国内大模型LLM选择以及主流大模型快速使用教程
国内大模型LLM选择以及主流大模型快速使用教程[GLM4/Qwen/Baichuan/Coze/Kimi]
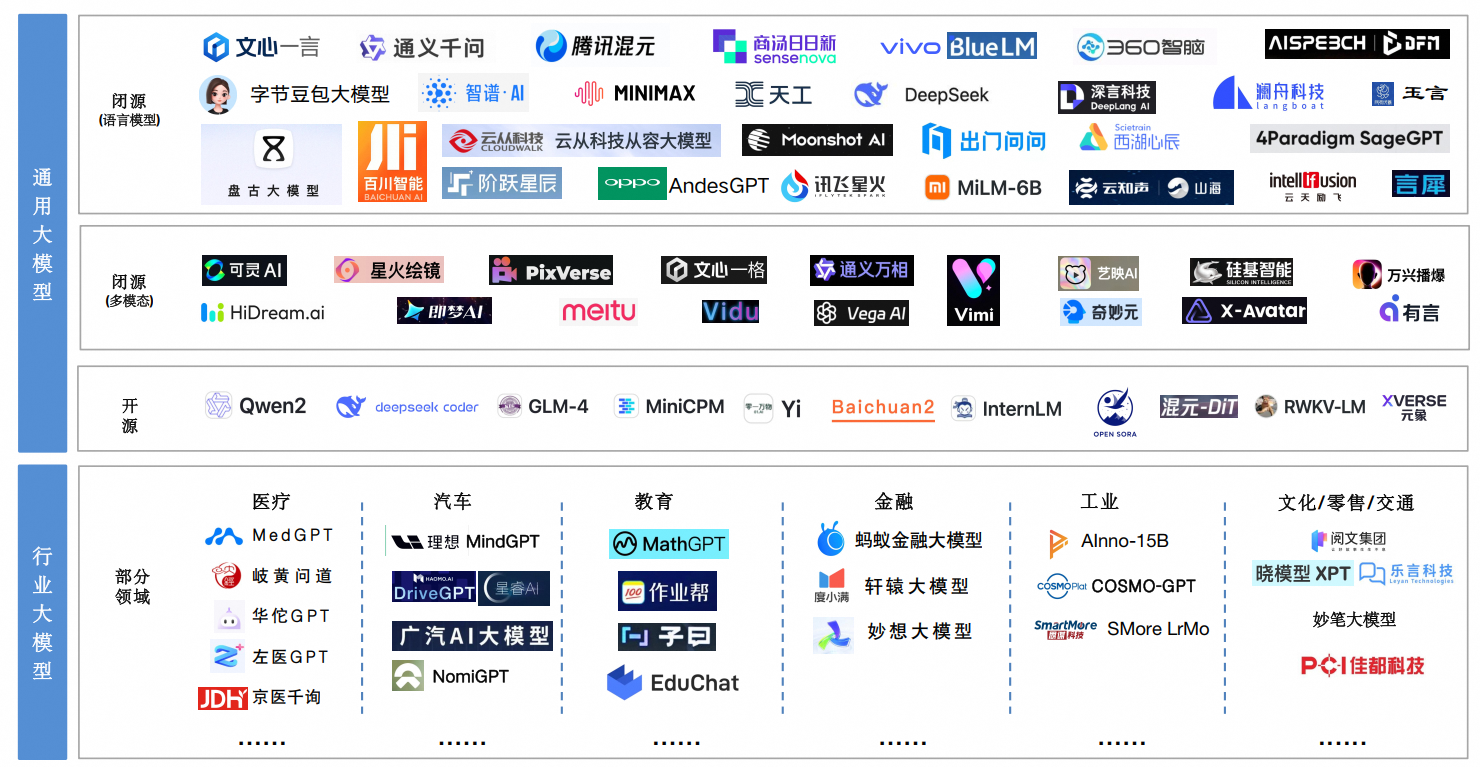
0. 大模型选择
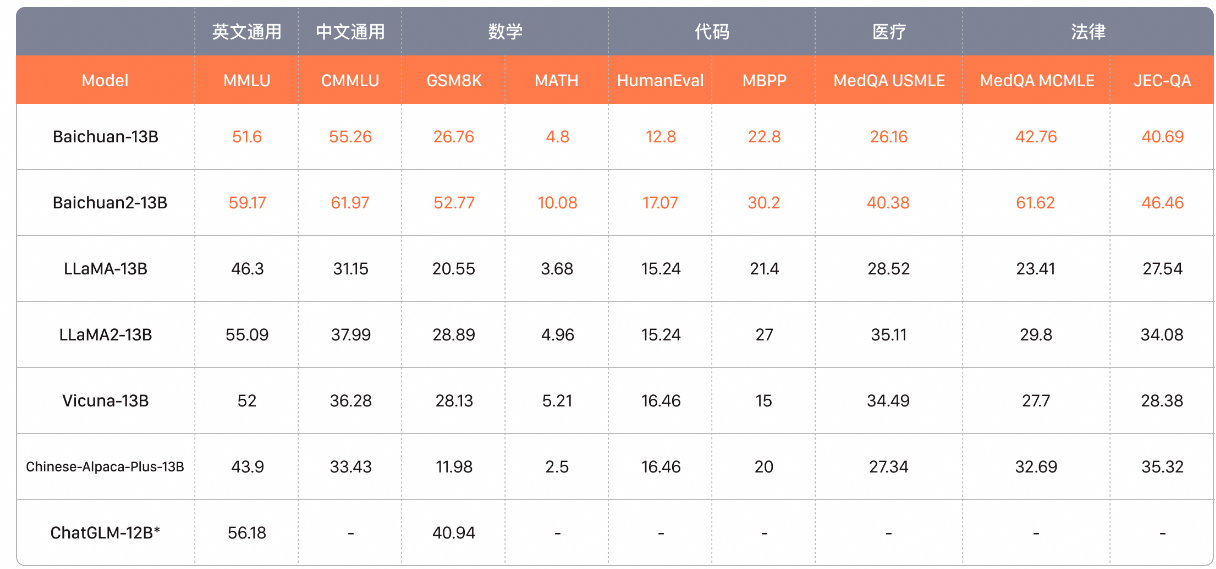
司南测评结果:
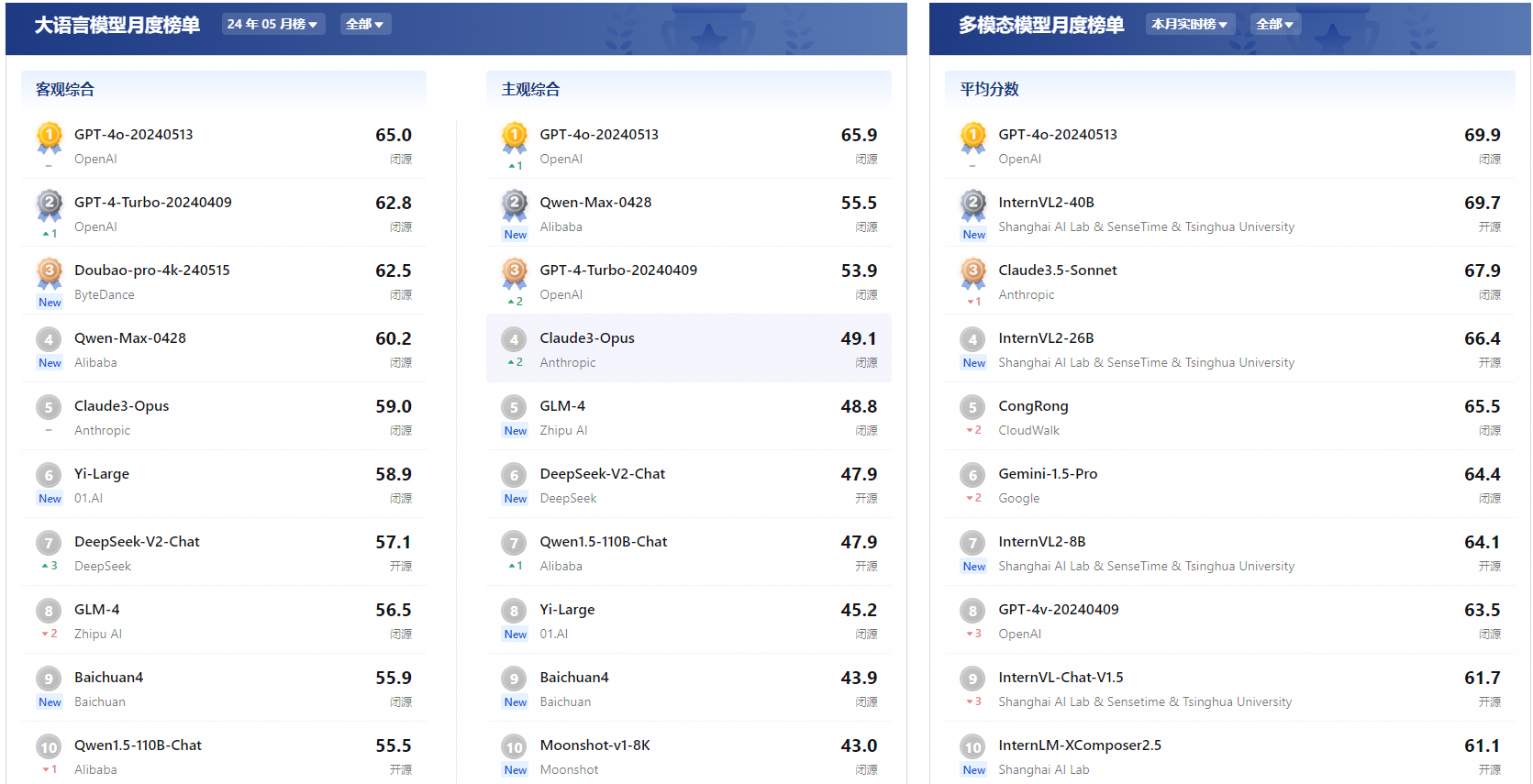
SuperCLue测评结果:
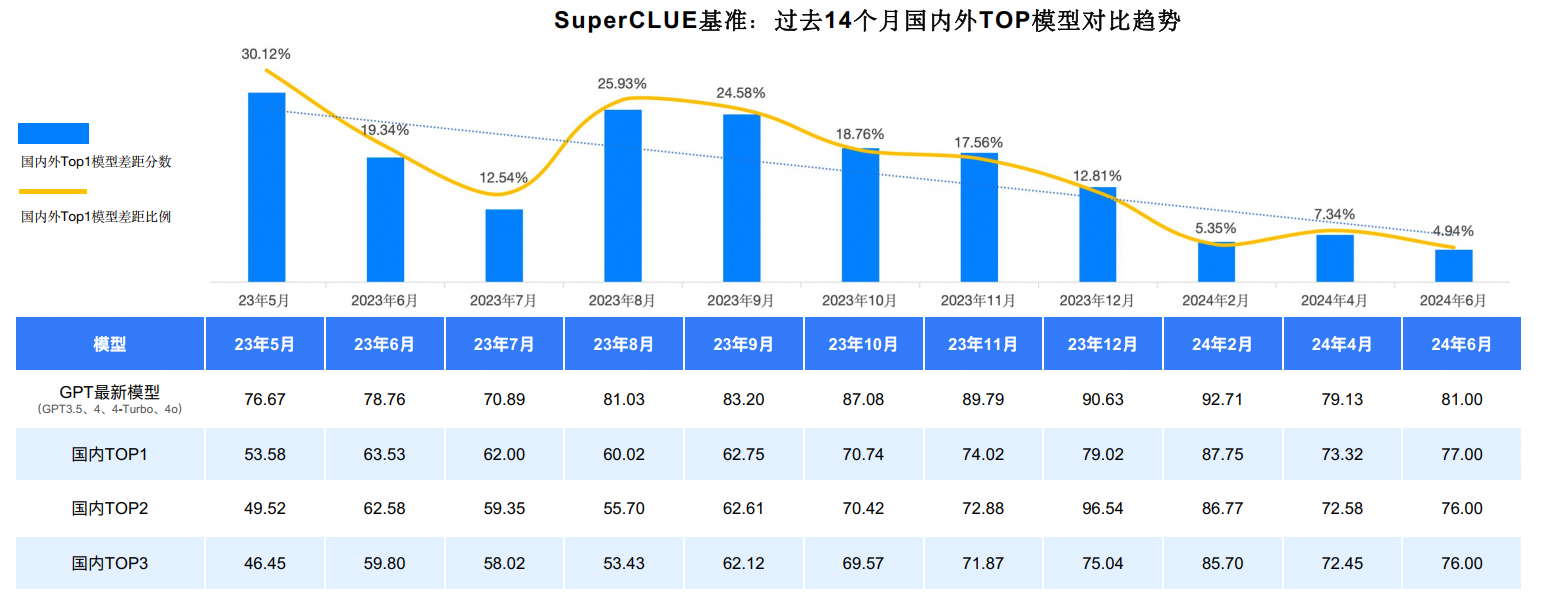
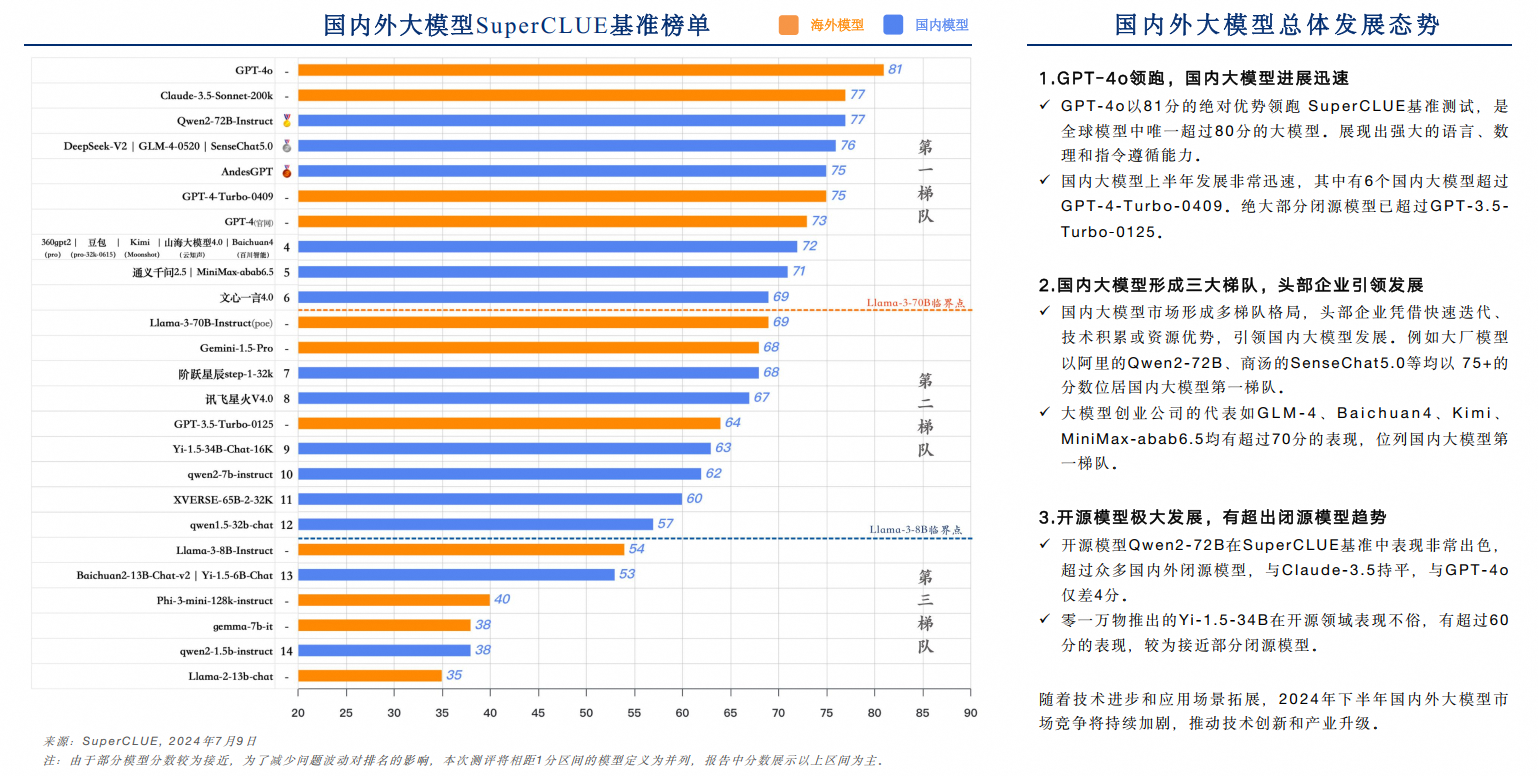
自2023年5月以来,全球及中国国内的大模型技术均展现出了强劲的发展势头,尤其是以GPT系列为代表的海外顶尖模型,历经了从GPT3.5到GPT4、GPT4-Turbo乃至GPT4o的多次迭代飞跃,持续推动AI技术的边界。与此同时,中国本土的大模型领域也经历了长达14个月的激烈竞争与快速进化,期间顶尖模型之位更迭了八次,彰显出国内技术实力的显著提升与不懈追求。
从宏观趋势来看,国内外顶尖大模型在中文处理能力上的差距正显著缩小。这一变化尤为引人注目,从2023年5月时高达30.12%的差距,到2024年6月已缩减至仅4.94%,标志着国内外大模型在中文通用能力上正逐步走向并驾齐驱的新阶段。这一成就不仅反映了中国AI技术的快速崛起,也预示着全球AI领域更加紧密的竞争与合作格局正在形成。
0.1 常见评估维度
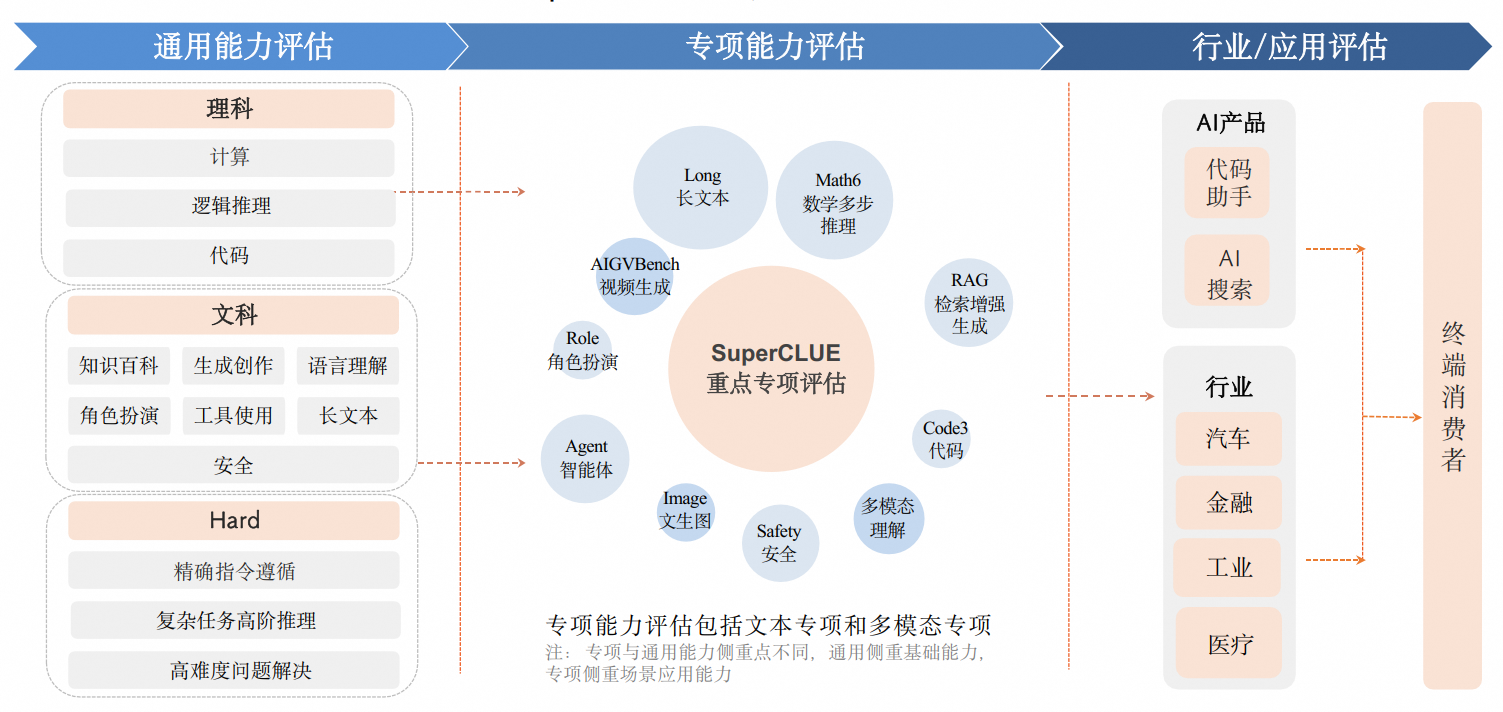

0.2 国内外大模型发展态势
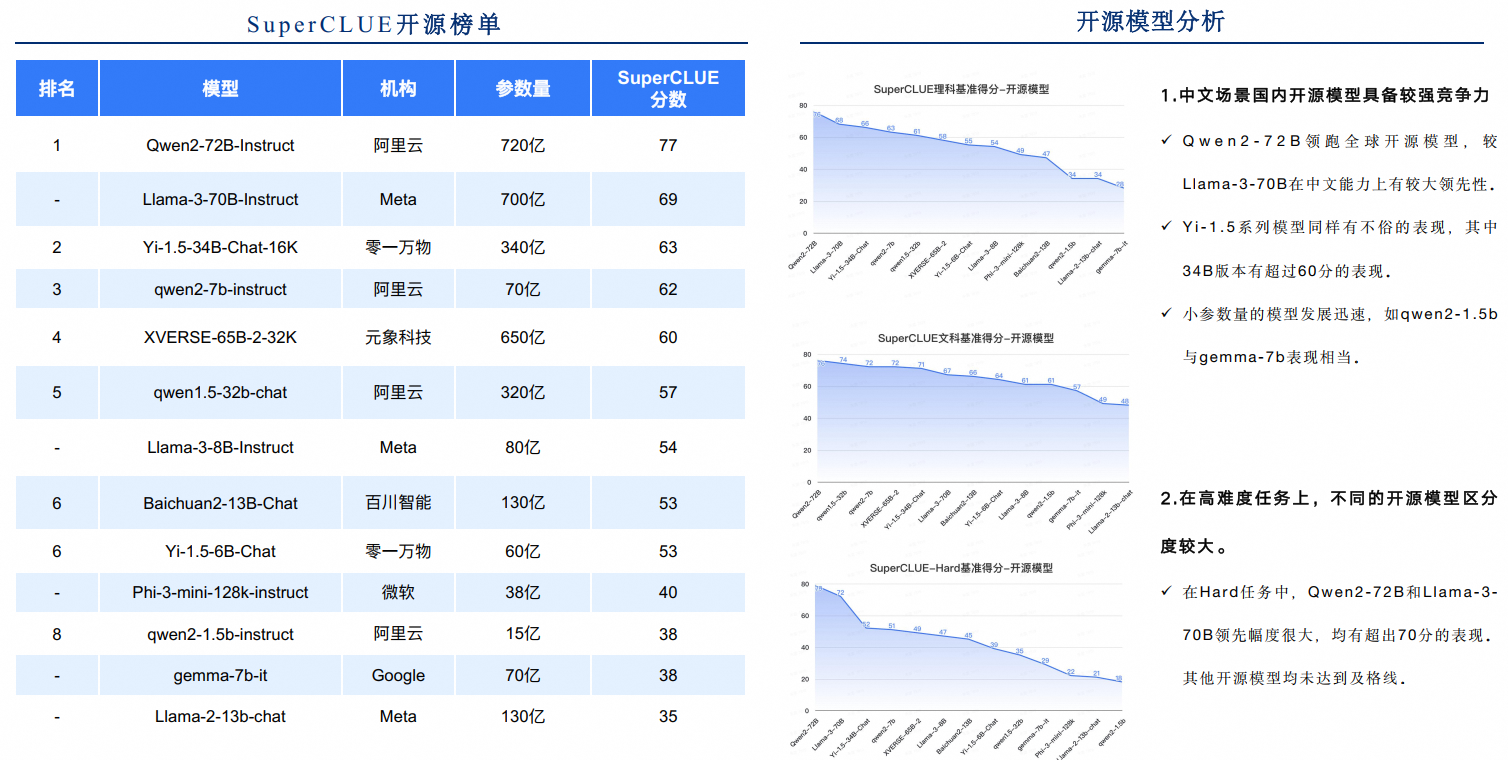
- 开源榜单
0.3 大模型评分细则


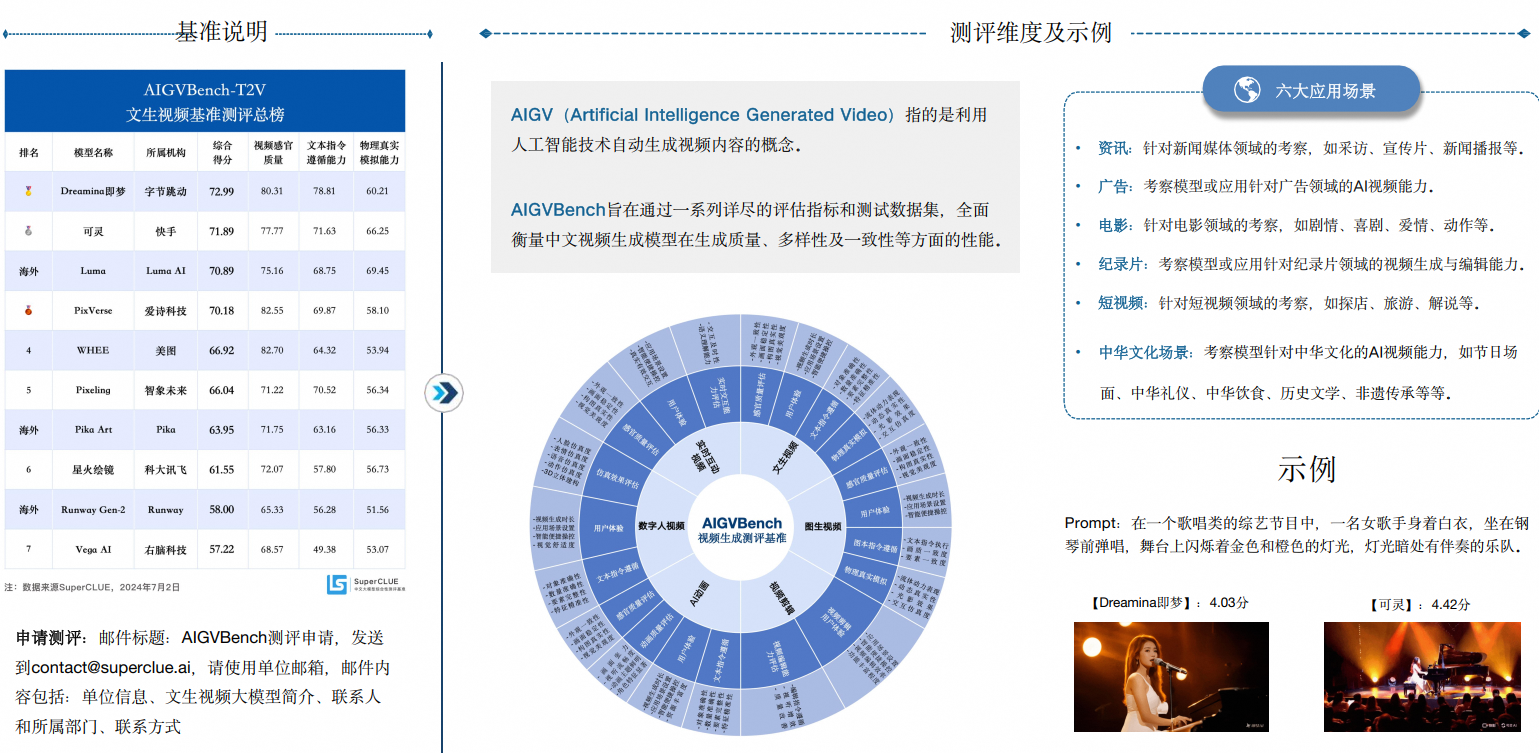
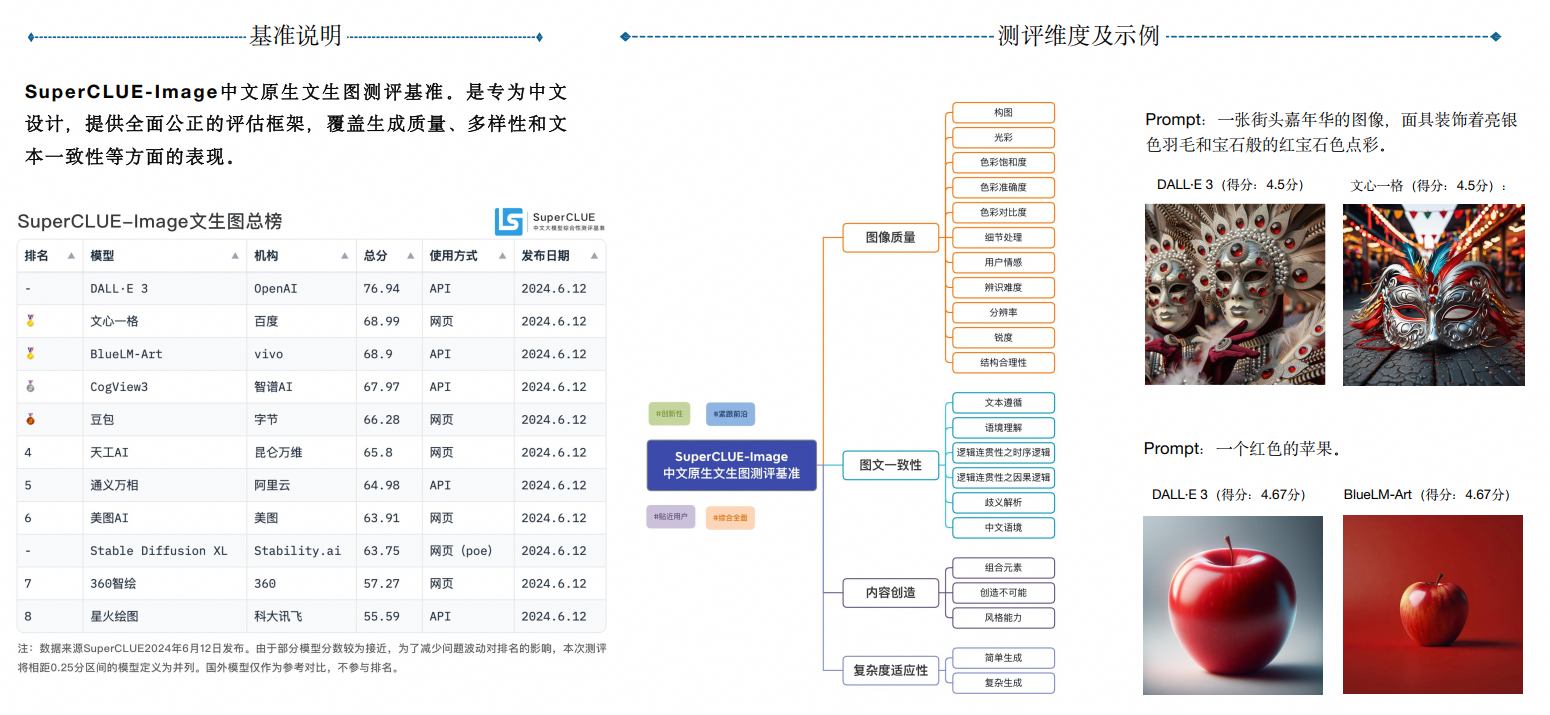
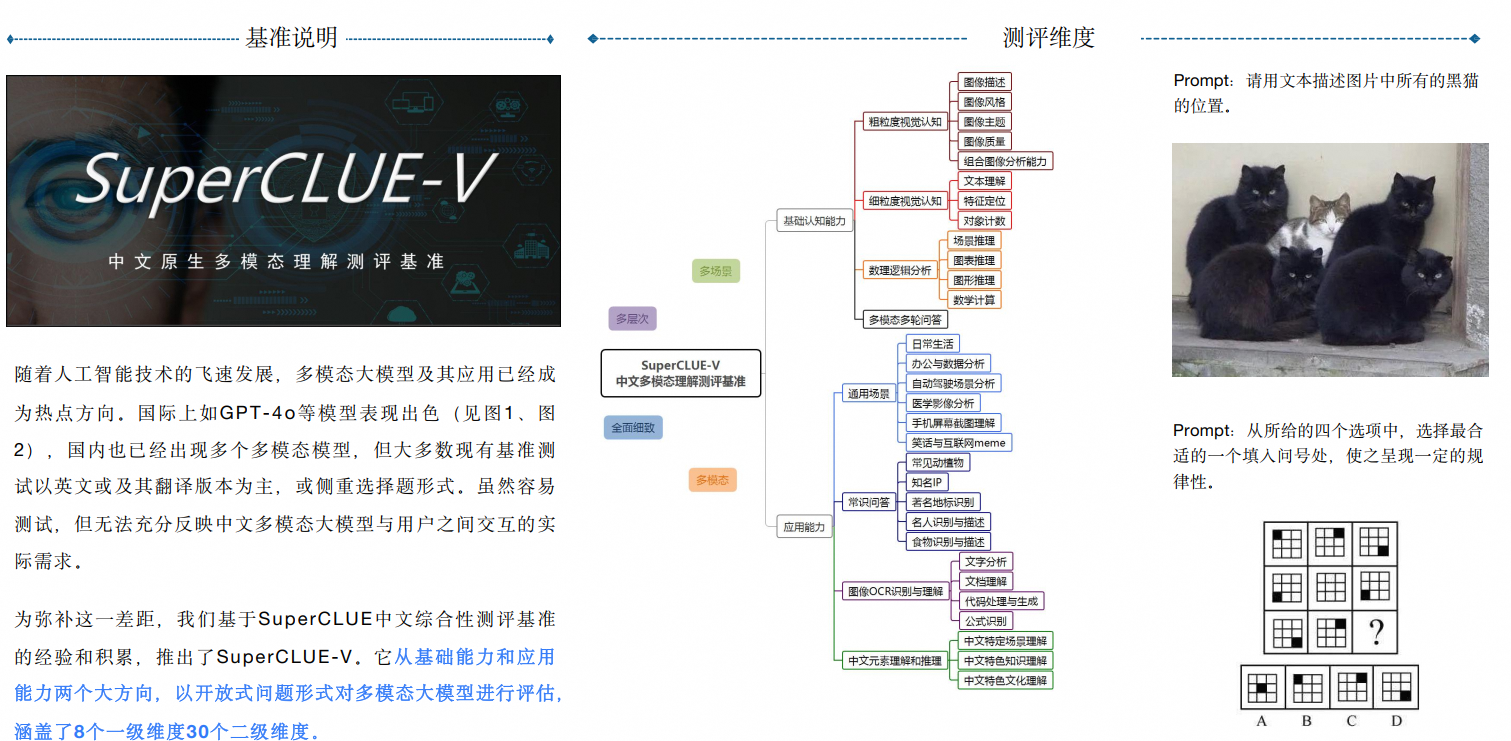
更多内容参考:SuperCLue官网
0.4 大模型选择几个维度:
- 开源闭源大模型选择:数据安全、Token成本,GPU成本
- 项目是否需要调用工具:ToolCall 工具微调
- 项目精度要求:准确度、专业、降本增效、情绪价值
- ToC:给用户提供更多情绪价值
- ToB:专业,精准
- 国内外大模型选择:数据安全、成本、速度、目标用户
使用开源大模型还是闭源大模型:如果你的应用和数据希望更加私有化,比较敏感不希望共享给大模型公司,那么你只有选择开源模型,并使用自托管的方式来运作;如果你的应用对数据敏感度不高,则可以选择闭源大模型;此外,截止到目前整体而言,闭源大模型,尤其是国外的闭源模型,其能力还是要胜过开源大模型的。AI应用是否需要类似工具调用能力: 如果你在开发类似AI Agents这一类应用,那么你需要使用针对tool call做过微调的模型,这类大模型可以识别和使用外部工具,通过function call之类来实现像GPTs那样的效果。要注意并不是所有的LLM都做了类似的微调。应用对精度的要求高低:参数越大、能力越强,7B和70B的差距就像小学生和大学生的差距一样,但是并不是所有的应用都需要大参数的大模型,比如你的应用只是简单的做一些文本处理工作,那么可能7B的部署成本和响应速度要比70B好很多。使用国内还是国外的LLM:取决于你的应用的部署,一般来说部署在国内的应用,调用国外的大模型接口也是没问题的,但是在注册、充值等方面可能面临问题。另外在头部的大模型领域,目前整体国外大模型要优于国内,所以,一切取决于对于成本、效果的权衡。
0.5 LLM能力(结构化输出、异步调用、流式调用、批处理等)
从模型是否支持工具调用、结构化输出、JSON、本地化部署这几个维度,可以看到目前langchain社区的支持情况:
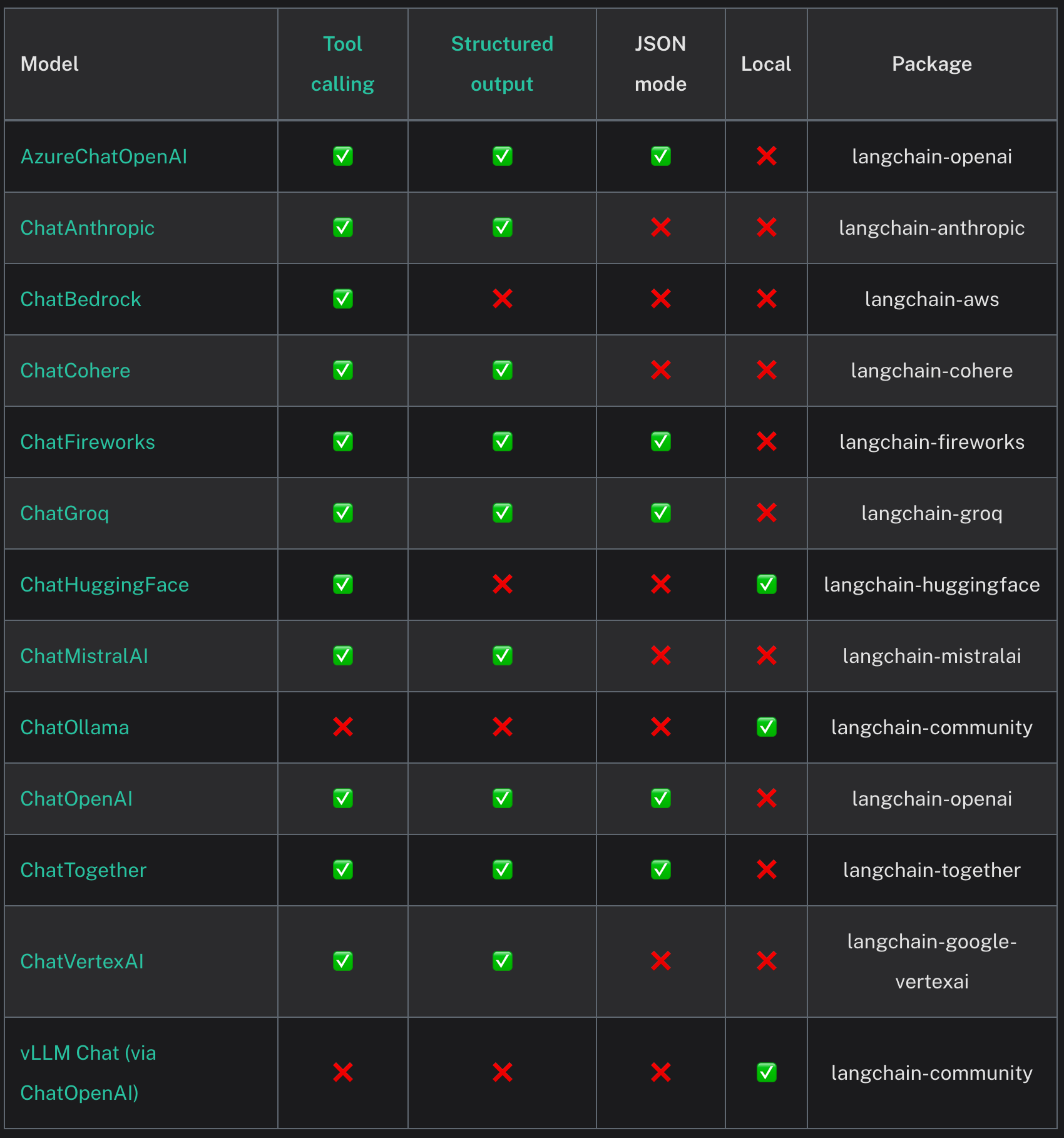
从模型是否支持普通调用、异步调用、流式调用、异步流调用、批处理和异步批处理,又可以将主流大模型再次分类。可以看到国内做的最好的是阿里通义千问

1.GLM4和通义千问实践
更多细节参考文章:初识langchain[1]:Langchain实战教学,利用qwen2.1与GLM-4大模型构建智能解决方案
1.1 普通调用
from getpass import getpass
DASHSCOPE_API_KEY = getpass()
import os
os.environ["DASHSCOPE_API_KEY"] = "sk61"
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage
chatLLM = ChatTongyi(streaming=True, )
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(
content=
"You are a helpful assistant that translates English to Chinese."),
HumanMessage(
content=
"Translate this sentence from English to Chinese. I love programming."
),
]
res = chatLLM(messages)
print(res)
1.2 通义千问支持Tools Calling
from getpass import getpass
DASHSCOPE_API_KEY = getpass()
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-"
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
llm = ChatTongyi(model="qwen-turbo")
llm_with_tools = llm.bind_tools([multiply])
msg = llm_with_tools.invoke("5乘以32的结果是多少?").tool_calls
print(msg)
- 输出结果 得到了入参
[{'name': 'multiply', 'args': {'first_int': 5, 'second_int': 32}, 'id': '', 'type': 'tool_call'}]
1.3 将工具结果输入给大模型
from langchain_core.messages import HumanMessage, ToolMessage
messages = [HumanMessage(query)]
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
for tool_call in ai_msg.tool_calls:
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
tool_output = selected_tool.invoke(tool_call["args"])
messages.append(ToolMessage(tool_output, tool_call_id=tool_call["id"]))
messages
#完整代码
from getpass import getpass
DASHSCOPE_API_KEY = getpass()
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-"
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, ToolMessage
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
tools=[multiply]
llm = ChatTongyi(model="qwen-turbo")
llm_with_tools = llm.bind_tools(tools)
query="what is 3*12?"
messages = [HumanMessage(query)]
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
for tool_call in ai_msg.tool_calls:
selected_tool = {"multiply": multiply}[tool_call["name"].lower()]
tool_output = selected_tool.invoke(tool_call["args"])
messages.append(ToolMessage(tool_output, tool_call_id=tool_call["id"]))
print(messages)
- 结果输出
[HumanMessage(content='what is 3*12?'), AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'multiply', 'arguments': '{"first_int": 3, "second_int": 12}'}, 'id': '', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'tool_calls', 'request_id': '941b5989-73fc-9d7b-a010-d63772296db2', 'token_usage': {'input_tokens': 187, 'output_tokens': 25, 'total_tokens': 212}}, id='run-58c2c22b-46fd-4d61-a1e9-9b4d1b2e4ec2-0', tool_calls=[{'name': 'multiply', 'args': {'first_int': 3, 'second_int': 12}, 'id': '', 'type': 'tool_call'}]), ToolMessage(content='36', tool_call_id='')]
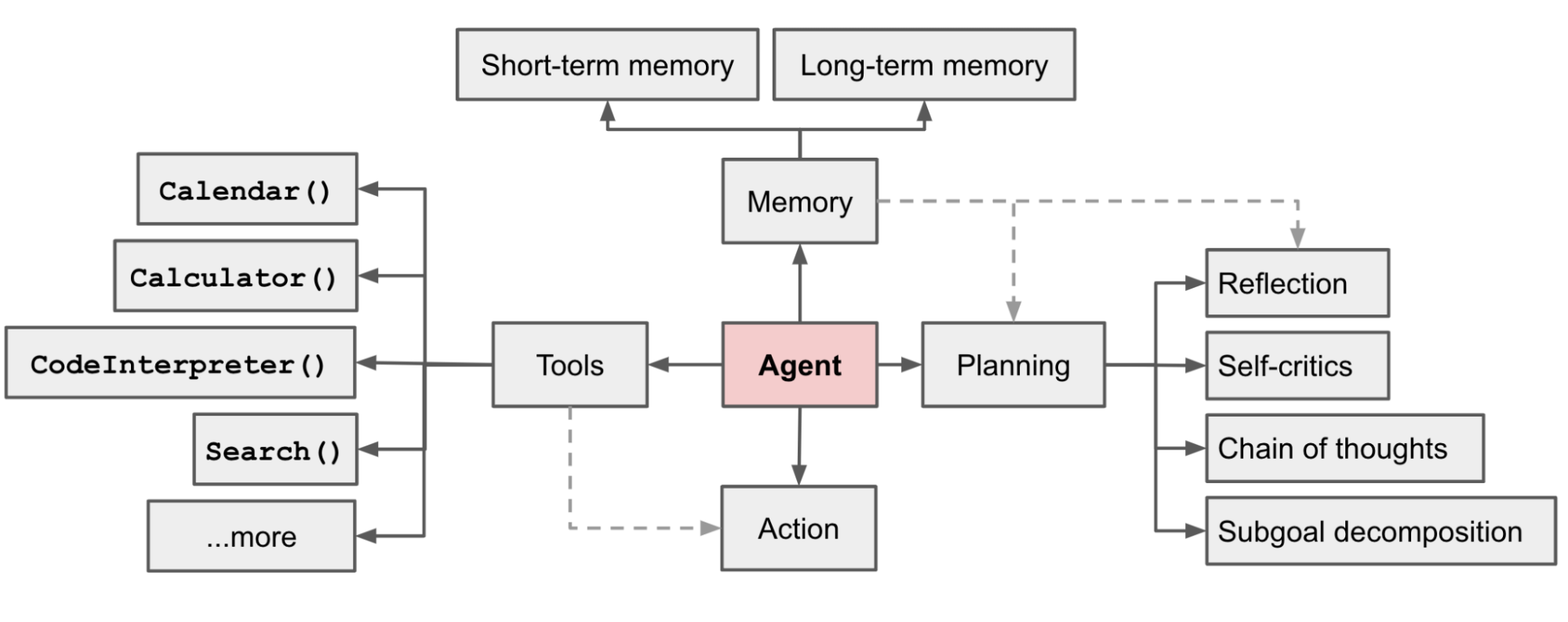
1.4 多模态(qwen-vl-max)能力
qwen-vl-max模型具备多模态能力,这里我们使用它来识别一张图片并对图片做出描述,图片如下
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import HumanMessage
chatLLM = ChatTongyi(model_name="qwen-vl-max")
image_message = {
"image": "https://ai-studio-static-online.cdn.bcebos.com/ea894a305d714a1790df1282975b01be0532f2b81f6f4860abda0c5eeb1f1211",
}
text_message = {
"text": "summarize this picture",
}
message = HumanMessage(content=[text_message, image_message])
chatLLM.invoke([message])
- 结果输出
AIMessage(content=[{'text': "The image presents an abstract representation of the Agent, which serves as the central hub for various cognitive processes and tools. The Agent is connected to both short-term memory and long-term memory, indicating its role in integrating past experiences and immediate perceptions.\n\nFrom the Agent, several tools branch out, including Calendar(), Calculator(), CodeInterpreter(), Search(), and more, suggesting that it can leverage various resources to accomplish tasks. Additionally, the Agent engages in planning by connecting back to itself through a feedback loop.\n\nSelf-reflection plays a crucial role in the Agent's operation, as indicated by its connections with self-critics. Furthermore, the Agent exhibits problem-solving abilities through its chain of thoughts, subgoal decomposition, and the use of external tools like Code Interpreter(). Overall, the Agent appears to be a highly adaptable and resourceful entity that integrates various cognitive functions and external aids to navigate complex environments or solve problems."}], response_metadata={'model_name': 'qwen-vl-max', 'finish_reason': 'stop', 'request_id': '557f9c6b-dacd-9aa1-ade2-f617453d3474', 'token_usage': {'input_tokens': 1264, 'output_tokens': 181, 'image_tokens': 1232}}, id='run-a39305d2-7c17-402f-bbd4-960d815ae55e-0')
2.月之暗面(Kimi )
Moonshot的文本生成模型(指moonshot-v1)是训练用于理解自然语言和书面语言的,它可以根据输入生成文本输出。对模型的输入也被称为“prompt”。通常我们建议您提供明确的指令以及给出一些范例,来让模型能够完成既定的任务,设计 prompt 本质上就是学会如何“训练”模型。moonshot-v1模型可以用于各种任务,包括内容或代码生成、摘要、对话、创意写作等。
API申请:https://platform.moonshot.cn/console/api-keys 使用手册:https://platform.moonshot.cn/docs/intro#%E4%B8%BB%E8%A6%81%E6%A6%82%E5%BF%B5
- 支持的模型有:
- moonshot-v1-8k: 它是一个长度为 8k 的模型,适用于生成短文本。
- moonshot-v1-32k: 它是一个长度为 32k 的模型,适用于生成长文本。
- moonshot-v1-128k: 它是一个长度为 128k 的模型,适用于生成超长文本。
2.1 langchain使用方式
import os
from langchain_community.chat_models.moonshot import MoonshotChat
from langchain_core.messages import HumanMessage, SystemMessage
#Generate your api key from: https://platform.moonshot.cn/console/api-keys
os.environ["MOONSHOT_API_KEY"] = "MOONSHOT_API_KEY"
chat = MoonshotChat()
#or use a specific model
#Available models: https://platform.moonshot.cn/docs
#chat = MoonshotChat(model="moonshot-v1-128k")
messages = [
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(
content="Translate this sentence from English to French. I love programming."
),
]
chat.invoke(messages)
2.2 单论对话
from openai import OpenAI
client = OpenAI(
api_key = "$MOONSHOT_API_KEY",
base_url = "https://api.moonshot.cn/v1",
)
completion = client.chat.completions.create(
model = "moonshot-v1-8k",
messages = [
{"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"},
{"role": "user", "content": "你好,我叫李雷,1+1等于多少?"}
],
temperature = 0.3,
)
print(completion.choices[0].message.content)
2.3 多轮对话
from openai import OpenAI
client = OpenAI(
api_key = "$MOONSHOT_API_KEY",
base_url = "https://api.moonshot.cn/v1",
)
history = [
{"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}
]
def chat(query, history):
history.append({
"role": "user",
"content": query
})
completion = client.chat.completions.create(
model="moonshot-v1-8k",
messages=history,
temperature=0.3,
)
result = completion.choices[0].message.content
history.append({
"role": "assistant",
"content": result
})
return result
print(chat("地球的自转周期是多少?", history))
print(chat("月球呢?", history))
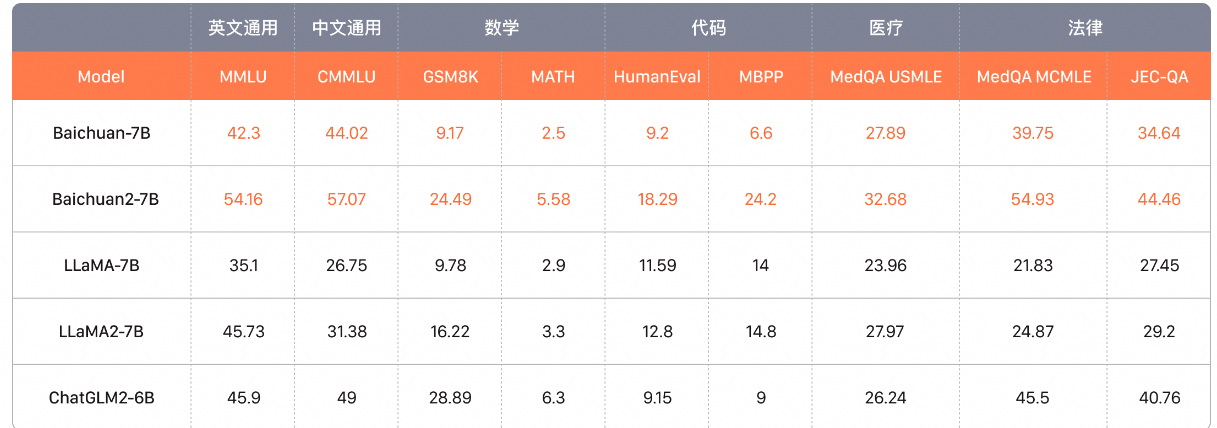
3. 百川智能
官网:https://platform.baichuan-ai.com/homePage

-
baichuan4:模型能力国内第一,在知识百科、长文本、生成创作等中文任务上超越国外主流模型。还具备行业领先的多模态能力,多项权威评测基准表现优异。[Search Agent /长窗口/多模态]
-
Baichuan3-Turbo:针对企业高频场景优化,效果大幅提升,高性价比。相对于Baichuan2模型,内容创作提升20%,知识问答提升17%, 角色扮演能力提升40%。整体效果比GPT3.5更优。[企业场景优化 /强化学习/中英双语]
from langchain_community.chat_models import ChatBaichuan
from langchain_core.messages import HumanMessage
chat = ChatBaichuan(baichuan_api_key="sk-")
#也可以使用192K开启流式输出
#chat = ChatBaichuan(
#baichuan_api_key="YOUR_API_KEY",
#streaming=True,
#)
chat([HumanMessage(content="结合北京市发展情况,编写《北京商务发展报告2023》的提纲。")])
- 输出结果
AIMessage(content='《北京商务发展报告2023》提纲\n\n一、引言\n 1. 报告背景\n 2. 报告目的与意义\n 3. 数据来源与研究方法\n\n二、北京市商务发展概况\n 1. 北京市经济发展总体情况\n 2. 北京市商务发展主要指标分析\n 3. 北京市商务发展特点与趋势\n\n三、北京市重点行业商务发展分析\n 1. 金融业\n 1.1 北京市金融业发展现状\n 1.2 北京市金融业发展特点与趋势\n 1.3 北京市金融业发展前景展望\n 2. 高新技术产业\n 2.1 北京市高新技术产业发展现状\n 2.2 北京市高新技术产业发展特点与趋势\n 2.3 北京市高新技术产业发展前景展望\n 3. 现代物流业\n 3.1 北京市现代物流业发展现状\n 3.2 北京市现代物流业发展特点与趋势\n 3.3 北京市现代物流业发展前景展望\n 4. 其他重点行业(如旅游业、文化创意产业等)\n\n四、北京市商务发展政策环境分析\n 1. 北京市商务发展政策环境概述\n 2. 北京市商务发展政策环境对行业发展的影响分析\n 3. 北京市商务发展政策环境展望\n\n五、北京市商务发展区域布局分析\n 1. 北京市商务发展区域布局现状\n 2. 北京市商务发展区域布局特点与趋势\n 3. 北京市商务发展区域布局展望\n\n六、北京市商务发展面临的挑战与机遇\n 1. 北京市商务发展面临的挑战\n 2. 北京市商务发展面临的机遇\n 3. 北京市商务发展应对挑战与把握机遇的策略建议\n\n七、北京市商务发展展望\n 1. 北京市商务发展总体展望\n 2. 北京市重点行业商务发展展望\n 3. 北京市商务发展政策环境与区域布局展望\n\n八、结论\n 1. 北京市商务发展主要成果与经验总结\n 2. 对北京市商务发展的建议与展望\n\n九、附录\n 1. 北京市商务发展相关数据汇总\n 2. 北京市商务发展相关政策汇总\n 3. 北京市商务发展相关研究报告与文献汇总', response_metadata={'token_usage': {'prompt_tokens': 21, 'completion_tokens': 475, 'total_tokens': 496}, 'model': 'Baichuan2-Turbo-192K'}, id='run-071ed1da-6950-412a-9a60-7216ceb53af0-0')
- 同样问题问baichuan4 其更加专业

请求频率限制当前企业认证账号限制 120 记录/分钟,非企业认证账号为 60 记录/分钟。如果您收到速率限制的报错,则表示您在短时间内发出了太多请求,API 会拒绝新请求,直到经过指定的时间。
4.字节扣子:
Coze 是新一代一站式 AI Bot 开发平台。无论你是否有编程基础,都可以在 Coze 平台上快速搭建基于 AI 模型的各类问答 Bot。而且你可以将搭建的 Bot 发布到各类社交平台和通讯软件上,让更多的用户与你搭建的 Bot 聊天。Coze 支持将 AI Bot 发布为 API 服务,你可以通过 HTTP 方式与 Bot 进行交互。
- 无限拓展的能力集
扣子集成了丰富的插件工具,可以极大地拓展 Bot 的能力边界。
- 内置插件:目前平台已经集成了近百款各类型的插件,包括资讯阅读、旅游出行、效率办公、图片理解等 API 及多模态模型。 你可以直接将这些插件添加到 Bot 中,丰富 Bot 能力。例如使用新闻插件,打造一个可以播报最新时事新闻的 AI 新闻播音员。
- 自定义插件:扣子平台也支持创建自定义插件。 你可以将已有的 API 能力通过参数配置的方式快速创建一个插件让 Bot 调用。
- 丰富的数据源
扣子提供了简单易用的知识库功能来管理和存储数据,支持 Bot 与你自己的数据进行交互。无论是内容量巨大的本地文件还是某个网站的实时信息,都可以上传到知识库中。这样,Bot 就可以使用知识库中的内容回答问题了。
- 内容格式:知识库支持添加文本格式、表格格式、照片格式的数据。
- 内容上传: 知识库支持 TXT 等本地文件、在线网页数据、Notion 页面及数据库、API JSON 等多种数据源,你也可以直接在知识库内添加自定义数据。
当前扣子 API 免费供开发者使用,每个空间的 API 请求限额如下:
- QPS (每秒发送的请求数):2
- QPM (每分钟发送的请求数):60
- QPD (每天发送的请求数):3000
将以下命令粘贴到终端中以运行你的第一个 API 请求。 在发送请求前,请将示例中的以下参数值替换成真实数据:
- {{Personal_Access_Token}}:生成的个人访问令牌。点击这里生成令牌。
- {{Bot_Id}}:Bot ID。进入 Bot 的开发页面,开发页面 URL 中 bot 参数后的数字就是 Bot ID。例如https://www.coze.cn/space/341****/bot/73428668*****,bot ID 为73428668*****。 确保 Bot 已发布为 API 服务。详情参考准备工作。
- {{UserId}}:标识当前与 Bot 交互的用户,由使用方在业务系统中自行定义、生成与维护。
- {{yourquery}}:发送的消息内容。
curl --location --request POST 'https://api.coze.cn/v3/chat' \
--header 'Authorization: Bearer {{Personal_Access_Token}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"bot_id": "{{Bot_Id}}",
"user_id": "{{UserId}}",
"stream": false,
"auto_save_history":true,
"additional_messages":[
{
"role":"user",
"content":"{{yourquery}}",
"content_type":"text"
}
]
}'

更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
#AI大模型#AI前沿技术

 查看8道真题和解析
查看8道真题和解析