
别让你的微服务在重试中死去:深入理解RPC异常重试机制
1 异常重试的意义
发起一次RPC调用远程的一个服务,如用户登录操作,先验证用户名密码,成功后,获取用户基本信息。通过远程的用户服务获取用户基本信息时,恰好网络故障,导致请求失败,而这请求我们希望它能尽可能执行成功,咋办?
需重发一次RPC调用,那是catch下,失败就再发起一次调用?显然不优雅。考虑RPC框架的重试机制。
2 RPC框架重试
当调用端发起的请求失败时,RPC框架自身可重试,再重发请求,用户可设置:
- 是否开启重试
- 重试次数
RPC异常重试:
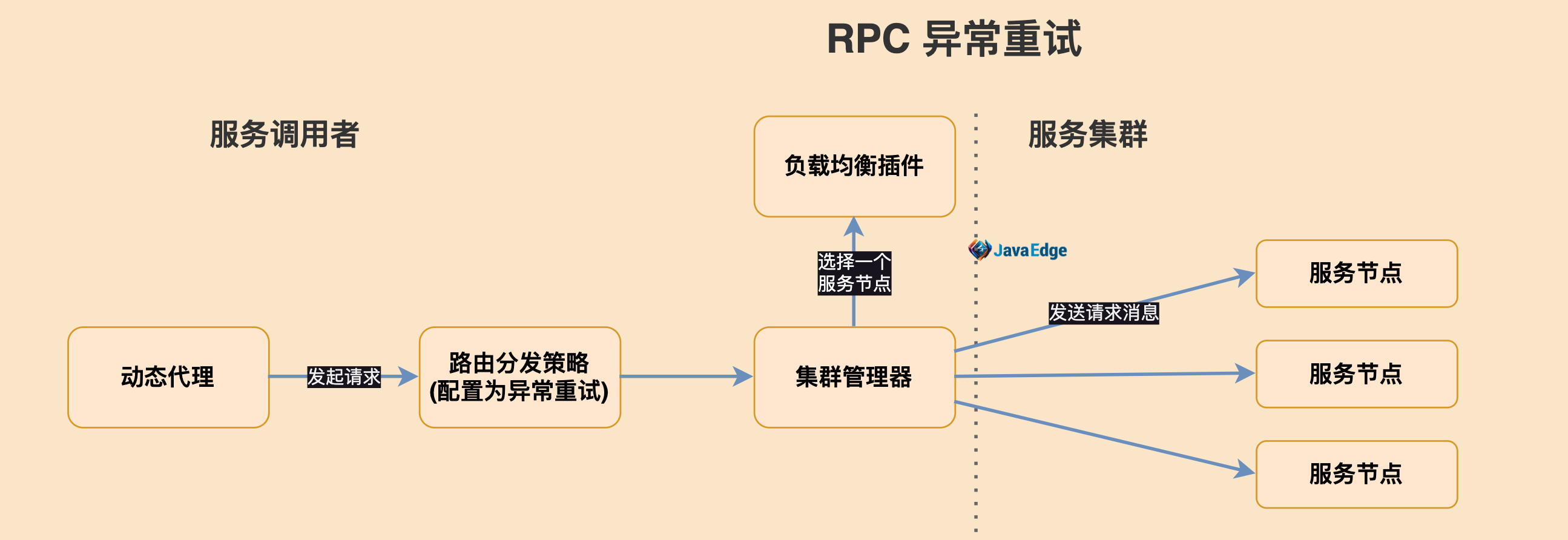
caller发RPC调用时,会经负载均衡,选择一个节点,之后向该节点发请求信息。当消息发失败或收到异常消息,即可捕获异常,根据异常触发重试,重新负载均衡选一节点发请求消息,并记录请求重试次数。当重试次数达到用户配置重试次数阈值,返回给caller动态代理一个失败异常,否则继续重试。
Q:RPC框架重试机制就是caller发现请求失败时捕获异常,再触发重试,所有异常都触发重试?
A:No!因为这异常可能是服务提供方抛回的业务异常,应正常返给动态代理,所以要在触发重试前判定捕获的异常,符合重试条件才触发,如网络超时异常、网络连接异常等。
3 业务逻辑须幂等
网络抖动一下导致请求超时,但这时调用方的请求信息可能已发到服务提供方的节点,也可能已发送到服务提供方的服务节点,若请求信息成功发送到服务节点,那这节点是不是就要执行业务逻辑了。
若此时发起重试,业务逻辑会被执行。若该服务业务逻辑不幂等,如插入数据操作,那触发重试就会引发问题。
综上,使用RPC框架的时候,要确保被调用的服务的业务逻辑幂等,才能考虑根据事件情况开启RPC框架异常重试功能。
4 超时时间的重置
把调用端的请求超时时间设5s,结果连续重试3次,每次耗时2s,那最终这请求耗时是6s,调用端设置的超时时间是不是就不准确了?
连续的异常重试,且每次处理的请求时间较长,最终会导致请求处理的时间过长,超出用户设置的超时时间。
解决该问题最直接方式:每次重试后都重置请求的超时时间。
当调用端发起RPC请求时,若发送请求发生异常并触发异常重试,先判定该请求是否已超时:
- 已超时,直接返回超时异常
- 否则,先重置该请求的超时时间,再发起重试
5 去掉有问题的服务节点
当调用端设置异常重试策略,发起一次RPC调用,通过负载均衡选择了节点,将请求消息发送到这节点。这时该节点由于负载压力大,导致该请求处理失败了,调用端触发了重试,再次通过负载均衡选择了一个节点,结果恰好仍选择该节点,这种情况下,重试效果受到影响。因此,要在所有发起重试、负载均衡选择节点时,去掉重试之前出现过问题的那个节点,以保证重试成功率。
RPC框架的异常重试机制,是调用端发送请求之后,若发送失败会捕获异常,触发重试,但不是所有异常都会触发重试,只有RPC框架中特定的异常才会如此,比如连接异常、超时异常。
而像服务端业务逻辑中抛回给调用端的异常是不能重试的。那么请你想一下这种情况:服务端的业务逻辑抛给调用端一个异常信息,而服务端抛出这个异常是允许调用端重新发起一次调用的。
案例
服务端的业务逻辑是对数据库某个数据的更新操作,更新失败则抛更新失败异常,调用端可再次调用,触发服务端重新执行更新操作。那这时对调用端来说,它接收到更新失败异常,虽然是服务端抛来的业务异常,但也可重试。
此时RPC框架重试机制如何优化?
RPC框架不知道哪些业务异常能去异常重试,可加个重试异常白名单,用户将允许重试的异常加入白名单。当调用端发起调用,并且配置了异常重试策略,捕获到异常后,采用这样的异常处理策略。若该异常是RPC框架允许重试的异常或该异常类型存在于可重试异常的白名单,就允许对该请求重试。
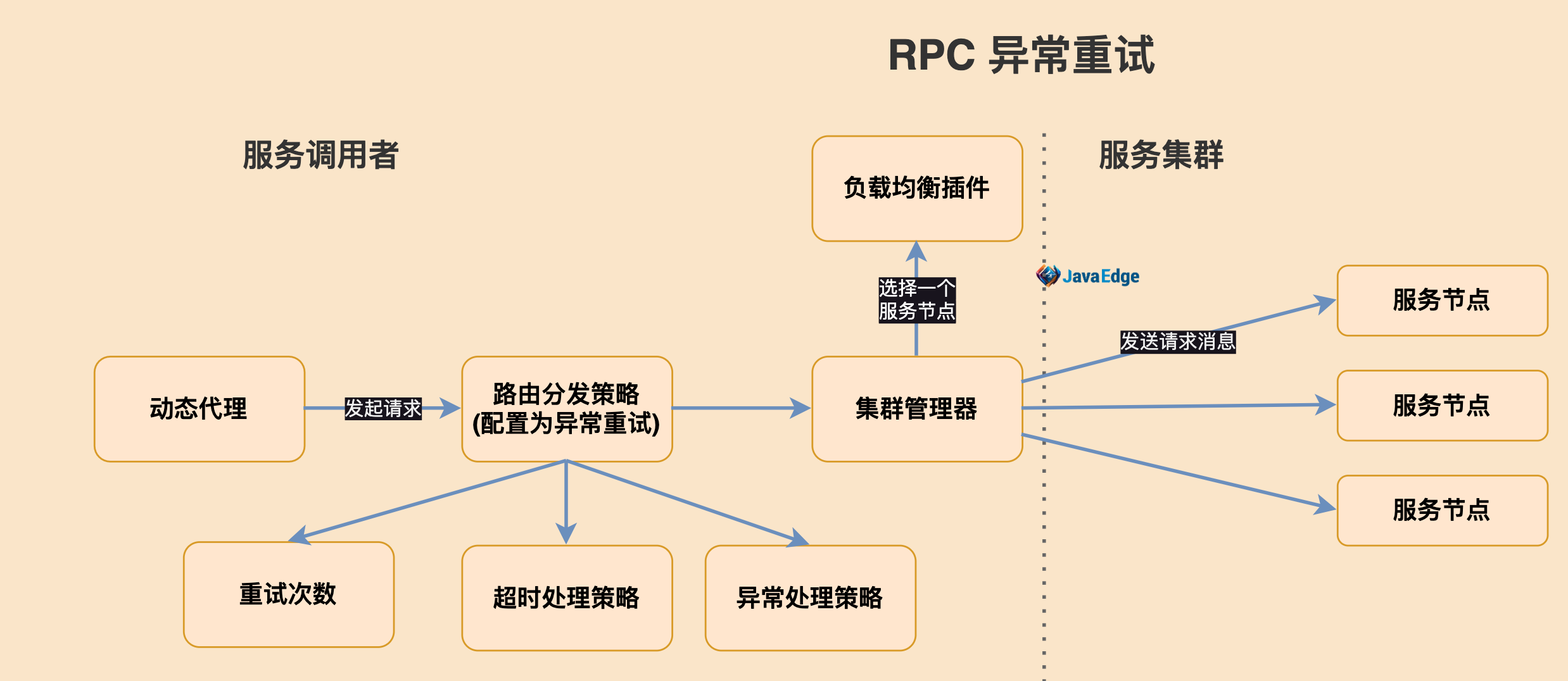
综上,可靠的异常重试机制:
6 总结
当调用端发起的请求失败时,如果配置了异常重试策略,RPC框架会捕捉异常,对异常进行判定,符合条件则进行重试,重发请求。
重试过程中,为在约定时间内进行安全可靠重试,在每次触发重试前,判定该请求是否已超时,若已超时,直接返回超时异常,否则重置该请求的超时时间,防止因多次重试导致该请求的处理时间超过用户配置的超时时间,而影响业务处理的耗时。
发起重试、负载均衡选择节点时,去掉重试前出现问题的节点,以提高重试成功率,并允许用户配置可重试异常的白名单,让RPC框架的异常重试功能对业务更友好。
要确保被调用的服务的业务逻辑是幂等的,才能考虑是否使用重试。
异常重试就是为了尽最大可能保证接口可用率的一种手段,但这种策略只能用在幂等接口上,否则就会因为重试导致应用系统数据“写花”。
FAQ
整个RPC调用的流程中,异常重试发生在哪环节?
重试也需要时间间隔一直调整,不然影响服务方性能。重试次数大于服务方实例时,动态调整重试间隔时间。比如当前服务有3个实例,调用方重试次数是10,前3次是失败就重试(不停换下一个节点)。从第4次开始,有延迟,第一次1S,第二次2S,第三次4S,以2幂次方增加重试间隔时间,保证服务调用方不因为重试把QPS或TPS占满。
异常重试机制发生在:客户端调用时,并且重试代码块包含的内容是集群处理(服务发现和负载均衡),及请求调用;并且包含异步响应的结果获取。 所以应该是在动态代理发起invoke,紧接着的一步。
感觉异常重试还是主要放到远程调用服务端这块?那如果是由于网络问题呢,调用端没收到响应,服务端就没法处理了吧!
failsafe failfast failover failback。
这个异常机制其实就像网络socket连接的时候发生的异常一样,我们可以采用避退策略。也就是第一次失败,延迟2秒再试第二次。假如第二次再失败,延迟4秒。直道重试次数达到上限。 当然了,在RPC场景下,我们也可以在前几次不断的路由切换,切换到不同的服务提供节点。
rpc都是实时业务,退避好像不合适啊
“保证被重试的业务服务是幂等的”,这就要求了服务提供方必须能支持重复请求,而这就需要业务部门在开发可提供的每一个服务时候都要注意到这一点,那么我们是否能在服务具体逻辑之前增加一层呢,比如每一次请求带有唯一id,这一层逻辑负责统计唯一id的执行情况以及是否完成了回调,重复收到的请求,是否能把保存下来的结果直接返回呢。
方案没问题,但需要考虑团队研发整体接受度
异常重试主要有客户端的重试,每个业务层也会有重试,通过幂等,白名单,摘除认为有问题的机器,重试次数来保证业务可用
rpc可以做到话,尽量下沉
这段超时时间重置不是很理解,A--->B--->C,B 调用 C 超时时间 10s,重试次数为 2. 如果 B 调用 C 耗费 5s 失败,然后重试。这时重试的超时不是只剩下 5 s 了吗? 如果又将这次超时时间重置为 10s,假如这次调用成功了,消耗了 9S,那么 B 总体耗费了 14 S,但是 A 设置超时时间假如 12 s,这时 A 不是已经超时断开了吗?
重置超时时间是指,将10秒置为5秒,很大开源的rpc框架是不会修改超时时间的。
异常重试机制应该发生在负载均衡选取服务节点并发起服务调用这个阶段,可以做到以下需求 \1. 服务调用失败,剔除失败的服务重新发起一次调用 \2. 捕获返回的异常信息,决定是否再次发起请求
如果最后一次重试,失败了,服务实际执行成功,造成调用方本地事务回滚,而服务下游数据提交成功,就会出现数据不一致。这能解决吗?还是这种问题出现概率小,到时候人工处理。
感觉是在动态代理的地方增加一个重试插件来实现。
rpc重试要业务层面负责幂等性
如果要重试,服务端的逻辑一定要幂等
在客户端使用动态代理执行远程调用的时候进行重试。因为这个时候能直接获取到调用结果,通过捕获的异常判断是否需要重试。
"caller收集服务端每个节点的指标数据,再按各种指标数据进行计算打分,最后根据每个节点分数,将更多流量打到分高的节点。",如果每个调用端都要单独检测服务端节点的各项指标,这也是一个不小的性能损耗把?这个检测要每个调用端自己实现吗?这个开发量也不少啊?
这个应该是rpc框架实现,方便使用方使用,至于性能开销,就要看计算的算法。
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W+技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网


