
数据结构
学习·算法的时间和空间复杂度
算法的特点
- 有限性(Finiteness):算法的有穷性是指算法必须能在执行有限个步骤之后终止,并且每个步骤在可接受时间内完成;
- 确切性(Definiteness):算法的每一步骤必须有确切的定义,无歧义
- 输入项(Input):一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
- 输出项(Output):一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
- 可行性(Effectiveness):算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步骤,即每个计算步都可以在有限步骤内完成(也称之为有效性)。
时间复杂度
若存在函数f(n), 使得当n趋近于无穷大时, T(n)/f(n)的极限值为不等于零的常数, 则称f(n)是T(n)的同数量级函数。 记作T(n)=O(f(n)), 称为O(f(n)), O为算法的渐进时间复杂度, 简称为时间复杂度

空间复杂度
一个算法在实施过程中,借助了额外的内存空间
void mergeSort(vector<int>& nums, vector<int>& temp, int l, int r){
if (l >= r) return;
int mid = (l + r) / 2;
mergeSort(nums, temp, l, mid);
mergeSort(nums, temp, mid+1, r);
int i=l,j=mid+1; int t = 0;
while (i<=mid && j<=r){
if (nums[i] <= nums[j]) temp[t++] = nums[i++];
else temp[t++] = nums[j++];
}
while (i <= mid) temp[t++] = nums[i++];
while (j <= r) temp[t++] = nums[j++];
for (int i=l,t=0; i<=r; i++)
nums[i] = temp[t++];
}
// 时间复杂度:O(nlogn)
// 空间复杂度:O(n) 如上的归并算法:借助了中间数组temp,因此空间复杂度为O(N)
线性表
线性表是一个相当灵活的数据结结构,其长度可根据需要增长或缩短,既对线性表元素不仅可以进行访问,还可删除和插入。
抽象数据类型(ADT或黑盒)包括的函数功能应有:构造一线性表、销毁一线性表、重置线性表、取长操作、判空操作、查找操作、删除操作、插入操作、取值操作。
template<class T>
class linearList
{
public:
virtual ~linearList(){}
virtual bool empty()const=0;
virtual int size()const=0;
virtual T& get()const=0;
virtual int index(const T& element)const=0;
virtual void erase(int index)=0;
virtua void insert(const T& element)=0;
virttual void output(ostream &out)const=0;
} 顺序表(数组)
顺序表时一种随机存取的存储结构(可下标访问)。其数据元素的存储位置遵循:假设每个数据元素存储需占用l个存储单元。
数组的特点是:
- 整齐:存储的是相同数据类型的元素
- 有序:所有元素在内存中是紧挨着的、连续的。
- 高效:正因为数组是有序的,可以直接通过下标访问元素,十分高效。

插入和删除操作的时间复杂度是O(n)。而数组是有序的,可以直接通过下标访问元素,十分高效,访问时间复杂度是O(1)(常数时间复杂度)。如果某些场景需要频繁插入和删除元素时,这时候不宜选用数组作为数据结构。
template<class T>class arrayList :public linearList<T> {
public:
arrayList(int initialCapacity = 10);
arrayList(const arrayList<T>&);
~arrayList() { delete[]element; }
virtual bool empty()const { return listsize == 0; }
virtual size_t size(){return listsize; }
virtual size_t capacity() { return arrayLength; }
virtual T& get(int ) const;
virtual T& operator[](int theIndex)const;
virtual int indexOf(const T& element)const;
virtual T& erase(int theIndex);
virtual size_t insert(int theIndex, const T& theInserElement);
virtual void output(std::ostream& os)const;
private:
void checkIndex(const int indexOf)const;
//std::shared_ptr<T[],end_connection> elememt;
//不建议使用智能指针形式的动态数组,
//因为析构函数使用的是默认delete,而不是delete[],
//若要使用则应该定义自己得删除器
void increaseLength(T*& , int , int);//扩容操作
T* element;
std::size_t listsize;
std::size_t arrayLength;
}; 反转字符串算法:
//反转字符串
oid reverseString(char* s, int sSize){
for (int i = 0, j = sSize - 1; i < j; ++i, --j) {
/* 不断 swap(s[i], s[j]) */
char c = s[i];
s[i] = s[j];
s[j] = c;
}
}
// 时间复杂度:O(n)
// 空间复杂度:O(1) 链表
链表( linked list) 是一种在物理上非连续、 非顺序的数据结构, 由若干节点( node) 所组成。
单向链表的每一个节点又包含两部分, 一部分是存放数据的变量data, 另一部分是指向下一个节点的指针next。双向链表有前驱prio和后继next。

//单向
struct ListNode {
int data;
ListNode *next;
};
//双向
struct ListNode{
int data;
ListNode* prio,*next;
}; 链表的特点是:
- 整齐:存储的是相同数据类型的元素
- 无序:所有元素在内存中是随机的、不连续的。
从渐进趋势来看,插入和删除操作的时间复杂度是O(1)。而链表是无序的,不可以直接通过下标访问元素,需要通过next指针逐次访问下一个元素才能找到目标元素,访问时间复杂度是O(n)。
如果某些场景需要频繁插入和删除元素时,这时候宜选用链表作为数据结构。但是如果需要高效访问元素时,不宜采用链表。
1、链表的创建和遍历
ListNode * initLink(){
ListNode * p=(ListNode*)malloc(sizeof(ListNode));//创建一个头结点
ListNode * temp=p;//声明一个指针指向头结点,用于遍历链表
//生成链表
for (int i=1; i<5; i++) {
ListNode *node=(ListNode*)malloc(sizeof(ListNode));
node->data=i;
node->next=NULL;
temp->next=node;
temp=temp->next;
}
return p;
} 2、链表中查找某结点
int selectElem(ListNode * p,int elem){
ListNode * t=p;
int i=1;
while (t->next) {
t=t->next;
if (t->data==elem) {
return i;
}
i++;
}
return -1;
} 3、向链表中插入结点
三种情况:
- 插入到链表的首部,也就是头结点和首元结点中间;
- 插入到链表中间的某个位置;
- 插入到链表最末端;

虽然插入位置有区别,都使用相同的插入手法。分为两步,如图所示:
- 将新结点的next指针指向插入位置后的结点;
- 将插入位置前的结点的next指针指向插入结点;
ListNode * insertElem(ListNode * p,int elem,int add){
ListNode * temp=p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (int i=1; i<add; i++) {
if (temp==NULL) {
printf("插入位置无效\n");
return p;
}
temp=temp->next;
}
//创建插入结点node
ListNode * node=(ListNode*)malloc(sizeof(ListNode));
node->data=elem;
//向链表中插入结点
node->next=temp->next;
temp->next=node;
return p;
} 4、从链表中删除节点
当需要从链表中删除某个结点时,需要进行两步操作:
- 将结点从链表中摘下来;
- 手动释放掉结点,回收被结点占用的内存空间;

ListNode * delElem(ListNode * p,int add){
ListNode * temp=p;
//temp指向被删除结点的上一个结点
for (int i=1; i<add-1; i++) {
temp=temp->next;
if (temp->next == NULL) // 判断add的有效性
return p;
}
ListNode *del=temp->next;//单独设置一个指针指向被删除结点,以防丢失
temp->next=temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域
free(del);//手动释放该结点,防止内存泄漏
return p;
} 总结:
线性表的链式存储相比于顺序存储,有两大优势:
- 链式存储的数据元素在物理结构没有限制,当内存空间中没有足够大的连续的内存空间供顺序表使用时,可能使用链表能解决问题。(链表每次申请的都是单个数据元素的存储空间,可以利用上一些内存碎片)
- 链表中结点之间采用指针进行链接,当对链表中的数据元素实行插入或者删除操作时,只需要改变指针的指向,无需像顺序表那样移动插入或删除位置的后续元素,简单快捷。
链表和顺序表相比,不足之处在于,当做遍历操作时,由于链表中结点的物理位置不相邻,使得计算机查找时需要通过遍历的方式,比起通过下标访问的顺序表,速度要慢。
数组访问时间复杂度O(1);插入和删除复杂度O(n)
链表访问时间复杂度O(n);插入和删除复杂度O(1)
//反转链表
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* cur = head;
while (cur) {
ListNode* next = cur->next;
cur->next = prev;
prev = cur;
cur = next;
}
return prev;
}
};
// 时间复杂度:O(n)
// 空间复杂度:O(1) 栈与队列
栈
栈规定:元素先入后出(First In Last Out, 简称FILO)
数组实现栈:
#include<exception>
#include<stdexcept>
template<class T>
class Stack
{
public:
virtual ~Stack() {};
virtual bool empty()const = 0;
virtual int size()const = 0;
virtual int Cap()const = 0;
virtual bool isFull()const = 0;
virtual T& top()const = 0;
virtual void increaseCapacity()=0;
virtual void push(const T& theElement) = 0;
virtual T& pop() = 0;
};
template<class T>
class arrayStack :public Stack<T> {
public:
arrayStack(int thecapacity = 10);
~arrayStack() { delete[]element; }
bool empty()const { return stackTop == stackBase; }
int size()const { return elementLength; }
int Cap()const { return capacity; }
bool isFull()const { return elementLength == capacity; }
T& top()const {
if (empty())
throw std::out_of_range("栈是空的");
return element[stackTop - 1]; }
void increaseCapacity();
void push(const T& theElement);
T& pop() {
if (empty())
throw std::out_of_range("栈是空的");
T e = element[--stackTop];
element[stackTop].~T();
elementLength--;
return e;
}
private:
int stackTop;
int stackBase;
int elementLength;
int capacity;
T* element;
};
template<class T>
arrayStack<T>::arrayStack(int thecapacity) {
stackTop = stackBase =elementLength = 0;
capacity = thecapacity;
element = new T[capacity];
}
template<class T>
void arrayStack<T>::increaseCapacity() {
arrayStack<T> s(capacity);
T e;
for (int n = elementLength; n > 0; --n) {
e = pop();
s.push(e);
}
delete[] element;
capacity = 2 * s.capacity;
element = new T[capacity];
for (int i = s.elementLength; i < 1;i--) {
e = s.pop();
push(e);
}
//s.~arrayStack(); s离开此作用域自动调用析构函数
}
template<class T>
void arrayStack<T>::push(const T& theElement) {
if (isFull())
increaseCapacity();
element[stackTop++] = theElement;
elementLength++;
}
链表实现栈:
template<class T>
class linkedStack:public stack<T>
{
public:
linkedStack(int capacity=10){stackTop=NULL;stackSize=0;}
~linkedStack()
{
while(stackTop!=NULL){
chainNode<T>nextNode=stackTop->next;
delete stackTop;
stackTop=nextNode;
}
}
bool empty()const{return stackSize==0;}
int size()const{return stackSize;}
T& top()
{
if(stackSize==0)
throw stackEmpty();
return stackTop->element;
}
void pop();
void push(const T& theElement)
{
stackTop=new chainNode<T>(theElement,stackTop);
//相当于s->element=theElement;s->next=stackTop;stackTop=s;
stackSize++;
}
private:
chainNode<T>* stackTop;
int stackSize;
}
template<class T>
void linkedStack<T>::pop()
{
if(stackSize==0)
throw stackEmpty();
chainNode nextNode=stackTop->next;
delete stackTop;
stackTop=nextNode;
stackSize--;
} 队列
队列是一个线性表,其插入和删除分别在不同端进行,插入那一端称为队尾rear,删除那一端称为队首(front) 。在数组循环队列中,空队特征是front = rear, 队满时也会有front = rear; 判断条件将出现二义性(到底是空还是满?)
解决方案有三种:
加设标志位,让删除动作使其为1,插入动作使其为0, 则可识别当前front == rear;
使用一个计数器记录队列中元素个数(即队列长度)
人为浪费一个单元,令队满特征为 front = (rear +1)%N---空闲单元法
这里采用空闲单元法解决二义性问题。

数组形式实现队列:
#include<string>
#include<iostream>
//自定义异常类
class illegalParameterValue
{
public:
illegalParameterValue() :message("Illega parameter value") {}
illegalParameterValue(const std::string& themessage) :message(themessage) {}
~illegalParameterValue() {}
void outputMessage() { std::cout << message << std::endl; }
private:
std::string message;
};
//数组实现队列
template<class T>
class arrayQueue
{
public:
arrayQueue(int initialCapacity = 10);
~arrayQueue() { delete[]element; }
bool empty()const { return front == rear; }
bool isFull()const { return (rear + 1) % queueCapacity == front; }
int size()const { return (queueCapacity + rear - front) % queueCapacity; }
int Cap()const { return queueCapacity; }
//取队头元素
T& frontElement()const{
if (empty())
throw illegalParameterValue("The arrayQueue is empty");
return element[front];
}
//取队尾元素
T& backElement()const {
if (empty())
throw illegalParameterValue("the arrayQueue is empty");
return element[rear-1];
}
//队尾插入
void push_back(const T& theElement);
//队头删除
T& pop_front();
//容量增加
void increaseCap();
private:
T* element;
int front, rear;
int queueCapacity;
};
template<class T>
arrayQueue<T>::arrayQueue(int initialCapaccity)
{
queueCapacity = initialCapaccity;
element = new T[queueCapacity];
front = rear = 0;
}
template<class T>
T& arrayQueue<T>::pop_front()
{
if (empty())
throw illegalParameterValue("the arrayQueue is empty");
T e = element[front];
element[front].~T();
front = (front + 1) % queueCapacity;
return e;
}
template<class T>
void arrayQueue<T>::push_back(const T& theElement)
{
if (isFull())
increaseCap();
element[rear] = theElement;
rear = (rear + 1) % queueCapacity;
}
template<class T>
void arrayQueue<T>::increaseCap()
{
arrayQueue<T> q(queueCapacity);
T e;
while (front<rear)
{
e = pop_front();
q.push_back(e);
}
delete[]element;
queueCapacity = 2 * queueCapacity;
element = new T[ queueCapacity];
front = rear = 0;
while (q.front<q.rear)
{
e = q.pop_front();
push_back(e);
}
} 链表形式实现队列:
链表实现队列无需考虑数组实现时的循环情况,只需考虑防止内存泄漏,不使用时及时释放即可。

#include<iostream>
using namespace std;
typedef int dataType;
struct node{ //链栈节点
dataType data; //数值
node *next; //指针域
};
class Queue{
public:
Queue();
~Queue();
void push(dataType var);
dataType pop();
int size();
bool isEmpty();
private:
node* front; // 队前
node* end; // 队后
int size_a; // 内存大小
};
Queue::Queue():size_a(0),end(NULL){ // 初始化
front = new node;
front->next = NULL;
}
Queue::~Queue(){
node *ptr = NULL;
while(front != NULL){
ptr = front->next;
delete front;
front = ptr;
}
}
void Queue::push(dataType a){ // end创建节点连接至front后面
if (end == NULL){
end = new node;
end->data = a;
end->next = NULL;
front->next = end;
}
else{
node* pTail = end; // 在end与front之间插入节点
end = new node;
end->data = a;
pTail->next = end;
end->next = NULL;
}
size_a++;
}
dataType Queue::pop(){
if (isEmpty()){
cout << "The queue is empty!" << endl;
return -1;
}
dataType data = front->next->data; // 删除front后一个节点
node* pCurr = front->next;
front->next = pCurr->next;
delete pCurr;
if (isEmpty()){
end = NULL;
}
size_a--;
return data;
}
int Queue::size(){
return size_a; //返回队列大小
}
bool Queue:: isEmpty(){
return (size() == 0);
} 哈希表(散列表)
哈希表也叫散列表,它是一个非常有用的数据结构。可以实现常数时间复杂度的查找。哈希表的做法是,将键值对放入数组中。因为数组可以通过下标实现常数时间复杂度的查找。这样相当于就找了键,也就找到了对应的值。
- 键值对通过取模或位运算等哈希函数操作来获取哈希值,这个哈希值就对应数组的下标。
- 数组一开始会申请一定数量的内存空间,当键值对多起来后,就需要两倍扩容。
- 在获取哈希值的过程中,可能出现哈希冲突,解决办法有开放地址法、二次探测法、链地址法。
桶和起始桶
当关键字的范围太大,不能用理想方法表示时,可以采用并不理想的散列表和散列函数:散列表位置的数量比关键字的个数少散列函数把若干个不同关键字映射到散列表的同一个位置,这时散列表的每一个位置叫一个桶;对关键字为K的数对,f(K)是起始桶;桶的数量等于散列表的长度或大小。
因为散列函数可以把若干个关键字映射到同一个桶,所以桶要能容纳多个数对
哈希的优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。如果不需要有序遍历数据,并且可以*数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。**
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)
哈希表的应用场景
哈希表适用于那种查找性能要求高,海量数据的应用场景,数据元素之间无逻辑关系要求的情况。
- 校验安装文件的完整性
在软件部署的时候,计算软件包当前的哈希值是否与预设值相等,防止软件包被篡改或被替换。Linux提供了基于sha算法的命令,用于计算文件的哈希值。
sha256sum fileName
存储和校验用户口令
用户口令不能用明文存储,更进一步,如果系统不知道用户口令明文,那就更好了,而哈希算法就可以做到既不知道用户明文,又可以校验用户口令
校验重复提交的消息
用户可能因为误操作重复提交数据,而这些数据会对系统产生影响,若要拒绝这些消息,最好的方法就是在每次提交时,计算消息的哈希值,当发现疑似重复提交的时候,做消息哈希值的对比,也可以防止哈希冲突攻击
作为数据库乐观锁的条件
数据库中,最常用的乐观锁方法是在表中增加额外的一列,用于记录一行数据的版本值,通常是一个计数或是时间戳。但是,一张已经存在大量数据的表需要增加额外的版本列,似乎不太可行,也不太方便,此时可以通过哈希计算出虚拟的版本列,用于乐观锁定控制,下面是摘自《Oracle 9i&10g 编程艺术》的例子。
begin for x in ( select deptno, dname, loc from dept where deptno = 10 ) loop dbms_output.put_line( 'Dname: ' || x.dname ); dbms_output.put_line( 'Loc: ' || x.loc ); dbms_output.put_line( 'Hash: ' || dbms_crypto.hash ( utl_raw.cast_to_raw(x.deptno||'/'||x.dname||'/'||x.loc), dbms_crypto.hash_sh1 ) ); end loop; end;
哈希冲突
开放定址法(再散列法):
当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
//其中H(key)为哈希函数,m 为表长,di称为增量序列 - 线性探测再散列
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
di=1,2,3,…,m-1
- 二次探测再散列
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
- 伪随机探测再散列
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
di=radom(1)*100;
再哈希法:
这种方法是同时构造多个不同的哈希函数
Hi=RH1(key) i=1,2,…,k 当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
连地址法:
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表(或红黑树),并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
下图是链地址法解决哈希冲突的图示:

建立公共溢出区:
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
下述代码为散列表的基本思想:
sting类型转换为整型Key:
template<>
class hash<string>
{
public:
size_t operator()(const string theKey)const
{
//把关键字theKey转换为一个负整数
int length=(int)theKey.length();
for(int i=0;i<length;i++)
{
hashValue=5*hashVlaue+theKey.at(i);
}
return size_t(hashValue);
}
}; hashTable的数据成员和成员函数:
template <class K,class V>
class hashTable<K,v>
{
public:
hashTable();
~hashTable();
int search(const K& theKey)const;
pair<const K,V>* find(const K& theKey)const;
void insert(const pair<const K,V>& thePair);
private:
pair<const K,V>**table; //散列表
hash<K> hash; //将类型K映射成为整数,即为哈希函数做准备
int dSize; //字典中的数对个数
int divisor; //散列函数除数
};
//哈希构造
template<class K,class V>
hashTable<K,V>::hashTable(int theDivisor)
{
divisor=theDivisor;
dSize=0;
//分配河初始化散列表数组
table=new pair<const K,V>*[divisor];
for(int i=0;i<divisor;i++)
table[i]==NULL;
}
template<class K,class V>
int hashTable<K,v>::search(const K&theKey)const
{
//搜素一个公开地址散列表,查找关键字为theKey的数对
//若匹配数对,返回它的位置,否则,若散列表不满,则返回可插入theKey数对的位置
int i=(int)hash(theKey)%divisor; //起始桶
int j=i;
do
{
if(table[j]==NULL||table[j]->first==theKey)
return j;
j=(j+1)%divisor; //使用开放定址法的线性探测策略
}while(j!=i);
return j;
}
template<class K,class V)
pair<const K,V>* hashTable<K,E>::find(const K& theKey)const
{
//返回匹配数对的指针
//若不匹配,则返回NULL
int B=search(theKey);
if(table[B]==NULL||table->first!=theKey)
return NULL;
return table[B];
}
template<class K,class V>
void hashTable<K,V>::insert(const pair<const K,E>& thePair)
{
//把数对thePair插入散列表中,若存在相同关键字的数对,则覆盖
//若表满,则抛出异常
//搜索散列表,查找匹配的数对
int b=search(thePair->first);
if(table[b]==NULL)
{
//没有匹配的数对,而且表不满
table[b]=new pair<const K,V>*(thePair);
dSize++;
}
else
{
if(table[b]->first==thePair.first)
{
table[b]->second=thePair.second;
}
else
throw hashTableFull();
}
} 二叉树
概念
定义:一颗二叉树T是有限个元素的集合(可为空)。当为非空时,其中一个元素为根,该节点(如果还要元素的话)下有可能有左子树和右子树。
二叉树和树的根本区别是:
- 二叉树的每个元素恰好有两颗子树。而树可有任意数量的子树
- 在二叉树中,每个元素的子树都是有序的,即左子树和右子数之分。而树的子树是无序的
- 二叉树可以为空。而树不能为空

满二叉树:一个二叉树的所有非叶子节点都存在左右孩子, 并且所有叶子节点都在同一层级上, 那么这个树就是满二叉树。

完全二叉树:对一个有n个节点的二叉树, 按层级顺序编号, 则所有节点的编号为从1到n。 如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同, 则这个二叉树为完全二叉树。

性质
在二叉树的第i层上至多有2^(i-1)个结点(i>=1);
深度为K的二叉树至多有2^(k)-1个结点(K>=1);
对任何一颗二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1;
具有n个结点的完全二叉树的深度为L[log2(n)]+1; (L[X]表示取不大于X的最大整数)
如果对一颗有n个结点的完全二叉树(深度为L[log2(n)]+1)的结点按层序编号(从第一层到L[log2(n)]+1层,每层从左到右),则对任一结点i(1<=i<=n),有:
①i=1,则结点i是二叉树的根,无双亲;i>1,则其双亲时结点[i/2]
②如果2i>n,则结点i无左孩子,否则其左孩子为2i
③如果2i+1>n,则结点无右孩子,否则其右孩子为2i+1
/*
**节点类,用于构建树
*/
template<class T>
class binaryTreeNode
{
public:
T element;
binaryTreeNode<T>* rightChrild, * leftChrild;
binaryTreeNode(){ rightChrild = NULL; leftChrild = NULL; }
binaryTreeNode(const T& theElement) :element(theElement),rightChrild(NULL),leftChrild(NULL) {}
binaryTreeNode(const T& theElement, binaryTreeNode<T>* theRightChrild, binaryTreeNode<T>* theLeftChrild) :element(theElement), rightChrild(theRightChrild), leftChrild(theLeftChrild) {}
}; 遍历
树的遍历有四种:前序遍历、中序遍历、后序遍历、层序遍历。
前序遍历的递归方法:先输出根节点,再顺序遍历左右子树。

template<class E>
void binaryTree<E>::preOrder(binaryTreeNode<E>* t) //递归前序遍历
{
if (t != NULL)
{
visit(t);
preOrder(t->leftChild);
preOrder(t->rightChild);
}
} 非递归:以压栈形式遍历,先输出节点信息,再持续左节点压入,没有左节点后(NULL),弹出找右节点,循环以上步骤,直到遍历完整棵树,即栈为空
template<class E>
void binaryTree<E>::preOrder(binaryTreeNode<E>* root)
{
Stack<binaryTreeNode<E>*> _stack;
binaryTreeNode<E>* temp=root;
while(temp||!_stack.empty())
{
while(temp)
{
visit(temp);
_stack.push(temp);
temp=temp->leftChild;
}
if(!_satck.empty())
{
temp=_stack.top();
_stack.pop();
temp=temp->rightChild;
}
}
} 中序遍历的非递归方法:以压栈形式遍历,先判断根节点压入,持续压入左节点,后弹出输出节点信息,再寻找右节点,循环以上步骤,直到遍历完整棵树

template<class E>
void binaryTree<E>::inOrder(binaryTreeNode<E>* root)
{
Stack<binaryTreeNode<E>*> _stack;
if(root!=NULL){
binaryTreeNode<E>* temp=root;
_stack.push(temp);
temp=temp->leftChild;
}
while(!_stack.empty())
{
while(temp)
{
_stack.push(temp);
temp=temp->leftChild;
}
if(!_stack.empty())
{
temp=_stack.top();
_stack.pop();
visit(temp);
temp=temp->rightChild;
}
}
} 后序遍历的非递归方法:以压栈形式实现,先判断根节点压入,后持续压入左节点,取栈顶节点,判断第几次出现在栈顶,第一次则寻找右节点,第二次则弹出输出节点信息(难度较大)

//非递归后序遍历-迭代
void postorderTraversal(TreeNode *root, vector<int> &path)
{
stack<TempNode *> s;
TreeNode *p = root;
TempNode *temp;
while(p != NULL || !s.empty())
{
while(p != NULL) //沿左子树一直往下搜索,直至出现没有左子树的结点
{
TreeNode *tempNode = new TreeNode;
tempNode->btnode = p;
tempNode->isFirst = true;
s.push(tempNode);
p = p->left;
}
if(!s.empty())
{
temp = s.top();
s.pop();
if(temp->isFirst == true) //表示是第一次出现在栈顶
{
temp->isFirst = false;
s.push(temp);
p = temp->btnode->right;
}
else //第二次出现在栈顶
{
path.push_back(temp->btnode->val);
p = NULL;
}
}
}
}
层序遍历:使用队列实现,判断根节点,后放入队列,取队头,判断后依次压入其左右节点,循环如此,直到遍历完

template<class E>
void binaryTree<E>::levelOrder(binaryTreeNode<E>* t)
{
//层次遍历,使用队列
arrayQueue<binaryTreeNode<E>*> q;
while (t != NULL)
{
visit(t);
if (t->leftChrild != NULL)
q.push_back(t->leftChrild);
if (t->rightChrild != NULL)
q.push_back(t->rightChrild);
if (q.size != 0)
t = q.pop_front;
else
t = NULL;
}
} 堆
大根堆
大根堆的每个节点都大于或等于其子节点的值。二叉堆虽然是树的概念,但是却是以数组的方式存储的。二叉堆可以用来实现堆排序。堆排序是一个效率要高得多的选择排序,首先把整个数组变成一个最大堆,然后每次从堆顶取出最大的元素,这样依次取出的最大元素就形成了一个排序的数组:

堆排序的核心分成两个部分,第一个是新建一个堆,第二个是弹出堆顶元素后重建堆。
堆的操作:
①插入:因为堆是完全二叉树,所以当加入一个元素形时,必须维持该堆仍为完全二叉树,即该新节点位置由此定下了。接着元素插入要依据原来是大根堆还是小根堆(即不能破环该堆的性质)。把插入的元素,沿着从新节点到根节点的路径,执行一趟冒泡操作,将新元素与其父节点的元素比较交换,直到后者大于前者(大根堆为例)。上面的插入策略是一个冒泡的过程,因此时间复杂为O(log2n)
②删除:在大根堆中删除一个元素,就是删除根节点的元素,取堆顶元素,在弹出根节点之后,把根节点的元素和树的最底层最右侧的元素互换(最后一个叶子节点)。此时堆肯定被破坏了,需重建堆,从根节点开始和两个子节点比较,如果父节点比最大的子节点小,那么就互换父节点和最大的子节点,直到没有或到最后一层。
③初始化:当堆刚开始时就要有n个元素,我们就要构建非空堆,我们需要在堆中执行n次插入操作。先将元素按层次插入,取位置在i=n/2的元素,如果以这个元素为根的子树是大根堆则不做操作,如果不是大根堆则从该节点开始的树进行检测替换,依次检查i-1,i-2……1等结点图解见P302页
//大根堆类定义
#include<string>
#include<iostream>
class queueException
{
public:
queueException():message("这个最大优先级类有错误") {}
queueException(const std::string& theMessage) :message(theMessage) {}
~queueException() {}
void outputException()
{
std::cout << message << std::endl;
}
private:
std::string message;
};
template<class T>
class maxHeap
{
public:
maxHeap(int capacity = 10) :heaSize(0), arrayLength(0) { heap = new T[capacity]; }
~maxHeap() { delete[]heap; }
bool empty() { return heaSize == 0; }
std::size_t size() { return heaSize; }
sta::size_t cap() { return arrayLength; }
//取堆顶元素
T& top()const;
//插入操作
void push(const T& theElement);
//删除堆顶元素
void pop();
//初始化大根堆
void initialize(T* theHeap, std::size_t theSize);
private:
std::size_t heaSize;
std::size_t arrayLength;
T* heap;
};
取堆顶元素:
template<class T>
T& maxHeap<T>::top()const
{
if (empty())
throw queueException("The priority queue is empty");
return heap[1];
} 插入操作:
template<class T>
void maxHeap<T>::push(const T& theElement)
{
//省略满元素数组加倍代码
int currentNode = ++heaSize;
while (currentNode!=1&&heap[currentNode/2]<theElement)
{
//比较父节点与子节点大小,若子>父,则执行该循环体
heap[currentNode] = heap[currentNode / 2];
currentNode /= 2;
}
heap[currentNode] = theElement;
} 删除操作:
template<class T>
void maxHeap<T>::pop()
{
if (heaSize == 0)
throw queueException("The priority queue is empty");
heap[1].~T(); //销毁根结点元素
T lastElement = heap[heaSize]; //将最后节点元素保存到中间量
heap[heaSize--].~T(); //销毁最后一节点元素
int currentNode = 1, child = 2;
while (child<heaSize)
{
if (child < heaSize && heap[child] < heap[child + 1])
child++;
//判断lastElement是否可以放在heap[currentNode]上
if (lastElement >= heap[child]) //可以
break;
heap[currentNode] = heap[child]; //不可以
currentNode = child
child *=2;
}
heap[currentNode] = lastElement; //保存lastElement到head[current]
}
初始化操作:
template<class T>
void maxHeap <T> ::initialize(T* theHeaad, std::size_t heapSize)
{
delete[]heap;
heap = theHeaad;
heaSize = heapSize;
//堆化,从root=heaSize/2开始,直到root=1
for (size_t root = heaSize/2; root>=1; root--)
{
T rootElement = heap[root];
int child = 2 * root;
while (child<=heaSize)
{
if (child < heaSize && heap[child] < heap[child + 1])
child++;
if (rootElement >= heap[child]) //可以将元素rootElement放到heap[child/2]
break;
heap[child / 2] = heap[child];
child *= 2;
}
heap[child/2]=rootElement
}
} 二叉堆节点“ 上浮” 和“ 下沉” 的时间复杂度都是O(logn) ,即调整堆的时间复杂度都是O(logn)。建堆过程的时间复杂度是O(n)。堆排序的时间复杂度是O(nlogn)
STL的类priority_queue利用了基于向量的堆来实现大根堆,它允许用户制定自己的优先级比较函数,因此,这个类也可以实现小根堆。
#include<queue> //升序队列,小顶堆 priority_queue<int,vector<int>,greater<int> > que; //降序队列,大顶堆 priority_queue<int,vector<int>,less<int> > que;
搜索树
搜索树主要有二叉搜索树和索引二叉搜索树。
二叉搜索树:查找、插入和删除操作的所需平均时间为O(log2n),最坏的情况为O(n)。对于给定一个关键字,使用二叉搜索树,可以在O(n)时间内,找到最接近它的关键字。
索引二叉搜索树:可以按关键字和按名次进行字典操作,例如读取关键字从小到大排名排名第10的元素。按名次的操作和按关键字的操作,其时间性能一样。索引二叉搜索树其中的元素具有名次(即索引),没有关键字。
二叉搜索树
二叉搜索树是一颗二叉树,可能为空,一颗非空的二叉搜索树满足以下特点:
- 每个元素有一个关键字,并且任意两个元素的关键字都不同(有重复值的二叉搜索树除外),因此所有的关键字都是唯一的
- 在根节点的左子树中,元素的关键字(如果有的话)都小于根节点关键字
- 在根节点的右子数中,元素的关键字都大于根节点的关键字
- 根节点的左右子树也都是二叉树
查找:查找关键字为theKey的元素,先从根查找,如果根为空,则搜索树为空的;若不为空,则将theKey与根关键字比较大小,由二叉树搜索树的性质知,比根的大,则向右子数查找,若小,则向左子树查找,依次类推
template<class K,class E>
pair<const K,E>*binarySearchTree<K,E>::find(const K& theKey)const
{
binaryTreeNode<const K,E>*p=rootNode;
while(p!=NULL)
{
if(theKey<p->element.first)
p=p->leftChild;
else if(theKey<p->element.first)
p=p->rightChild;
else
return &p->element;
}
return NULL;
} 插入:重复的关键字进行值更新,从根节点开始比较,直到遇到相同的关键或NULL
template<class K,class E>
void binarySearchTree<K,E>::insert(const pair<const K,E>& thePair)
{
binaryTreeNode<pair<const K,E> *p=rootNode,*pp=NULL;
while(p!=NULL)
{
pp=p;
if(thePair.first<p->element.first)
p=p->leftChild;
else if(thePair.first>p->element.first)
p=p->rightChild;
else
{
p->element.second=thePair.second;
return;
}
}
binaryTreeNode<pair<const K,E> *newNode =new binaryTreeNode<pair<const K,E>>(thePair);
if(rootNode==NULL)
{
rootNode=newNode;
rootNode->leftChild=rootNode->rightChild=NULL;
}
else
{
if(pp->element.first<thePair.first)
pp->rightChild=newNode;
else
pp->leftChild=newNode;
}
stSize++;
} 删除:假设要删除接节点p,我们要考虑三种情况①p是叶子;②p只有一颗非空子树;③p有两颗非空子树
- 第一种情况非常好做,只有释放叶子节点的空间即可,若是根节点,置为NULL
- 第二种情况也较为简单 ,如果p是根节点,则p的唯一子树的根节点成为新的搜索树的根节点。若p有父节点pp,则修改pp的指针域,使它指向p的唯一孩子,然后释放节点p
- 第三种情况较复杂,我们先将该节点的元素替换为它左子树的最大元素(或者右子树的最小的一个元素)。然后把替换的节点删除,该删除的结点如果有左子树,则该左子树变为该结点的双亲的右子树(或者删除的结点如果有右子树,则该右子树变为该结点的双亲的左子树)
template<class K,class E>
void binarySearchTree<K,E>::erase(const K& theKey)
{
binaryTreeNode<pair<const K,E>>* p=rootNode,*pp=NULL;
while(p!=NULL&&p.element.first!=theKey)
{ //定位关键值相等的节点
pp=p;
if(p->element.first>theKey)
p=p->leftChild;
else
p=p->rightChild;
}
if(p==NULL) //不存在
return;
if(p->leftChild!=NULL&&p->rightChild!=NULL) //第三种情况
{
binaryTreeNode<pair<const K,E>>* theMaxNode=p->leftNode,*s=p;
while(theMaxNode->rightChild!=NULL) //寻找左子树最大值进行替换
{
s=theMaxNode;
theMaxNode=theMaxNode->rightChild;
}
//p->element=theMaxNode->element; 无法这样移动,因为key是常量
binaryTreeNode<pair<const K,E>>* q=new binaryTreeNode<pair<const K,E>>
(theMaxNode->element,p->leftChild,p->rightChild); //这样移动合法
if(pp==NULL) //即删除的是根节点的情况
rootNode=q;
else if(p==pp->leftNode) //不是根节点,判断p是pp的左树还是右树
pp->leftChild=q;
else
pp->rightChild=q;
if(s==p) q->leftChild=theMaxNode->leftChild;
delete p;
p=s //为简化下面判断if(p->leftChild!=NULL)语句
}
binaryTreeNode<pair<const K,E>>*c;
if(p->leftChild!=NULL)
c=p->leftChild;
else
c=p->rightChild;
//删除p
if(p==rootNode)
rootNode=c;
else
{
if(p==pp->leftChild)
pp->leftChild=c;
else
pp->rightChild=c;
}
stSize--;
delete p;
} 索引二叉搜索树
它源于普通的二叉搜索树,只是在每个节点中添加一个leftSize域,这个域的值是该节点左子树的元素个数
平衡搜索树
两种平衡二叉树结构:AVL和红-黑树;一个树结构:B-树。
AVL和红-黑树适合内部存储的应用,B-树适合外部存储的应用。这些平衡树结构可以在最坏情况下用时O(logn)实现字典操作和按名次的操作。STL类的map、multimap使用的是红-黑树结构,以保证查找的时间复杂度在O(logN)
AVL平衡二叉树
平常的的二分查找树可能会退化成O(N)的时间复杂度,为保证O(logN)的时间复杂度引入了AVL树
如果搜索树的高度总是O(logn),我们能保证查找、插入、删除的时间为O(logn)。最坏情况下的高度为O(logn)的树为平衡树(balanced tree)
定义:一颗空的二叉树是AVL树;如果T是一颗非空的二叉树,T1和T2分别是其左子树和右子数,那么当T满足以下条件时,T是一颗AVL树:①T1和T2是AVL树;②|hl-hr|≤1,其中hl和hr分别是Tl和TR的高。
template <class T>
class AVLTreeNode{
public:
T key; // 关键字(键值)
int height; // 高度
AVLTreeNode *left; // 左孩子
AVLTreeNode *right; // 右孩子
AVLTreeNode(T value, AVLTreeNode *l, AVLTreeNode *r):
key(value), height(0),left(l),right(r) {}
}; 一颗AVL搜索树既是二叉搜索树,也是AVL树。如果用AVL搜索树来描述字典,并在对数级时间内完成每一种字典操作,那么,我们必须确定AVL树的下列特征:
- 一颗n个元素的AVL树,其高度是O(logn)
- 对于每一个n≥0,都存在一颗AVL树
- 对一颗n元素的AVL搜索树,在O(高度)=O(logn)的时间内可以实现查找
- 将一个新元素插入一颗n元素AVL搜索树种,可以得到一颗n+1元素的AVL树,且插入用时为O(logn)
- 一个元素从一颗n元素的AVL搜索树删除,可以得到一颗n-1的AVL搜索树,而且用时为O(logn)
注:AVL树的最主要特征是节点存储有平衡因子bf,平衡因子的绝对值必须满足小于等于1,在插入删除时都涉及到平衡操作
template <class T>
class AVLTree {
private:
AVLTreeNode<T> *mRoot; // 根结点
public:
AVLTree();
~AVLTree();
// 获取树的高度
int height();
// 获取树的高度
int max(int a, int b);
// 前序遍历"AVL树"
void preOrder();
// 中序遍历"AVL树"
void inOrder();
// 后序遍历"AVL树"
void postOrder();
// (递归实现)查找"AVL树"中键值为key的节点
AVLTreeNode<T>* search(T key);
// (非递归实现)查找"AVL树"中键值为key的节点
AVLTreeNode<T>* iterativeSearch(T key);
// 查找最小结点:返回最小结点的键值。
T minimum();
// 查找最大结点:返回最大结点的键值。
T maximum();
// 将结点(key为节点键值)插入到AVL树中
void insert(T key);
// 删除结点(key为节点键值)
void remove(T key);
// 销毁AVL树
void destroy();
// 打印AVL树
void print();
private:
// 获取树的高度
int height(AVLTreeNode<T>* tree) ;
// 前序遍历"AVL树"
void preOrder(AVLTreeNode<T>* tree) const;
// 中序遍历"AVL树"
void inOrder(AVLTreeNode<T>* tree) const;
// 后序遍历"AVL树"
void postOrder(AVLTreeNode<T>* tree) const;
// (递归实现)查找"AVL树x"中键值为key的节点
AVLTreeNode<T>* search(AVLTreeNode<T>* x, T key) const;
// (非递归实现)查找"AVL树x"中键值为key的节点
AVLTreeNode<T>* iterativeSearch(AVLTreeNode<T>* x, T key) const;
// 查找最小结点:返回tree为根结点的AVL树的最小结点。
AVLTreeNode<T>* minimum(AVLTreeNode<T>* tree);
// 查找最大结点:返回tree为根结点的AVL树的最大结点。
AVLTreeNode<T>* maximum(AVLTreeNode<T>* tree);
// LL:左左对应的情况(左单旋转)。
AVLTreeNode<T>* leftLeftRotation(AVLTreeNode<T>* k2);
// RR:右右对应的情况(右单旋转)。
AVLTreeNode<T>* rightRightRotation(AVLTreeNode<T>* k1);
// LR:左右对应的情况(左双旋转)。
AVLTreeNode<T>* leftRightRotation(AVLTreeNode<T>* k3);
// RL:右左对应的情况(右双旋转)。
AVLTreeNode<T>* rightLeftRotation(AVLTreeNode<T>* k1);
// 将结点(z)插入到AVL树(tree)中
AVLTreeNode<T>* insert(AVLTreeNode<T>* &tree, T key);
// 删除AVL树(tree)中的结点(z),并返回被删除的结点
AVLTreeNode<T>* remove(AVLTreeNode<T>* &tree, AVLTreeNode<T>* z);
// 销毁AVL树
void destroy(AVLTreeNode<T>* &tree);
// 打印AVL树
void print(AVLTreeNode<T>* tree, T key, int direction);
}; 插入
如果按二叉搜索树的插入算***影响AVL树将不在是AVL树。如下图将32插入VAL搜索树:此时破环了AVL搜索树的平衡,因为平衡因子不在是-1,1,0,而是有2
/*
* 将结点插入到AVL树中,并返回根节点
*
* 参数说明:
* tree AVL树的根结点
* key 插入的结点的键值
* 返回值:
* 根节点
*/
template <class T>
AVLTreeNode<T>* AVLTree<T>::insert(AVLTreeNode<T>* &tree, T key)
{
if (tree == NULL)
{
// 新建节点
tree = new AVLTreeNode<T>(key, NULL, NULL);
if (tree==NULL)
{
cout << "ERROR: create avltree node failed!" << endl;
return NULL;
}
}
else if (key < tree->key) // 应该将key插入到"tree的左子树"的情况
{
tree->left = insert(tree->left, key);
// 插入节点后,若AVL树失去平衡,则进行相应的调节。
if (height(tree->left) - height(tree->right) == 2)
{
if (key < tree->left->key)
tree = leftLeftRotation(tree);
else
tree = leftRightRotation(tree);
}
}
else if (key > tree->key) // 应该将key插入到"tree的右子树"的情况
{
tree->right = insert(tree->right, key);
// 插入节点后,若AVL树失去平衡,则进行相应的调节。
if (height(tree->right) - height(tree->left) == 2)
{
if (key > tree->right->key)
tree = rightRightRotation(tree);
else
tree = rightLeftRotation(tree);
}
}
else //key == tree->key)
{
cout << "添加失败:不允许添加相同的节点!" << endl;
}
tree->height = max( height(tree->left), height(tree->right)) + 1;
return tree;
}
template <class T>
void AVLTree<T>::insert(T key)
{
insert(mRoot, key);
} 由平衡变为不平衡情况只有两种:
- -1变为-2,即右子树插入
- 1变为2,左子树插入
也就是只有插入前的树是弱平衡的(-1和1),插入后才会使树不平衡。下面是两条重要规律:
- 只有从根到新插入节点的路径上的节点,其平衡因子在插入后会改变
- 假设A是离新插入节点最近的祖先,且A满足平衡因子为-2或2(上图A为40),在插入前,从A到新插入节点的路径上,所有节点平衡因子都是0,因此可通过A点是否存在来判断是否需要旋转。

为使插入后维护平衡,使用旋转的思想维护AVL树的平衡,从情况不同可划分为LL型(右旋)、LR型(左旋再右旋)、RR(左旋)型和RL(右旋再左旋)型四种。RR和LL称为单旋转,RL和LR为双旋转。
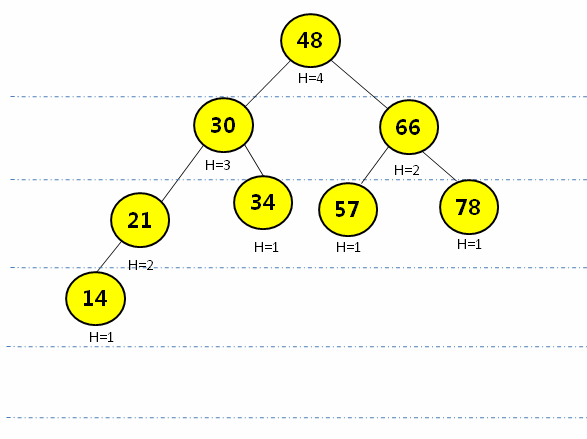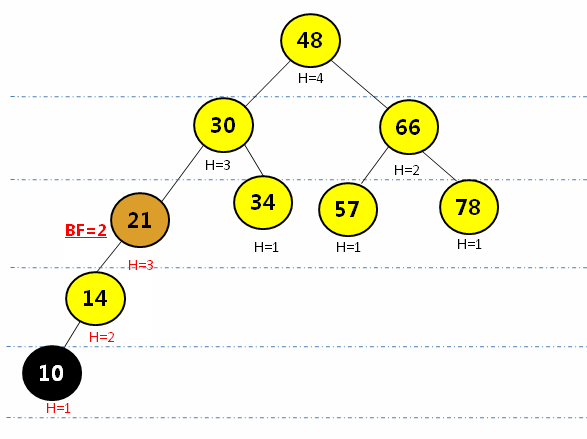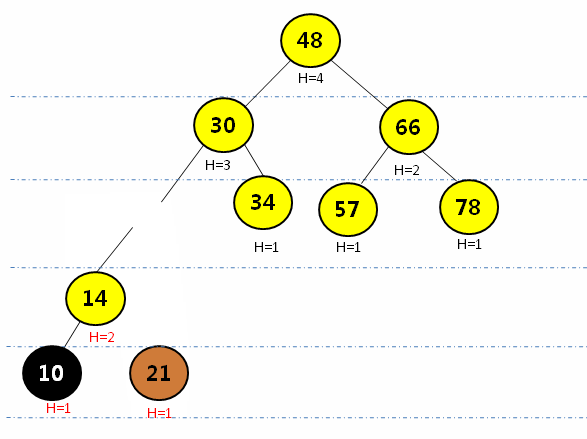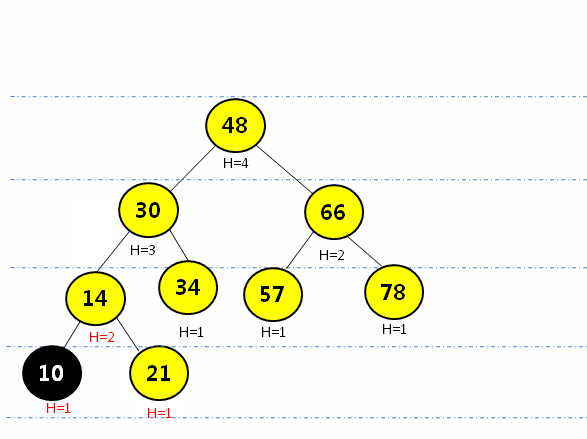
LL型(右旋):在最小平衡子树根节点平衡因子>=2且在根节点的左孩子的左孩子插入元素,进行右旋
/*
* LL:左左对应的情况(左单旋转)。
*
* 返回值:旋转后的根节点
*/
template <class T>
AVLTreeNode<T>* AVLTree<T>::leftLeftRotation(AVLTreeNode<T>* k2)
{
AVLTreeNode<T>* k1;
k1 = k2->left;
k2->left = k1->right;
k1->right = k2;
k2->height = max( height(k2->left), height(k2->right)) + 1;
k1->height = max( height(k1->left), k2->height) + 1;
return k1;
} RR型(左旋):在最小平衡子树根节点平衡因子>=-2且在根节点的右孩子的右孩子插入元素,进行左旋。

/*
* RR:右右对应的情况(右单旋转)。
*
* 返回值:旋转后的根节点
*/
template <class T>
AVLTreeNode<T>* AVLTree<T>::rightRightRotation(AVLTreeNode<T>* k1)
{
AVLTreeNode<T>* k2;
k2 = k1->right;
k1->right = k2->left;
k2->left = k1;
k1->height = max( height(k1->left), height(k1->right)) + 1;
k2->height = max( height(k2->right), k1->height) + 1;
return k2;
} LR型(左旋后右旋):在最小平衡子树根节点(21)的左孩子(14)的节点插入新元素(18),先绕根节点的左孩子节点(14)左旋,再围根节点(21)右旋
/*
* LR:左右对应的情况(左双旋转)。
*
* 返回值:旋转后的根节点
*/
template <class T>
AVLTreeNode<T>* AVLTree<T>::leftRightRotation(AVLTreeNode<T>* k3)
{
k3->left = rightRightRotation(k3->left);
return leftLeftRotation(k3);
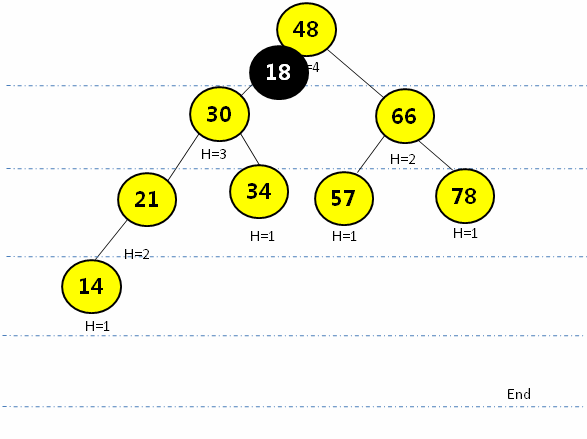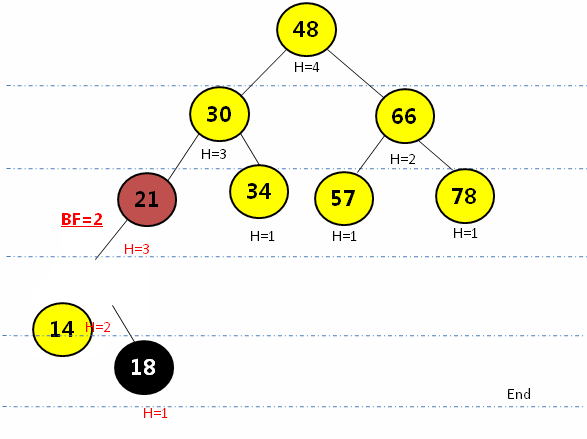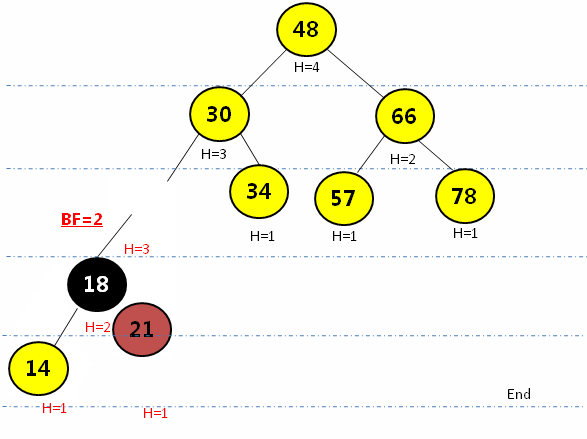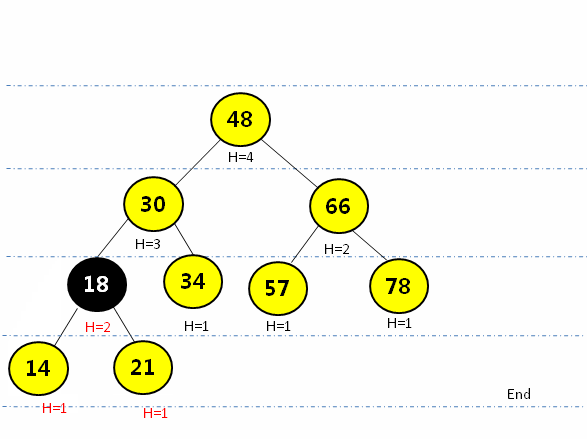
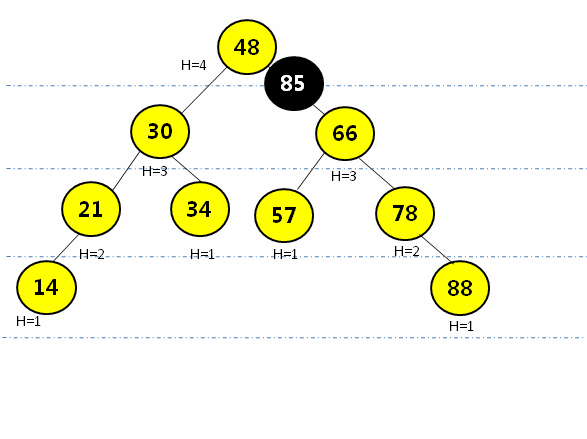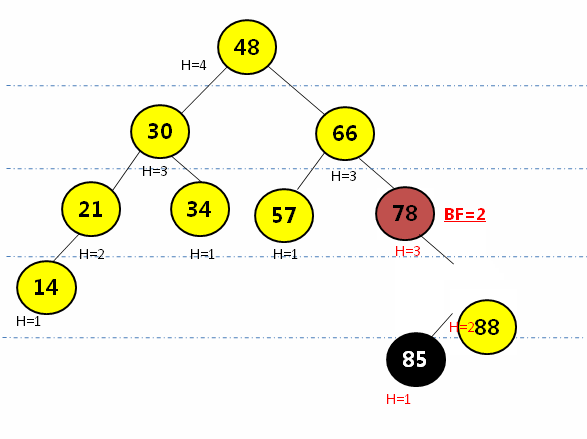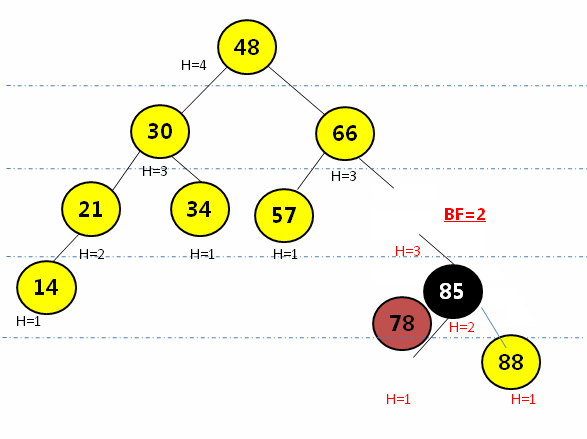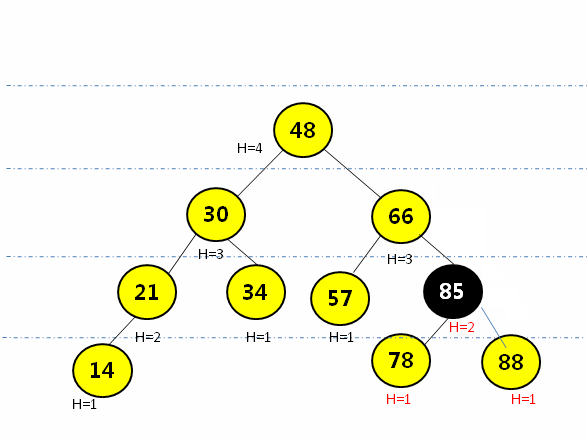
} RL型(右旋后左旋):在最小平衡子树根节点(78)的右孩子(88)的节点插入新元素(85),先绕根节点的右孩子节点(88)右旋,再围根节点(78)左旋
/*
* RL:右左对应的情况(右双旋转)。
*
* 返回值:旋转后的根节点
*/
template <class T>
AVLTreeNode<T>* AVLTree<T>::rightLeftRotation(AVLTreeNode<T>* k1)
{
k1->right = leftLeftRotation(k1->right);
return rightRightRotation(k1);
} 代码来自于[skywang12345]大佬,需要完整代码请来这里:大佬入口
删除
首先查找要删除的节点,找到以后,要删除的节点分为两种情况:
要删除的节点左右两个孩子都存在。则在右子树中查找最小的节点,将其值替换为要删除的节点的值,因为右子树的最小节点必然没有左孩子,即只有一个孩子.然后问题转化为删除这个右子树中最小的节点。(或者也可以将问题转化为删除左子树里最大的节点)。
要删除的孩子节点只有一个孩子节点,则直接将仅有的一个孩子节点提上来即可.
删除以后将进行从删除节点向上进行平衡性的检查:(在查找要删除的节点的过程中,将经过的路径上的节点位置全部存放到一个stack)
如下情况:
取出栈顶元素pr并弹出栈顶元素,如果删除的节点X的key值比该节点pr的key值小,则必定是左树删除,则pr->bf要减1,否则pr->bf要+1。
如果删除后pr->bf的绝对值是为-1和+1(则删除前为0,左右平衡),删除了以后只是其左子树或者右子树少了一个节点,但pr这个树的高度并没发生变化.对与pr的上面的所有节点而言树高并没有发生变化,所以调整完成,直接退出.
如果平衡因子变为0:则在删除之前平衡因子是+1或者-1,现在删除节点以后变为0,则pr这棵树树的高度减1(发生了变化,影响到了上面的祖先节点),则要向上(出栈)继续检查,所以情况重新回到上面出栈去检查..
如果删除前平衡因子的绝对值是2:则平衡打破,进行旋转平衡调整:
红黑树
树中的每一个结点的颜色或者是黑色或者是红色。其它的特征可由扩展二叉树说明:在一棵规则的二叉树中,每一个空指针NULL用一个黑色外部结点来替代。其它性质还有:
- RB1:根结点和所以外部结点都是黑色
- RB2:在根至外部结点路径上,没有连续两个结点是红色的
- RB3:在所有(根至外部结点的路径上),黑色结点数目相同
红黑树是一种弱平衡二叉树,相对于要求严格的AVL树来说,它的平衡操作旋转次数少。即AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
所以红黑树在查找,插入删除的性能都是O(logn),且性能稳定,所以STL里面很多结构包括map、multi_map、set底层实现都是使用的红黑树。
插入失衡情况
由以上的三个规则性质知,把新节点赋为黑色肯定不符合RB3,而把新节点赋为红色虽然一定符合RB3,但可能违反了RB2。
如果是新节点赋为红色而造成RB2规则被破坏,我们就说树的平衡杯破坏了。此时平衡破坏则必有有两连续红色节点:一个是新节点u,一个是其父结点pu。而此时u得祖父节点gu一定是黑色的:
- 当pu是gu的左孩子,u是pu的左孩子时且gu的另一个孩子(右孩子)是黑色的(可为外部节点),该不平衡类型为LLb类型。
- 当pu是gu的左孩子,u是pu的左孩子时且gu的另一个孩子(右孩子)是红色的(不是外部节点),该不平衡类型为LLr类型。
- 依次类推出LRb、LRr、RRb、RRr、RLb、RLr
平衡方法:两种类型XYr和XYb
- XYr型的不平衡可以通过改变颜色来处理:将pu节点变为黑色,pu和gu的右孩子都为黑色,另外如果gu不是根则改为红色,如果时根节点则保持gu为黑色不变;因为gu由黑变红的情况可能导致上一层平衡破坏,如果破坏了(即原gu与gu父结点都为红),分析是XYr类型还是XYb类型,继续恢复平衡操作。

- XYb型则需要旋转。插入后依次旋转足以保持平衡。该旋转的改变同AVL相似

删除失衡情况
对于删除操作,首先使用二叉搜索树的删除算法。然后进行颜色变动,需要的话还要进行一次旋转。删除红色节点,不会影响规则,只需将相应的需要变色的指针变色即可。删除黑色节点,会影响RB3(不是根节点时)。使用该删除算法,不会违反除RB3外的其它红黑树规则。

