
深入浅出解析Stable Diffusion完整核心基础知识

Rocky Ding
写在前面
【算法兵器谱】栏目专注分享AI行业中的前沿/经典/必备的模型&论文,并对具备划时代意义的模型&论文进行全方位系统的解析,比如Rocky之前出品的爆款文章Make YOLO Great Again系列。也欢迎大家提出宝贵的优化建议,一起交流学习💪
大家好,我是Rocky。
2022年,Stable Diffusion横空出世,成为AI行业从传统深度学习时代过渡至AIGC时代的标志模型,并为工业界和投资界注入了新的活力,让AI再次性感。
本文中,Rocky将深入浅出的讲解Stable Diffusion的核心知识,例举最有价值的应用场景,对Stable Diffusion的训练过程进行通俗易懂的分析,并尝试对其性能进行优化,Rocky希望我们能更好的入门Stable Diffusion及其背后的AIGC领域。
话不多说,在Rocky毫无保留的分享下,让我们开始学习吧!
关于作者
Rocky在校招期间拿到了北上广深杭等地的约10个算法offer,现在是一名算法研究员,目前专注于AIGC创新产品的落地应用以及AI算法解决方案的商用。
在研究生期间,Rocky曾在京东研究院,星环科技,联想研究院,北大方正信产集团研究院,百融云创等公司做算法实习生,对不同性质公司的商业闭环逻辑比较了解。
Rocky喜欢参加算法竞赛,多次获得CVPR,AAAI,Kaggle等顶级平台的算法竞赛冠军和Top成绩。
Rocky相信人工智能,数据科学,商业逻辑,金融工具,终身成长,以及顺应时代的潮流会赋予我们超能力。
Rocky是AI人才发展联盟(AIHIA)的联合创始人,积极在业余时间进行创业实践与基本面扩展。
Rocky喜欢分享和交流,秉持着“也要学习也要酷”的生活态度,希望能和大家多多交流。AI算法,面试,简历,求职等问题都可直接和我交流~
So,enjoy:
正文开始
----【目录先行】----
Stable Diffusion核心基础内容
-
Stable Diffusion模型原理
-
Stable Diffusion模型的核心组件
-
Stable Diffusion推理流程
Stable Diffusion经典应用场景
-
文本生成图片
-
图片生成图片
-
图片inpainting
-
使用controlnet辅助生成图片
-
超分辨率重建
Stable Diffusion训练过程
Stable Diffusion性能优化
----【Stable Diffusion核心基础内容】----
【一】Stable Diffusion模型原理
Stable Diffusion(SD)模型和GAN模型一样,是生成式模型,了解GAN模型的朋友都知道,生成式模型能够生成和训练集分布相似的输出结果(拟合数据分布),在计算机视觉领域是图片,在自然语言处理领域是文字。
下面是主流生成式模型各自的生成逻辑:

Rocky在这里拿GAN详细展开讲讲,由于篇幅原因,VAE和Flow-based models这里就不过多介绍,感兴趣的朋友可以找Rocky私下交流。
GAN由生成器和判别器组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声。而判别器的主要职责是区分生成器生成的样本与样本,输入一般是样本与相应的生成样本,我们想要的是对样本输出的置信度越接近越好,而对生成样本输出的置信度越接近越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
我们可以将GAN中的生成器比喻为印假钞票的犯罪分子,判别器则被当作警察。犯罪分子努力让印出的假钞看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是图像,还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
好的,讲完GAN,让我们回到SD模型。SD模型有两个最基本也是最经典的应用,分别是文生图(txt2pic)和图生图(pic2pic)。

文生图是指将一段文字输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文字描述的图片。比如上图中输入了“天堂,巨大的,海滩”,于是生成了一个美丽沙滩的图片。

而图生图在输入文字的基础上,再输入一张图片,SD模型将根据文字的提示,将图片进行丰富,比如上图中,SD模型将“海盗船”添加在之前那个美丽的沙滩上。
Rocky在这里也分享一些朋友生成的图片,整体上都非常逼真:

感受了SD模型强大的生成能力,大家可能会想到生成式领域上一个霸主模型GAN,与GAN模型不同的是,SD模型是属于扩散模型,并且是基于latent的扩散模型。
什么是扩散模型呢?用通俗的话来讲,就是将图像的生成过程分多步进行,逐步完善图像内容,经过20-50次的“扩散”循环,最终输出精致的图像。
下面是一个直观的例子,将随机高斯噪声矩阵通过SD模型的Inference过程,逐步去燥,最后生成一个小别墅的图片。

那latent又是什么呢?基于latent的扩散模型可以在低维度的隐空间上进行“扩散”过程而不是在实际pixel空间,这样一来大大降低了内存占用和计算复杂性,这是常规扩散模型和latent扩散模型之间的主要区别。同样的,在训练中,latent扩散模型也将训练过程聚焦在latent空间中。
举个例子,如果SD模型中将数据矩阵缩小的倍数设为,那么原本尺寸为的数据矩阵就会进入的latent隐空间中,内存和计算量直接缩小倍,整体效率大大提升。
到这里,大家应该对SD模型的基本概念有一个清晰的认识了,Rocky这里再帮大家总结一下:
- SD模型是生成式模型,与GAN模型有很多相似的地方,输入可以是图片,也可以是文字,输出是图片。
- SD模型属于扩散模型,扩散模型的整理逻辑是生成过程分步化与迭代化,这给整个生成过程引入更多约束与优化提供了可能。
- SD模型是基于latent的,将生成空间压缩到latent空间中,比起常规扩散模型,大大提高计算效率的同时,降低了内存占用,成为了SD模型爆发的关键一招。
- 站在CTO视角,将维度拉到最高维,Rocky认为SD模型的整体流程是一个优化噪声的艺术。
【二】Stable Diffusion模型的核心组件
SD模型主要由自动编码器(VAE),U-Net以及文本编码器三个核心组件构成。
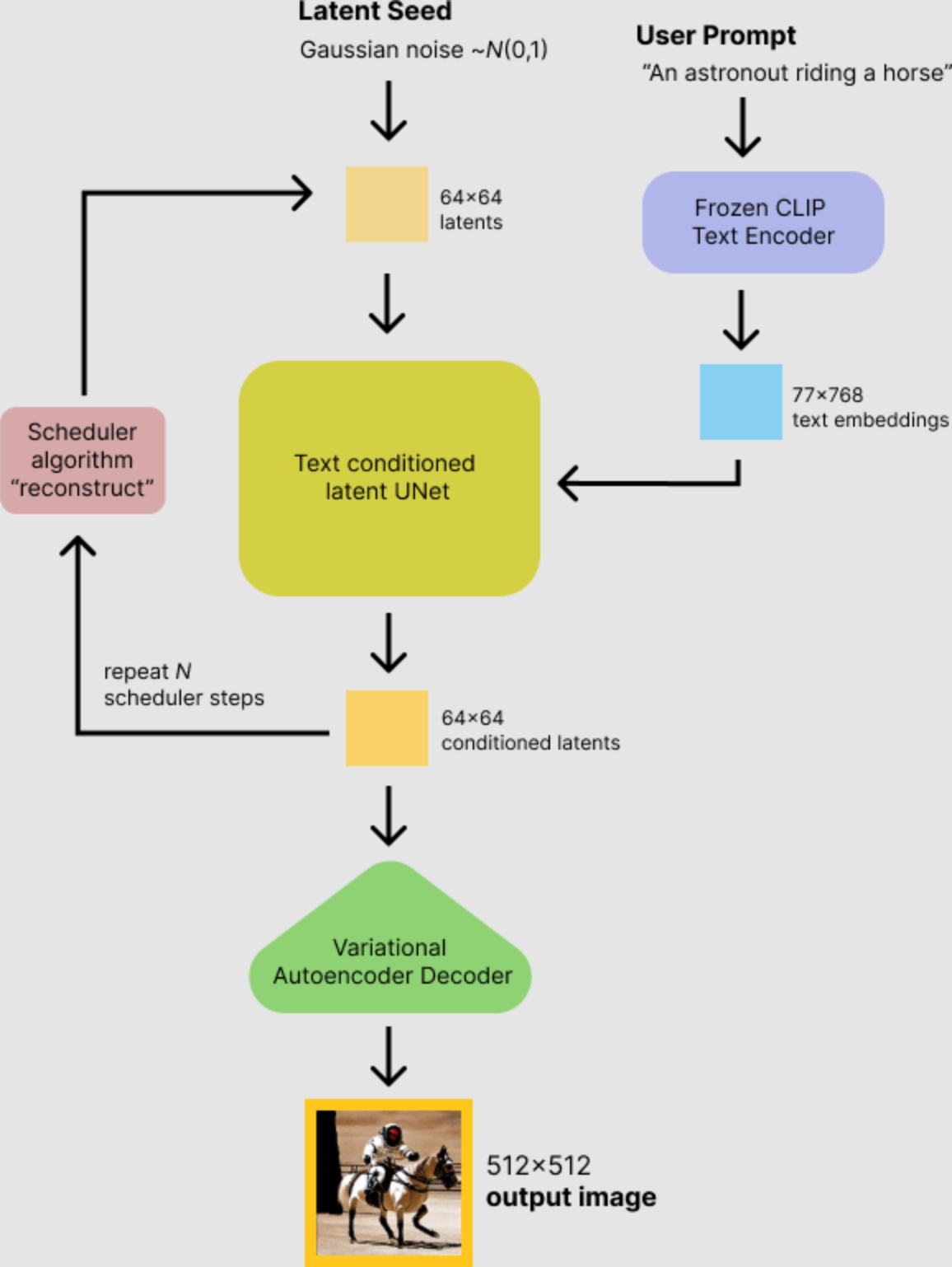
- 自动编码器(VAE):VAE的编码器能够将输入图像转换为低维特征,作为U-Net的输入。VAE的解码器将隐特征升维解码成完整图像。不同的VAE结构能够为生成图片带来不同的细节与整体颜色。
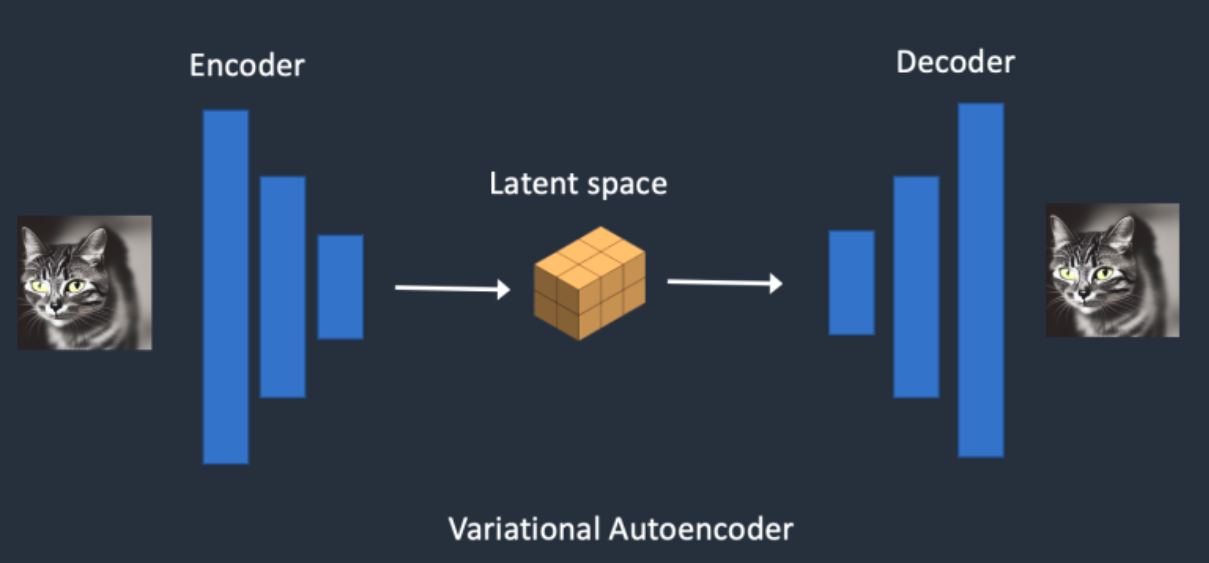
为什么VAE可以将图像压缩到一个非常小的潜空间后能再次对图像还原呢?虽然整个过程可以看作是一个有损压缩,但自然图像并不是随机的,它们具有很高的规律性:比如说一张脸上的眼睛、鼻子、脸颊和嘴巴之间遵循特定的空间关系,又比如说一只猫有四条腿,并且是一个特定的生物结构。所以如果我们生成的图像尺寸在之上时,其实特征损失带来的影响非常小。
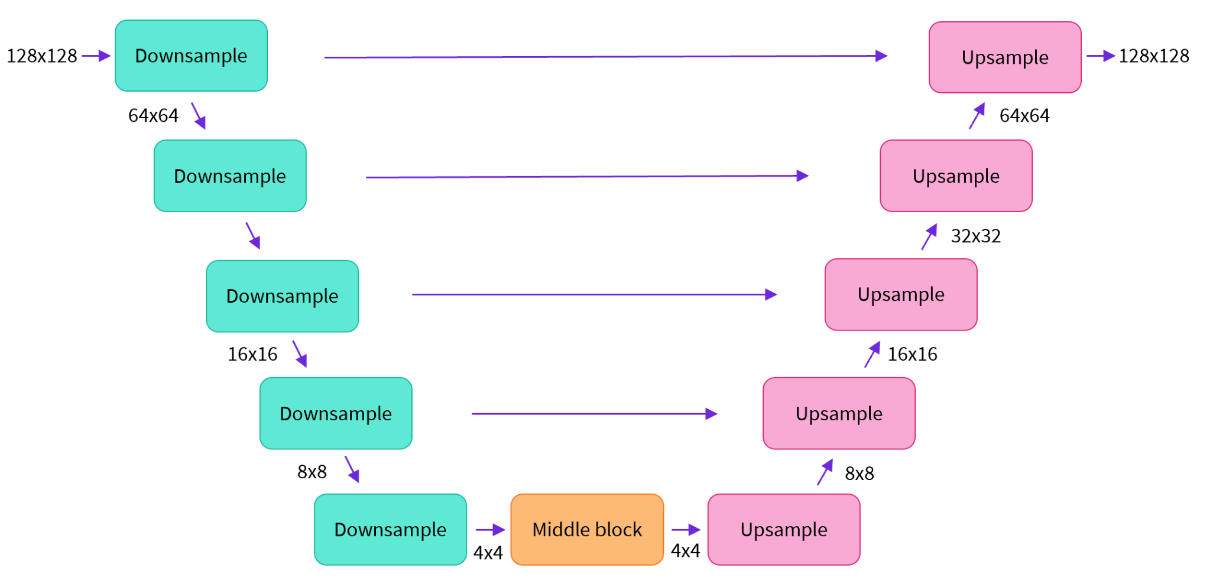
- U-Net:预测噪声残差,结合调度算法(PNDM,DDIM,K-LMS等)进行噪声重构,逐步将随机高斯噪声转化成图片的隐特征。U-Net整体结构一般由ResNet模块构成,并在ResNet模块之间添加CrossAttention模块用于接收文本信息。
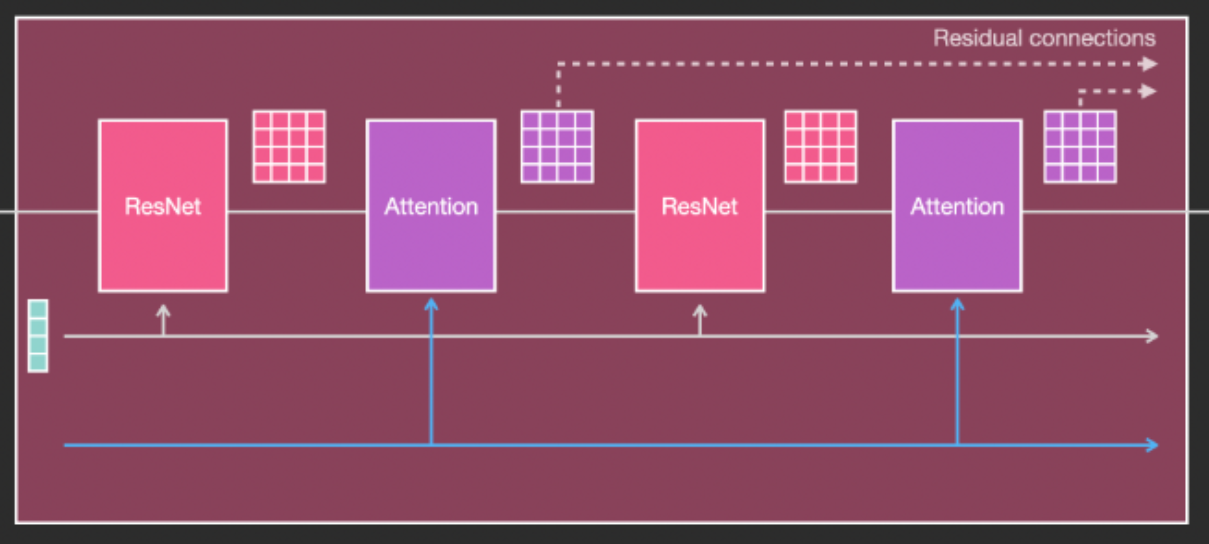
- 文本编码器:将输入prompt进行编码,输出token embeddings向量(语意信息),通过CrossAttention方式送入扩散模型的U-Net中作为condition,对生成图像内容进行一定程度上的控制,目前SD默认的是CLIP text encoder。
【三】Stable Diffusion推理流程
想要运行Stable Diffusion(SD),我们可以直接使用diffusers的完整pipeline流程。
#首先,安装相关依赖
pip install diffusers transformers scipy ftfy accelerate
#读取diffuers库
from diffusers import StableDiffusionPipeline
#初始化SD模型,加载预训练权重
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
#使用GPU加速
pipe.to("cuda")
#如GPU的内存少于10GB,可以加载float16精度的SD模型
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", revision="fp16", torch_dtype=torch.float16)
#接下来,我们就可以运行pipeline了
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# 由于没有固定seed,每次运行代码,我们都会得到一个不同的图片。
我们打开下载的预训练文件夹,可以看到预训练模型主要由以下几个部分组成:
text_encoder和tokenizer,scheduler,unet,vae。
其中text_encoder,scheduler,unet,vae分别代表了上面讲到过的SD模型的核心结构。
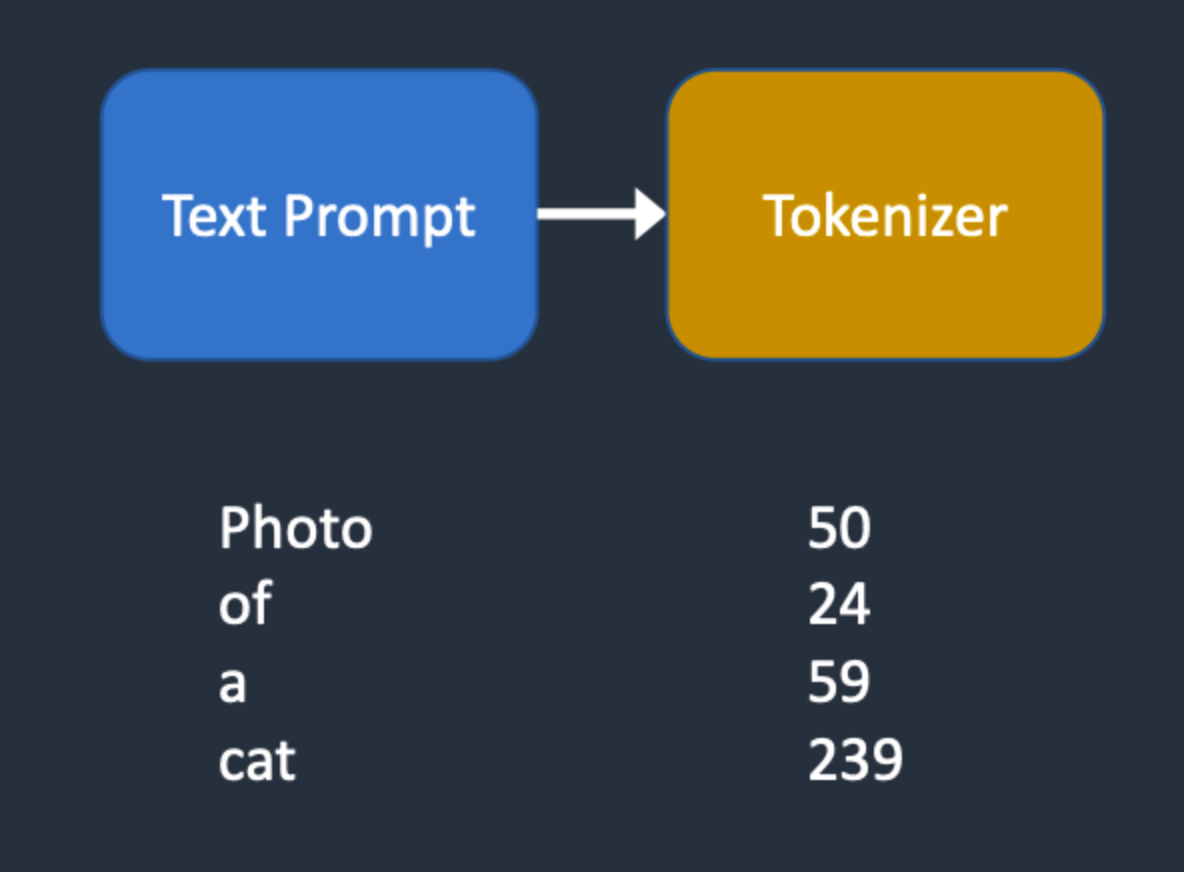
同时我们还可以看到Tokenizer文件夹,表示标记器。Tokenizer首先将Prompt中的每个词转换为一个称为标记(token)的数字,符号化(Tokenization)是计算机理解单词的方式。然后,通过text_encoder将每个标记都转换为一个768值的向量,称为嵌入(embedding),用于U-Net的condition。
有时候我们运行完pipeline之后,会出现纯黑色图片,这表示我们本次生成的图片触发了NSFW机制,出现了一些违规的图片,我们可以修改seed重新进行生成。
我们可以自己设置seed,来达到对图片生成的控制。
import torch
#manual_seed(1024):每次使用具有相同种子的生成器时,都会获得相同的图像输出。
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
将pipeline的完整结构梳理好之后,我们再对一些核心参数进行讲解:
-
num_inference_steps。num_inference_steps表示我们对图片进行噪声优化的次数。一般来说,我们可以选择num_inference_steps = 20/25/50,数值越大,图片生成效果越好,但同时生成所需的时间就越长。
-
guidance_scale,代表无分类指引(Classifier-free guidance,guidance_scale,CFG)是一个控制文本提示对扩散过程的影响程度的值。简单来说就是在加噪阶段将条件控制下预测的噪音和无条件下的预测噪音组合在一起来确定最终的噪声。通常guidance_scale可以选7-8.5之间,如果使用非常大的值,图像可能看起来不错,但多样性会降低。

其中代表CFG,当越大时,condition起的作用越大,即生成的图像更和输入文本一致,当被设置为时,图像生成是无条件的,文本提示会被忽略。
- 输出尺寸
SD在默认情况下会输出尺寸的图片。我们也可以自定义设置图片尺寸,Rocky建议如下:
- 建议height和width都是8的倍数。
- 低于可能会导致图像质量较低。
- 创建非正方形图像的推荐方法是在一维中使用,另一个使用更大的值。
prompt = "a photograph of an astronaut riding a horse"
# Number of denoising steps
steps = 25
# Scale for classifier-free guidance
CFG = 7.5
image = pipe(prompt, guidance_scale=CFG, height=512, width=768, num_inference_steps=steps).images[0]
除了将预训练模型整体加载,我们还可以将SD模型的不同组件单独加载:
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
from diffusers import LMSDiscreteScheduler
# 单独加载VAE模型
vae = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
# 单独家在CLIP模型和tokenizer
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 单独加载U-Net模型
unet = UNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="unet")
# 单独加载调度算法
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
----【Stable Diffusion经典应用场景】----
文本生成图像
输入:prompt
输入:图像
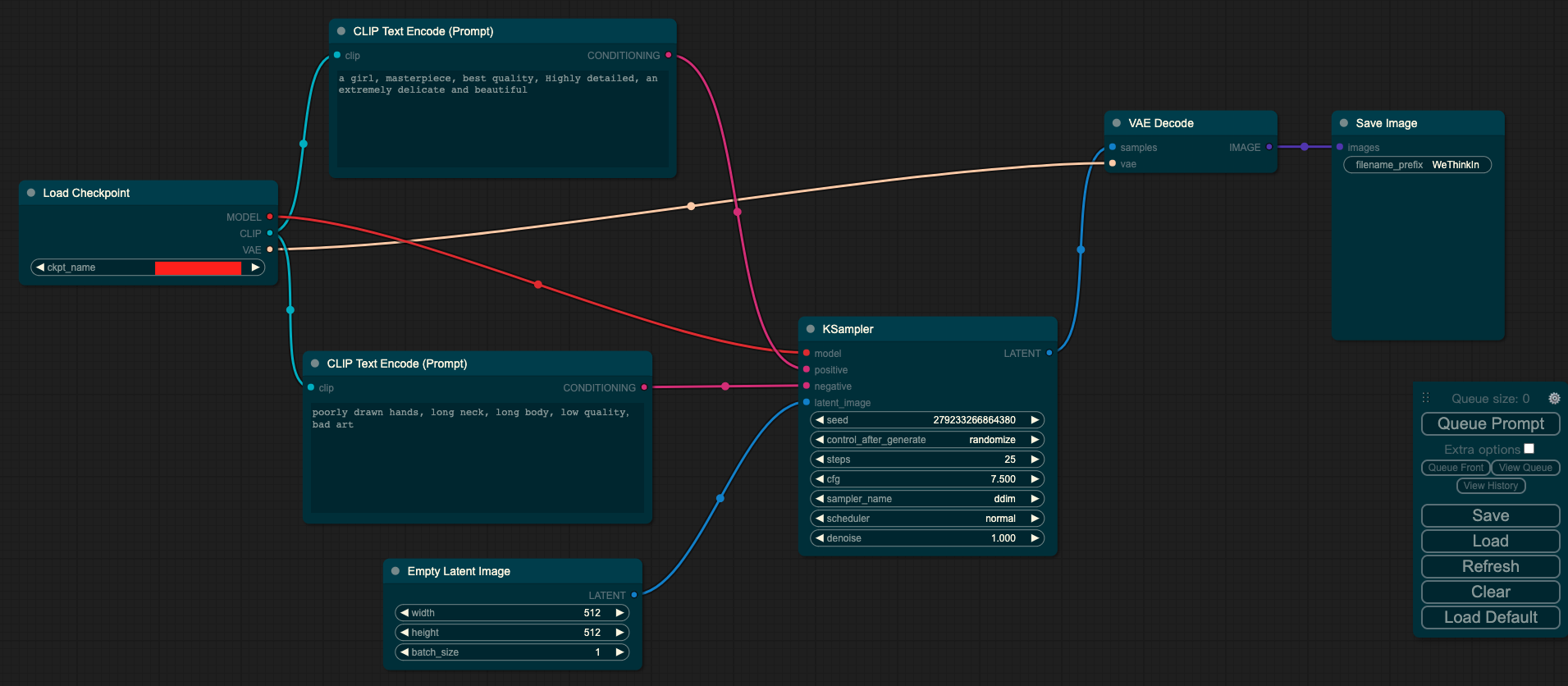
其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE,U-Net),CLIP Text Encode表示文本编码器,可以输入prompt和negative prompt,来控制图像的生成,Empty Latent Image表示初始化的高斯噪声,KSampler表示调度算法以及SD相关生成参数,VAE Decode表示使用VAE的解码器将低维度的隐空间特征转换成像素空间的生成图像。
图片生成图片
输入:图像 + prompt
输出:图像

其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE,U-Net),CLIP Text Encode表示文本编码器,可以输入prompt和negative prompt,来控制图像的生成,Load Image表示输入的图像,KSampler表示调度算法以及SD相关生成参数,VAE Encode表示使用VAE的编码器将输入图像转换成低维度的隐空间特征,VAE Decode表示使用VAE的解码器将低维度的隐空间特征转换成像素空间的生成图像。
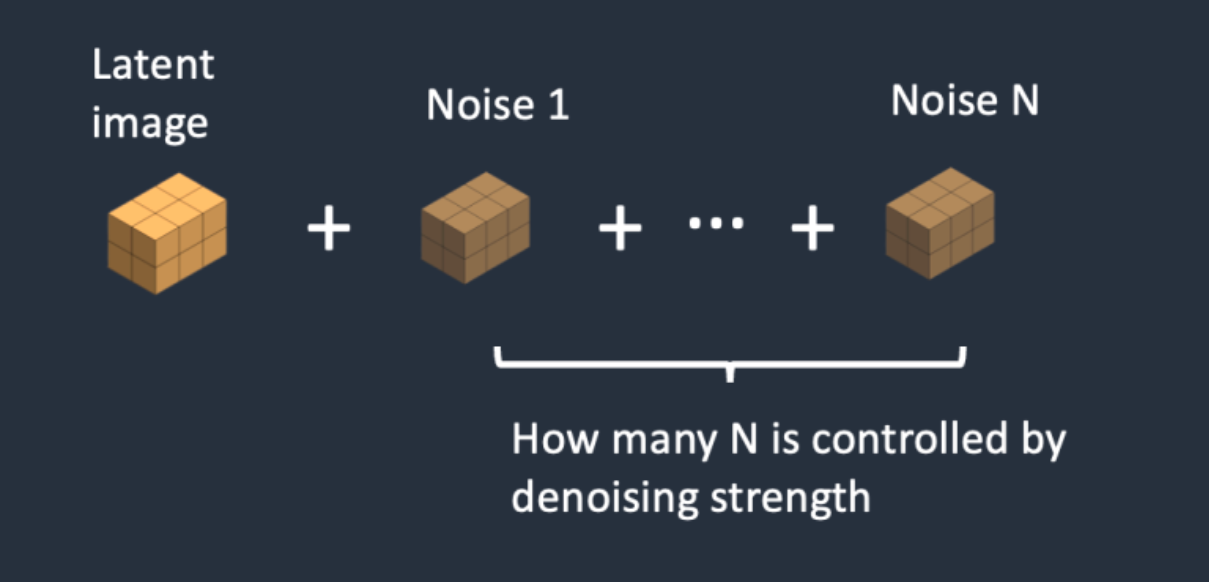
与文字生成图片的过程相比,图片生成图片的预处理阶段,先把噪声添加到隐空间特征中。我们设置一个去噪强度(Denoising strength)控制加入多少噪音。如果它是0,就不添加噪音。如果它是1,则添加最大数量的噪声,使潜像成为一个完整的随机张量,如果将去噪强度设置为1,就完全相当于文本转图像,因为初始潜像完全是随机的噪声。
图片inpainting
输入:图像 + mask + prompt
输出:图像
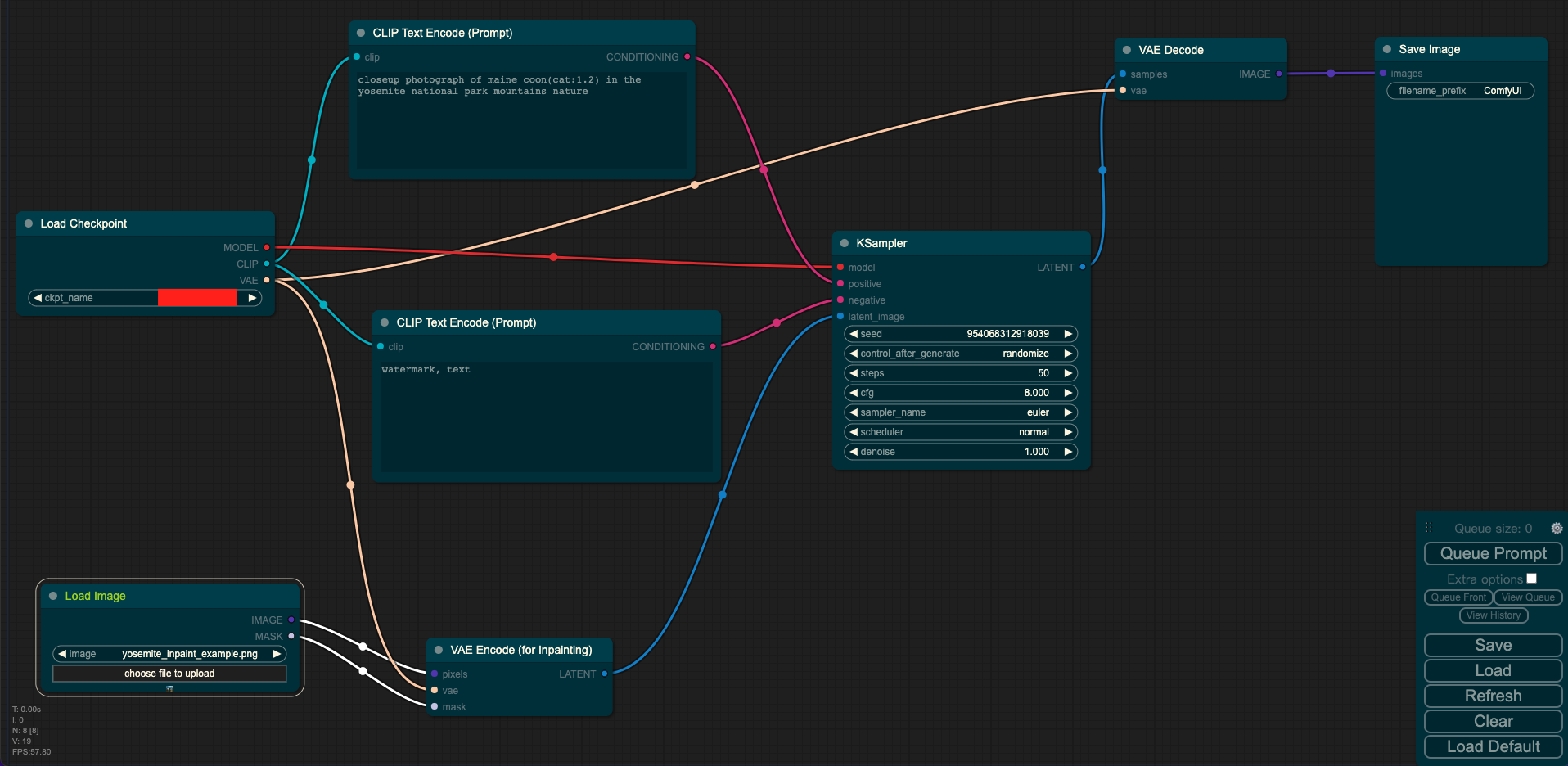
其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE,U-Net),CLIP Text Encode表示文本编码器,可以输入prompt和negative prompt,来控制图像的生成,Load Image表示输入的图像和mask,KSampler表示调度算法以及SD相关生成参数,VAE Encode表示使用VAE的编码器将输入图像和mask转换成低维度的隐空间特征,VAE Decode表示使用VAE的解码器将低维度的隐空间特征转换成像素空间的生成图像。
下面就是如何进行图像inpainting的直观过程:

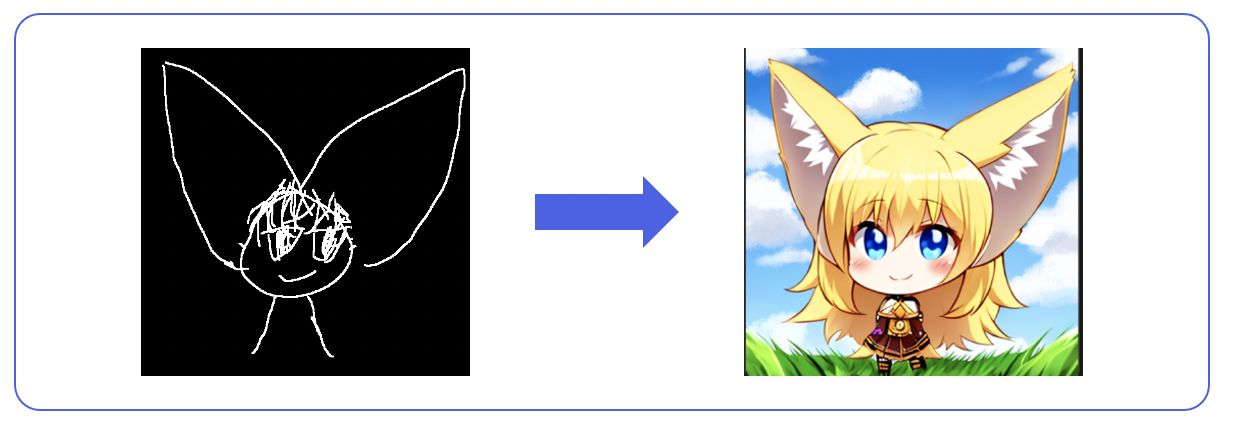
使用controlnet辅助生成图片
输入:素描图 + prompt
输出:图像
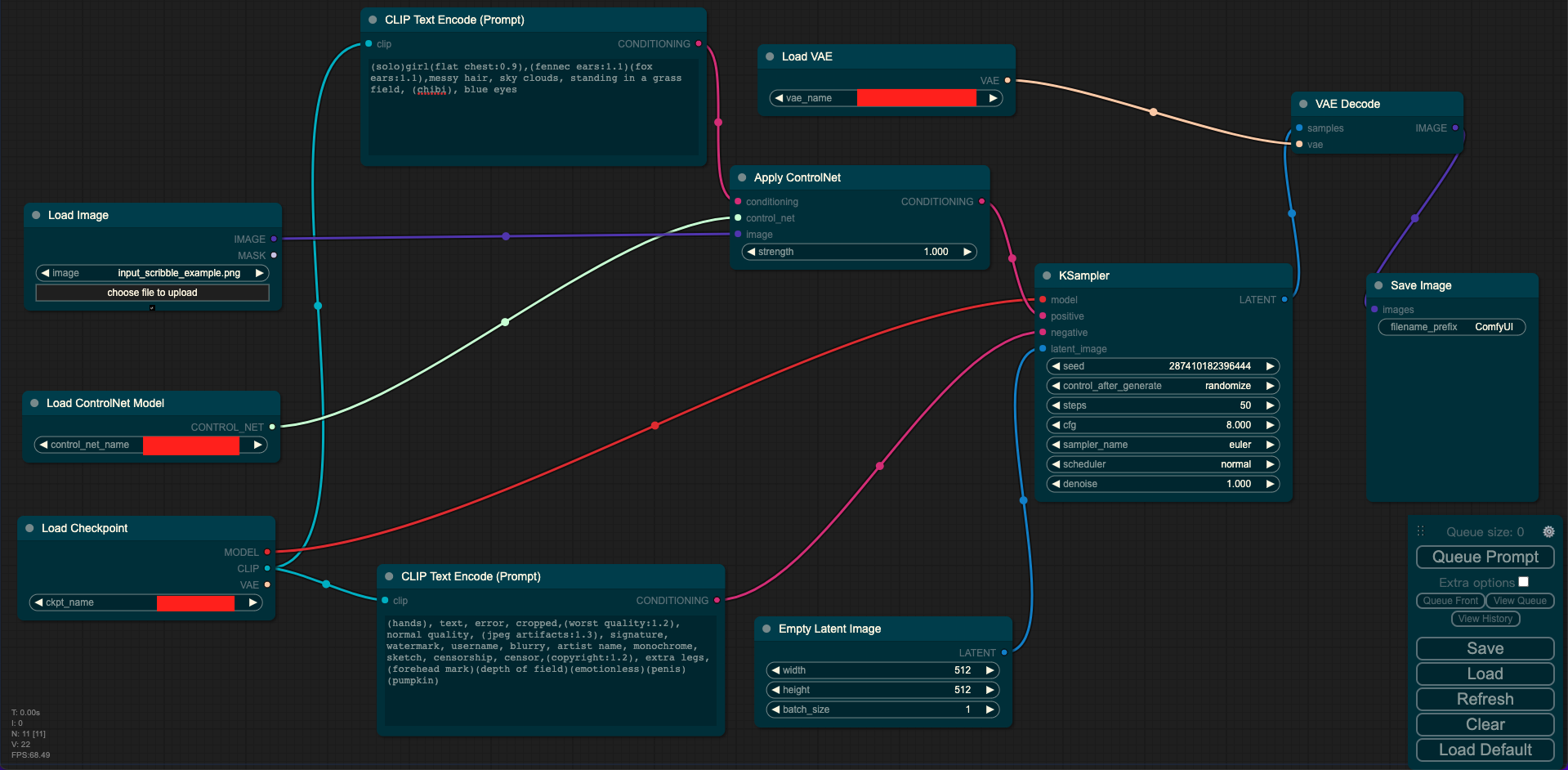
其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE,U-Net),CLIP Text Encode表示文本编码器,可以输入prompt和negative prompt,来控制图像的生成,Load Image表示输入的ControlNet需要的预处理图,Empty Latent Image表示初始化的高斯噪声,Load ControlNet Model表示对ControlNet进行初始化,KSampler表示调度算法以及SD相关生成参数,VAE Decode表示使用VAE的解码器将低维度的隐空间特征转换成像素空间的生成图像。
超分辨率重建
输入:prompt/(图像 + prompt)
输入:图像
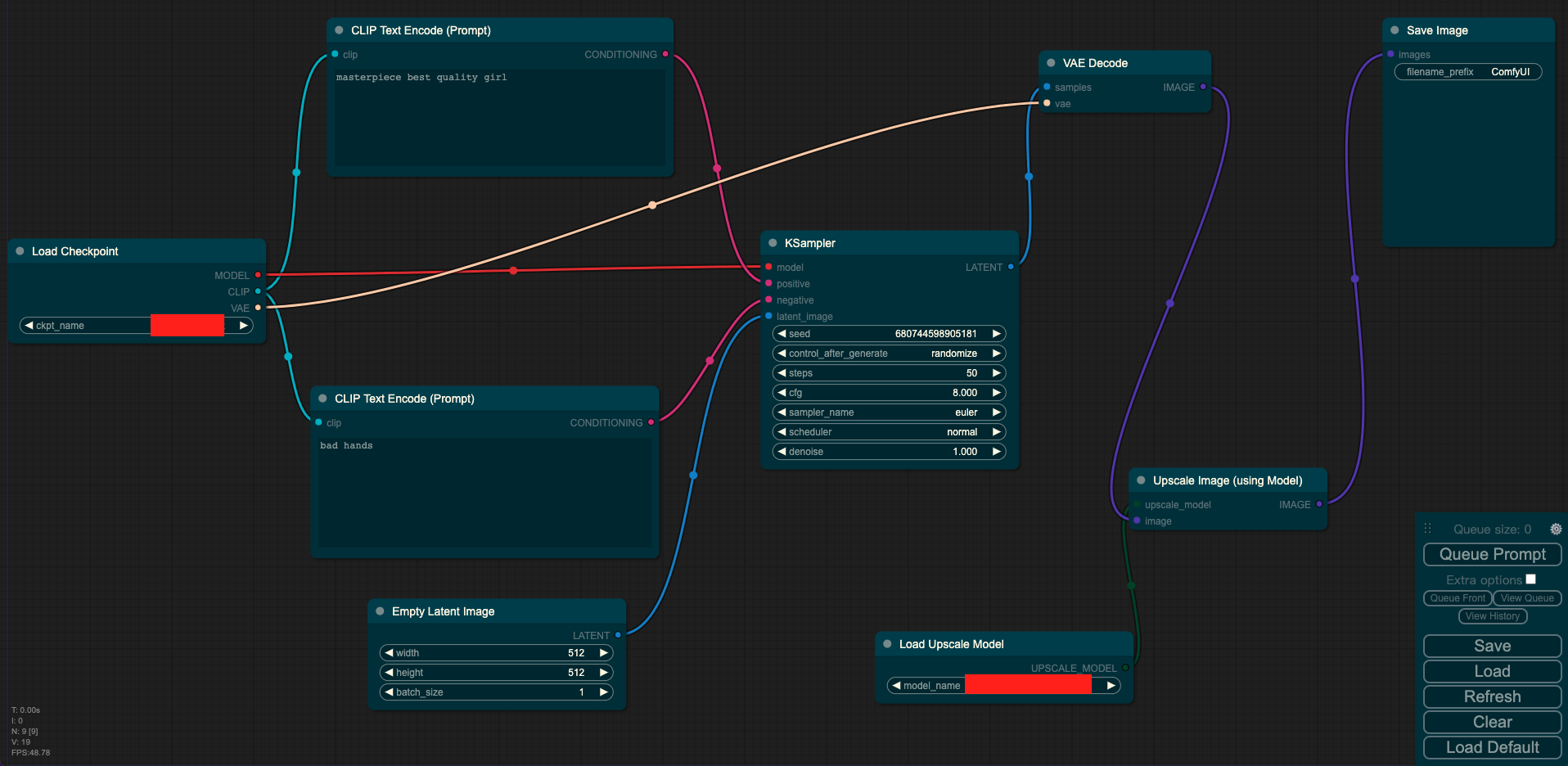
其中Load Checkpoint模块代表对SD模型的主要结构进行初始化(VAE,U-Net),CLIP Text Encode表示文本编码器,可以输入prompt和negative prompt,来控制图像的生成,Empty Latent Image表示初始化的高斯噪声,Load Upscale Model表示对超分辨率重建模型进行初始化,KSampler表示调度算法以及SD相关生成参数,VAE Decode表示使用VAE的解码器将低维度的隐空间特征转换成像素空间的生成图像,Upscale Image表示将生成的图片进行超分。
----【Stable Diffusion训练过程】----
Stable Diffusion的整个训练过程在最高维度上可以看成是如何加噪声和如何去噪声的过程,并在针对噪声的“对抗与攻防”中学习到生成图片的能力。
具体地,在训练过程中,我们首先对干净样本进行加噪处理,采用多次逐步增加噪声的方式,直至干净样本转变成为纯噪声。

接着,让SD模型学习去噪过程,最后抽象出一个高维函数,这个函数能在纯噪声中“优化”噪声,得到一个干净样本。
其中,将去噪过程具像化,就得到使用U-Net预测噪声,并结合调度算法逐步去噪的过程。
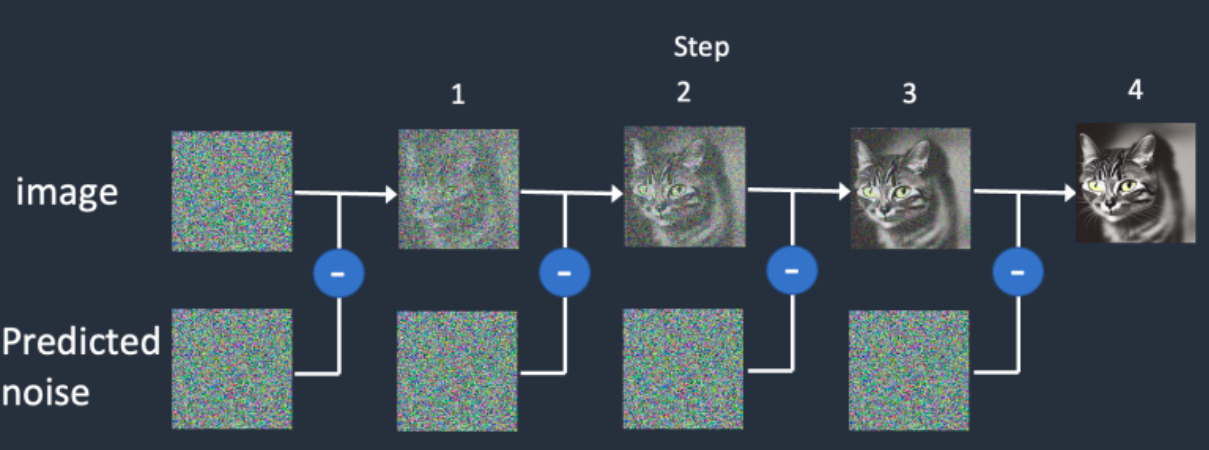
我们可以看到,加噪和去噪过程都是逐步进行的,我们假设进行步,那么每一步,SD都要去预测噪声,从而形成“小步快跑的稳定去噪”,类似于移动互联网时代的产品逻辑,这是足够伟大的关键一招。
与此同时,在加噪过程中,每次增加的噪声量级可以不同,假设有5种噪声量级,那么每次都可以取一种量级的噪声,增加噪声的多样性。
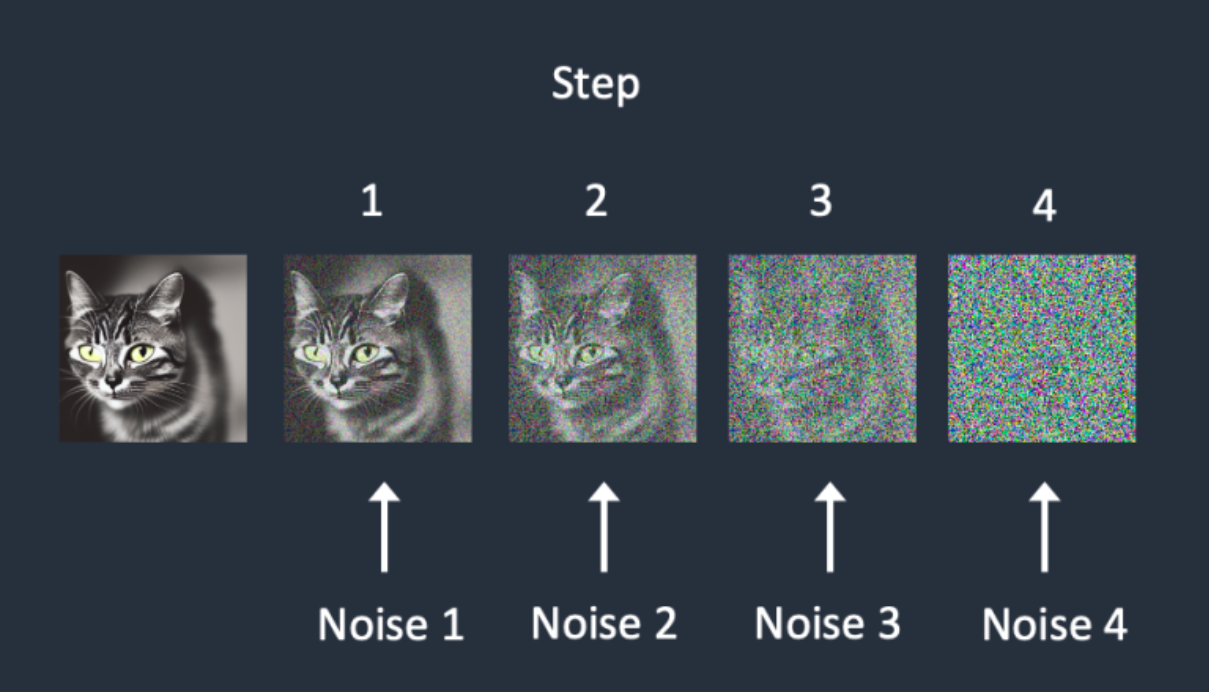
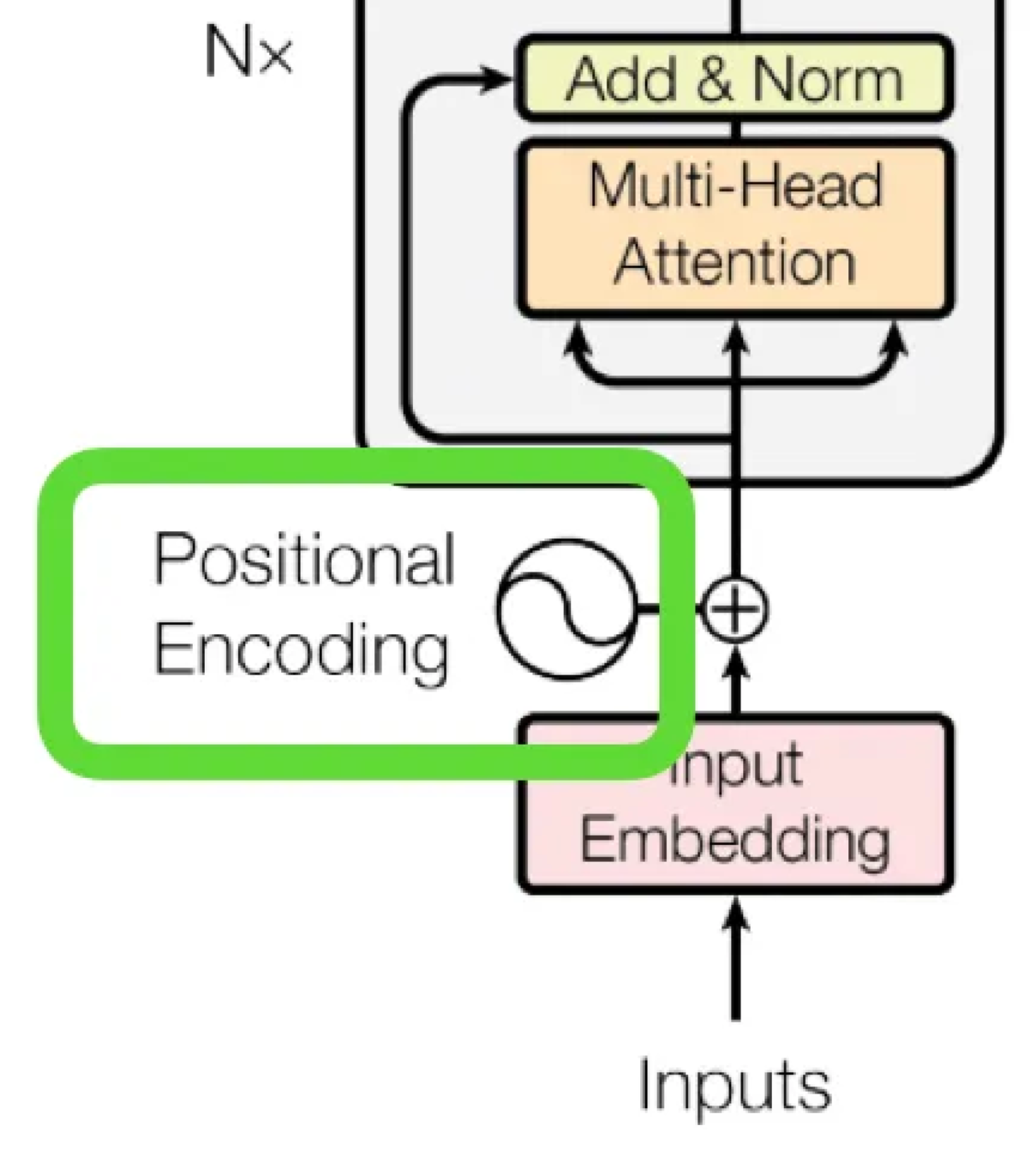
那么怎么让网络知道目前处于的哪一步呢?这时就需要Positional embeddings了,通过位置编码,将步数也传入网络中,从而让网络知道现在处于哪一步,和Transformer中的操作类似:
----【Stable Diffusion性能优化】----
使用TF32精度
import torch
torch.backends.cuda.matmul.allow_tf32 = True
TF32在性能和精度上实现了平衡。下面是TF32精度的一些作用和优势:
- 加速训练速度:使用TF32精度可以在保持相对较高的模型精度的同时,加快模型训练的速度。
- 减少内存需求:TF32精度相对于传统的浮点数计算(如FP32)需要更少的内存存储。这对于训练大规模的深度学习模型尤为重要,可以减少内存的占用。
- 可接受的模型精度损失:使用TF32精度会导致一定程度的模型精度损失,因为低精度计算可能无法精确表示一些小的数值变化。然而,对于大多数深度学习应用,TF32精度仍然可以提供足够的模型精度。
使用FP16半精度
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
)
使用FP16半精度训练的优势:
减少了一半的内存占用,我们可以进一步将batch大小翻倍,并将训练时间减半。 一些GPU如V100, 2080Ti等针对16位计算进行了优化,能自动加速3-8倍。
对注意力模块进行切片
当模型中的注意力模块存在多个注意力头时,可以使用切片注意力操作,使得每个注意力头依次计算注意力矩阵,从而大幅减少内存占用,但随之而来的是推理时间增加约10%。
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
# 切片注意力
pipe.enable_attention_slicing()
对VAE进行切片
和注意力模块切片一样,我们也可以对VAE进行切片,让VAE每次处理Batch(32)中的一张图片,从而大幅减少内存占用。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
#切片VAE
pipe.enable_vae_slicing()
images = pipe([prompt] * 32).images
大图像切块
当想要生成4k或者更大的图像,并且内存不充裕时,可以使用图像切块的操作,让VAE的编码器与解码器对切块后的图像逐一处理,最后从容拼接生成大图。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
prompt = "a beautiful landscape photograph"
# 大图像切块
pipe.enable_vae_tiling()
image = pipe([prompt], width=3840, height=2224, num_inference_steps=20).images[0]
CPU <-> GPU切换
可以将整个SD模型或者SD模型的部分模块权重加载到CPU中,只有等推理时再将需要的权重加载到GPU。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
)
#子模块CPU <-> GPU切换
pipe.enable_sequential_cpu_offload()
#整个SD模型CPU <-> GPU切换
pipe.enable_model_cpu_offload()
变换Memory Format
在CV领域,两种比较常见的memory format是channels first(NCHW)和channels last(NHWC)。将channels first转变成为channels last可能会提升推理速度,不过这也需要依AI框架和硬件而定。
在Channels Last内存格式中,张量的维度顺序为:(batch_size, height, width, channels)。其中,batch_size表示批处理大小,height和width表示图像或特征图的高度和宽度,channels表示通道数。
相比而言,Channels First是另一种内存布局,其中通道维度被放置在张量的第二个维度上。在Channels First内存格式中,张量的维度顺序为:(batch_size, channels, height, width)。
选择Channels Last或Channels First内存格式通常取决于硬件和软件平台以及所使用的深度学习框架。不同的平台和框架可能对内存格式有不同的偏好和支持程度。
在一些情况下,Channels Last内存格式可能具有以下优势:
- 内存访问效率:在一些硬件架构中,如CPU和GPU,Channels Last内存格式能够更好地利用内存的连续性,从而提高数据访问的效率。
- 硬件加速器支持:一些硬件加速器(如NVIDIA的Tensor Cores)对于Channels Last内存格式具有特定的优化支持,可以提高计算性能。
- 跨平台兼容性:某些深度学习框架和工具更倾向于支持Channels Last内存格式,使得在不同的平台和框架之间迁移模型更加容易。
需要注意的是,选择内存格式需要根据具体的硬件、软件和深度学习框架来进行评估。某些特定的操作、模型结构或框架要求可能会对内存格式有特定的要求或限制。因此,建议在特定环境和需求下进行测试和选择,以获得最佳的性能和兼容性。
print(pipe.unet.conv_out.state_dict()["weight"].stride())
# 变换Memory Format
pipe.unet.to(memory_format=torch.channels_last)
print(pipe.unet.conv_out.state_dict()["weight"].stride())
使用xFormers
使用xFormers插件能够让注意力模块优化运算,提升20%左右的运算速度。
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
).to("cuda")
# 使用xFormers
pipe.enable_xformers_memory_efficient_attention()
精致的结尾
到这里,Stable Diffusion的核心知识就完整展现在我们的面前了,希望在AIGC时代中,大家能和Rocky一起,飞速成长!

 查看14道真题和解析
查看14道真题和解析