
【Graph Embedding】SDNE:算法原理,实现和应用
本文首发于知乎专栏 https://zhuanlan.zhihu.com/p/56637181 ,欢迎关注~
SDNE(Structural Deep Network Embedding Daixin)是和node2vec并列的工作,均发表在2016年的KDD会议中。可以看作是基于LINE的扩展,同时也是第一个将深度学习应用于网络表示学习中的方法。
不清楚LINE的同学可以参考
SDNE使用一个自动编码器结构来同时优化1阶和2阶相似度(LINE是分别优化的),学习得到的向量表示能够保留局部和全局结构,并且对稀疏网络具有鲁棒性。
SDNE 算法原理
相似度定义
SDNE中的相似度定义和LINE是一样的。简单来说,1阶相似度衡量的是相邻的两个顶点对之间相似性。2阶相似度衡量的是,两个顶点他们的邻居集合的相似程度。
2阶相似度优化目标
L2nd=∑i=1n∣∣x^i−xi∣∣22
这里我们使用图的邻接矩阵进行输入,对于第i个顶点,有 xi=si,每一个 si都包含了顶点i的邻居结构信息,所以这样的重构过程能够使得结构相似的顶点具有相似的embedding表示向量。
这里存在的一个问题是由于图的稀疏性,邻接矩阵S中的非零元素是远远少于零元素的,那么对于神经网络来说只要全部输出0也能取得一个不错的效果,这不是我们想要的。
文章给出的一个方法是使用带权损失函数,对于非零元素具有更高的惩罚系数。
修正后的损失函数为
L2nd=∑i=1n∣∣(x^i−xi)⊙bi∣∣22=∣∣(X^−X)⊙B∣∣F2
其中 ⊙为逐元素积, bi={bi,j}j=1n,若 si,j=0,则 bi,j=1,否则 bi,j=β>1
1阶相似度优化目标
对于1阶相似度,损失函数定义如下
L1st=∑i,j=1nsi,j∣∣yi(K)−yj(K)∣∣22=∑i,j=1nsi,j∣∣yi−yj∣∣22
该损失函数可以让图中的相邻的两个顶点对应的embedding vector在隐藏空间接近。
L1st还可以表示为
L1st=∑i,j=1n∣∣yi−yj∣∣22=2tr(YTLY)
其中L是图对应的拉普拉斯矩阵, L=D−S,D是图中顶点的度矩阵,S是邻接矩阵。
Di,i=∑jsi,j
整体优化目标
联合优化的损失函数为
Lmix=L2nd+αL1st+νLreg,
Lreg是正则化项, α为控制1阶损失的参数, ν为控制正则化项的参数。
模型结构
先看左边,是一个自动编码器的结构,输入输出分别是邻接矩阵和重构后的邻接矩阵。通过优化重构损失可以保留顶点的全局结构特性(论文的图画错了,上面应该是Global structure preserved cost)。

再看中间一排, yi(K)就是我们需要的embedding向量,模型通过1阶损失函数使得邻接的顶点对应的embedding向量接近,从而保留顶点的局部结构特性(中间应该是 Local structure preserved cost)
实现
文章提出使用深度信念网络进行预训练来获得较好的参数初始化,这里我就偷个懒省略这个步骤了~
损失函数定义
l_2nd是2阶相似度对应的损失函数,参数beta控制着非零元素的惩罚项系数。y_true和y_pred分别是输入的邻接矩阵和网络重构出的邻接矩阵。
l_1st是1阶相似度对应的损失函数,参数alpha控制着其在整体损失函数中的占比。
def l_2nd(beta):
def loss_2nd(y_true, y_pred):
b_ = np.ones_like(y_true)
b_[y_true != 0] = beta
x = K.square((y_true - y_pred) * b_)
t = K.sum(x, axis=-1, )
return K.mean(t)
return loss_2nd
def l_1st(alpha):
def loss_1st(y_true, y_pred):
L = y_true
Y = y_pred
batch_size = tf.to_float(K.shape(L)[0])
return alpha * 2 * tf.linalg.trace(tf.matmul(tf.matmul(Y, L, transpose_a=True), Y)) / batch_size
return loss_1st
模型定义
create_model函数创建SDNE模型,l1和l2分别为模型的正则化项系数,模型的输入A为邻接矩阵,L为拉普拉斯矩阵。输出A_为重构后的邻接矩阵,Y为顶点的embedding向量。
函数中两个for循环分别对应encoder和decoder结构。
def create_model(node_size, hidden_size=[256, 128], l1=1e-5, l2=1e-4):
A = Input(shape=(node_size,))
L = Input(shape=(None,))
fc = A
for i in range(len(hidden_size)):
if i == len(hidden_size) - 1:
fc = Dense(hidden_size[i], activation='relu',kernel_regularizer=l1_l2(l1, l2),name='1st')(fc)
else:
fc = Dense(hidden_size[i], activation='relu',kernel_regularizer=l1_l2(l1, l2))(fc)
Y = fc
for i in reversed(range(len(hidden_size) - 1)):
fc = Dense(hidden_size[i], activation='relu',kernel_regularizer=l1_l2(l1, l2))(fc)
A_ = Dense(node_size, 'relu', name='2nd')(fc)
model = Model(inputs=[A, L], outputs=[A_, Y])
return model
应用
使用SDNE在wiki数据集上进行节点分类任务和可视化任务(感兴趣的同学可以试试别的数据集,我比较懒就选了个很小的数据集)。 wiki数据集包含 2,405 个网页和17,981条网页之间的链接关系,以及每个网页的所属类别。
本例中的训练,评测和可视化的完整代码在下面的git仓库中,
https://github.com/shenweichen/GraphEmbedding
分类任务
micro-F1: 0.6341
macro-F1: 0.4962
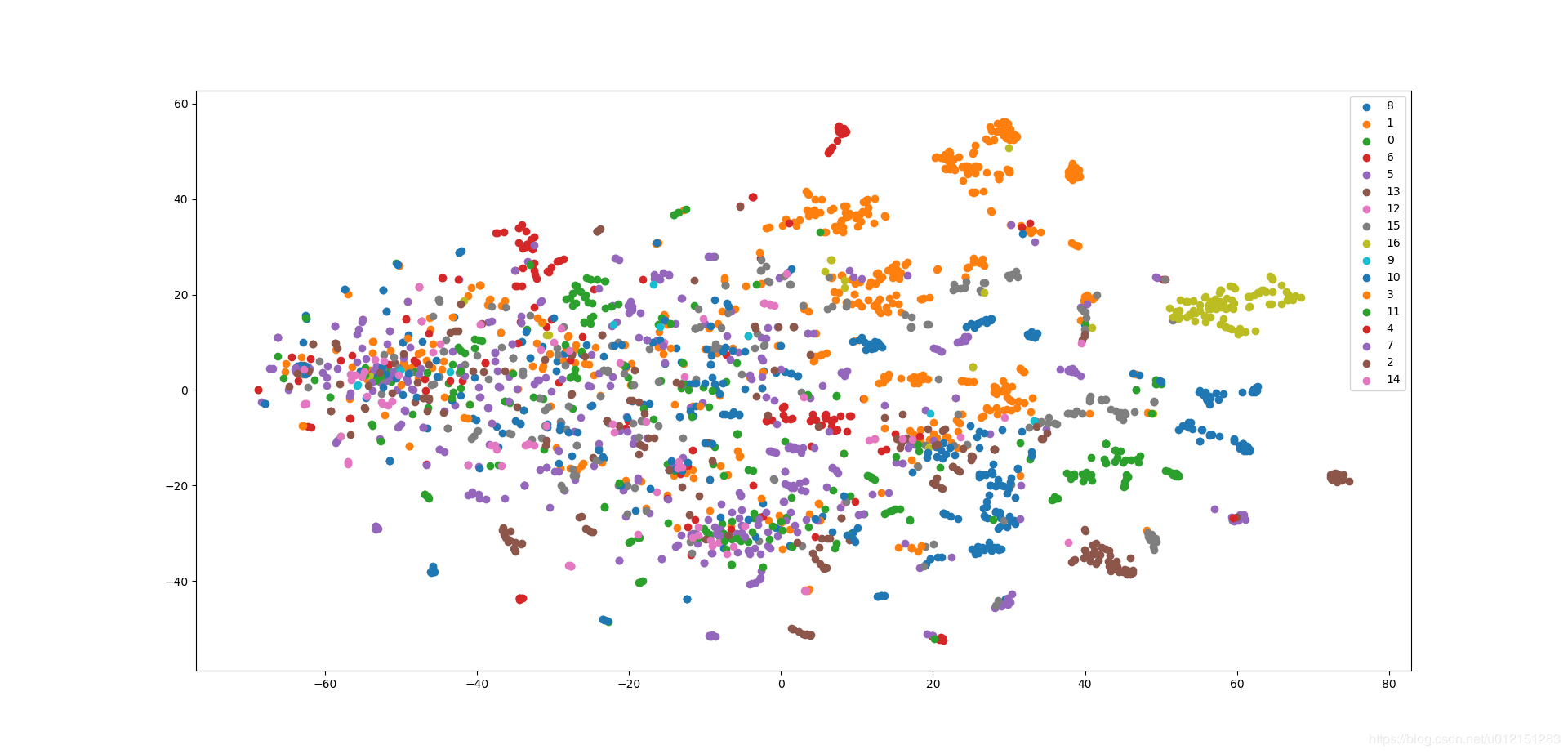
可视化
这个貌似某些类别的点的向量都聚集在一起了,可能和超参的设置还有网络权重的初始化有关,我懒得调了~
参考资料
想要了解更多关于GraphEmbedding算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!
. . . . . . .



