
场景题:假设有40亿QQ号,但只有1G内存,如何实现去重?
今天咱们来聊聊一道经典的面试题:假设有 40 亿个 QQ 号,但服务器只有 1G 内存,如何实现高效的去重操作?
一、常规方法为什么不行?
在日常开发中,我们经常会用到一些简单的去重方法,比如使用 HashSet 或 List.contains() 来判断重复。但如果数据量达到 40 亿,这些方法瞬间就会暴露出致命问题。
首先,我们来算一笔账。如果用 Java 的 int 类型存储 40 亿个 QQ 号,每个 int 占用 4 字节,那么总共需要的内存空间是:
40 亿 × 4 字节 = 160 亿字节 ≈ 14.9 GB
这已经远远超出了 1G 内存的限制。即使我们用更省空间的方式存储,比如直接用 byte,也至少需要 40 亿字节,也就是 3.7GB 左右,依然超出了 1G 的限制。更别提 HashSet 或 List 本身还会带来额外的内存开销。
其次,即使内存足够,常规方法的效率也低得可怜。对于 40 亿个数据,每次查询都需要遍历整个集合,时间复杂度是 O(n),这在实际场景中是完全不可接受的。
所以,面对这种海量数据去重的问题,必须另辟蹊径,寻找更高效、更节省内存的解决方案。
二、解决方案一:位数组(BitMap)
位数组是一种非常节省空间的数据结构,它的核心思想是用一个位(bit)来表示一个数据的存在与否。比如,用 1 表示某个 QQ 号存在,用 0 表示不存在。
1. 位数组的优势
位数组的最大优点是空间利用率极高。对于 40 亿个 QQ 号,我们只需要 40 亿个位(bit)。换算成字节就是:
40 亿 ÷ 8 = 5 亿字节 ≈ 0.465 GB
不到 1G 内存就能轻松搞定,简直是完美契合!
2. 位数组的实现
在 Java 中,我们可以直接使用 BitSet 来实现位数组。BitSet 是 Java 自带的一个类,位于 java.util 包中,操作起来非常方便。
举个简单的例子:
import java.util.BitSet;
public class BitmapExample {
public static void main(String[] args) {
BitSet bitmap = new BitSet();
// 假设 QQ 号从 0 开始
int qq = 123456789;
bitmap.set(qq); // 将该 QQ 号对应的位设置为 1
// 判断 QQ 号是否存在
boolean exists = bitmap.get(qq);
System.out.println("QQ 号 " + qq + " 是否存在:" + exists);
// 清除某个 QQ 号
bitmap.clear(qq);
exists = bitmap.get(qq);
System.out.println("清除后,QQ 号 " + qq + " 是否存在:" + exists);
}
}
在这个例子中,set() 方法用于标记某个 QQ 号存在,get() 方法用于判断是否存在,clear() 方法用于清除标记。整个过程简单高效,查询速度极快,时间复杂度仅为 O(1)。
三、解决方案二:布隆过滤器(Bloom Filter)
布隆过滤器是一种基于位数组的高效数据结构,但它比普通的位数组更强大,也更节省空间。它由布隆在 1970 年提出,主要用于判断一个元素是否存在于某个集合中。
1. 布隆过滤器的工作原理
布隆过滤器的核心是一个位数组和多个哈希函数。当我们插入一个元素时,会通过多个哈希函数将其映射到位数组的多个位置,并将这些位置的值设置为 1。查询时,同样通过哈希函数计算出这些位置,如果所有位置的值都是 1,则认为该元素“可能”存在;否则,一定不存在。
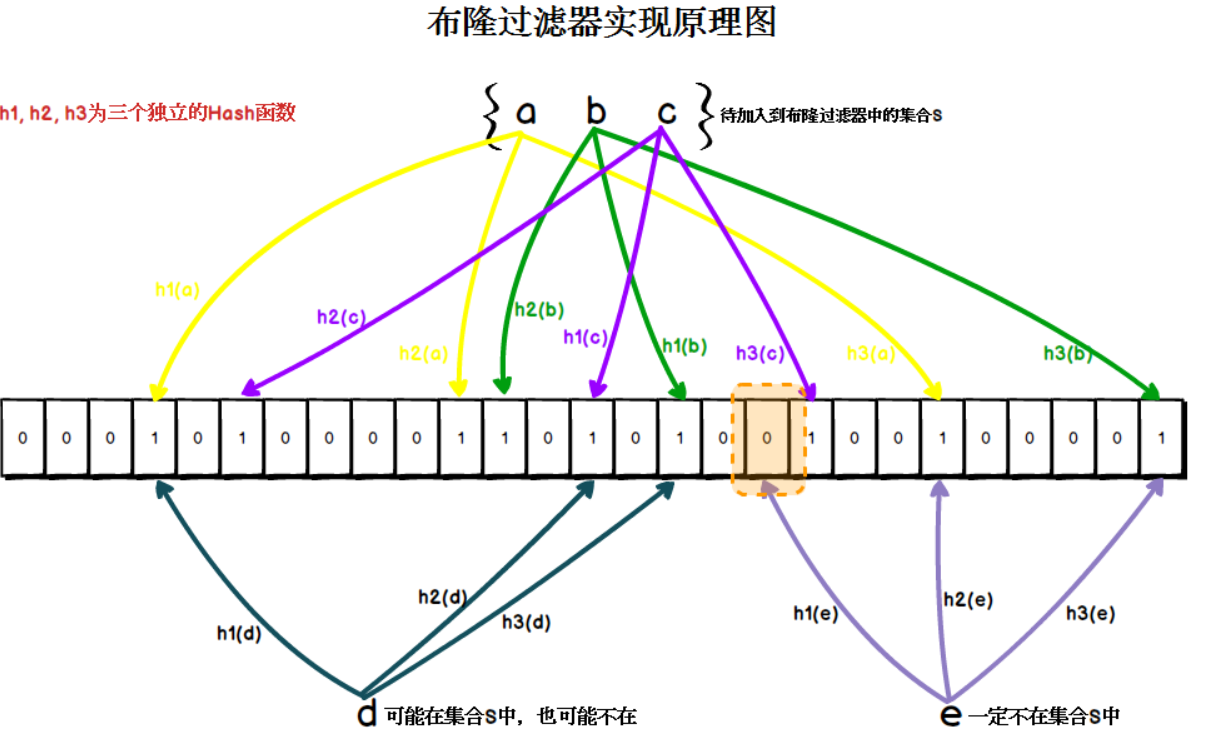
2. 布隆过滤器的优势
布隆过滤器的最大优势是空间利用率极高,同时查询速度极快。对于 40 亿个 QQ 号,布隆过滤器可能只需要几十 MB 的内存就能完成去重操作。而且,它的插入和查询操作的时间复杂度都是 O(1),效率极高。
不过,布隆过滤器也有一个缺点——存在一定的误判率(False Positive)。也就是说,它可能会误判某个元素存在,但实际上并不存在。但这种误判率可以通过调整哈希函数的数量和位数组的大小来控制。
3. 布隆过滤器的实现
在 Java 中,布隆过滤器的实现方式有多种。最常见的是使用 Google 的 Guava 库,它提供了非常方便的布隆过滤器实现。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
// 创建布隆过滤器,设置期望插入的数据量和误判率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 4000000000L, 0.01);
// 插入数据
bloomFilter.put("123456789");
bloomFilter.put("987654321");
// 查询数据是否存在
System.out.println("123456789 是否存在:" + bloomFilter.mightContain("123456789"));
System.out.println("999999999 是否存在:" + bloomFilter.mightContain("999999999"));
}
}
在这个例子中,我们创建了一个布隆过滤器,设置了期望插入的数据量为 40 亿,误判率为 1%。然后通过 put() 方法插入数据,通过 mightContain() 方法查询数据是否存在。
四、两种方案的对比
位数组和布隆过滤器都是高效的去重方案,但它们各有优缺点。
- 位数组:
空间利用率较高,查询速度快,且没有误判。但它的缺点是空间利用率仍有提升空间,对于更大的数据量,可能会占用更多内存。 - 布隆过滤器:
空间利用率极高,查询速度极快,适合处理海量数据。但它的缺点是存在误判率,虽然可以通过调整参数来降低误判率,但无法完全避免。
所以在实际使用中,我们需要根据具体场景来选择合适的方案。如果对精准度要求极高,且内存足够,可以使用位数组;如果对空间要求苛刻,且可以接受一定的误判率,那么布隆过滤器是更好的选择。
五、实际应用场景
这两种方案在实际开发中都非常有用。比如在大数据处理、搜索引擎、分布式系统等领域,我们经常会遇到海量数据去重的问题。通过使用位数组或布隆过滤器,我们可以高效地解决这些问题,大大提升系统的性能和效率。
举个实际的例子,假设我们在一个电商平台上需要判断某个用户是否已经购买过某个商品。如果用户量非常大,直接用数据库查询会非常低效。这时,我们可以用布隆过滤器来实现快速判断,虽然可能会有极小的概率误判,但可以通过后续的精确查询来弥补。
六、总结
今天,我们聊了聊如何在有限的内存(1G)内处理 40 亿个 QQ 号的去重问题。通过对比位数组和布隆过滤器两种方案,我们发现:
- 位数组:
适合对精准度要求高的场景,空间利用率较高,查询速度快,但仍有提升空间。 - 布隆过滤器:
适合对空间要求苛刻的场景,空间利用率极高,查询速度快,但存在误判率。
最后,如果你觉得这篇文章对你有帮助,别忘了点赞和分享哦!
#java# 查看12道真题和解析
查看12道真题和解析

