玩转字词句魔法:打造超强样本集的数据增强策略
玩转字词句魔法:打造超强样本集的数据增强策略,句式变换揭秘同义句生成与回译在数据增强中的创新应用
1. WordSimilarity
这是一个基于哈工大同义词词林扩展版的单词相似度计算方法的python实现,参考论文如下:
pip install WordSimilarity
from word_similarity import WordSimilarity2010
ws_tool = WordSimilarity2010()
b_a = "抄袭"
b_b = "克隆"
sim_b = ws_tool.similarity(b_a, b_b)
print(b_a, b_b, '相似度为', sim_b)
#抄袭 克隆 最终的相似度为 0.585642777645155
w_a = '人民'
sample_list = ["国民", "群众", "党群", "良民", "同志", "成年人", "市民", "亲属", "志愿者", "先锋" ]
for s_a in sample_list:
sim_a = ws_tool.similarity(w_a,s_a)
print(w_a, s_a, '相似度为', sim_a)
#人民 国民 相似度为 1
#人民 群众 相似度为 0.9576614882494312
#人民 党群 相似度为 0.8978076452338418
#人民 良民 相似度为 0.7182461161870735
#人民 同志 相似度为 0.6630145969121822
#人民 成年人 相似度为 0.6306922220793977
#人民 市民 相似度为 0.5405933332109123
#人民 亲属 相似度为 0.36039555547394153
#人民 志愿者 相似度为 0.22524722217121346
#人民 先锋 相似度为 0.18019777773697077
更多项目参考:
https://github.com/BiLiangLtd/WordSimilarity https://github.com/ashengtx/CilinSimilarity 实现了三种计算方法。 https://github.com/Xls1994/Cilin http://www.codepub.cn/2015/08/04/Based-on-the-extended-version-of-synonyms-Cilin-word-similarity-computing/ Java实现
2.OpenHowNet
OpenHowNet API由清华大学自然语言处理实验室(THUNLP)开发,提供方便的义原信息查询、义原树展示、基于义原的词相似度计算等功能。网站体验词语义原在线查询和展示功能。
官网:https://openhownet.thunlp.org/
https://openhownet.thunlp.org/item?id=000000265705
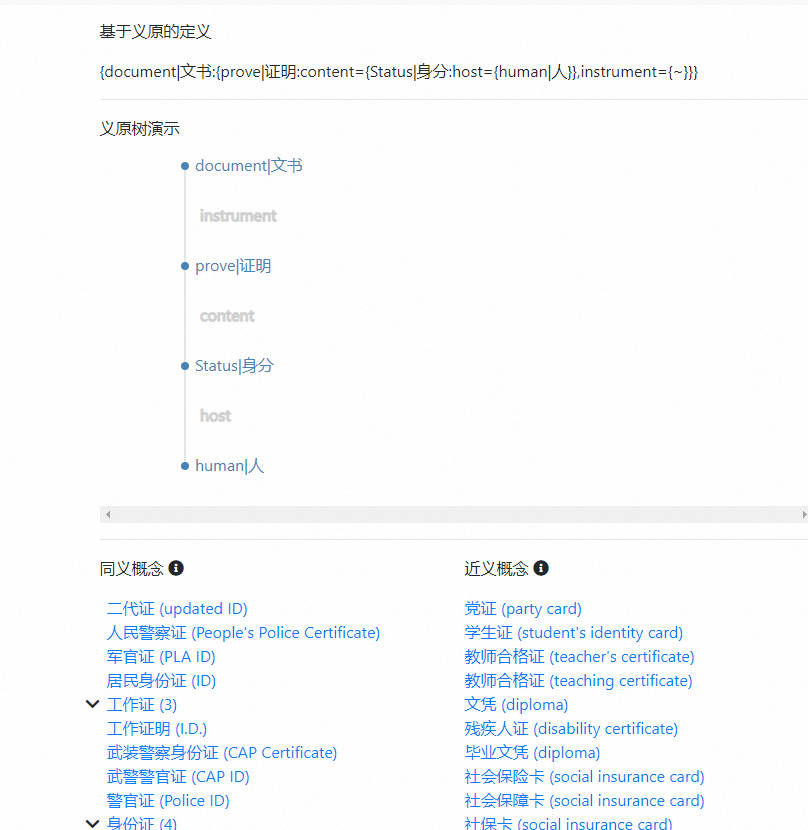
2.1 HowNet简介
HowNet是最典型的义原知识库。义原在语言学中被定义为最小的语义单位,有语言学家认为世界所有语言的所有词语的语义都可以用一个有限的义原集合来表示。董振东和董强先生父子将此思想付诸实践,耗时近30年构建了HowNet(知网),通过预定义的2000多个义原为20多万个由中英文词语所表示的概念进行了标注。
- HowNet词典 HowNet核心数据(即HowNet词典,可从OpenHowNet网站下载)包括237,973个概念。每个概念由中英文词语及其词性、情感倾向、例句、义原标注等信息组成。下面是HowNet中一个概念的示例:
NO.=000000026417 # 概念编号
W_C=不惜 # 中文词语
G_C=verb # 中文词语词性
S_C=PlusFeeling|正面情感 # 中文词语情感倾向
E_C=~牺牲业余时间,~付出全部精力,~出卖自己的灵魂 # 中文词语例句
W_E=do not hesitate to # 英文词语
G_E=verb # 英文词语词性
S_E=PlusFeeling|正面情感 # 英文词语情感倾向
E_E= # 英文词语例句
DEF={willing|愿意} # 义原标注
RMK=
2.2 OpenHowNet API
- 通过 pip 安装(推荐)
pip install OpenHowNet
- 通过 Github 安装
git clone https://github.com/thunlp/OpenHowNet/
cd OpenHowNet
python setup.py install
- 运行要求
- Python>=3.6
- anytree>=2.4.3
- tqdm>=4.31.1
- requests>=2.22.0
核心数据类型
-
HowNetDict:HowNet词典类,封装HowNet核心数据的检索、展示、相似度计算等核心功能。
-
Sense:HowNet中的概念类,封装用于描述概念的中英文词语及其词性、义原标注等信息。
-
Sememe:HowNet中的义原类,封装用于描述义原的中英文词语、义原的出现频率以及义原间关系等信息。
-
初始化
import OpenHowNet
hownet_dict = OpenHowNet.HowNetDict()
这里如果没有下载义原数据会报错,需要执行 OpenHowNet.download() 。
2.2.1 获取HowNet中词语对应的概念
默认情况下,api将从HowNet中搜索输入词语(中文或英文)所属的概念,并返回一个Sense实例列表。为了提高效率,可以设置输入词语的语言。如果目标词不属于HowNet中的任何概念,将返回一个空list。
#查找"苹果"所属的所有概念
>>> result_list = hownet_dict.get_sense("苹果")
>>> print("The number of retrievals: ", len(result_list))
The number of retrievals: 8
>>> print("An example of retrievals: ", result_list)
An example of retrievals: [No.244401|apple|苹果, No.244402|malus pumila|苹果, No.244403|orchard apple tree|苹果, No.244396|apple|苹果, No.244397|apple|苹果, No.244398|IPHONE|苹果, No.244399|apple|苹果, No.244400|iphone|苹果]
通过每个Sense实例,可以得到每个概念的详细信息(包括概念编号,中英文词语、义原标注等):
>>> sense_example = result_list[0]
>>> print("Sense example:", sense_example)
Sense example: No.244401|apple|苹果
>>> print("Sense id: ",sense_example.No)
Sense id: 000000244401
>>> print("English word in the sense: ", sense_example.en_word)
English word in the sense: apple
>>> print("Chinese word in the sense: ", sense_example.zh_word)
Chinese word in the sense: 苹果
>>> print("HowNet Def of the sense: ", sense_example.Def)
HowNet Def of the sense: {tree|树:{reproduce|生殖:PatientProduct={fruit|水果},agent={~}}}
>>> print("Sememe list of the sense: ", sense_example.get_sememe_list())
Sememe list of the sense: {fruit|水果, tree|树, reproduce|生殖}
你可以通过如下方式展示一个概念的义原标注的可视化形式(即义原树):
>>> sense_example.visualize_sememe_tree()
[sense]No.244401|apple|苹果
└── [None]tree|树
└── [agent]reproduce|生殖
└── [PatientProduct]fruit|水果
2.2.2 获取HowNet中的所有词语和义原
工具包提供了获取HowNet中所有概念、词语、义原等信息的api。
#获取所有概念
>>> all_senses = hownet_dict.get_all_sense()
>>> print("The number of all senses: {}".format(len(all_senses)))
The number of all senses: 237974
#获取所有中文词语
>>> zh_word_list = hownet_dict.get_zh_words()
>>> print("Chinese words in HowNet: ",zh_word_list[:30])
Chinese words in HowNet: ['', '"', '#', '#号标签', '$', '$.J.', '$A.', '$NZ.', '%', "'", '(', ')', '*', '+', ',', '-', '--', '.', '...', '...为止', '...也同样使然', '...以上', '...以内', '...以来', '...何如', '...内', '...出什么问题', '...发生了什么', '...发生故障', '...家里有几口人']
#获取所有英文词语
>>> en_word_list = hownet_dict.get_en_words()
>>> print("English words in HowNet: ",en_word_list[:30])
English words in HowNet: ['A', 'An', 'Frenchmen', 'Frenchwomen', 'Ottomans', 'a', 'aardwolves', 'abaci', 'abandoned', 'abbreviated', 'abode', 'aboideaux', 'aboiteaux', 'abscissae', 'absorbed', 'acanthi', 'acari', 'accepted', 'acciaccature', 'acclaimed', 'accommodating', 'accompanied', 'accounting', 'accused', 'acetabula', 'acetified', 'aching', 'acicula', 'acini', 'acquired']
#获取所有义原
>>> all_sememes = hownet_dict.get_all_sememes()
>>> print('There are {} sememes in HowNet'.format(len(all_sememes)))
There are 2540 sememes in HowNet
2.2.3 获取词语的义原标注
工具包提供了直接根据输入的目标词语检索其所属概念的义原标注的功能。
默认情况下,工具包将查找该词语所属的Sense列表,并返回每个Sense对应的Sememe列表。
>>> hownet_dict.get_sememes_by_word(word = '苹果', display='list', merge=False, expanded_layer=-1, K=None)
[{'sense': No.244396|apple|苹果,
'sememes': {PatternValue|样式值, SpeBrand|特定牌子, able|能, bring|携带, computer|电脑}},
{'sense': No.244397|apple|苹果,
'sememes': {fruit|水果}},
{'sense': No.244398|IPHONE|苹果,
'sememes': {PatternValue|样式值, SpeBrand|特定牌子, able|能, bring|携带, communicate|交流, tool|用具}},
{'sense': No.244399|apple|苹果,
'sememes': {PatternValue|样式值, SpeBrand|特定牌子, able|能, bring|携带, communicate|交流, tool|用具}},
{'sense': No.244400|iphone|苹果,
'sememes': {PatternValue|样式值, SpeBrand|特定牌子, able|能, bring|携带, communicate|交流, tool|用具}},
{'sense': No.244401|apple|苹果,
'sememes': {fruit|水果, reproduce|生殖, tree|树}},
{'sense': No.244402|malus pumila|苹果,
'sememes': {fruit|水果, reproduce|生殖, tree|树}},
{'sense': No.244403|orchard apple tree|苹果,
'sememes': {fruit|水果, reproduce|生殖, tree|树}}]
通过设置 display ,除了可以将义原以列表形式(list)展示外,还可以以词典形式(dict)、树节点形式(tree)、可视化形式(visual)等不同形式进行展示。
#获取以词典形式展示的义原集合
>>> hownet_dict.get_sememes_by_word(word='苹果',display='dict')[0]
{'sense': No.244396|apple|苹果, 'sememes': {'role': 'sense', 'name': No.244396|apple|苹果, 'children': [{'role': 'None', 'name': computer|电脑, 'children': [{'role': 'modifier', 'name': PatternValue|样式值, 'children': [{'role': 'CoEvent', 'name': able|能, 'children': [{'role': 'scope', 'name': bring|携带, 'children': [{'role': 'patient', 'name': '$'}]}]}]}, {'role': 'patient', 'name': SpeBrand|特定牌子}]}]}}
#获取以树的形式组织的义原(得到义原树的根节点)
>>> d.get_sememes_by_word(word='苹果',display='tree')[0]
{'sense': No.244396|apple|苹果, 'sememes': Node('/No.244396|apple|苹果', role='sense')}
#可视化展示义原树 (通过设置参数K来控制需要打印的义原树的数量)
>>> d.get_sememes_by_word(word='苹果',display='visual',K=2)
Find 8 result(s)
Display #0 sememe tree
[sense]No.244396|apple|苹果
└── [None]computer|电脑
├── [modifier]PatternValue|样式值
│ └── [CoEvent]able|能
│ └── [scope]bring|携带
│ └── [patient]$
└── [patient]SpeBrand|特定牌子
Display #1 sememe tree
[sense]No.244397|apple|苹果
└── [None]fruit|水果
当 display='list' 时,可以通过设置merge将所有Sense的义原列表合并到同一个列表,以及通过expanded_layer设置每个概念的义原树展开的层数等(expanded_layer默认为-1表示展开所有层)。
下面的例子展示了将苹果所属的所有概念的义原列表进行合并后输出的结果:
>>> hownet_dict.get_sememes_by_word(word = '苹果', display='list', merge=True, expanded_layer=-1, K=None)
{PatternValue|样式值, SpeBrand|特定牌子, able|能, bring|携带, communicate|交流, computer|电脑, fruit|水果, reproduce|生殖, tool|用具, tree|树}
2.2.4 查询义原之间的关系
你可以输入中文或英文词语来查找与之相关的义原并查找义原之间的关系,同时可以选择将整个三元组输出:
#查找 FormValue|形状值 和 round|圆 这两个义原之间的关系
>>> relations = hownet_dict.get_sememe_relation('FormValue','圆', return_triples=False)
>>> print(relations)
'hyponym'
>>> triples = hownet_dict.get_sememe_relation('FormValue','圆', return_triples=True)
>>> print(triples)
[(FormValue|形状值, 'hyponym', round|圆)]
2.2.5 检索与输入义原存在某种关系的所有义原
输入的义原可以使用任意语言,但是关系必须为英文小写。同样的,可以选择将整个三元组输出。
#查找与义原 FormValue|形状值 存在 hyponym 关系的所有义原
>>> triples = hownet_dict.get_related_sememes('FormValue', relation = 'hyponym', return_triples=True)
>>> print(triples)
[(FormValue|形状值, 'hyponym', round|圆), (FormValue|形状值, 'hyponym', unformed|不成形), (AppearanceValue|外观值, 'hyponym', FormValue|形状值), (FormValue|形状值, 'hyponym', angular|角), (FormValue|形状值, 'hyponym', square|方), (FormValue|形状值, 'hyponym', netlike|网), (FormValue|形状值, 'hyponym', formed|成形)]
2.3 高级功能
2.3.1高级功能1:基于义原的词语相似度和同/近义词
实现方法基于以下论文:
An Approach of Hybrid Hierarchical Structure for Word Similarity Computing by HowNet. Jiangming Liu, Jinan Xu, Yujie Zhang. IJCNLP 2013. [pdf]
- 额外初始化
由于计算相似度需要额外的文件,初始化的开销将比之前的大。
你可以按照如下方式对HowNetDict初始化:
>>> hownet_dict_advanced = OpenHowNet.HowNetDict(init_sim=True)
Initializing OpenHowNet succeeded!
Initializing similarity calculation succeeded!
你也可以在需要使用时再对已经初始化的HowNetDict进行额外的初始化:
>>> hownet_dict.initialize_similarity_calculation()
Initializing similarity calculation succeeded!
2.3.2 获得义原标注完全相同的Sense
你可以获得与指定Sense拥有完全相同义原标注的Sense
>>> s = hownet_dict_advanced.get_sense('苹果')[0]
>>> hownet_dict_advanced.get_sense_synonyns(s)[:10]
[No.110999|pear|山梨, No.111007|hawthorn|山楂, No.111009|haw|山楂树, No.111010|hawthorn|山楂树, No.111268|Chinese hawthorn|山里红, No.122955|Pistacia vera|开心果树, No.122956|pistachio|开心果树, No.122957|pistachio tree|开心果树, No.135467|almond tree|扁桃, No.154699|fig|无花果]
- 获取输入词语的近义词
工具包将首先确定输入词语所属的Sense,继而为每个Sense分别查找K个义原标注最接近的Sense,最后输出对应的词语。注意需要设置输入词的语言。
同时可以选择设置所需词语的词性、输出词语相似度以及无视Sense将所有词语合并到同一个列表等,具体请查询文档。如果输入词语不在HowNet中,函数将返回一个空list。
#为“苹果”所属的每个Sense找出5个最相近的近义词
>>> hownet_dict_advanced.get_nearest_words('苹果', language='zh',K=5)
{No.244396|apple|苹果: ['IBM', '东芝', '华为', '戴尔', '索尼'],
No.244397|apple|苹果: ['丑橘', '乌梅', '五敛子', '凤梨', '刺梨'],
No.244398|IPHONE|苹果: ['OPPO', '华为', '苹果', '智能手机', '彩笔'],
No.244399|apple|苹果: ['OPPO', '华为', '苹果', '智能手机', '彩笔'],
No.244400|iphone|苹果: ['OPPO', '华为', '苹果', '智能手机', '彩笔'],
No.244401|apple|苹果: ['山梨', '山楂', '山楂树', '山里红', '开心果树'],
No.244402|malus pumila|苹果: ['山梨', '山楂', '山楂树', '山里红', '开心果树'],
No.244403|orchard apple tree|苹果: ['山梨', '山楂', '山楂树', '山里红', '开心果树']}
#并各个Sense的近义词查找的结果
>>> hownet_dict_advanced.get_nearest_words('苹果', language='zh',K=5, merge=True)
['IBM', '东芝', '华为', '戴尔', '索尼']
2.3.3 计算两个词语的相似度
如果其中的任何一个词不在HowNet中,函数将返回-1。
#计算“苹果”和“梨”基于义原的相似度
>>> word_sim=hownet_dict_advanced.calculate_word_similarity('苹果','梨')
>>> print('The similarity of 苹果 and 梨 is {}.'.format(word_sim))
The similarity of 苹果 and 梨 is 1.0.
2.3.4 高级功能 2:BabelNet同义词集词典
本工具包集成了对于BabelNet中部分同义词集(称为BabelNet synset)信息的查询功能。BabelNet是一个多语百科词典,由BabelNet synset组成,每个BabelNet synset包含表达相同意思的各种语言的同义词。下面这篇工作为一些BabelNet synset标注了义原,这里的查询功能基于其标注结果实现。
Towards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets. Fanchao Qi, Liang Chang, Maosong Sun, Sicong Ouyang and Zhiyuan Liu. AAAI-20. [pdf] [code]
- 额外初始化 本功能同样需要额外的初始化操作:
>>> hownet_dict.initialize_babelnet_dict()
Initializing BabelNet synset Dict succeeded!
#你也可以在创建HowNetDict实例时初始化
>>> hownet_dict_advanced = HowNetDict(init_babel=True)
Initializing OpenHowNet succeeded!
Initializing BabelNet synset Dict succeeded!
- BabelNet synset信息查询 通过以下API可以对BabelNet synset中丰富的信息(中英同义词、定义、图片链接等)进行查询。
>>> syn_list = hownet_dict_advanced.get_synset('黄色')
>>> print("{} results are retrieved and take the first one as an example".format(len(syn_list)))
3 results are retrieved and take the first one as an example
>>> syn_example = syn_list[0]
>>> print("Synset: {}".format(syn_example))
Synset: bn:00113968a|yellow|黄
>>> print("English synonyms: {}".format(syn_example.en_synonyms))
English synonyms: ['yellow', 'yellowish', 'xanthous']
>>> print("Chinese synonyms: {}".format(syn_example.zh_synonyms))
Chinese synonyms: ['黄', '黄色', '淡黄色+的', '黄色+的', '微黄色', '微黄色+的', '黄+的', '淡黄色']
>>> print("English glosses: {}".format(syn_example.en_glosses))
English glosses: ['Of the color intermediate between green and orange in the color spectrum; of something resembling the color of an egg yolk', 'Having the colour of a yolk, a lemon or gold.']
>>> print("Chinese glosses: {}".format(syn_example.zh_glosses))
Chinese glosses: ['像丝瓜花或向日葵花的颜色。']
- BabelNet synset关系查询 你还可以查询BabelNet同义词集相关的同义词集。
>>> related_synsets = syn_example.get_related_synsets()
>>>print("There are {} synsets that have relation with the {}, they are: ".format(len(related_synsets), syn_example))
There are 6 synsets that have relation with the bn:00113968a|yellow|黄, they are:
>>>print(related_synsets)
[bn:00099663a|chromatic|彩色, bn:00029925n|egg_yolk|蛋黄, bn:00092876v|resemble|相似, bn:00020726n|color|颜色, bn:00020748n|visible_spectrum|可见光, bn:00081866n|yellow|黄色]
- BabelNet synset义原标注查询 工具包同样提供了利用BabelNet synset义原标注来查询中英文词语义原标注的功能:
>>> print(hownet_dict_advanced.get_sememes_by_word_in_BabelNet('黄色'))
[{'synset': bn:00113968a|yellow|黄, 'sememes': [yellow|黄]}, {'synset': bn:00101430a|dirty|淫秽的, 'sememes': [lascivious|淫, dirty|龊, despicable|卑劣, BadSocial|坏风气]}, {'synset': bn:00081866n|yellow|黄色, 'sememes': [yellow|黄]}]
>>> print(hownet_dict_advanced.get_sememes_by_word_in_BabelNet('黄色',merge=True))
[lascivious|淫, despicable|卑劣, BadSocial|坏风气, dirty|龊, yellow|黄]
3. Synonyms
https://github.com/chatopera/Synonyms
Chinese Synonyms for Natural Language Processing and Understanding.
更好的中文近义词:聊天机器人、智能问答工具包。
synonyms可以用于自然语言理解的很多任务:文本对齐,推荐算法,相似度计算,语义偏移,关键字提取,概念提取,自动摘要,搜索引擎等。
synonyms#display(word [, size = 10]) 以友好的方式打印近义词,方便调试,display(WORD [, SIZE])调用了 synonyms#nearby 方法。
>>> synonyms.display("飞机")
'飞机'近义词:
1. 飞机:1.0
2. 直升机:0.8423391
3. 客机:0.8393003
4. 滑翔机:0.7872388
5. 军用飞机:0.7832081
6. 水上飞机:0.77857226
7. 运输机:0.7724742
8. 航机:0.7664748
9. 航空器:0.76592904
10. 民航机:0.74209654
SIZE 是打印词汇表的数量,默认 10。
4. JioNLP 中文 NLP 预处理、解析工具包
官网:https://github.com/dongrixinyu/JioNLP
JioNLP 是一个面向 NLP 开发者的工具包,提供 NLP 任务预处理、解析功能,准确、高效、零使用门槛。请下拉本网页,查阅具体功能信息,并按 Ctrl+F 进行搜索。JioNLP在线版 可快速试用部分功能。关注同名微信公众号 JioNLP 可获取最新的 NLP 资讯,数据资源。
- 安装 Installation
- python>=3.6 github 版本略领先于 pip
$ git clone https://github.com/dongrixinyu/JioNLP
$ cd ./JioNLP
$ pip install .
- pip 安装
$ pip install jionlp
4.2.数据增强(☆)
| 回译 | BackTranslation | 给定一篇文本,采用各大厂云平台的机器翻译接口, 实现数据增强 |
⭐ |
| 邻近汉字换位 | swap_char_position | 随机交换相近字符的位置,实现数据增强 | |
| 同音词替换 | homophone_substitution | 相同读音词汇替换,实现数据增强 | ⭐ |
| 随机增删字符 | random_add_delete | 随机在文本中增加、删除某个字符,对语义不造成影响 | |
| NER实体替换 | replace_entity | 根据实体词典,随机在文本中替换某个实体,对语义不 造成影响,也广泛适用于序列标注、文本分类 |
⭐ |
新词发现
jio.new_word.new_word_discovery 给定一个文本语料文档,返回其中发现的高可能性成词结果。
>>> import jionlp as jio
>>> input_file = '/path/to/text_file.txt'
# input_file 内的样例文本,即一行一条纯文本即可
# 应采儿吸毒是怎么回事?应采儿藏毒事件始末真相
# 但刚出道没几年应采儿就因为吸毒入狱,2004年11月6日凌晨,应采儿与朋友从KTV出来驾车经过九龙塘金巴伦道49号时
# 董洁,1980年4月19日出生于辽宁省大连市,毕业于中国人民解放军国防大学军事文化学院舞蹈系,中国内地影视女演员。
>>> new_words_dict = jio.new_word.new_word_discovery(input_file)
>>> print(new_words_dict)
>>> print(jio.new_word.new_word_discovery.__doc__)
# {'浑水': [34, 6.9],
# '贝壳': [28, 6.7],
# '证监会': [18, 5.8]}
- 其中,input_file 中应当包含纯文本,不同文本段由\n区分。返回的结果是一词典 dict,其中包含了词频和该词的左右信息熵。
- 新词发现方法依然采用统计词汇的内聚度(PMI点间互信息熵)、以及与边界字的分离度(词汇左右信息熵) 进行统计。两个统计指标均有参数可控。分别为min_mutual_information和min_entropy。此外还有词频参数min_freq,指示在文本语料中,词频若低于该值,则属于罕见词汇,不具有统计意义,也不进行返回。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
#自然语言处理#1.本专栏主要包含NLP信息抽取相关技术,如命名实体识别、关系抽取、事件抽取、多任务抽取等;以及智能标注方案。 2.本专栏会提供技术方案、码源等。 3.订阅本专栏可以让你快速实现项目方案,性价比很高,省去找资料试错环节。

 查看5道真题和解析
查看5道真题和解析

