
常见算子的数据倾斜解决方案
推荐阅读文章列表
前言
数据倾斜既是工作中最常见的一个问题,也是大数据求职面试中最常见的一个话题。
想必大家一定听说过数据倾斜,也知道很多的解决方案,但是你是否知道哪些算子最容易发生数据倾斜,对应的解决方案又有哪些呢?比如最常见的热门算子:join、group by、count(distinct)、row_number【数据倾斜出现频率从高至低】
本文将会从 数据倾斜定义、如何分析数据倾斜、解决方案 三个方面来剖析数据倾斜问题
数据倾斜定义
定义:通俗来讲,一张表中某个或某些特定值出现的频次远大于其他数值,这样就会导致某个或某些task处理的数据量远超过其他task,因此发生数据倾斜。
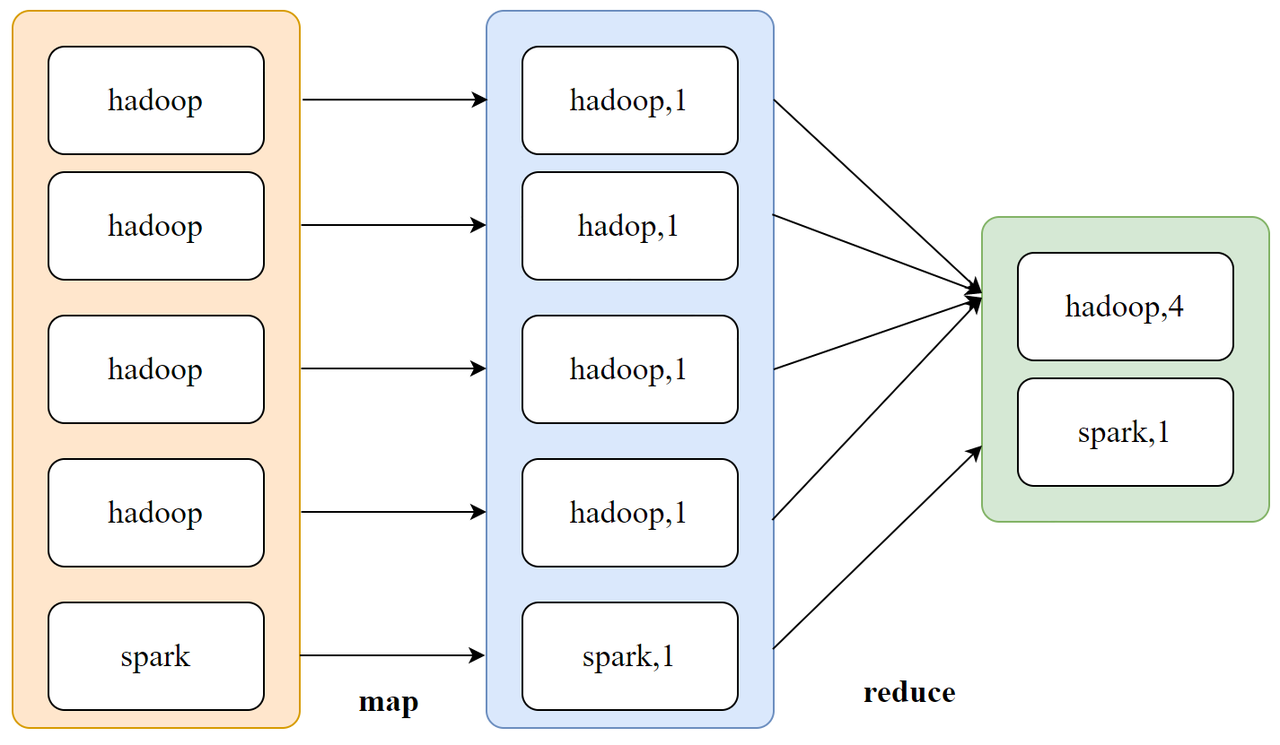
举例:下图是计算所有大学生每门技术的学习人数,可以发现学习hadoop的人数远大于spark,那么处理hadoop的task的压力就会更大,导致数据倾斜。

如何分析数据倾斜
- 确诊问题(判断问题是不是数据倾斜)
- 定位问题(判断具体是哪段代码发生数据倾斜)
- 分析问题(分析造成数据倾斜的原因是什么)

具体来讲:
- 打开sparkui界面,查看所有stage的执行时长,是否存在某个或某几个stage执行时长大大超过了其余stage的平均时长
- 获取执行时长最长的stage的id,到DAG图中进行搜索,找到对应的执行代码
- 通过Python/SQL分析代码涉及到所有表的shuffle key的分布,观察是否存在某个key分布较集中
解决方案
Join
两种情况,一种是大小表join,一种是大大表join
- 大小表join:开启mapjoin即可
-- b是小表(MB级及以下) a是大表(GB及以上)
select /*+mapjoin(b)*/
a.*
from a
left join b
on a.id = b.id
- 大大表join:
【存在热点值】:拆分热点和非热点
-- 1.识别表a的热点key,并保存在tmp表中
-- 2.热点key和表b进行join
-- 3.非热点key和表b进行join
-- 4.将2和3的结果合并一起
select /*+mapjoin(a)*/a.id, a.name, b.score
from (select * from a where a.id in (select id from tmp)) a
join b
on a.id = b.id
union all
select a.id, a.name, b.score
from (select * from a where a.id not in (select id from tmp)) a
join b
on a.id = b.id
【不存在热点值】:采用分桶join
create table t (
a string,
b string
)
partitioned by (dt string)
clustered by (b) into 2048 buckets;
Group By
- 加盐打散
-- 优化前sql
select id, count(*)
from t
group by id
;
-- 优化后sql
select
t.id,
sum(t.cnt)
from (
select
id,
case when id in ('1001','1002') then cast(rand() * 100 as bigint),
count(*) as cnt
from t
group by
id,
case when id in ('1001','1002') then cast(rand() * 100 as bigint)
) t
group by t.id
;
Count Distinct
-- 优化前sql
select dt, count(distinct user_id) as cnt
from t
group by dt
;
- 方式1:两阶段聚合+加盐打散
select
split(rand_dt, '_')[1] as dt,
count(*) as cnt
from (
select
concat(cast(rand() * 10 as bigint), '_', dt) as rand_dt
user_id
from t
group by
concat(cast(rand() * 10 as bigint), '_', dt)
user_id
) t
group by split(rand_dt, '_')[1]
;
- 方式2:构建bitmap
select
dt,
getcardinality(idbits) as cnt -- 2. 计算基数
from (
-- 1.转换为bit
select
dt,
id2bit(user_id) as idbits
from t
) t
group by dt
Row_number
- 加盐打散
-- 需求:计算每个用户的成绩排名(假设大量用户id进入到同一个reduce进行计算)
-- 优化前sql
select
uid, score,
row_number() over(partition by uid order by score desc) rk
from t
-- 优化后sql
select
uid, score,
row_number() over(partition by uid, bucket order by score desc) rk
from (
select
uid, score, cast(rand() * 10 as bigint) as bucket
from t
)t
下期预告
关于数据治理,我有些话要说
#数据人的面试交流地##校招过来人的经验分享##2025届提前批# 查看5道真题和解析
查看5道真题和解析
