = require('express')();
var server = require('http').Server(app);
var WebSocket = require('ws');
var wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws) {
console.log('server: receive connection.');
ws.on('message', function incoming(message) {
console.log('server: received: %s', message);
});
ws.send('world');
});
app.get('/', function (req, res) {
res.sendfile(__dirname + '/index.html');
});
app.listen(3000);
2、客户端
代码如下,向8080端口发起WebSocket连接。连接建立后,打印日志,同时向服务端发送消息。接收到来自服务端的消息后,同样打印日志。
<script>
var ws = new WebSocket('ws://localhost:8080');
ws.onopen = function () {
console.log('ws onopen');
ws.send('from client: hello');
};
ws.onmessage = function (e) {
console.log('ws onmessage');
console.log('from server: ' + e.data);
};
</script>
3、运行结果
可分别查看服务端、客户端的日志,这里不展开。
服务端输出:
server: receive connection.
server: received hello
客户端输出:
client: ws connection is open
client: received world
四、如何建立连接
前面提到,WebSocket复用了HTTP的握手通道。具体指的是,客户端通过HTTP请求与WebSocket服务端协商升级协议。协议升级完成后,后续的数据交换则遵照WebSocket的协议。
1、客户端:申请协议升级
首先,客户端发起协议升级请求。可以看到,采用的是标准的HTTP报文格式,且只支持GET方法。
GET / HTTP/1.1
Host: localhost:8080
Origin: http://127.0.0.1:3000
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: w4v7O6xFTi36lq3RNcgctw==
重点请求首部意义如下:
Connection: Upgrade:表示要升级协议Upgrade: websocket:表示要升级到websocket协议。Sec-WebSocket-Version: 13:表示websocket的版本。如果服务端不支持该版本,需要返回一个Sec-WebSocket-Versionheader,里面包含服务端支持的版本号。Sec-WebSocket-Key:与后面服务端响应首部的Sec-WebSocket-Accept是配套的,提供基本的防护,比如恶意的连接,或者无意的连接。
注意,上面请求省略了部分非重点请求首部。由于是标准的HTTP请求,类似Host、Origin、Cookie等请求首部会照常发送。在握手阶段,可以通过相关请求首部进行 安全限制、权限校验等。
2、服务端:响应协议升级
服务端返回内容如下,状态代码101表示协议切换。到此完成协议升级,后续的数据交互都按照新的协议来。
HTTP/1.1 101 Switching Protocols
Connection:Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: Oy4NRAQ13jhfONC7bP8dTKb4PTU=
备注:每个header都以
\r\n结尾,并且最后一行加上一个额外的空行\r\n。此外,服务端回应的HTTP状态码只能在握手阶段使用。过了握手阶段后,就只能采用特定的错误码。
3、Sec-WebSocket-Accept的计算
Sec-WebSocket-Accept根据客户端请求首部的Sec-WebSocket-Key计算出来。
计算公式为:
- 将
Sec-WebSocket-Key跟258EAFA5-E914-47DA-95CA-C5AB0DC85B11拼接。 - 通过SHA1计算出摘要,并转成base64字符串。
伪代码如下:
>toBase64( sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )
验证下前面的返回结果:
const crypto = require('crypto');
const magic = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
const secWebSocketKey = 'w4v7O6xFTi36lq3RNcgctw==';
let secWebSocketAccept = crypto.createHash('sha1')
.update(secWebSocketKey + magic)
.digest('base64');
console.log(secWebSocketAccept);
// Oy4NRAQ13jhfONC7bP8dTKb4PTU=
五、数据帧格式
客户端、服务端数据的交换,离不开数据帧格式的定义。因此,在实际讲解数据交换之前,我们先来看下WebSocket的数据帧格式。
WebSocket客户端、服务端通信的最小单位是帧(frame),由1个或多个帧组成一条完整的消息(message)。
- 发送端:将消息切割成多个帧,并发送给服务端;
- 接收端:接收消息帧,并将关联的帧重新组装成完整的消息;
本节的重点,就是讲解数据帧的格式。详细定义可参考 RFC6455 5.2节 。
1、数据帧格式概览
下面给出了WebSocket数据帧的统一格式。熟悉TCP/IP协议的同学对这样的图应该不陌生。
- 从左到右,单位是比特。比如
FIN、RSV1各占据1比特,opcode占据4比特。 - 内容包括了标识、操作代码、掩码、数据、数据长度等。(下一小节会展开)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
2、数据帧格式详解
针对前面的格式概览图,这里逐个字段进行讲解,如有不清楚之处,可参考协议规范,或留言交流。
FIN:1个比特。
如果是1,表示这是消息(message)的最后一个分片(fragment),如果是0,表示不是是消息(message)的最后一个分片(fragment)。
RSV1, RSV2, RSV3:各占1个比特。
一般情况下全为0。当客户端、服务端协商采用WebSocket扩展时,这三个标志位可以非0,且值的含义由扩展进行定义。如果出现非零的值,且并没有采用WebSocket扩展,连接出错。
Opcode: 4个比特。
操作代码,Opcode的值决定了应该如何解析后续的数据载荷(data payload)。如果操作代码是不认识的,那么接收端应该断开连接(fail the connection)。可选的操作代码如下:
- %x0:表示一个延续帧。当Opcode为0时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
- %x1:表示这是一个文本帧(frame)
- %x2:表示这是一个二进制帧(frame)
- %x3-7:保留的操作代码,用于后续定义的非控制帧。
- %x8:表示连接断开。
- %x9:表示这是一个ping操作。
- %xA:表示这是一个pong操作。
- %xB-F:保留的操作代码,用于后续定义的控制帧。
Mask: 1个比特。
表示是否要对数据载荷进行掩码操作。从客户端向服务端发送数据时,需要对数据进行掩码操作;从服务端向客户端发送数据时,不需要对数据进行掩码操作。
如果服务端接收到的数据没有进行过掩码操作,服务端需要断开连接。
如果Mask是1,那么在Masking-key中会定义一个掩码键(masking key),并用这个掩码键来对数据载荷进行反掩码。所有客户端发送到服务端的数据帧,Mask都是1。
掩码的算法、用途在下一小节讲解。
Payload length:数据载荷的长度,单位是字节。为7位,或7+16位,或1+64位。
假设数Payload length === x,如果
- x为0~126:数据的长度为x字节。
- x为126:后续2个字节代表一个16位的无符号整数,该无符号整数的值为数据的长度。
- x为127:后续8个字节代表一个64位的无符号整数(最高位为0),该无符号整数的值为数据的长度。
此外,如果payload length占用了多个字节的话,payload length的二进制表达采用网络序(big endian,重要的位在前)。
Masking-key:0或4字节(32位)
所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask为1,且携带了4字节的Masking-key。如果Mask为0,则没有Masking-key。
备注:载荷数据的长度,不包括mask key的长度。
Payload data:(x+y) 字节
载荷数据:包括了扩展数据、应用数据。其中,扩展数据x字节,应用数据y字节。
扩展数据:如果没有协商使用扩展的话,扩展数据数据为0字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。
应用数据:任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。
3、掩码算法
掩码键(Masking-key)是由客户端挑选出来的32位的随机数。掩码操作不会影响数据载荷的长度。掩码、反掩码操作都采用如下算法:
首先,假设:
- original-octet-i:为原始数据的第i字节。
- transformed-octet-i:为转换后的数据的第i字节。
- j:为
i mod 4的结果。 - masking-key-octet-j:为mask key第j字节。
算法描述为: original-octet-i 与 masking-key-octet-j 异或后,得到 transformed-octet-i。
j = i MOD 4 transformed-octet-i = original-octet-i XOR masking-key-octet-j
六、数据传递
一旦WebSocket客户端、服务端建立连接后,后续的操作都是基于数据帧的传递。
WebSocket根据opcode来区分操作的类型。比如0x8表示断开连接,0x0-0x2表示数据交互。
1、数据分片
WebSocket的每条消息可能被切分成多个数据帧。当WebSocket的接收方收到一个数据帧时,会根据FIN的值来判断,是否已经收到消息的最后一个数据帧。
FIN=1表示当前数据帧为消息的最后一个数据帧,此时接收方已经收到完整的消息,可以对消息进行处理。FIN=0,则接收方还需要继续监听接收其余的数据帧。
此外,opcode在数据交换的场景下,表示的是数据的类型。0x01表示文本,0x02表示二进制。而0x00比较特殊,表示延续帧(continuation frame),顾名思义,就是完整消息对应的数据帧还没接收完。
2、数据分片例子
直接看例子更形象些。下面例子来自MDN,可以很好地演示数据的分片。客户端向服务端两次发送消息,服务端收到消息后回应客户端,这里主要看客户端往服务端发送的消息。
第一条消息
FIN=1, 表示是当前消息的最后一个数据帧。服务端收到当前数据帧后,可以处理消息。opcode=0x1,表示客户端发送的是文本类型。
第二条消息
- FIN=0,opcode=0x1,表示发送的是文本类型,且消息还没发送完成,还有后续的数据帧。
- FIN=0,opcode=0x0,表示消息还没发送完成,还有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。
- FIN=1,opcode=0x0,表示消息已经发送完成,没有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。服务端可以将关联的数据帧组装成完整的消息。
Client: FIN=1, opcode=0x1, msg="hello"
Server: (process complete message immediately) Hi.
Client: FIN=0, opcode=0x1, msg="and a"
Server: (listening, new message containing text started)
Client: FIN=0, opcode=0x0, msg="happy new"
Server: (listening, payload concatenated to previous message)
Client: FIN=1, opcode=0x0, msg="year!"
Server: (process complete message) Happy new year to you too!
七、连接保持+心跳
WebSocket为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的TCP通道保持连接没有断开。然而,对于长时间没有数据往来的连接,如果依旧长时间保持着,可能会浪费包括的连接资源。
但不排除有些场景,客户端、服务端虽然长时间没有数据往来,但仍需要保持连接。这个时候,可以采用心跳来实现。
- 发送方->接收方:ping
- 接收方->发送方:pong
ping、pong的操作,对应的是WebSocket的两个控制帧,opcode分别是0x9、0xA。
举例,WebSocket服务端向客户端发送ping,只需要如下代码(采用ws模块)
ws.ping('', false, true);
八、Sec-WebSocket-Key/Accept的作用
前面提到了,Sec-WebSocket-Key/Sec-WebSocket-Accept在主要作用在于提供基础的防护,减少恶意连接、意外连接。
作用大致归纳如下:
- 避免服务端收到非法的websocket连接(比如http客户端不小心请求连接websocket服务,此时服务端可以直接拒绝连接)
- 确保服务端理解websocket连接。因为ws握手阶段采用的是http协议,因此可能ws连接是被一个http服务器处理并返回的,此时客户端可以通过Sec-WebSocket-Key来确保服务端认识ws协议。(并非百分百保险,比如总是存在那么些无聊的http服务器,光处理Sec-WebSocket-Key,但并没有实现ws协议。。。)
- 用浏览器里发起ajax请求,设置header时,Sec-WebSocket-Key以及其他相关的header是被禁止的。这样可以避免客户端发送ajax请求时,意外请求协议升级(websocket upgrade)
- 可以防止反向代理(不理解ws协议)返回错误的数据。比如反向代理前后收到两次ws连接的升级请求,反向代理把第一次请求的返回给cache住,然后第二次请求到来时直接把cache住的请求给返回(无意义的返回)。
- Sec-WebSocket-Key主要目的并不是确保数据的安全性,因为Sec-WebSocket-Key、Sec-WebSocket-Accept的转换计算公式是公开的,而且非常简单,最主要的作用是预防一些常见的意外情况(非故意的)。
强调:Sec-WebSocket-Key/Sec-WebSocket-Accept 的换算,只能带来基本的保障,但连接是否安全、数据是否安全、客户端/服务端是否合法的 ws客户端、ws服务端,其实并没有实际性的保证。
九、数据掩码的作用
WebSocket协议中,数据掩码的作用是增强协议的安全性。但数据掩码并不是为了保护数据本身,因为算法本身是公开的,运算也不复杂。除了加密通道本身,似乎没有太多有效的保护通信安全的办法。
那么为什么还要引入掩码计算呢,除了增加计算机器的运算量外似乎并没有太多的收益(这也是不少同学疑惑的点)。
答案还是两个字:安全。但并不是为了防止数据泄密,而是为了防止早期版本的协议中存在的代理缓存污染攻击(proxy cache poisoning attacks)等问题。
1、代理缓存污染攻击
下面摘自2010年关于安全的一段讲话。其中提到了代理服务器在协议实现上的缺陷可能导致的安全问题。猛击出处。
“We show, empirically, that the current version of the WebSocket consent mechanism is vulnerable to proxy cache poisoning attacks. Even though the WebSocket handshake is based on HTTP, which should be understood by most network intermediaries, the handshake uses the esoteric “Upgrade” mechanism of HTTP [5]. In our experiment, we find that many proxies do not implement the Upgrade mechanism properly, which causes the handshake to succeed even though subsequent traffic over the socket will be misinterpreted by the proxy.”
[TALKING] Huang, L-S., Chen, E., Barth, A., Rescorla, E., and C. Jackson, "Talking to Yourself for Fun and Profit", 2010,
在正式描述攻击步骤之前,我们假设有如下参与者:
- 攻击者、攻击者自己控制的服务器(简称“邪恶服务器”)、攻击者伪造的资源(简称“邪恶资源”)
- 受害者、受害者想要访问的资源(简称“正义资源”)
- 受害者实际想要访问的服务器(简称“正义服务器”)
- 中间代理服务器
攻击步骤一:
- 攻击者浏览器 向 邪恶服务器 发起WebSocket连接。根据前文,首先是一个协议升级请求。
- 协议升级请求 实际到达 代理服务器。
- 代理服务器 将协议升级请求转发到 邪恶服务器。
- 邪恶服务器 同意连接,代理服务器 将响应转发给 攻击者。
由于 upgrade 的实现上有缺陷,代理服务器 以为之前转发的是普通的HTTP消息。因此,当协议服务器 同意连接,代理服务器 以为本次会话已经结束。
攻击步骤二:
- 攻击者 在之前建立的连接上,通过WebSocket的接口向 邪恶服务器 发送数据,且数据是精心构造的HTTP格式的文本。其中包含了 正义资源 的地址,以及一个伪造的host(指向正义服务器)。(见后面报文)
- 请求到达 代理服务器 。虽然复用了之前的TCP连接,但 代理服务器 以为是新的HTTP请求。
- 代理服务器 向 邪恶服务器 请求 邪恶资源。
- 邪恶服务器 返回 邪恶资源。代理服务器 缓存住 邪恶资源(url是对的,但host是 正义服务器 的地址)。
到这里,受害者可以登场了:
- 受害者 通过 代理服务器 访问 正义服务器 的 正义资源。
- 代理服务器 检查该资源的url、host,发现本地有一份缓存(伪造的)。
- 代理服务器 将 邪恶资源 返回给 受害者。
- 受害者 卒。
附:前面提到的精心构造的“HTTP请求报文”。
Client → Server:
POST /path/of/attackers/choice HTTP/1.1 Host: host-of-attackers-choice.com Sec-WebSocket-Key: <connection-key>
Server → Client:
HTTP/1.1 200 OK
Sec-WebSocket-Accept: <connection-key>
2、当前解决方案
最初的提案是对数据进行加密处理。基于安全、效率的考虑,最终采用了折中的方案:对数据载荷进行掩码处理。
需要注意的是,这里只是限制了浏览器对数据载荷进行掩码处理,但是坏人完全可以实现自己的WebSocket客户端、服务端,不按规则来,攻击可以照常进行。
但是对浏览器加上这个限制后,可以大大增加攻击的难度,以及攻击的影响范围。如果没有这个限制,只需要在网上放个钓鱼网站骗人去访问,一下子就可以在短时间内展开大范围的攻击。
10.tcp/ip五层模型
- 应用层(Application Layer):该层为用户提供应用程序,如电子邮件、文件传输、远程登录等。常见的协议有 HTTP、FTP、SMTP 等。
- 传输层(Transport Layer):该层负责数据传输,并保证数据传输的可靠性。常见的协议有 TCP 和 UDP。
- 网络层(Internet Layer):该层主要解决数据在网络中的路由问题。常见的协议有 IP、ICMP、ARP 等。
- 数据链路层(Data Link Layer):该层主要解决相邻节点之间的通信问题,将比特流转换成帧进行传输。常见的协议有 Ethernet、WiFi 等。
- 物理层(Physical Layer):该层实现物理连接和比特流传输,如网线、光纤等。
11.dns服务器用的是什么协议
DNS同时占用UDP和TCP端口53是公认的,这种单个应用协议同时使用两种传输协议的情况在TCP/IP栈也算是个另类。但很少有人知道DNS分别在什么情况下使用这两种协议。
先简单介绍下TCP与UDP。 TCP是一种面向连接的协议,提供可靠的数据传输,一般服务质量要求比较高的情况,使用这个协议。UDP---用户数据报协议,是一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
TCP与UDP的区别: UDP和TCP协议的主要区别是两者在如何实现信息的可靠传递方面不同。TCP协议中包含了专门的传递保证机制,当数据接收方收到发送方传来的信息时,会自动向发送方发出确认消息;发送方只有在接收到该确认消息之后才继续传送其它信息,否则将一直等待直到收到确认信息为止。 与TCP不同,UDP协议并不提供数据传送的保证机制。如果在从发送方到接收方的传递过程中出现数据报的丢失,协议本身并不能做出任何检测或提示。因此,通常人们把UDP协议称为不可靠的传输协议。相对于TCP协议,UDP协议的另外一个不同之处在于如何接收突发性的多个数据报。不同于TCP,UDP并不能确保数据的发送和接收顺序。事实上,UDP协议的这种乱序性基本上很少出现,通常只会在网络非常拥挤的情况下才有可能发生。 既然UDP是一种不可靠的网络协议,那么还有什么使用价值或必要呢?其实不然,在有些情况下UDP协议可能会变得非常有用。因为UDP具有TCP所望尘莫及的速度优势。虽然TCP协议中植入了各种安全保障功能,但是在实际执行的过程中会占用大量的系统开销,无疑使速度受到严重的影响。反观UDP由于排除了信息可靠传递机制,将安全和排序等功能移交给上层应用来完成,极大降低了执行时间,使速度得到了保证。
DNS在进行区域传输的时候使用TCP协议,其它时候则使用UDP协议; DNS的规范规定了2种类型的DNS服务器,一个叫主DNS服务器,一个叫辅助DNS服务器。在一个区中主DNS服务器从自己本机的数据文件中读取该区的DNS数据信息,而辅助DNS服务器则从区的主DNS服务器中读取该区的DNS数据信息。当一个辅助DNS服务器启动时,它需要与主DNS服务器通信,并加载数据信息,这就叫做区传送(zone transfer)。
为什么既使用TCP又使用UDP? 首先了解一下TCP与UDP传送字节的长度限制: UDP报文的最大长度为512字节,而TCP则允许报文长度超过512字节。当DNS查询超过512字节时,协议的TC标志出现删除标志,这时则使用TCP发送。通常传统的UDP报文一般不会大于512字节。
区域传送时使用TCP,主要有一下两点考虑: 1.辅域名服务器会定时(一般时3小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,则会执行一次区域传送,进行数据同步。区域传送将使用TCP而不是UDP,因为数据同步传送的数据量比一个请求和应答的数据量要多得多。 2.TCP是一种可靠的连接,保证了数据的准确性。
域名解析时使用UDP协议: 客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。不用经过TCP三次握手,这样DNS服务器负载更低,响应更快。虽然从理论上说,客户端也可以指定向DNS服务器查询的时候使用TCP,但事实上,很多DNS服务器进行配置的时候,仅支持UDP查询包。
12.ping命令 用的是什么协议。在哪一层。
ping命令使用的是ICMP协议(Internet Control Message Protocol,互联网控制报文协议)。ICMP是一种网络层协议,位于OSI模型的第三层(网络层),用于在IP网络中传递错误消息和操作指令。ping命令通过发送ICMP Echo Request(回显请求)消息来测试目标主机是否可达并测量往返延迟时间。当目标主机收到Echo Request消息后,会返回一个ICMP Echo Reply(回显应答)消息给源主机,由此可以确认目标主机的可达性以及测量通信延迟。因此,ping命令既可以用于诊断网络故障,也可以用于测试网络连接速度。
13.能详细讲一下有限状态机怎么解析http报文吗
一、HTTP报文
HTTP的报文格式:
起始行 头部字段 空 行 消息正文 其中起始行和头部字段成为Header,消息正文称为body。Header和body之间一定要有空行隔开。

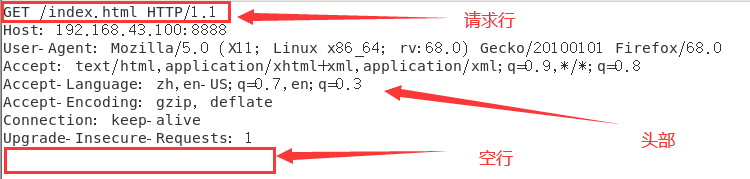
请求行的格式:

如下: GET /index.html HTTP/1.1 请求方法为GET, url为/index.html,版本为HTTP/1.1
而请求头部就是用 key:value 更详细的方式说明HTTP报文。 而我们要做的就是解析这样的http请求,并发送应答报文给客户端。
二、程序结构
主程序:

recv() 是从套接字中读取http报文数据到buffer中
解析HTTP请求的主函数:
parse_content()
在parse_content中首先通过parse_line()读取一行, 主状态有解析请求行和解析头部两种状态,初始状态为解析请求行,当解析请求行完毕,状态转移到解析头部字段
//部分代码,非完整代码
HTTP_CODE parse_content(char* buffer, int& checked_index, CHECK_STATE& checkstate, int& read_index, int& start_line)
{
//每次读取一行解析
while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK)
{
switch (checkstate)
{
case CHECK_STATE_REQUESTLINE://解析请求行
{
//调用解析请求行函数,解析完成后在函数中完成状态转移
retcode = parse_requestline(szTemp, checkstate);
break;
}
case CHECK_STATE_HEADER://解析头部字段
{
retcode = parse_headers(szTemp);
//解析结果被省略了
break;
}
}
}
if (linestatus == LINE_OPEN)//不能读取到完整行
{
return NO_REQUEST;
}
else
{
return BAD_REQUEST;
}
}
三、完整代码
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <iostream>
using namespace std;
constexpr auto BUFFER_SIZE = 4096;
//主状态机状态
//CHECK_STATE_REQUESTLINE 解析请求行;CHECK_STATE_HEADER 解析头部字段
enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT };
//从状态机状态,LINE_OK 完整的一行;LINE_OPEN该行尚未读完;LINE_BAD 该行有错误
enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };
//处理http请求的结果 NO_REQUEST 表示读取的请求结果不完整;GET_REQUEST 读取了完整正确的http请求;BAD_REQUEST表示客户请求有错
enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };
static const char* szret[] = { "I get a correct result\n", "Something wrong\n" };
//次状态机,每次读取一行,通过读取到/r/n来判断是不是完整的一行
LINE_STATUS parse_line(char* buffer, int& checked_index, int& read_index)
{
char temp;
for (; checked_index < read_index; ++checked_index)
{
temp = buffer[checked_index];
if (temp == '\r')
{
if ((checked_index + 1) == read_index)
{
return LINE_OPEN;
}
else if (buffer[checked_index + 1] == '\n')
{
buffer[checked_index++] = '\0';
buffer[checked_index++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
else if (temp == '\n')
{
if ((checked_index > 1) && buffer[checked_index - 1] == '\r')
{
buffer[checked_index - 1] = '\0';
buffer[checked_index++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}
//解析请求行 GET url HTTP/1.1
HTTP_CODE parse_requestline(char* szTemp, CHECK_STATE& checkstate)
{
char* szURL = strpbrk(szTemp, " \t");
if (!szURL)
{
return BAD_REQUEST;
}
*szURL++ = '\0';
char* szMethod = szTemp;
if (strcasecmp(szMethod, "GET") == 0)
{
printf("The request method is GET\n");
}
else
{
return BAD_REQUEST;
}
szURL += strspn(szURL, " \t");
char* szVersion = strpbrk(szURL, " \t");
if (!szVersion)
{
return BAD_REQUEST;
}
*szVersion++ = '\0';
szVersion += strspn(szVersion, " \t");
if (strcasecmp(szVersion, "HTTP/1.1") != 0)
{
return BAD_REQUEST;
}
if (strncasecmp(szURL, "http://", 7) == 0)
{
szURL += 7;
szURL = strchr(szURL, '/');
}
if (!szURL || szURL[0] != '/')
{
return BAD_REQUEST;
}
//URLDecode( szURL );
printf("The request URL is: %s\n", szURL);
checkstate = CHECK_STATE_HEADER;
return NO_REQUEST;
}
//解析头部字段,读取到空行说明头部正确
HTTP_CODE parse_headers(char* szTemp)
{
if (szTemp[0] == '\0')
{
return GET_REQUEST;
}
else if (strncasecmp(szTemp, "Host:", 5) == 0)
{
szTemp += 5;
szTemp += strspn(szTemp, " \t");
printf("the request host is: %s\n", szTemp);
}
else
{
printf("I can not handle this header\n");
}
return NO_REQUEST;
}
//解析报文主函数
HTTP_CODE parse_content(char* buffer, int& checked_index, CHECK_STATE& checkstate, int& read_index, int& start_line)
{
LINE_STATUS linestatus = LINE_OK;
HTTP_CODE retcode = NO_REQUEST;
while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK)
{
char* szTemp = buffer + start_line;
start_line = checked_index;
switch (checkstate)
{
case CHECK_STATE_REQUESTLINE:
{
retcode = parse_requestline(szTemp, checkstate);
if (retcode == BAD_REQUEST)
{
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER:
{
retcode = parse_headers(szTemp);
if (retcode == BAD_REQUEST)
{
return BAD_REQUEST;
}
else if (retcode == GET_REQUEST)
{
return GET_REQUEST;
}
break;
}
default:
{
return INTERNAL_ERROR;
}
}
}
if (linestatus == LINE_OPEN)
{
return NO_REQUEST;
}
else
{
return BAD_REQUEST;
}
}
int main(int argc, char* argv[])
{
const char *ip = "127.0.0.1";
int port = 8888;
// if (argc <= 2)
// {
// printf("usage: %s ip_address port_number\n", basename(argv[0]));
// return 1;
// }
// const char* ip = argv[1];
// int port = atoi(argv[2]);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET, ip, &address.sin_addr);
address.sin_port = htons(port);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
int ret = bind(listenfd, (struct sockaddr*) & address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int fd = accept(listenfd, (struct sockaddr*) & client_address, &client_addrlength);
if (fd < 0)
{
printf("errno is: %d\n", errno);
}
else
{
char buffer[BUFFER_SIZE];
memset(buffer, '\0', BUFFER_SIZE);
int data_read = 0;
int read_index = 0;
int checked_index = 0;
int start_line = 0;
CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE;
while (1)
{
data_read = recv(fd, buffer + read_index, BUFFER_SIZE - read_index, 0);
cout<<buffer<<endl;
if (data_read == -1)
{
printf("reading failed\n");
break;
}
else if (data_read == 0)
{
printf("remote client has closed the connection\n");
break;
}
read_index += data_read;
HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line);
if (result == NO_REQUEST)
{
continue;
}
else if (result == GET_REQUEST)
{
send(fd, szret[0], strlen(szret[0]), 0);
break;
}
else
{
send(fd, szret[1], strlen(szret[1]), 0);
break;
}
}
close(fd);
}
close(listenfd);
return 0;
}
四、运行
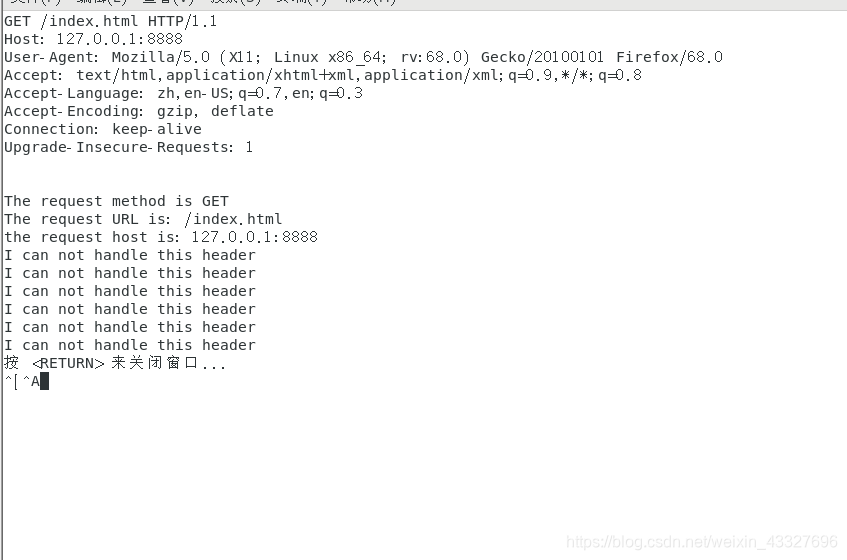
首先服务器上运行解析HTTP请求的代码,
客户端发送HTTP请求: 1、可以通过命令行: curl 127.0.0.1:8888/url url可以随便写,也可以空着
2、可以通过浏览器发起http请求: 地址栏输入: 127.0.0.1:8888/index.html
服务器运行结果:
14.如果解析http请求的时候,用户一次性没传完数据,(如果头部都没传完,请求报文长度字段都没传完,怎么办)
当用户一次性没有传完整个HTTP请求报文时,HTTP解析器可能会遇到以下情况:
- 请求头部未传完:在等待请求头部的状态下,如果读取的数据不足以解析出完整的请求头部,则可以等待更多数据到达,直到能够解析出完整的请求头部为止。如果连接已经关闭或者超时,则可以返回一个错误或异常。
- 请求体未传完(Content-Length):在等待消息体的状态下,如果读取的数据不足以满足Content-Length指定的长度,则可以继续等待更多数据到达,并将其存储在缓冲区中。当读取到足够数量的字节后,就可以开始处理HTTP消息体。如果连接已经关闭或者超时,则可以返回一个错误或异常。
- 请求体未传完(Transfer-Encoding):在等待消息体的状态下,如果使用了Transfer-Encoding进行编码,则需要根据当前编码类型和剩余数据量来判断是否需要等待更多数据。例如,在chunked编码中,每个块都有一个长度字段用于指示块大小,因此解析器可以依次读取每个块并将其存储在缓冲区中。当所有块都被读取完成后,解析器会跳转到processing complete状态并返回结果给调用者。
15.路由表说一下
1.概述
在计算机网络中,路由器的主要工作就是为经过路由器的每个数据包寻找一条最佳的传输路径,并将该数据有效地传送到目的站点。为了能够实现从众多路径中选择最佳的传输路径,路由器中保存了周边网络的拓扑信息和各种路径参数,我们将这张表称作路由表。路由表(routing table)或称路由择域信息库(RIB, Routing Information Base),是一个存储在路由器或者联网计算机中的电子表格(文件)或类数据库。路由表存储着指向特定网络地址的路径(在有些情况下,还记录有路径的路由度量值)。路由表建立的主要目标是为了实现路由协议和静态路由选择。
在每一个路由器设备中,通常都维护了两张比较相似的表,分别为:
- 路由信息表,简称为RIB表、路由表
- 转发信息表, 简称为FIB表、转发表
路由表(RIB表)用来决策路由;转发表用来转发分组🎡
2.命令
查询RIB表:
┌──(root㉿kali)-[~/Desktop]
└─# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.18.2 0.0.0.0 UG 100 0 0 eth0
192.168.18.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
查询FIB表:
┌──(root㉿kali)-[~/Desktop]
└─# route -F
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.18.2 0.0.0.0 UG 100 0 0 eth0
192.168.18.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
由于是主机设备,路由表比较简单,且不存在多个出接口,因此FIB表和RIB是相同的。
3.路由表项内容
目的网络地址(Destination) + 子网掩码(Genmask)
网络地址和网络掩码共同确定本机可以达到的目的网络范围
通常情况下,目的网络范围包含以下几种情况:
- 主机地址:某个特定主机的网络地址
- 子网地址:某个特定子网的网络地址
- 默认路由:所有未在路由表中指定的网络地址,用0.0.0.0统一匹配,用于配置默认网关(kali虚拟机中默认路由显示为default)
网关(Gateway)+ 下一跳(Next Hop)
接口(Iface)
接口定义了针对特定的网络目的地址,路由器用于转发数据包的出接口。即用来确定数据包从哪个网口上发送到下一跳设备
跳数(Metric)
跳数用于指出路由的成本,通常情况下代表:到达目标地址所需要的总路由器个数,一个跳数代表经过一个路由器,IP数据报首部中的TTL字段就是该数据报所能存活的总跳数。跳数越少往往代表着该路由成本越低,跳数越多则说明成本越高。当具有多条达到相同目的网络的路由选项时,路由算法会选择具有更少跳数的路由
标志(Flags)
路由表中常见的flag标记有:
- U:路由是动态的;
- H:目标是一个主机;
- G:路由指向网关;
- R:恢复动态路由产生的表项;
- D:由路由的后台程序动态安装;
- M:由路由的后台程序修改;
- !: 拒绝路由。
引用次数(Ref)
Linux内核中未使用,一般是0
查询次数(Use)
此路由项被路由软件查找的次数
16.路由表为空怎么找到下一跳
当路由器收到一个待转发的数据报,在从路由表得出下一跳路由器的IP地址后,不是把这个地址填入IP数据报,而是送交数据链路层的网络接口软件。网络接口软件负责把下一跳路由器的IP地址转换成硬件地址(必须使用ARP),并将此硬件地址放在链路层的MAC帧的首部,然后根据这个硬件地址找到下一个路由器。由此可见,当发送一连串的数据报时,上述的这种查找路由表,用ARP得到硬件地址,把硬件地址写入MAC帧的首部等过程,将不断得进行重复,造成一定的开销。
那能否在路由表中不使用IP地址而直接使用硬件地址呢? 答案是不可以的,因为我们使用抽象的IP地址,本来是为了隐藏各种底层网络的复杂性而便于分析和研究问题,这样就不可避免要付出代价,例如在选择路由时多了一些开销,但是反过来,如果在路由表中直接使用硬件地址,会带来更多的麻烦
17.粘包拆包是什么,发生在哪一层
1 什么是粘包
在学习粘包之前,先纠正一下读音,很多视频教程中将“粘”读作“nián”。经过调研,个人更倾向于读“zhān bāo”。
如果在百度百科上搜索“粘包”,对应的读音便是“zhān bāo”,语义解释为:网络技术术语。指TCP协议中,发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
TCP是面向字节流的协议,就是没有界限的一串数据,本没有“包”的概念,“粘包”和“拆包”一说是为了有助于形象地理解这两种现象。
2 为什么UDP没有粘包
粘包拆包问题在数据链路层、网络层以及传输层都有可能发生。日常的网络应用开发大都在传输层进行,由于UDP有消息保护边界,不会发生粘包拆包问题,因此粘包拆包问题只发生在TCP协议中。
3 粘包拆包发生场景
因为TCP是面向流,没有边界,而操作系统在发送TCP数据时,会通过缓冲区来进行优化,例如缓冲区为1024个字节大小。
如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包。
关于粘包和拆包可以参考下图的几种情况:
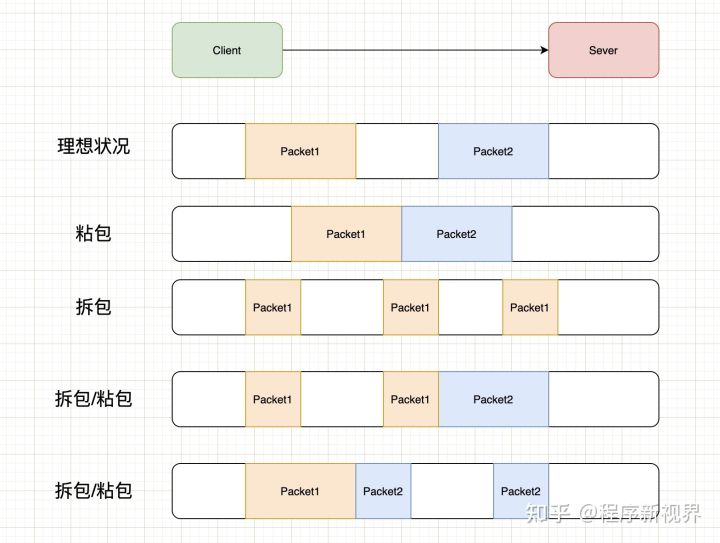
上图中演示了以下几种情况:
- 正常的理想情况,两个包恰好满足TCP缓冲区的大小或达到TCP等待时长,分别发送两个包;
- *粘包:两个包较小,间隔时间短,发生粘包,合并成一个包发送;*
- *拆包:一个包过大,超过缓存区大小,拆分成两个或多个包发送;*
- *拆包和粘包:Packet1过大,进行了拆包处理,而拆出去的一部分又与Packet2进行粘包处理。*
4 常见的解决方案
对于粘包和拆包问题,常见的解决方案有四种:
- **发送端将每个包都封装成固定的长度,**比如100字节大小。如果不足100字节可通过补0或空等进行填充到指定长度;
- 发送端在每个包的末尾使用固定的分隔符,例如\r\n。如果发生拆包需等待多个包发送过来之后再找到其中的\r\n进行合并;例如,FTP协议;
- 将消息分为头部和消息体,头部中保存整个消息的长度,只有读取到足够长度的消息之后才算是读到了一个完整的消息;
- *通过自定义协议进行粘包和拆包的处理。*
5 Netty对粘包和拆包问题的处理
Netty对解决粘包和拆包的方案做了抽象,提供了一些解码器(Decoder)来解决粘包和拆包的问题。如:
- LineBasedFrameDecoder:以行为单位进行数据包的解码;
- DelimiterBasedFrameDecoder:以特殊的符号作为分隔来进行数据包的解码;
- FixedLengthFrameDecoder:以固定长度进行数据包的解码;
- LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议(最常用);
基于Netty进行网络读写的程序,可以直接使用这些Decoder来完成数据包的解码。对于高并发、大流量的系统来说,每个数据包都不应该传输多余的数据(所以补齐的方式不可取),LenghtFieldBasedFrameDecode更适合这样的场景。
6 小结
TCP协议粘包拆包问题是因为TCP协议数据传输是基于字节流的,它不包含消息、数据包等概念,需要应用层协议自己设计消息的边界,即消息帧(Message Framing)。如果应用层协议没有使用基于长度或者基于终结符息边界等方式进行处理,则会导致多个消息的粘包和拆包。
虽然很多框架中都有现成的解决方案,比如Netty,但底层的原理我们还是要清楚的,而且还要知道有这么会事,才能更好的结合场景进行使用。
18.TCP在什么情况下会出现大量time_wait,哪个阶段出现
我们首先要弄清楚TIME_WAIT状态是什么?TIME_WAIT状态是主动关闭TCP连接的一方(即先发起FIN包的一方),在发送完最后一个ACK包后进入的状态。系统需要在TIME_WAIT状态下等待2MSL(maximum segment lifetime )后才能释放连接(端口)。根据RFC 793 MSL是2分钟,一般的TCP实现有30秒、1分钟和2分钟不等。进入TIME_WAIT状态等待2MSL主要有两个目的:一方面是主动关闭连接的一方在对方没有收到最后一个ACK包时(这时对方还会重发FIN,收到两个FIN的时间间隔一定小于2MSL)有时间可以重发ACK包,另一方面处于TIME_WAIT的连接(IP和端口组合)不能重用,这样可以保证被重新分配的socket不会受到之前残留的延迟重发报文影响。
由于主动关闭TCP连接的一方才会进入TIME_WAIT状态,一般情况服务器端不会出现TIME_WAIT状态,因为大多数情况都是客户端主动发起连接并主动关闭连接。但是某些服务如pop/smtp、ftp却是服务端收到客户端的QUIT命令后主动关闭连接,这就造成这类服务器上容易出现大量的TIME_WAIT状态的连接,而且并发量越大处于此种状态的连接越多。另外,对于被动关闭连接的服务在主动关闭客户端非法请求或清理长时间不活动的连接时(这种情况很可能是客户端程序忘记关闭连接)也会出现TIME_WAIT的状态。
19.TCP 包头字段... 标志位-> 建立连接过程,终止连接过程-> TIME_WAIT, CLOSE_WAIT 分析,属于哪一方?
TCP包头中的标志位有URG(紧急数据)、ACK(确认)、PSH(推送)、RST(重置连接)、SYN(同步序号)和FIN(结束)。
建立连接过程中,客户端首先向服务器发送一个SYN标志位的TCP包,表示请求建立连接。服务器在收到该包后,会回复一个SYN+ACK的TCP包,表示已收到请求并同意建立连接。最后,客户端再回复一个ACK标志位的TCP包进行确认。
终止连接过程中,一方需要向另一方发送一个FIN标志位的TCP包来表示要关闭连接。接收到FIN标志位的一方会回复一个ACK标志位的TCP包进行确认,并进入CLOSE_WAIT状态或TIME_WAIT状态。如果是主动发起关闭连接的一方,则会进入TIME_WAIT状态;如果是被动响应关闭连接请求的一方,则会进入CLOSE_WAIT状态。
在TIME_WAIT和CLOSE_WAIT状态下,均属于被动响应关闭请求的一方。在这两个状态下,通信双方都不能发送新数据,但是仍然能够接收对方发送来的数据。在经过一定时间后,处于TIME_WAIT状态的一方才能彻底释放资源,并完成与对方断开连接;而处于CLOSE_WAIT状态的一方则需要等待对方最终关闭连接才能彻底释放资源。
20.TCP 建立连接过程 -> SYN + ACK 包能不能拆开来发
TCP建立连接过程中,客户端向服务器发送SYN标志位的TCP包,而服务器在收到该包后需要回复一个SYN+ACK标志位的TCP包。这个SYN+ACK包不能拆开来发,因为它是一个整体,其中既包含了SYN标志位表示同意建立连接,又包含了ACK标志位表示确认客户端的请求。
如果将SYN和ACK分别单独发送,则无法保证通信的可靠性。因为只有当服务器同时收到了客户端发送的SYN和确认收到该SYN的ACK才能确认建立连接成功,并开始进行数据传输。如果SYN和ACK不是同时被接收到,则无法建立正确的连接。
因此,在TCP建立连接过程中,必须按照规定格式发送完整的SYN+ACK包才能够成功建立连接。
21.讲讲quic/听说过哪些快速重传算法/timewait状态干啥用的
TCP中的快速重传算法主要有以下几种:
- SACK(Selective Acknowledgment)算法:允许接收方向发送方反馈丢失数据包的序列号,从而避免不必要的重传。
- FACK(Forward Acknowledgment)算法:在接收方缓存区有空间时,可以提前向发送方发送确认信息,告诉它哪些数据已经成功接收。
- D-SACK(Duplicate Selective Acknowledgment)算法:当发生数据包乱序或丢失时,不仅通知发送方这个事实,还向其指出该问题所在的数据段和丢失/乱序的字节位置。
- TCP NewReno:相比于早期TCP Reno,在检测到快速重传事件后采取了更好的措施来恢复拥塞窗口大小,并在一定程度上优化了网络吞吐量。
22.提到了TCP,黏包怎么解决?(固定包头接收,指定内存长度)
黏包问题是指在传输过程中多个数据包被合并成了一个或者一个数据包被拆分成了多个,造成接收方无法正确解析。解决黏包问题的方法主要有以下两种:
- 固定包头接收:发送方在每个数据包前加上固定长度的头部信息,接收方先读取头部信息获取数据包长度,再根据长度截取对应的数据。这样可以保证每次接收到的数据都是完整的。
- 指定内存长度:发送方在每个数据包前不添加任何头部信息,而是在尾部添加一个特殊字符(例如换行符“\n”),接收方按照特殊字符进行切割,并且预先给缓存区分配足够长的空间来容纳整个消息。这样也能确保接收到的数据都是完整的。
23.查看网络状况(以为是netstate,其实是ping、traceroute,紧张忘记说了)
- 使用ping命令:在命令行中输入“ping + 目标IP地址或域名”,回车后会显示与目标主机之间的网络延迟和数据包传输情况。如果出现丢包现象,则说明网络存在问题。
- 使用tracert命令:在命令行中输入“tracert + 目标IP地址或域名”,回车后会显示到达目标主机所经过的路由节点,以及每个节点的延迟时间。通过分析延迟时间可以确定网络问题出现的位置。
- 使用网络性能监视器:操作系统自带了一些网络性能监视工具,如Windows下的资源监视器、Linux下的iftop等,可以实时监测网络流量、带宽利用率、连接数等指标,有助于发现和解决网络问题。
- 使用第三方网络工具:还有许多第三方的网络检测工具,如Wireshark、NetScanTools等,这些工具提供更详细和全面的信息来帮助用户诊断和调试网络故障。
24.抓包工具?(wireshark,紧张又给忘了靠)
一、Wireshark抓包介绍
1、WireShark简介
Wireshark是一个网络封包分析软件。网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料。Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换。
2、 WireShark的应用
网络管理员使用Wireshark 来检测网络问题, 网络安全工程师使用Wireshark来检查资讯安全相关问题, 开发者使用Wireshark 来为新的通讯协议除错, 普通使用者使用Wireshark来学习网络协议的相关知识。 当然,有的人也会“居心叵测”的用它来寻找一些敏感信息…
3、 WireShark抓数据包技巧
- (1)确定Wireshark的物理位置。如果没有一个正确的位置,启动Wireshark后会花费很长的时间捕获一些与自己无关的数据。
- (2)选择捕获接口。一般都是选择连接到Internet网络的接口,这样才可以捕获到与网络相关的数据。否则,捕获到的其它数据对自己也没有任何帮助。
- (3)使用捕获过滤器。通过设置捕获过滤器,可以避免产生过大的捕获数据。这样用户在分析数据时,也不会受其它数据干扰。而且,还可以为用户节约大量的时间。e
- (4)使用显示过滤器。通常使用捕获过滤器过滤后的数据,往往还是很复杂。为了使过滤的数据包再更细致,此时使用显示过滤器进行过滤。火
- (5)使用着色规则。通常使用显示过滤器过滤后的数据,都是有用的数据包。如果想更加突出的显示某个会话,可以使用着色规则高亮显示。
- (6)构建图表。如果用户想要更明显的看出一个网络中数据的变化情况,使用图表的形式可以很方便的展现数据分布情况。
- (7)重组数据。当传输较大的图片或文件时,需要将信息分布在多个数据包中。这时候就需要使用重组数据的方法来抓取完整的数据。Wireshark的重组功能,可以重组一个会话中不同数据包的信息,或者是重组一个完整的图片或文件。
二、Wireshark抓包入门操作
1、常见协议包
本节课主要分析以下几种协议类型。
- ARP协议
- ICMP协议
- TCP协议
- UDP协议
- DNS协议
- HTTP协议
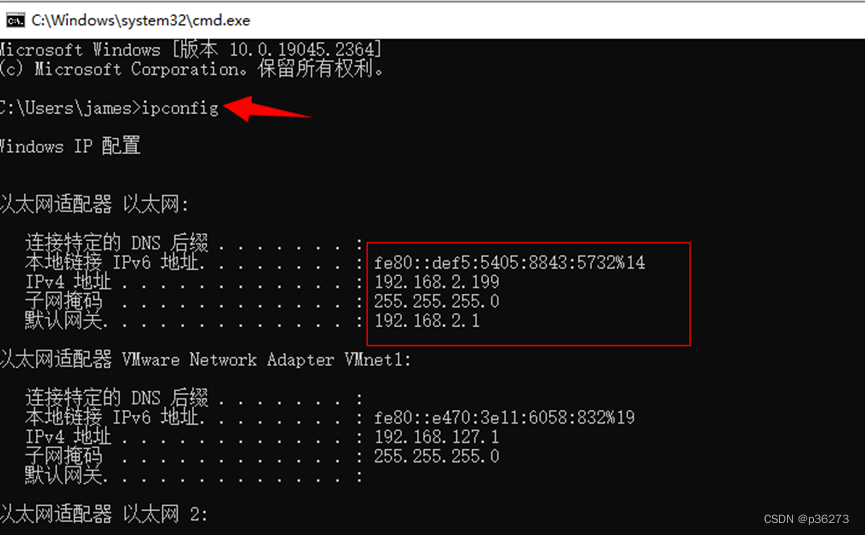
2、查看本机要抓包的网络
- 输入指令ipconfig找到对应的网络
3、混杂模式介绍
- 混杂模式概述:混杂模式就是接收所有经过网卡的数据包,包括不是发给本机的包,即不验证MAC地址。普通模式下网卡只接收发给本机的包(包括广播包)传递给上层程序,其它的包一律丢弃。
- 一般来说,混杂模式不会影响网卡的正常工作,多在网络监听工具上使用。
4、如何开起混杂模式
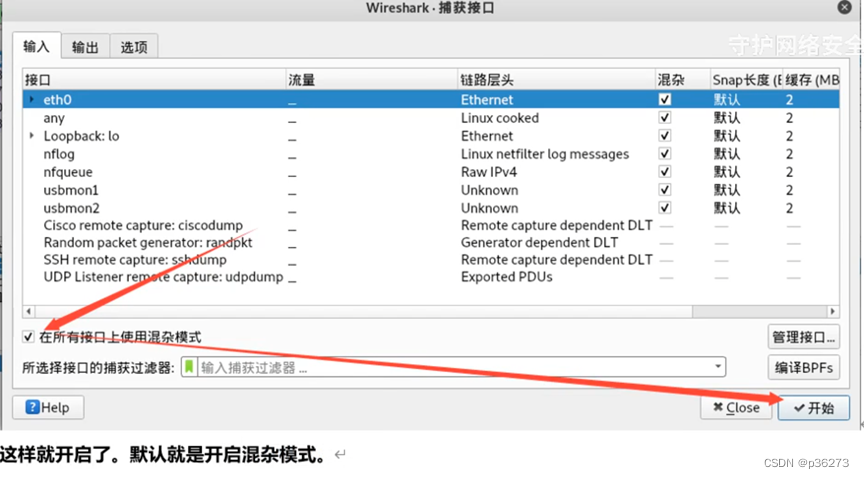
三、Wireshark过滤器使用
1、开启以上的混淆模式,抓取接口上使用混杂模式直接进行抓包
例1:对TCP协议的包进行筛选
例2:筛选出ACK相关的包 。SYN=1、ACK=0:客户端请求向服务端建立连接。
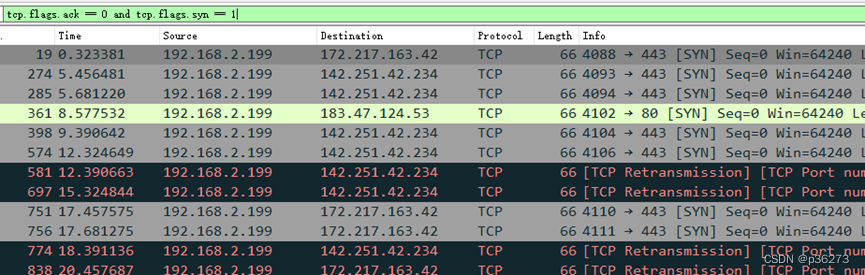
例3:抓取指定条件的包。tcp.flags.fin == 1 当 FIN=1 时,表明数据已经发送完毕,要求释放连接
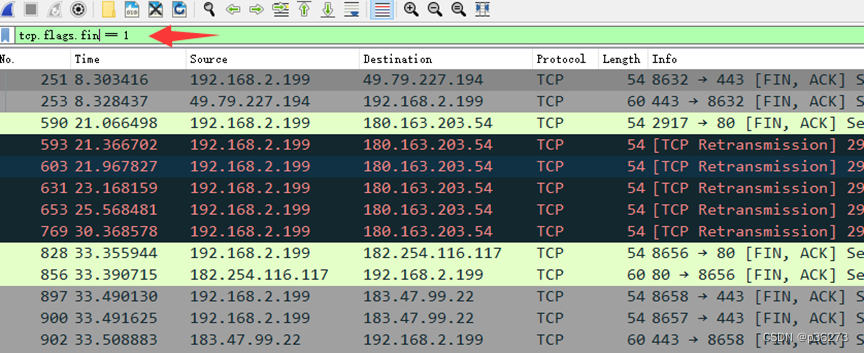
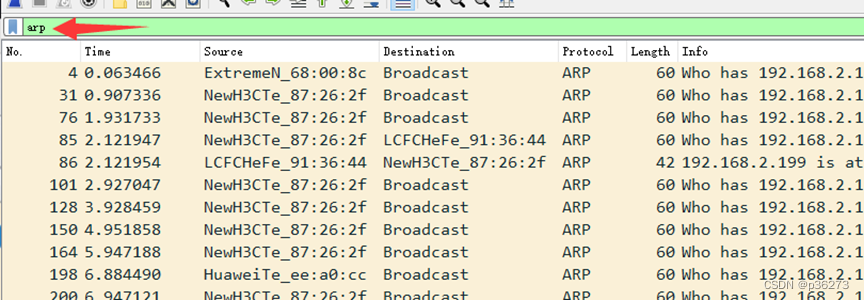
例4:筛选出ARP数据包
例5:筛选出udp属于传输层的数据包
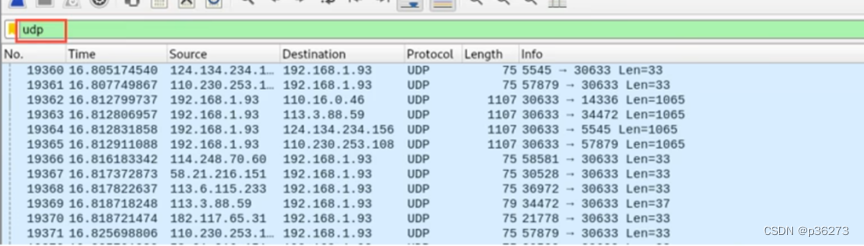
我们使用过滤器输入“udp”以筛选出udp报文。但是为什么输入udp之后出现那么多种协议呢?原因就是oicq以及dns都是基于udp的传输层之上的协议
扩展:客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。不用经过三次握手,这样DNS服务器负载更低,响应更快。理论上说,客户端也可以指定向DNS服务器查询时用TCP,但事实上,很多 DNS服务器进行配置的时候,仅支持UDP查询包。
例6:http请求

例7:dns数据包
例8:数据包条件筛选 其实我们不仅可以对协议类型进行筛选,我们还有跟多的筛选条件,比如源地址目的地址等等例6:筛选源地址是192.168.1.53或目的地址是192.168.1.1
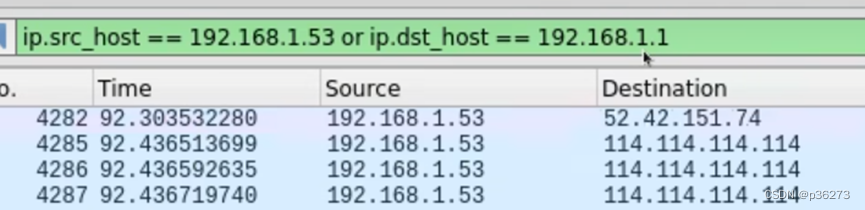
例9:本机向外发或接受的所有数据包

四、ARP协议
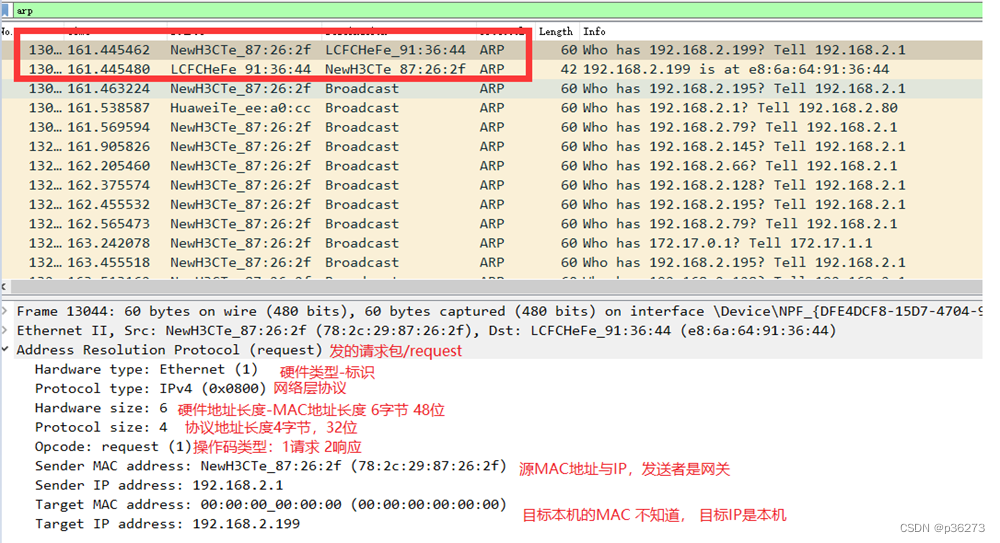
1、Arp协议解读
- 协议分析的时候我们关闭混淆模式,避免一些干扰的数据包存在常用协议分析-ARP协议(英语:Address Resolution Protocol,细与︰AKP) 是一个通过解析网层地址来找寻数据链路层地址的网络传输协议,它在IPv4中极其重要。ARP是通过网络地址来定位MAC地址。
- 主机向目标机器发送信息时,ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址,存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
2、分析ARP包
五、ICMP抓包与解读
1、先Ping一个地址,获得ICMP包
2、再筛选过滤icmp格式包
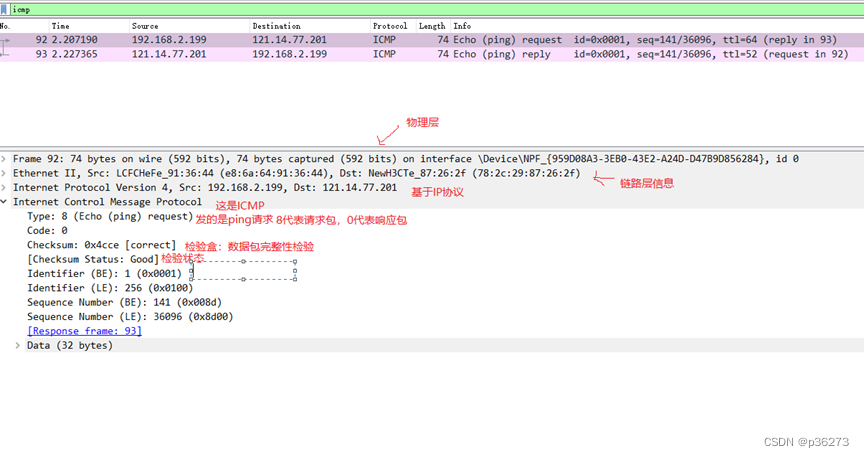
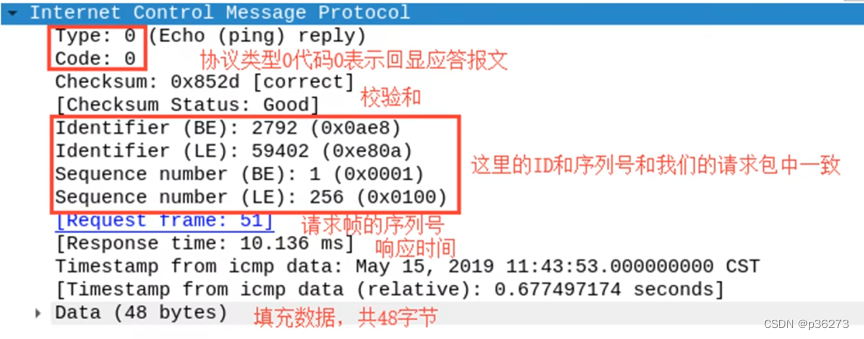 工作过程:
工作过程:
- 本机发送一个ICMP Echo Request的包
- 接收方返回一个ICMP Echo Reply,包含了接受到数据拷贝和一些其他指令
六、TCP的3次握手协议
1、清空数据包然后筛选tcp开始抓包
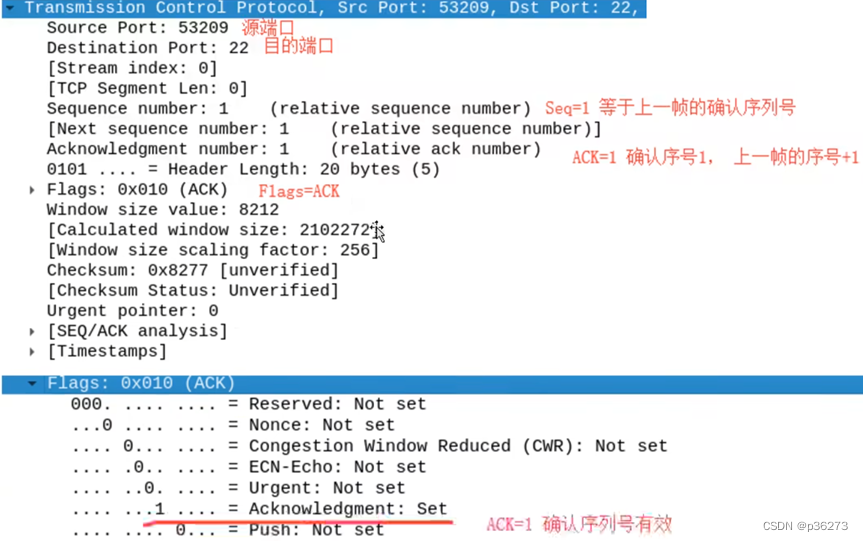
- 选中一个包,进行解读
七、TCP连接断开的4次挥手
我们分析一下过程,我们在终端输入EXIT实际上是在我们Kali 上执行的命令,表示我们SSHD的Server端向客户端发起关闭链接请求。
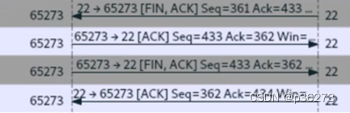
- 我们分析一下过程,我们在终端输入EXIT实际上是在我们Kali上执行的命令,表示我们SSHD的Server端向客户端发起关闭链接请求。
- 第一次挥手:
- 服务端发送一个[FIN+ACK],表示自己没有数据要发送了,想断开连接,并进入FIN_WAIT_1状态
- 第二次挥手:
- 客户端收到FIN后,知道不会再有数据从服务端传来,发送ACK进行确认,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),客户端进入CLOSE_WAIT状态.
- 第三次挥手:
- 客户端发送[FIN+ACK]给对方,表示自己没有数据要发送了,客户端进入LAST_ACK状态,然后直接断开TCP会话的连接,释放相应的资源。
- 第四次挥手:
- 服务户端收到了客户端的FIN信令后,进入TIMED_WAIT 状态并发迂
- ACK确认消息。服务端在TIMED_WAIT 状态下,等待一段时间,没有数据到来,就认为对面已经收到了自己发送的ACK并正确关闭了进入 CLOSE状态,自己也断开了TCP连接,释放所有资源。当客户端收到服务端的ACK回应后,会进入CLOSE状态并关闭本端的会话接口,释放相应资源。
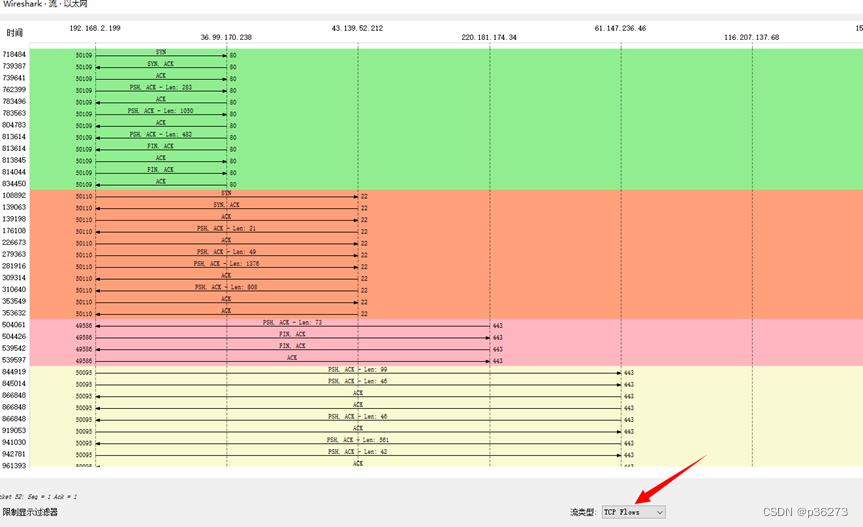
数据流的统计
八、wireshark常用过滤条件
1、常用条件
- ‘eq’和’==’ 等同
- and 并且
- or 或者
- ‘!’ 和’not’ 取反
2、针对IP地址过滤
1.源地址:ip.src == 192.168… 2.目的地址:ip.dst == 192.168.xx 3.不看源或目的地址:ip.addr == 192.168.xx
3、针对协议过滤
1.某种协议的数据包 直接输入协议名字 如:http 2.排除某种协议 not tcp 或者 !tcp
4、针对端口过滤
1.捕获某端口的数据包 tcp.port == 80 tcp.srcport == 80 tcp.dstport == 80 2.捕获多端口 udp.port >=2048
5、针对长度和内容过滤
1.长度过滤 data.len > 0 udp.lenth < 30 http.content_lenth <= 20 2.数据包内容过滤 http.request.uri matches “vipscu”(匹配http请求中含有vipscu字段的请求信息)
25.TCP 2MSL说一下,为什么
TCP 2MSL是指TCP连接关闭后,等待两倍的最大报文段生存时间(Maximum Segment Lifetime)后,才能释放该连接所占用的资源。这个时间通常为60秒左右。
TCP 2MSL存在的主要原因是防止网络上旧数据包延迟到达时被误认为是新连接,从而引起不必要的问题。当一个TCP连接关闭时,可以通过发送FIN、ACK和RST等控制报文告知对端关闭操作已完成。但由于各种因素,如网络拥堵、路由器故障或重传机制等,可能会导致已经关闭的连接在某些节点上仍然存在数据包滞留,并且可能被误认为是新连接。如果没有适当的延迟时间,这些旧数据包可能会干扰新建立的连接。
因此,在TCP 2MSL期间内维护该连接状态信息以便处理任何晚到达的报文段或复制报文段。在这段时间内如果收到了新的数据包,则需要重新开始计算2MSL时间,并持续等待更长的时间来确保所有延迟到达的数据都得到处理。
 查看6道真题和解析
查看6道真题和解析
 除了体面就只剩厂了
除了体面就只剩厂了