
Alias:时间复杂度O(1)的离散采样方法
本文首发于知乎专栏,欢迎关注~ https://zhuanlan.zhihu.com/p/54867139
最近在看graph embedding的一些东西,发现像deepwalk,node2vec在采样节点路径以及line中采样边的时候都用到了Alias方法。这里简单总结一下
问题定义
给定一个离散型随机变量的概率分布规律 P(X=i)=pi, i∈1,...N,希望设计一个方法能够从该概率分布中进行采样使得采样结果尽可能服从概率分布 P
O(N)的方法
想象随机事件依其概率的大小分布在一个长度为1的线段上。那么我在线段中随机取一点,看看该点落在哪个事件对应的区间中,就取该区间对应的事件即可。
具体实现如下:
- 生成01均匀分布 r∼Unif(0,1)
- 查找下标k使得 ∑j=1k−1pj≤r<∑j=1kpj
- 返回
k
显然线构造一个存储累积事件概率的数组时间复杂度为 O(N),每次进行线性查找的时间复杂度为 O(N)
O(logN)的方法
上面在通过累加的方式构造出累积事件概率数组后,我们可以发现该数组满足非递减有序,对于有序数组的查找很容易想到使用二分查找进行优化,使用二分查找后的时间复杂度为 O(logN)
O(1)的方法
现在介绍使用空间换时间优化的方法Alias。
Alias方法整个概率分布转化为一个1*N的矩形,对于每个事件i,转换为对应矩形中的面积为 ∑k=1k=Npkpi∗N。
通过上述操作,一般会有某些位置面积大于1某些位置的面积小于1。我们通过将面积大于1的事件多出的面积补充到面积小于1对应的事件中,以确保每一个小方格的面积为1,同时,保证每一方格至多存储两个事件。
维护两个数组accept和alias,accept数组中的accept[i]表示事件i占第i列矩形的面积的比例。
alias[i]表示第i列中不是事件i的另一个事件的编号。
在进行采样的时候,每次生成一个随机数 i∈[0,N),再生成一个随机数 r∼Unif(0,1),若 r<accept[i],则表示接受事件i,否则,拒绝事件 i返回alias[i]
该算法对应的代码如下,可以看到预处理alias table的时间复杂度仍为 O(N),而每次采样产生时间的时间复杂度为 O(1)。
采样结果可视化
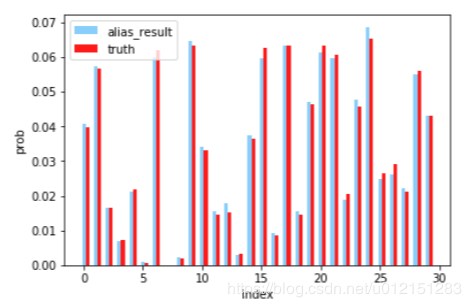
Python代码
import numpy as np
def gen_prob_dist(N):
p = np.random.randint(0,100,N)
return p/np.sum(p)
def create_alias_table(area_ratio):
l = len(area_ratio)
accept, alias = [0] * l, [0] * l
small, large = [], []
for i, prob in enumerate(area_ratio):
if prob < 1.0:
small.append(i)
else:
large.append(i)
while small and large:
small_idx, large_idx = small.pop(), large.pop()
accept[small_idx] = area_ratio[small_idx]
alias[small_idx] = large_idx
area_ratio[large_idx] = area_ratio[large_idx] - (1 - area_ratio[small_idx])
if area_ratio[large_idx] < 1.0:
small.append(large_idx)
else:
large.append(large_idx)
while large:
large_idx = large.pop()
accept[large_idx] = 1
while small:
small_idx = small.pop()
accept[small_idx] = 1
return accept,alias
def alias_sample(accept, alias):
N = len(accept)
i = int(np.random.random()*N)
r = np.random.random()
if r < accept[i]:
return i
else:
return alias[i]
def simulate(N=100,k=10000,):
truth = gen_prob_dist(N)
area_ratio = truth*N
accept,alias = create_alias_table(area_ratio)
ans = np.zeros(N)
for _ in range(k):
i = alias_sample(accept,alias)
ans[i] += 1
return ans/np.sum(ans),truth
if __name__ == "__main__":
alias_result,truth = simulate()
参考资料
[1] Li A Q, Ahmed A, Ravi S, et al. Reducing the sampling complexity of topic models[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 891-900.
[2] 【数学】时间复杂度O(1)的离散采样算法—— Alias method/别名采样方法


