《强化学习》 DP动态规划
奖赏设计
累计奖赏和折扣累计奖赏
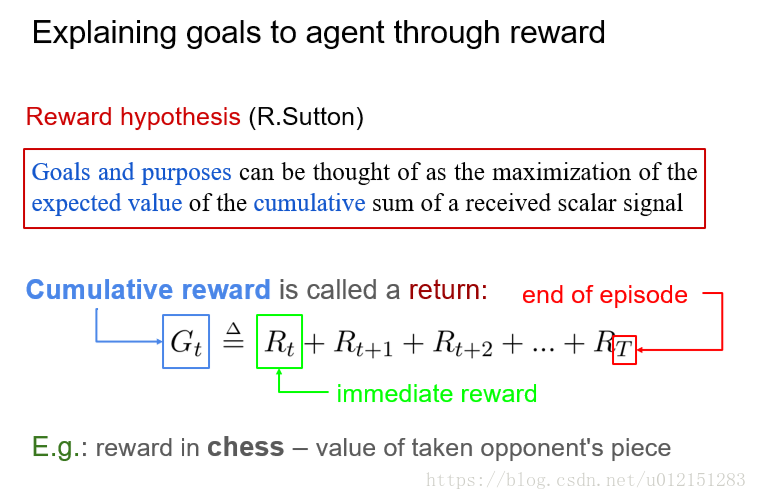

数学上看,折扣奖赏机制可以将累计回报转化为递推的形式:
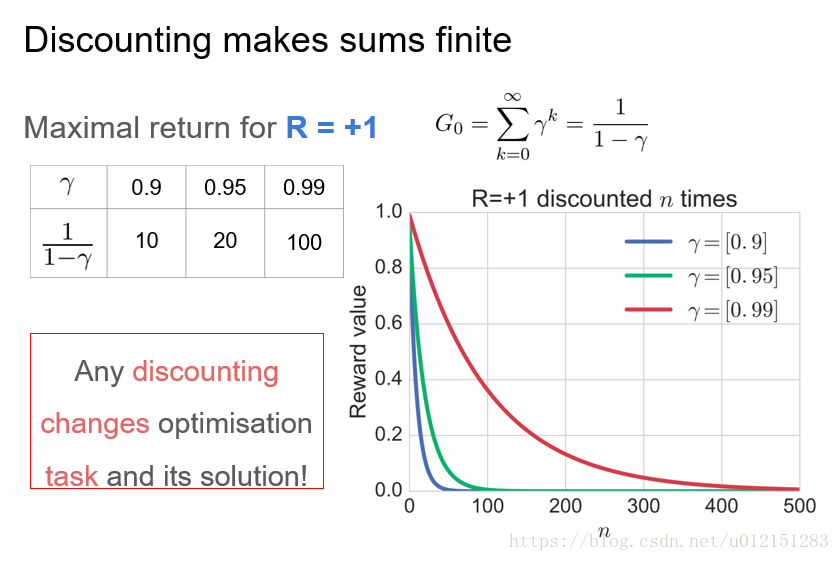
折扣是一种固定效应模型

奖赏设计:不要平移,奖励做什么而不是怎么做
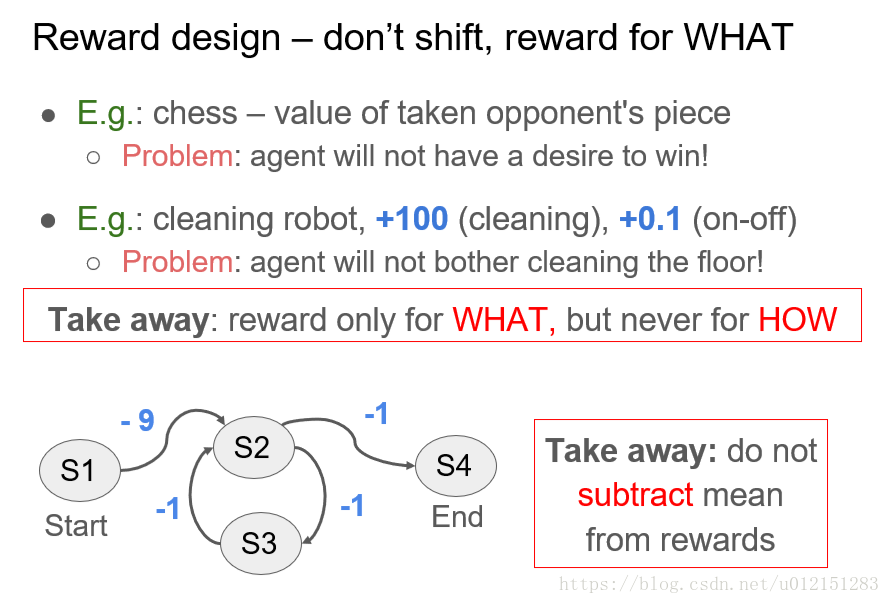
奖赏设计:缩放,塑形

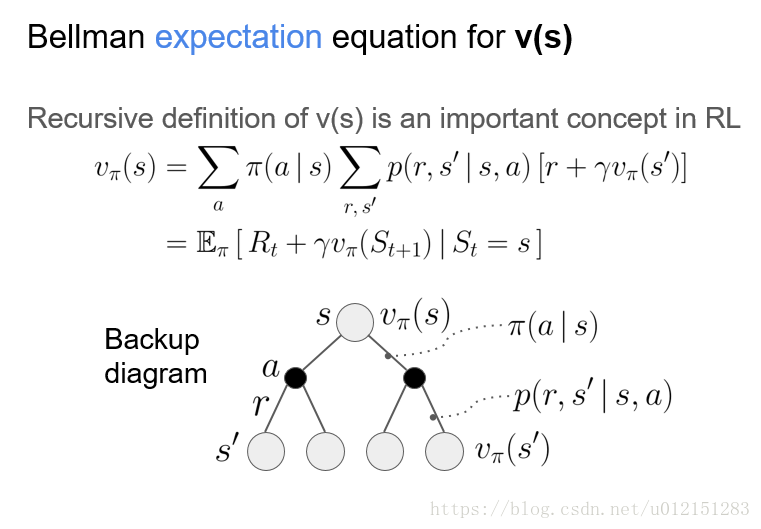
贝尔曼等式
状态值函数

值函数的贝尔曼期望等式
动作值函数

两者关系

动作值函数的贝尔曼期望等式

衡量策略优劣

贝尔曼最优等式

广义策略迭代GPI
策略评估


策略改进



GPI


数学上看,折扣奖赏机制可以将累计回报转化为递推的形式:
相关推荐




 查看24道真题和解析
查看24道真题和解析