
《微服务架构实战》读书笔记-ZipKin
Zipkin是什么
zipkin分布式跟踪系统;它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
为什么使用Zipkin
结构概述
***(Tracers)存在在你的应用程序中生存,记录时间和关于操作的元数据。他们经常使用库,因此他们的使用对用户是透明的。例如,当它收到一个请求并发送一个响应时,一个感应器(instrumented )的web服务器记录。所收集的跟踪数据称为Span。
在生产过程中,instrumention是安全的,并且没有太多的开销。由于这个原因,他们只在带内(in-band)传播id,告诉接收方有一个正在进行中的跟踪。完成的跨度被报告给Zipkin的“外带(out-of-band)”,类似于应用程序如何异步地报告指标。
例如,当一个操作被跟踪,它需要发出一个传出的http请求时,会添加几个头来传播IDs。header不用于发送诸如操作名称之类的细节。
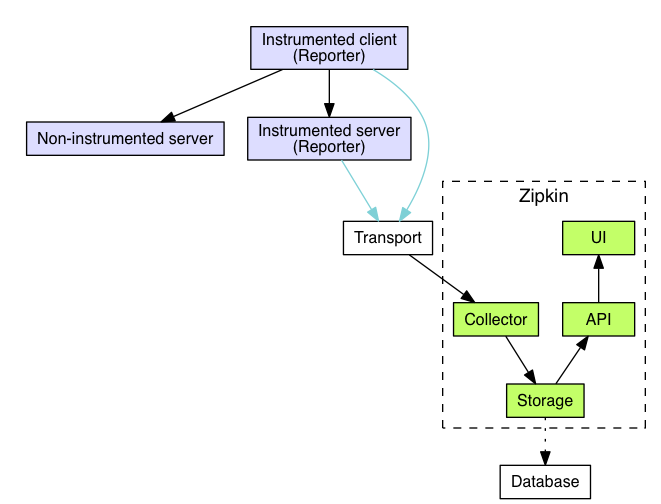
将数据发送给Zipkin的应用程序的一种组件被称为Reporter。记者(Reporters)通过几个传输器(transports )中的一个传输跟踪数据到Zipkin收集器(collectors),这些收集器将跟踪数据保存到存储(storage)中。稍后,通过API查询存储,以向UI提供数据。
下面是一个描述这个流程的图表:
Transport
由测试库发送的数据(Spans)必须从追踪到Zipkin的collectors的服务中传输。有三种主要的传输方式:HTTP、Kafka和Scribe。
Components
- collector
- storage
- search
- web UI
Zipkin Collector
一旦跟踪数据到达了Zipkin Collector守护程序,就会被Zipkin的收集器进行验证、存储和索引。
Storage
Zipkin最初是为了存储Zipkin的数据而建立的,因为Cassandra是可扩展的,有一个灵活的模式,在Twitter上被大量使用。但是,我们使这个组件可插拔。除了Cassandra之外,我们还支持弹性搜索和MySQL。其他的后端可以作为第三方扩展来提供。
Zipkin Query Service
一旦数据被存储和索引,我们就需要一种方法来提取数据。查询守护进程提供一个简单的JSON API用于查找和检索跟踪。这个API的主要使用者是Web UI。
Web UI
我们创建了一个GUI,为查看跟踪提供了一个很好的界面。web UI提供了一种基于服务、时间和注释查看跟踪的方法。注意:UI中没有内置的身份验证机制!
cs Client Send 客户端发起请求
sr Server Receive 服务器接收请求,开始处理
ss Server Send 服务器完成处理,给客户端应答
cr Client Receive 客户端接受应答从服务器
traceId:标记一次请求的跟踪,相关的Spans都有相同的traceId;
id:span id;
name:span的名称,一般是接口方法的名称;
parentId:可选的id,当前Span的父Span id,通过parentId来保证Span之间的依赖关系,如果没有parentId,表示当前Span为根Span;
timestamp:Span创建时的时间戳,使用的单位是微秒(而不是毫秒),所有时间戳都有错误,包括主机之间的时钟偏差以及时间服务重新设置时钟的可能性,
出于这个原因,Span应尽可能记录其duration;
duration:持续时间使用的单位是微秒(而不是毫秒);
annotations:注释用于及时记录事件;有一组核心注释用于定义RPC请求的开始和结束


 查看6道真题和解析
查看6道真题和解析