
面试八股文对校招的用处有多大?服务器篇
前言
1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
服务器
RPG
本文为第十一篇,后续会陆续更新。 共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接:https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i --
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
十一、服务器
01.用户认证和鉴权(jwt)
JWT认证
1.前后端token的认证流程:
前端发送登陆请求 – > 后端登陆接口接受 -->后端数据处理后返给前端token –> 前端将token存储后 -->每次请求都带着这个token去访问 —>后端设置jwtoken拦截器 -->只放行登陆接口 -->如果前端访问别的接口必须带有token –> 否则被拦截器拦截 并让前端回复到登陆页面
2、Token的处理方式:
JWT的token当服务端返回以后,是需要客户端进行主动地动作的,并不是像cookie一样,在后边的请求,都会自动带过去。这样就导致了如下几种做法:
将Jwt的token作为cookie返回给客户端。这样后续的请求都会带着这个token过来。这样在拦截的时候,就可以使用了。
将Jwt的token作为返回字符串,先返回给前端,前端再后续请求时,写到anthorization的request的head中,这个做法需要 编程去做,而且通用的做法,都是在ajax当中去做。构造请求。
将Jwt的token作为返回字符串,先返回给前端,前端再后续请求时,将Jwt的token写到token的request的head中,这个做法,也是编程实现,只不过具体做法,也是通过ajax进行。构造请求。只不过是自定义的head。
其实jwt的token也可以作为URL的参数进行传递的,这也是一个方法。
另外,jwt返回给前端的token,一般的做法都是放到localStorage当中,也就是前端浏览器的存储空间当中。可以将token存储在 localstorage里面,需要防止xss攻击
3、例子:
在登陆请求成功后把后端返回数据存储到浏览器
定义request.js 统一处理发送的请求为其加上token ,统一处理响应 若包含统一返回类code为 token未验证成功code 401 则让用户到登陆页面重新登陆
注意:客户端必须主动操作jwt返回的token,这个就不是自动的过程了。
2.JWT的使用建议 通常来说,一共由三种使用的方案:
JWT的方案 1、用户去认证中心登录,认证中心生成JWT,返回给客户端。
2、客户端带着jwt,请求其他的多个系统。
3、其他的系统,自己解析jwt,如果能解析,就说明登录成功,就可以继续业务。
通常,这个方案会将用户名等信息放到jwt当中,这样就不用认证中心校验了。
JWT + 认证中心 + redis 1、用户去认证中心登录,认证中心生产JWT,然后保存到reids中,然后再发给客户端
2、客户端带着jwt,去访问其他的多个系统。
3、其他收系统,取出jwt,传给认证中心。认证中心解析jwt,并将解析结果与redis的结果对比,然后将具体的用户信息返回给客户端。
JWT+认证中心+redis+各个系统redis 1、用户去认证中心登录,认证中心生产JWT,然后保存到reids中,然后再发给客户端
2、客户端带着jwt,去访问其他的多个系统。
3、多系统(比如系统A)收到jwt,A解析并取出用户信息,先判断自己的A的redis中有没有jwt。 3.1 如果有,就合法,a系统可以继续执行业务逻辑。 3.2 如果没有就拿着jwt去认证中心验证。 3.2.1 如果通过,a系统就把这个jwt保存到自己的redis,并设置对应的失效时间。 下次这个jwt再来到a的时候,就不需要去认证中心校验了。 3.2.2 如果验证不通过此次请求就不合法,告诉客户端需要跳转登录页面, 去认证中心登录,返回步骤1。
很多人都建议在使用token以后,就不用在后端存储用户信息了,其实理论上是可以的,但是JWT也是有安全问题的,所以一般是不建议这么用的。
建议做法:用户登录校验成功后会随机生成一个key,比如uuid,使用这个随机生成的key作为key,用户信息作为value,保存在Redis中,并设置失效时间。然后创建一个JWT TOKEN,使用随机生成的key作为jwt的有效载体,将生成好的JWT Token返给前端,前端保存在本地,当访问后端服务时,前端需要在请求头中携带 jwt token,后端通过拦截器对请求进行拦截,校验token是否有效,如果token有效,则在jwt token的有效载体中获取key,然后使用该key在redis中查找是否存在,如果存在说明登录验证通过,如果不存在说明验证登录信息已过期。
封装了一个JWT工具类提供创建JWT Token和解析JWT Token的方法,登录接口,根据用户提交的登录信息,校验通过后生成JWT Token,客户端保存token,以后访问服务时需要在请求头中携带token。Token校验接口,在拦截器中进行处理,应用程序访问服务时在拦截器校验Header中携带token的有效性,如果有效则返回请求的服务资源,如果无效则返回认证失败。
02.从url下图片10000张图片(写了想法,代码没写出来,http的api忘了),10台机器并行下载,怎么实现(主线程给子线程分配下载任务,从线程池取(给自己挖坑))。
实现思路:
- 首先需要一个存储所有图片 URL 的列表,可以存在数据库中或者文件中。
- 创建一个线程池来管理下载任务。线程池的大小为 10,每个线程在完成下载任务后返回结果给主线程。
- 主线程从存储图片 URL 的列表中读取 URL,并将其分配给空闲的子线程进行下载。如果当前没有空闲的子线程,则主线程等待直到有子线程可用。
- 子线程下载完一张图片后,将其保存到本地并返回下载结果给主线程,然后继续等待下一个任务。
- 当所有图片都被下载完成后,主线程结束程序。
代码实现:
python复制代码import threading
import requests
# 图片URL列表(假设已经从数据库或文件中读取)
image_urls = [
"http://example.com/image1.jpg",
"http://example.com/image2.jpg",
"http://example.com/image3.jpg",
...
]
# 线程池大小
MAX_THREADS = 10
class DownloadThread(threading.Thread):
def __init__(self, thread_id, task_queue):
threading.Thread.__init__(self)
self.thread_id = thread_id
self.task_queue = task_queue
def run(self):
while True:
# 从任务队列获取一个下载任务
try:
image_url = self.task_queue.get(block=False)
except queue.Empty:
break
# 下载图片并保存到本地
response = requests.get(image_url)
with open(f"{self.thread_id}_{image_url.split('/')[-1]}", "wb") as f:
f.write(response.content)
# 将下载结果返回给主线程
print(f"Thread {self.thread_id} downloaded image {image_url}")
self.task_queue.task_done()
# 创建任务队列并填充任务
task_queue = queue.Queue()
for url in image_urls:
task_queue.put(url)
# 创建线程池并启动子线程
threads = []
for i in range(MAX_THREADS):
thread = DownloadThread(i, task_queue)
thread.start()
threads.append(thread)
# 等待所有任务完成
task_queue.join()
# 所有图片下载完成,结束程序
print("All images downloaded successfully.")
以上是一个简单的多线程下载图片的实现示例,代码中使用了 Python 的 threading 和 queue 模块来实现线程和任务队列的管理。需要注意的是,在实际应用中还需要考虑网络连接超时、异常处理等问题。
03.雪花算法原理
snowflake是twitter的分布式环境生成全局唯一id的解决方案
1.snowflake id组成分析
1.1 snowflake-64bit
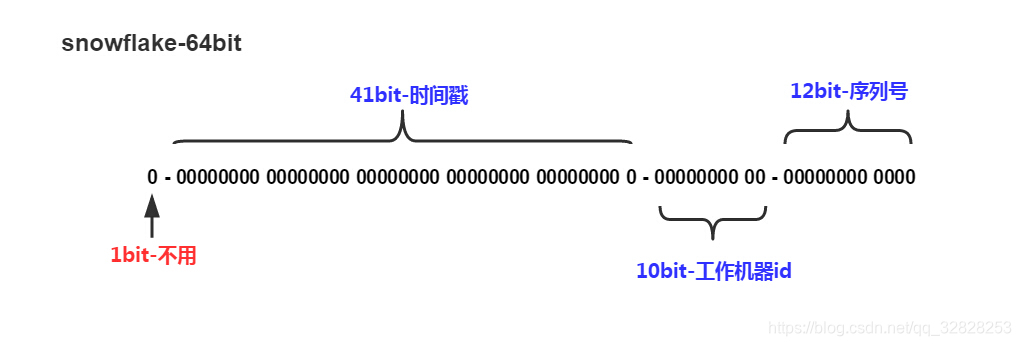 分别有三部分(其中第一位保留位,暂时没用):
分别有三部分(其中第一位保留位,暂时没用):
- 第一部分:时间戳(毫秒级),这里为41bit
- 第二部分:工作机器id,一般为==5bit数据中心id(datacenterId)+5bit机器id(workerId)==组成,10位的长度最多支持部署1024个节点
- 第三部分:在相同毫秒内,可以产生2^12 个id,12位的计数顺序号支持每个节点每毫秒产生4096个ID序列
1.2 snowflake-32bit
 大致与64bit相同,唯一区别是时间戳部分这里仅占用32bit,因为保存的时间戳为:当前时间戳-雪花算法开始的时间戳,得出来的数据仅用10bit就可以保存,位数越少,对磁盘、数据索引等数据提高越明显
大致与64bit相同,唯一区别是时间戳部分这里仅占用32bit,因为保存的时间戳为:当前时间戳-雪花算法开始的时间戳,得出来的数据仅用10bit就可以保存,位数越少,对磁盘、数据索引等数据提高越明显
2.优点
- 按照时间自增排序,在多个分布式系统内不会产生id碰撞(数据中心+机器id区分)
- 高性能:理论上QPS约为409.6w/s(1000*2^12)
- 不依赖于任何外部第三方系统
- 灵活性高:可以根据自身业务情况调整分配bit位
3.缺点
- 强依赖时钟:生成都是以时间自增,如果时间回拨,可能导致id重复
美团对此缺点做了一些改进,具体可以参考:Leaf——美团点评分布式ID生成系统
4.源码解析
/*** twitter的snowflake算法 -- java实现** @author beyond* @date 2016/11/26*/
public class SnowFlake {/*** 起始的时间戳 2016-11-26 21:21:05*/private final static long START_STAMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 12; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数private final static long DATA_CENTER_BIT = 5;//数据中心占用的位数/*** 每一部分的最大值*/private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;private long dataCenterId; //数据中心private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStamp = -1L;//上一次时间戳public SnowFlake(long dataCenterId, long machineId) {if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {throw new IllegalArgumentException("dataCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.dataCenterId = dataCenterId;this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {// 获得当前时间的毫秒数long currStamp = getNewStamp();if (currStamp < lastStamp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStamp == lastStamp) {// 相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE; // 为了保证取值范围最大为MAX_SEQUENCE// 同一毫秒的序列数已经达到最大if (sequence == 0L) { // 即:已经超出MAX_SEQUENCE 即:1000000000000currStamp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStamp = currStamp;return (currStamp - START_STAMP) << TIMESTAMP_LEFT // 时间戳部分| dataCenterId << DATA_CENTER_LEFT // 数据中心部分| machineId << MACHINE_LEFT // 机器标识部分| sequence; // 序列号部分}/*** 获得下一个毫秒数,比lastStamp大的下一个毫秒数** @return*/private long getNextMill() {long mill = getNewStamp();while (mill <= lastStamp) {mill = getNewStamp();}return mill;}/*** 获得当前毫秒数** @return*/private long getNewStamp() {return System.currentTimeMillis();}public static void main(String[] args) {SnowFlake snowFlake = new SnowFlake(3L, 10L);System.out.println("snowFlake.nextId() = " + snowFlake.nextId());}
}
其中有对三个部分都限制了最大值(MAX_DATA_CENTER_NUM、MAX_MACHINE_NUM、MAX_SEQUENCE),我们通过图解的方式来看下计算过程:

5.总结
其它还有利用数据库来生成分布式全局唯一ID方案,不过性能与稳定性都不如snowflake,针对snowflake比较成熟的解决方案可以参考 Leaf——美团点评分布式ID生成系统,此方案综合考虑到了高可用、容灾、分布式下时钟等问题。
04.分布式锁
1、锁的分类
1.1、线程锁
主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
1.2、进程锁
为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
1.3、分布式锁
当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
2、分布式锁应具备什么条件
互斥性:任意时刻,只能有一个客户端获取锁,不能同时有两个客户端获取到锁。 安全性:锁只能被持有该锁的客户端删除,不能由其它客户端删除。 死锁:获取锁的客户端因为某些原因(如down机等)而未能释放锁,其它客户端再也无法获取到该锁。 容错:当部分节点(redis节点等)down机时,客户端仍然能够获取锁和释放锁。
3、分布式锁的核心
加锁:要保证同一时间只有一个客户端可以拿到锁,得到锁之后开始执行相关业务。 解锁:在业务执行完毕后,须及时释放锁,以便其他线程可以进入。 锁超时:如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住(死锁),别的线程再也别想进来。所以需要设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放,避免死锁。
4、分布式锁的实现方式
4.1、基于数据库实现
4.1.1、基于数据库表实现
在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。 (1)创建如下数据表
DROP TABLE IF EXISTS `method_lock`;
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
`desc` varchar(255) NOT NULL COMMENT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
(2)执行方法
想要执行某个方法,就调用这个方法向数据表method_lock中插入数据:
INSERT INTO method_lock (method_name, desc)
VALUES ('methodName', '测试的methodName');
(3)锁释放
成功插入则表示获取到锁,插入失败则表示获取锁失败;插入成功后,就好继续方法体的内容,执行完成后删除对应的行数据释放锁:
delete from method_lock where method_name ='methodName';
(4)缺点
这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。 这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。 这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁。 (5)调优
因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换; 不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁; 没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据; 不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。 在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
4.1.2、基于数据库排他锁实现
利用我们的创建method_lock表,通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
"select * from methodLock where method_name= '" + methodName + "' for update"; //悲观锁
public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from methodLock where method_name=xxx for update;
if(result==null){
return true;
}
}catch(Exception e){
}
sleep(1000);
}
return false;
}
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
public void unlock(){
connection.commit();
}
通过connection.commit();操作来释放锁。这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
4.2、基于zookeeper实现分布式锁
基于zookeeper临时有序节点可以实现的分布式锁。ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。Znode分为四种类型:
1.持久节点 (PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
2.持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
3.临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除:
4.临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
基于ZooKeeper实现分布式锁的步骤如下: (1)创建一个目录mylock; (2)线程A想获取锁就在mylock目录下创建临时顺序节点; (3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁; (4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点; (5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
使用zookeeper能解决的分布式问题:
锁无法释放? 使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
非阻塞锁? 使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
不可重入? 使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
单点问题? 使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
公平问题? 使用Zookeeper可以解决公平锁问题,客户端在ZK中创建的临时节点是有序的,每次锁被释放时,ZK可以通知最小节点来获取锁,保证了公平。
Zookeeper数据同步问题: Zookeeper是一个保证了弱一致性即最终一致性的分布式组件。Zookeeper采用称为Quorum Based Protocol的数据同步协议。假如Zookeeper集群有N台Zookeeper服务器(N通常取奇数,3台能够满足数据可靠性同时有很高读写性能,5台在数据可靠性和读写性能方面平衡最好),那么用户的一个写操作,首先同步到N/2 + 1台服务器上,然后返回给用户,提示用户写成功。基于Quorum Based Protocol的数据同步协议决定了Zookeeper能够支持什么强度的一致性。
在分布式环境下,满足强一致性的数据储存基本不存在,它要求在更新一个节点的数据,需要同步更新所有的节点。这种同步策略出现在主从同步复制的数据库中。但是这种同步策略,对写性能的影响太大而很少见于实践。因为Zookeeper是同步写N/2+1个节点,还有N/2个节点没有同步更新,所以Zookeeper不是强一致性的。
用户的数据更新操作,不保证后续的读操作能够读到更新后的值,但是最终会呈现一致性。牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可。 推荐一个Apache的开源库Curator(https://github.com/apache/curator/),它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
Zookeeper实现分布式的优缺点: 优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
4.3、基于缓存实现分布式锁
4.3.1、使用命令
(1)加锁: SETNX key value:当且仅当key不存在时,set一个key为value的字符串,返回1;若key存在,则什么都不做,返回0。
(2)设置锁的超时: expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)释放锁: del key:删除key 在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。除此之外,我们还可以使用set key value NX EX max-lock-time 实现加锁,并且使用 EVAL 命令执行lua脚本实现解锁。
EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
XX : 只在键已经存在时, 才对键进行设置操作。
4.3.2、实现思路
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.params.SetParams;
import java.util.Collections;
public class RedisTool2 {
private static Jedis jedis = new Jedis("127.0.0.1",6379);
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
private static final Long RELEASE_SUCCESS = 1L;
/**
* EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
*
* PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
*
* NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
*
* XX : 只在键已经存在时, 才对键进行设置操作。
*/
/**
* 尝试获取分布式锁
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间(过期时间) 需要根据实际的业务场景确定
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(String lockKey, String requestId, int expireTime) {
SetParams params = new SetParams();
String result = jedis.set(lockKey, requestId, params.nx().ex(expireTime));
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
/**
* 尝试获取分布式锁
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间(过期时间)需要根据实际的业务场景确定
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock1(String lockKey, String requestId, int expireTime){
//只在键 key 不存在的情况下, 将键 key 的值设置为 value 。若键 key 已经存在, 则 SETNX 命令不做任何动作。设置成功返回1,失败返回0
long code = jedis.setnx(lockKey, requestId); //保证加锁的原子操作
//通过timeOut设置过期时间保证不会出现死锁【避免死锁】
jedis.expire(lockKey, expireTime); //设置键的过期时间
if(code == 1){
return true;
}
return false;
}
/**
* 解锁操作
* @param key 锁标识
* @param value 客户端标识
* @return
*/
public static Boolean unLock(String key,String value){
//luaScript 这个字符串是个lua脚本,代表的意思是如果根据key拿到的value跟传入的value相同就执行del,否则就返回0【保证安全性】
String luaScript = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then return redis.call(\"del\",KEYS[1]) else return 0 end";
//jedis.eval(String,list,list);这个命令就是去执行lua脚本,KEYS的集合就是第二个参数,ARGV的集合就是第三参数【保证解锁的原子操作】
Object var2 = jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value));
if (RELEASE_SUCCESS == var2) {
return true;
}
return false;
}
/**
* 解锁操作
* @param key 锁标识
* @param value 客户端标识
* @return
*/
public static Boolean unLock1(String key, String value){
//key就是redis的key值作为锁的标识,value在这里作为客户端的标识,只有key-value都比配才有删除锁的权利【保证安全性】
String oldValue = jedis.get(key);
long delCount = 0; //被删除的key的数量
if(oldValue.equals(value)){
delCount = jedis.del(key);
}
if(delCount > 0){ //被删除的key的数量大于0,表示删除成功
return true;
}
return false;
}
/**
* 重试机制:
* 如果在业务中去拿锁如果没有拿到是应该阻塞着一直等待还是直接返回,这个问题其实可以写一个重试机制,
* 根据重试次数和重试时间做一个循环去拿锁,当然这个重试的次数和时间设多少合适,是需要根据自身业务去衡量的
* @param key 锁标识
* @param value 客户端标识
* @param timeOut 过期时间
* @param retry 重试次数
* @param sleepTime 重试间隔时间
* @return
*/
public Boolean lockRetry(String key,String value,int timeOut,Integer retry,Long sleepTime){
Boolean flag = false;
try {
for (int i=0;i<retry;i++){
flag = tryGetDistributedLock(key,value,timeOut);
if(flag){
break;
}
Thread.sleep(sleepTime);
}
}catch (Exception e){
e.printStackTrace();
}
return flag;
}
}
5、参考文章
参考文章
6、示例代码
SpinLock类:
package com.yibin.blnp.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.params.SetParams;
/**
* 用途:自旋锁
*
* @version v1.01
* @Author liaoyibin **********
* @createDate 2023/3/16 21:12
* @modifyRecord <pre>
* 版本 修改人 修改时间 修改内容描述
* ----------------------------------------------
* 1.00 liaoyibin 2023/3/16 21:12 新建
* ----------------------------------------------
* </pre>
*/
public class SpinLock {
/**
* 成功锁标志
**/
private static final String LOCK_SUCCESS = "OK";
/**
* 失败锁标识
**/
private static final long UNLOCK_SUCCESS = 1L;
/**
* @author liaoyibin
* 描述: 尝试获取分布式锁
* @Date 21:19 2023/3/16
* @param jedis Redis客户端
* @param lockKey 锁键值
* @param value 锁的值
* @param expireTime 超期时间
* @return boolean 是否获取成功
**/
public static boolean tryLock(Jedis jedis, String lockKey, String value, int expireTime) {
// 自旋锁
while (true) {
// set key value ex seconds nx(只有键不存在的时候才会设置key)
String result = jedis.set(lockKey, value,SetParams.setParams().ex(expireTime).nx());
if (LOCK_SUCCESS.equals(result)) {
return true;
}
}
}
/**
* @author liaoyibin
* 描述: 释放分布式锁
* @Date 21:26 2023/3/16
* @param jedis Redis客户端
* @param lockKey 锁
* @return boolean 是否释放成功
**/
public static boolean unlock(Jedis jedis, String lockKey) {
Long result = jedis.del(lockKey);
if (UNLOCK_SUCCESS == result) {
return true;
}
return false;
}
}
SpinLockTest类:
package com.yibin.blnp.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.UUID;
/**
* 用途:分布式自旋锁测试
*
* @version v1.01
* @Author liaoyibin **********
* @createDate 2023/3/16 21:40
* @modifyRecord <pre>
* 版本 修改人 修改时间 修改内容描述
* ----------------------------------------------
* 1.00 liaoyibin 2023/3/16 21:40 新建
* ----------------------------------------------
* </pre>
*/
public class SpinLockTest {
/**
* 初始次数
**/
private int count = 0;
/**
* 加锁 key
**/
private String lockKey = "lock";
/**
* @author liaoyibin
* 描述: 加锁
* @Date 21:59 2023/3/16
* @param jedis
* @return void
**/
private void addLock(Jedis jedis) {
// 加锁
boolean locked = SpinLock.tryLock(jedis, lockKey, UUID.randomUUID().toString(), 60);
try {
if (locked) {
for (int i = 0; i < 500; i++) {
count++;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
SpinLock.unlock(jedis, lockKey);
}
}
public static void main(String[] args) throws Exception {
SpinLockTest redisLockTest = new SpinLockTest();
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMinIdle(1);
jedisPoolConfig.setMaxTotal(5);
JedisPool jedisPool = new JedisPool(jedisPoolConfig,
"192.168.56.111", 6379, 1000, "123456");
Thread t1 = new Thread(() -> redisLockTest.addLock(jedisPool.getResource()));
Thread t2 = new Thread(() -> redisLockTest.addLock(jedisPool.getResource()));
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(redisLockTest.count);
}
}
05.redis和MySQL数据一致性相关设计
MySQL与Redis都是常用的数据存储和缓存系统。为了提高应用程序的性能和可伸缩性,很多应用程序将MySQL和Redis一起使用,其中MySQL作为主要的持久存储,而Redis作为主要的缓存。在这种情况下,应用程序需要确保MySQL和Redis中的数据是同步的,以确保数据的一致性。以下是一些常用的MySQL和Redis缓存同步方案:

1、定时同步:应用程序可以定期将MySQL中的数据同步到Redis中。这种方法的优点是实现简单,缺点是可能会导致数据不一致,因为数据在同步的过程中可能会被修改。

2、实时同步:可以使用触发器或者消息队列实现MySQL和Redis之间的实时同步。当MySQL中的数据发生变化时,触发器或者消息队列会立即通知Redis进行更新。这种方法的优点是实时性高,缺点是实现复杂。

3、双写模式:可以将MySQL和Redis同时写入,确保数据的一致性。这种方法的优点是实现简单,缺点是可能会影响性能。

4、读写分离:可以将MySQL用于写操作,而将Redis用于读操作。这种方法的优点是实现简单,缺点是可能会导致数据不一致,因为MySQL和Redis之间的同步延迟。

选择哪种方法取决于应用程序的具体需求和性能要求。需要权衡不同方法的优缺点,并根据实际情况进行选择。

MySQL和Redis是两种不同类型的数据库,MySQL是关系型数据库,Redis是基于内存的键值存储数据库。在使用这两种数据库时,要考虑数据一致性的问题。 下面是一些可能的MySQL和Redis数据一致性设计:

1、双写:双写是指同时将数据写入MySQL和Redis。这种方法可以保证数据的一致性,但是会降低系统的性能,因为每次写操作需要写入两个数据库。

2、读写分离:读写分离是指将读操作从MySQL转移到Redis中,只在MySQL中执行写操作。这样可以提高系统的性能,但是会导致读操作的数据与写操作的数据存在一定的延迟。

2、异步写入:异步写入是指先将数据写入MySQL,然后异步将数据写入Redis。这种方法可以提高系统的性能,但是不能保证数据的实时性。

4、数据同步:可以使用数据同步工具,如Canal等,将MySQL中的数据同步到Redis中。这种方法可以保证数据的一致性和实时性,但是需要额外的配置和维护工作。

6、在MySQL中存储Redis中的键值对:可以在MySQL中创建一个键值对表,用来存储Redis中的键值对,然后在Redis中读写这些数据。这种方法可以提高系统的性能,但是需要额外的存储空间和维护工作。

需要根据具体的业务场景和系统需求来选择合适的数据一致性设计方案。


06.长短连接的区别和应用场景
一.长连接和短连接
长连接:是指在一个TCP连接上可以发送多个数据包,但是如果没有数据包发送时,也要双方发检测包以维持这个链连接
短连接:当双方需要有数据交互的时候,就建立一个TCP连接,本次交互完成后,就断开这个连接
注:双方指客户端和服务端
二.各自优缺点及使用场景
长连接可以省去较多建立连接和关闭连接的操作,所以比较节省资源和时间,但是长连接如果一直存在的话,第一需要很多探测包的发送来维持这个连接,第二对服务器将是很大的负荷
相对而言,短连接则不需要服务器承担太大负荷,只要存在的连接就都是有用连接,但如果客户端请求频繁,就会在TCP的建立连接和关闭连接上浪费较大的资源和时间
三.使用场景
综合长连接短连接的优缺点,我们不难发现,这两种连接没有绝对的好坏之分,只能说在不同的场景使用不同的连接才是上策
一般而言,像京东,淘宝这些大型的网站,随时随刻有成千上万的用户对服务端发送请求,一般使用短连接,因为如果用长连接的话,用户越来越多,服务器一般扛不住这么多长连接
其实现在的大部分网站,使用的都是短连接,应该还是服务器压力的问题吧
而即时通讯(比如QQ)一般使用的是长连接(UDP长连接),但并不是永久连接,一般也会有一个保持的时间,比如30分钟,24小时等,因为即时通讯是频繁的发送请求,使用长连接只需要建立一次连接,比较划算,同时再根据业务设置保持时间,超过这个时间就断开连接,也一定程度上保证了服务器的压力不会过大
同理,网络游戏一般也使用长连接,同理即时通讯
网络拥塞之拥塞避免和拥塞管理
拥塞避免通过指定报文丢弃策略来解除网络过载,拥塞管理通过指定报文调度次序来确保高优先级业务优先被处理。
07.RAII实现数据库连接池,怎么实现的
C++ RAII
C++面向对象编程时,创建变量会执行构造函数,销毁对象时执行析构函数,若进程堆资源在构造函数中获取,在析构函数中释放资源,即实现了RAII,理论上该技术可以以用于任何的系统资源。
数据库连接池
一个常规的数据库连接池所包含的组件如下所示。
//connection.h
class connection_pool{
public:
MYSQL *GetConnection(); //获取数据库连接
bool ReleaseConnection(MYSQL *conn); //释放连接
int GetFreeConn(); //获取连接
void DestroyPool(); //销毁所有连接
//单例模式
static connection_pool *GetInstance();
void init(string url, string User, string PassWord, string DataBaseName, int Port, int MaxConn, int close_log);
private:
connection_pool();//私有构造函数,防止类外申请变量。
~connection_pool();
int m_MaxConn; //最大连接数
int m_CurConn; //当前已使用的连接数
int m_FreeConn; //当前空闲的连接数
locker lock;
list<MYSQL *> connList; //连接池
sem reserve;
public:
string m_url; //主机地址
string m_Port; //数据库端口号
string m_User; //登陆数据库用户名
string m_PassWord; //登陆数据库密码
string m_DatabaseName; //使用数据库名
int m_close_log; //日志开关
};
connection.cpp
connection_pool::connection_pool(){
m_CurConn = 0;
m_FreeConn = 0;
}
connection_pool *connection_pool::GetInstance(){
static connection_pool connPool;
return &connPool;
}
//构造初始化
void connection_pool::init(string url, string User, string PassWord, string DBName, int Port, int MaxConn, int close_log){
m_url = url;
m_Port = Port;
m_User = User;
m_PassWord = PassWord;
m_DatabaseName = DBName;
m_close_log = close_log;
for (int i = 0; i < MaxConn; i++){
MYSQL *con = NULL;
con = mysql_init(con);
if (con == NULL){
LOG_ERROR("MySQL Error");
exit(1);
}
con = mysql_real_connect(con, url.c_str(), User.c_str(), PassWord.c_str(), DBName.c_str(), Port, NULL, 0);
if (con == NULL){
LOG_ERROR("MySQL Error");
exit(1);
}
connList.push_back(con);
++m_FreeConn;
}
reserve = sem(m_FreeConn);
m_MaxConn = m_FreeConn;
}
//使用指针可以访问到池子
//当有请求时,从数据库连接池中返回一个可用连接,更新使用和空闲连接数
MYSQL *connection_pool::GetConnection(){
MYSQL *con = NULL;
if (0 == connList.size())
return NULL;
reserve.wait();
lock.lock();
con = connList.front();
connList.pop_front();
--m_FreeConn;
++m_CurConn;
lock.unlock();
return con;
}
//释放当前使用的连接
bool connection_pool::ReleaseConnection(MYSQL *con){
if (NULL == con)
return false;
lock.lock();
connList.push_back(con);
++m_FreeConn;
--m_CurConn;
lock.unlock();
reserve.post();
return true;
}
//销毁数据库连接池
void connection_pool::DestroyPool(){
lock.lock();
if (connList.size() > 0){
list<MYSQL *>::iterator it;
for (it = connList.begin(); it != connList.end(); ++it){
MYSQL *con = *it;
mysql_close(con);
}
m_CurConn = 0;
m_FreeConn = 0;
connList.clear();
}
lock.unlock();
}
在数据库连接池中使用RAII技术如下所示:
//RAII.h
class connectionRAII{
public:
connectionRAII(MYSQL **con, connection_pool *connPool);
~connectionRAII();
private:
MYSQL *conRAII;
connection_pool *poolRAII;
//RAII.c
connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool){
*SQL = connPool->GetConnection();
conRAII = *SQL;
poolRAII = connPool;
}
connectionRAII::~connectionRAII(){
poolRAII->ReleaseConnection(conRAII);
}
};
分析: 在使用时通过调用GetInstance()生成数据库连接池,将数据库连接池永恒放在静态栈中,代码如下所示:
m_connPool = connection_pool::GetInstance();
m_connPool->init("localhost", m_user, m_passWord, m_databaseName, 3306, m_sql_num, m_close_log);
//初始化数据库读取表
users->initmysql_result(m_connPool);
当程序出该作用域时mysqlcon函数自动析构,释放该条数据库的连接。
connectionRAII mysqlcon(&request->mysql, m_connPool);
request->process();
08.http服务器,他的目标是什么,通过什么方式实现的
1.对于HTTP的简单理解
1.1 http服务器简介
HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。HTTP 是一个基于TCP/IP 通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)
1.2 http工作原理
http协议工作于客户端-服务端架构上,浏览器作为http客户端通过URL向http服务器即web服务器发送所有请求,web服务器根据接收到的请求向客户端发送响应信息,http端口默认为80端口
注意事项
- http是无连接的,就是一次只能处理一个请求处理完请求后给客户发送应答,断开连接
- http是媒体独立的,客户端和服务端只知道如何处理数据内容,任何类型的数据都可以通过http发送,客户端和服务器指定使用合适的MIME-type内容类型
- http是无状态的,对于事务处理没有记忆,缺少状态信息保存
1.3 http消息结构
- HTTP 是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无
- 状态的请求/响应协议
- 一个 HTTP"客户端"是一个应用程序(Web 浏览器或其他任何客户端),通过连接到服务器达
- 到向服务器发送一个或多个 HTTP 的请求的目的
- 一个 HTTP"服务器"同样也是一个应用程序(通常是一个 Web 服务,如 Apache Web 服务器
- 或 IIS 服务器等),通过接收客户端的请求并向客户端发送 HTTP 响应数据
- HTTP 使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接
1.4 客户端请求消息
客户端发送一个http请求到服务器的请求消息包括以下格式:请求行、请求头部、空行和请求数据四个部分

客户端请求示例
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务器响应信息 http响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文
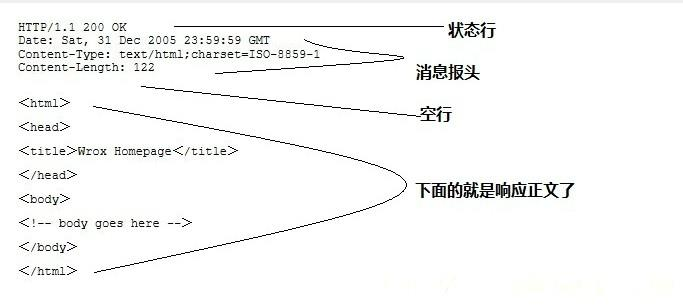
GET请求服务端响应示例:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
输出结果:
Hello World! My payload includes a trailing CRLF.
1.5 HTTP的请求方法
根据HTTP标准,http可以有多种请求方法
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法
1.6 HTTP响应头信息
HTTP 请求头提供了关于请求,响应或者其他的发送实体的信息
1.7 HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。HTTP 状态码的英文为 HTTP Status Code
1.7.1 五种类型状态码
1.7.2 状态码列表
2.HTTP的实现
本设计使用Reactor模型实现一个http服务器,Reactor模型不再过多赘述,可以看我另外一篇专门讲Reactor的博客,本文主要讲建立TCP连接,接受客户端请求和发送HTTP响应,这也是一个http连接的生命周期
2.1 建立TCP连接
这一步的应用场景一般是对连接进行检验,比如
- ip限制检查
- 负载均衡
int accept_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
if (reactor == NULL) return -1;
struct sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int clientfd;
if ((clientfd = accept(fd, (struct sockaddr*)&client_addr, &len)) == -1) {
if (errno != EAGAIN && errno != EINTR) {
}
printf("accept: %s\n", strerror(errno));
return -1;
}
int flag = 0;
if ((flag = fcntl(clientfd, F_SETFL, O_NONBLOCK)) < 0) {
printf("%s: fcntl nonblocking failed, %d\n", __func__, MAX_EPOLL_EVENTS);
return -1;
}
struct ntyevent *event = ntyreactor_idx(reactor, clientfd);
nty_event_set(event, clientfd, recv_cb, reactor);
nty_event_add(reactor->epfd, EPOLLIN, event);
printf("new connect [%s:%d], pos[%d]\n",
inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port), clientfd);
return 0;
}
2.2 接受http请求
int recv_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
struct ntyevent *ev = ntyreactor_idx(reactor, fd);
int len = recv(fd, ev->buffer, BUFFER_LENGTH , 0); //接受一个http请求
nty_event_del(reactor->epfd, ev);
if (len > 0) {
ev->length = len;
ev->buffer[len] = '\0';
printf("C[%d]:%s\n", fd, ev->buffer);
nty_event_set(ev, fd, send_cb, reactor);
nty_event_add(reactor->epfd, EPOLLOUT, ev);
} else if (len == 0) {
close(ev->fd);
//printf("[fd=%d] pos[%ld], closed\n", fd, ev-reactor->events);
} else {
close(ev->fd);
printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno));
}
return len;
}
2.3http协议解析
处理客户端发来的请求报文前要先弄清楚是什么请求报文,下面以GET和POST请求为例
int http_request(struct ntyevent *ev) {
// GET, POST
char linebuf[1024] = {0};
int idx = readline(ev->buffer, 0, linebuf);
if (strstr(linebuf, "GET")) {
ev->method = HTTP_METHOD_GET;
//uri
int i = 0;
while (linebuf[sizeof("GET ") + i] != ' ') i++;
linebuf[sizeof("GET ")+i] = '\0';
sprintf(ev->resource, "./%s/%s", HTTP_WEBSERVER_HTML_ROOT, linebuf+sizeof("GET "));
} else if (strstr(linebuf, "POST")) {
}
}
2.4 http协议处理
http是一个超文本传输协议,这个函数是对文本进行处理
int http_response(struct ntyevent *ev) {
if (ev == NULL) return -1;
memset(ev->buffer, 0, BUFFER_LENGTH);
#if 0
const char *html = "<html><head><title>hello http</title></head><body><H1>King</H1></body></html>\r\n\r\n";
ev->length = sprintf(ev->buffer,
"HTTP/1.1 200 OK\r\n\
Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n\
Content-Type: text/html;charset=ISO-8859-1\r\n\
Content-Length: 83\r\n\r\n%s",
html);
#else
printf("resource: %s\n", ev->resource);
int filefd = open(ev->resource, O_RDONLY);
if (filefd == -1) { // return 404
ev->ret_code = 404;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 404 Not Found\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: 85\r\n\r\n"
"<html><head><title>404 Not Found</title></head><body><H1>404</H1></body></html>\r\n\r\n" );
} else {
struct stat stat_buf;
fstat(filefd, &stat_buf);
close(filefd);
if (S_ISDIR(stat_buf.st_mode)) {
ev->ret_code = 404;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 404 Not Found\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: 85\r\n\r\n"
"<html><head><title>404 Not Found</title></head><body><H1>404</H1></body></html>\r\n\r\n" );
} else if (S_ISREG(stat_buf.st_mode)) {
ev->ret_code = 200;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 200 OK\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: %ld\r\n\r\n",
stat_buf.st_size );
}
}
#endif
return ev->length;
}
2.5 发送HTTP响应
int send_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
struct ntyevent *ev = ntyreactor_idx(reactor, fd);
http_response(ev);
//
int len = send(fd, ev->buffer, ev->length, 0);
if (len > 0) {
printf("send[fd=%d], [%d]%s\n", fd, len, ev->buffer);
if (ev->ret_code == 200) {
int filefd = open(ev->resource, O_RDONLY);
struct stat stat_buf;
fstat(filefd, &stat_buf);
sendfile(fd, filefd, NULL, stat_buf.st_size);
close(filefd);
}
nty_event_del(reactor->epfd, ev);
nty_event_set(ev, fd, recv_cb, reactor);
nty_event_add(reactor->epfd, EPOLLIN, ev);
} else {
close(ev->fd);
nty_event_del(reactor->epfd, ev);
printf("send[fd=%d] error %s\n", fd, strerror(errno));
}
return len;
}
2.6 全部代码附录
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <arpa/inet.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <time.h>
#include <sys/stat.h>
#include <sys/sendfile.h>
#define BUFFER_LENGTH 4096
#define MAX_EPOLL_EVENTS 1024
#define SERVER_PORT 8888
#define PORT_COUNT 1
#define HTTP_WEBSERVER_HTML_ROOT "html"
#define HTTP_METHOD_GET 0
#define HTTP_METHOD_POST 1
typedef int NCALLBACK(int ,int, void*);
struct ntyevent {
int fd;
int events;
void *arg;
int (*callback)(int fd, int events, void *arg);
int status;
char buffer[BUFFER_LENGTH];
int length;
long last_active;
// http param
int method; //
char resource[BUFFER_LENGTH];
int ret_code;
};
struct eventblock {
struct eventblock *next;
struct ntyevent *events;
};
struct ntyreactor {
int epfd;
int blkcnt;
struct eventblock *evblk; //fd --> 100w
};
int recv_cb(int fd, int events, void *arg);
int send_cb(int fd, int events, void *arg);
struct ntyevent *ntyreactor_idx(struct ntyreactor *reactor, int sockfd);
void nty_event_set(struct ntyevent *ev, int fd, NCALLBACK callback, void *arg) {
ev->fd = fd;
ev->callback = callback;
ev->events = 0;
ev->arg = arg;
ev->last_active = time(NULL);
return ;
}
int nty_event_add(int epfd, int events, struct ntyevent *ev) {
struct epoll_event ep_ev = {0, {0}};
ep_ev.data.ptr = ev;
ep_ev.events = ev->events = events;
int op;
if (ev->status == 1) {
op = EPOLL_CTL_MOD;
} else {
op = EPOLL_CTL_ADD;
ev->status = 1;
}
if (epoll_ctl(epfd, op, ev->fd, &ep_ev) < 0) {
printf("event add failed [fd=%d], events[%d]\n", ev->fd, events);
return -1;
}
return 0;
}
int nty_event_del(int epfd, struct ntyevent *ev) {
struct epoll_event ep_ev = {0, {0}};
if (ev->status != 1) {
return -1;
}
ep_ev.data.ptr = ev;
ev->status = 0;
epoll_ctl(epfd, EPOLL_CTL_DEL, ev->fd, &ep_ev);
return 0;
}
int readline(char *allbuf, int idx, char *linebuf) {
int len = strlen(allbuf);
for(;idx < len;idx ++) {
if (allbuf[idx] == '\r' && allbuf[idx+1] == '\n') {
return idx+2;
} else {
*(linebuf++) = allbuf[idx];
}
}
return -1;
}
int http_request(struct ntyevent *ev) {
// GET, POST
char linebuf[1024] = {0};
int idx = readline(ev->buffer, 0, linebuf);
if (strstr(linebuf, "GET")) {
ev->method = HTTP_METHOD_GET;
//uri
int i = 0;
while (linebuf[sizeof("GET ") + i] != ' ') i++;
linebuf[sizeof("GET ")+i] = '\0';
sprintf(ev->resource, "./%s/%s", HTTP_WEBSERVER_HTML_ROOT, linebuf+sizeof("GET "));
} else if (strstr(linebuf, "POST")) {
}
}
int recv_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
struct ntyevent *ev = ntyreactor_idx(reactor, fd);
int len = recv(fd, ev->buffer, BUFFER_LENGTH, 0); //
if (len > 0) {
ev->length = len;
ev->buffer[len] = '\0';
printf("C[%d]:%s\n", fd, ev->buffer); //http
http_request(ev);
//send();
nty_event_del(reactor->epfd, ev);
nty_event_set(ev, fd, send_cb, reactor);
nty_event_add(reactor->epfd, EPOLLOUT, ev);
} else if (len == 0) {
nty_event_del(reactor->epfd, ev);
close(ev->fd);
//printf("[fd=%d] pos[%ld], closed\n", fd, ev-reactor->events);
} else {
nty_event_del(reactor->epfd, ev);
close(ev->fd);
printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno));
}
return len;
}
int http_response(struct ntyevent *ev) {
if (ev == NULL) return -1;
memset(ev->buffer, 0, BUFFER_LENGTH);
#if 0
const char *html = "<html><head><title>hello http</title></head><body><H1>King</H1></body></html>\r\n\r\n";
ev->length = sprintf(ev->buffer,
"HTTP/1.1 200 OK\r\n\
Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n\
Content-Type: text/html;charset=ISO-8859-1\r\n\
Content-Length: 83\r\n\r\n%s",
html);
#else
printf("resource: %s\n", ev->resource);
int filefd = open(ev->resource, O_RDONLY);
if (filefd == -1) { // return 404
ev->ret_code = 404;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 404 Not Found\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: 85\r\n\r\n"
"<html><head><title>404 Not Found</title></head><body><H1>404</H1></body></html>\r\n\r\n" );
} else {
struct stat stat_buf;
fstat(filefd, &stat_buf);
close(filefd);
if (S_ISDIR(stat_buf.st_mode)) {
ev->ret_code = 404;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 404 Not Found\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: 85\r\n\r\n"
"<html><head><title>404 Not Found</title></head><body><H1>404</H1></body></html>\r\n\r\n" );
} else if (S_ISREG(stat_buf.st_mode)) {
ev->ret_code = 200;
ev->length = sprintf(ev->buffer,
"HTTP/1.1 200 OK\r\n"
"Date: Thu, 11 Nov 2021 12:28:52 GMT\r\n"
"Content-Type: text/html;charset=ISO-8859-1\r\n"
"Content-Length: %ld\r\n\r\n",
stat_buf.st_size );
}
}
#endif
return ev->length;
}
int send_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
struct ntyevent *ev = ntyreactor_idx(reactor, fd);
http_response(ev);
//
int len = send(fd, ev->buffer, ev->length, 0);
if (len > 0) {
printf("send[fd=%d], [%d]%s\n", fd, len, ev->buffer);
if (ev->ret_code == 200) {
int filefd = open(ev->resource, O_RDONLY);
struct stat stat_buf;
fstat(filefd, &stat_buf);
sendfile(fd, filefd, NULL, stat_buf.st_size);
close(filefd);
}
nty_event_del(reactor->epfd, ev);
nty_event_set(ev, fd, recv_cb, reactor);
nty_event_add(reactor->epfd, EPOLLIN, ev);
} else {
close(ev->fd);
nty_event_del(reactor->epfd, ev);
printf("send[fd=%d] error %s\n", fd, strerror(errno));
}
return len;
}
int accept_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor*)arg;
if (reactor == NULL) return -1;
struct sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int clientfd;
if ((clientfd = accept(fd, (struct sockaddr*)&client_addr, &len)) == -1) {
if (errno != EAGAIN && errno != EINTR) {
}
printf("accept: %s\n", strerror(errno));
return -1;
}
int flag = 0;
if ((flag = fcntl(clientfd, F_SETFL, O_NONBLOCK)) < 0) {
printf("%s: fcntl nonblocking failed, %d\n", __func__, MAX_EPOLL_EVENTS);
return -1;
}
struct ntyevent *event = ntyreactor_idx(reactor, clientfd);
nty_event_set(event, clientfd, recv_cb, reactor);
nty_event_add(reactor->epfd, EPOLLIN, event);
printf("new connect [%s:%d], pos[%d]\n",
inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port), clientfd);
return 0;
}
int init_sock(short port) {
int fd = socket(AF_INET, SOCK_STREAM, 0);
fcntl(fd, F_SETFL, O_NONBLOCK);
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(port);
bind(fd, (struct sockaddr*)&server_addr, sizeof(server_addr));
if (listen(fd, 20) < 0) {
printf("listen failed : %s\n", strerror(errno));
}
return fd;
}
int ntyreactor_alloc(struct ntyreactor *reactor) {
if (reactor == NULL) return -1;
if (reactor->evblk == NULL) return -1;
struct eventblock *blk = reactor->evblk;
while (blk->next != NULL) {
blk = blk->next;
}
struct ntyevent *evs = (struct ntyevent*)malloc((MAX_EPOLL_EVENTS) * sizeof(struct ntyevent));
if (evs == NULL) {
printf("ntyreactor_alloc ntyevents failed\n");
return -2;
}
memset(evs, 0, (MAX_EPOLL_EVENTS) * sizeof(struct ntyevent));
struct eventblock *block = (struct eventblock *)malloc(sizeof(struct eventblock));
if (block == NULL) {
printf("ntyreactor_alloc eventblock failed\n");
return -2;
}
memset(block, 0, sizeof(struct eventblock));
block->events = evs;
block->next = NULL;
blk->next = block;
reactor->blkcnt ++; //
return 0;
}
struct ntyevent *ntyreactor_idx(struct ntyreactor *reactor, int sockfd) {
int blkidx = sockfd / MAX_EPOLL_EVENTS;
while (blkidx >= reactor->blkcnt) {
ntyreactor_alloc(reactor);
}
int i = 0;
struct eventblock *blk = reactor->evblk;
while(i ++ < blkidx && blk != NULL) {
blk = blk->next;
}
return &blk->events[sockfd % MAX_EPOLL_EVENTS];
}
int ntyreactor_init(struct ntyreactor *reactor) {
if (reactor == NULL) return -1;
memset(reactor, 0, sizeof(struct ntyreactor));
reactor->epfd = epoll_create(1);
if (reactor->epfd <= 0) {
printf("create epfd in %s err %s\n", __func__, strerror(errno));
return -2;
}
struct ntyevent *evs = (struct ntyevent*)malloc((MAX_EPOLL_EVENTS) * sizeof(struct ntyevent));
if (evs == NULL) {
printf("ntyreactor_alloc ntyevents failed\n");
return -2;
}
memset(evs, 0, (MAX_EPOLL_EVENTS) * sizeof(struct ntyevent));
struct eventblock *block = (struct eventblock *)malloc(sizeof(struct eventblock));
if (block == NULL) {
printf("ntyreactor_alloc eventblock failed\n");
return -2;
}
memset(block, 0, sizeof(struct eventblock));
block->events = evs;
block->next = NULL;
reactor->evblk = block;
reactor->blkcnt = 1;
return 0;
}
int ntyreactor_destory(struct ntyreactor *reactor) {
close(reactor->epfd);
//free(reactor->events);
struct eventblock *blk = reactor->evblk;
struct eventblock *blk_next = NULL;
while (blk != NULL) {
blk_next = blk->next;
free(blk->events);
free(blk);
blk = blk_next;
}
return 0;
}
int ntyreactor_addlistener(struct ntyreactor *reactor, int sockfd, NCALLBACK *acceptor) {
if (reactor == NULL) return -1;
if (reactor->evblk == NULL) return -1;
//reactor->evblk->events[sockfd];
struct ntyevent *event = ntyreactor_idx(reactor, sockfd);
nty_event_set(event, sockfd, acceptor, reactor);
nty_event_add(reactor->epfd, EPOLLIN, event);
return 0;
}
int ntyreactor_run(struct ntyreactor *reactor) {
if (reactor == NULL) return -1;
if (reactor->epfd < 0) return -1;
if (reactor->evblk == NULL) return -1;
struct epoll_event events[MAX_EPOLL_EVENTS+1];
int checkpos = 0, i;
while (1) {
/*
long now = time(NULL);
for (i = 0;i < 100;i ++, checkpos ++) {
if (checkpos == MAX_EPOLL_EVENTS) {
checkpos = 0;
}
if (reactor->events[checkpos].status != 1) {
continue;
}
long duration = now - reactor->events[checkpos].last_active;
if (duration >= 60) {
close(reactor->events[checkpos].fd);
printf("[fd=%d] timeout\n", reactor->events[checkpos].fd);
nty_event_del(reactor->epfd, &reactor->events[checkpos]);
}
}
*/
int nready = epoll_wait(reactor->epfd, events, MAX_EPOLL_EVENTS, 1000);
if (nready < 0) {
printf("epoll_wait error, exit\n");
continue;
}
for (i = 0;i < nready;i ++) {
struct ntyevent *ev = (struct ntyevent*)events[i].data.ptr;
if ((events[i].events & EPOLLIN) && (ev->events & EPOLLIN)) {
ev->callback(ev->fd, events[i].events, ev->arg);
}
if ((events[i].events & EPOLLOUT) && (ev->events & EPOLLOUT)) {
ev->callback(ev->fd, events[i].events, ev->arg);
}
}
}
}
// 3, 6w, 1, 100 ==
// <remoteip, remoteport, localip, localport>
int main(int argc, char *argv[]) {
unsigned short port = SERVER_PORT; // listen 8888
if (argc == 2) {
port = atoi(argv[1]);
}
struct ntyreactor *reactor = (struct ntyreactor*)malloc(sizeof(struct ntyreactor));
ntyreactor_init(reactor);
int i = 0;
int sockfds[PORT_COUNT] = {0};
for (i = 0;i < PORT_COUNT;i ++) {
sockfds[i] = init_sock(port+i);
ntyreactor_addlistener(reactor, sockfds[i], accept_cb);
}
//dup2(sockfd, STDIN);
ntyreactor_run(reactor);
ntyreactor_destory(reactor);
for (i = 0;i < PORT_COUNT;i ++) {
close(sockfds[i]);
}
free(reactor);
return 0;
}
09.负载均衡的一些场景问题
1. 不同的负载场景
我们知道负载均衡层的作用是“将来源于外部的处理压力通过某种规律/手段分摊到内部各个处理节点上”,那么不同的业务场景需要的负载均衡方式又是不一样的,架构师还要考虑架构方案的成本、可扩展性、运维难易度等问题。下面我们先介绍几种典型的不同业务场景,大家也可以先想一下如果是您,会怎么架设这些场景的负载均衡层。
需要注意的是,这个系统的文章,我们都将使用这几个典型的业务场景来讲解系统架构的设计递归设计。在后续几篇介绍负载层架构的文章中,我们也将通过这几个典型的业务场景讲解负载层的架构方案。
1.1、负载场景一
这是一个国家级物流园区的货运订单和物流管理系统。在物流园区内的货运代理商、合作司机(货运车辆)、园区管理员和客服人员都要使用这套系统。每日RUV在1万人次,日PV在10万左右。甲方总经理使用这套系统的原有是抱着“试一下移动互联网对物流产品是否能起到提高效率的作用”。可以看出整个系统基本上没有访问压力,甲方对您设计的系统只有一个要求:能够保证系统以后的功能和性能扩展性。
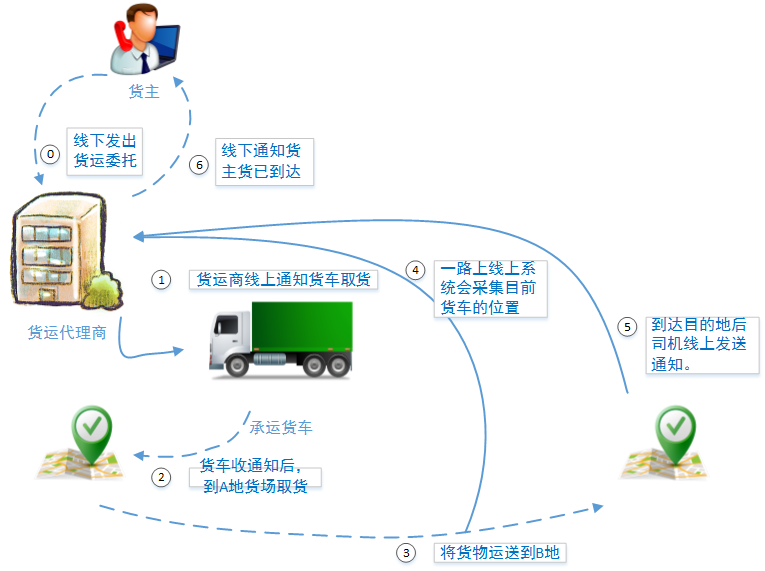
1.2、负载场景二
效果不错!在第一版系统架设后的6个月,货场丢货的情况大大减少,并且由于货车在途情况的监控,按时到达率也显著提升,货车司机也反映由于整个货场货车信息都是共享的,货车的待货时间也明显缩短。在这期间物流园中越来越多的货运代理商、货车司机都开始使用这套系统了,整个系统的访问量成线性增长。
物流园的总经理对整个系统的作用感到满意,决定扩大系统的使用范围,并增加新的功能。经过讨论甲方最终决定把整套系统开放给货主:或者可以在系统上查看货运代理商的线路报价、线上通知代理商上门取货、监控目前自己货品的运输状态、了解第三方签收情况。初步估计系统的日RUV将达到10万,日PV将突破50万。
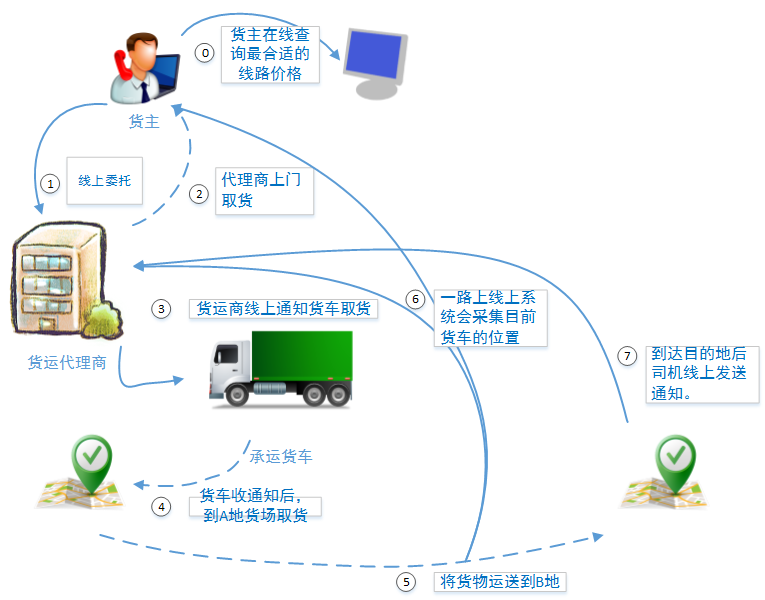
1.3、负载场景三
一年后,赞不绝口的大宗货品运输服务质量终于传到了政府领导的耳朵里。省里分管运输的领导亲自领队到物流园区参观考察,最终决定由省政府牵头,各地方政府参与,将这套管理办法在整个省级范围进行推广使用。全省10家大型物流园和50家二级物流园中的上万货运代理商、散落省内的零散代理商、10万个人/企业货主、40万优等资质车源共同接入系统。
新的功能上,增加了费用结算和运费保障功能,从货主预付款开始到第三方确认收货的整个环节都进行费用管理。为了保证线上收货环节的顺利,新版本中还增加了代理商之间的合作收货功能。新系统的日RUV将超过50万,日PV将突破250万。
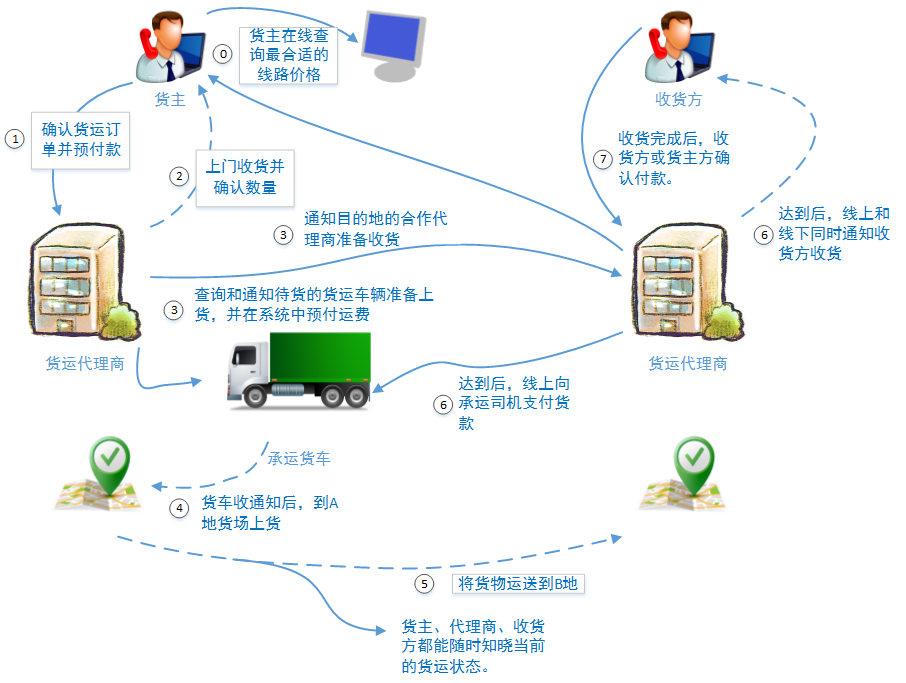
1.4、负载场景四
服务效应、经济效应、口碑效应不断发酵,经过近两年多的发展,目前这套系统已经是省内知名的物流配送平台,专门服务大宗货运物流。联合政府向全国推广服务的时机终于到来。预计全国1000多个物流园区,50万左右物流代理商,500万货运车辆、数不清的个人和企业货主都将使用该系统。预估的RUV和PV是多少呢?无法预估,如果按照全国32省来进行一个简单的乘法,是可以得到一个大概的值(50万 * 32 = 1500万+;500万 * 32 = 1.5亿+,已经超过了JD.com的平峰流量),但是各省的物流业规模是不一样的,从业者数量也不一样,所以这样的预估并不科学。而且再这样的系统规模下我们应该更过的考虑系统的峰值冗余。
业务功能的情况:为了保证注册货车的有效性,您所在的公司被政府允许访问政府的车辆信息库,在车辆注册的过程中进行车辆信息有效性的验证(第三方系统接口调用,我们并不知道第三方系统是否能够接收一个较高水平的并发量,所以这个问题留给我我们的架构师,我们将在业务层讲解时进行详细的描述)。
1.5、沉思片刻
看到这里,我们已经将几个递进的业务场景进行了详细的说明(甚至在后文中我们讨论业务层、业务通信层、数据存储层时所涉及的业务场景也不会有什么大的变化了)。看客们看到这里,可以稍作休息,先想想如果是您,您会如何搭建负载层,甚至整个系统的顶层架构。
由于整个系统的性能除了和硬件有关外,业务层的拆分规则,代码质量,缓存技术的使用方式,数据库的优化水平都可能对其产生影响。所以:
我们在讨论负载层的几篇文章中,我们要假设系统架构中各层的设计都没有对系统性能产生瓶颈
如果您已经思考好了,那么可以继续看以下的内容。
2、负载方案构想
2.1、解决方案一:独立的Nginx/Haproxy方案
很显然,第一个业务场景下,系统并没有多大的压力就是一套简单业务系统,日访问量也完全没有“有访问压力”这样的说法。但是客户有一个要求值得我们关注:要保证系统以后的功能和性能扩展性。为了保证功能和性能扩展性,在系统建立之初就要有一个很好的业务拆分规划,例如我们首先会把用户信息权限子系统和订单系统进行拆分,独立的车辆信息和定位系统可能也需要拆分出来。
这也是我们在系统建立时就要引入负载均衡层的一个重要原因。也是负载均衡层的重要作用之一。如下图所示:
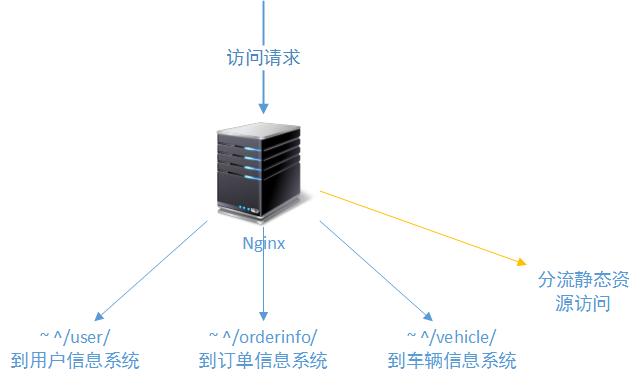
可以看出,这时负载均衡层只有一个作用,就是按照设定的访问规则,将访问不同系统的请求转发给对应的系统,并且在出现错误访问的情况下转发到错误提示页面。
2.2、解决方案二:Nginx/Haproxy + Keepalived方案
此后,系统的访问压力进一步加大,系统的稳定性越来越受到我们的关注。所以在单节点处理还能满足业务要求的情况下,我们为负载层(还有各层)引入热备方案,以保证一个节点在崩溃的情况下,另一个节点能够自动接替其工作,为工程师解决问题赢得时间。如下图所示:
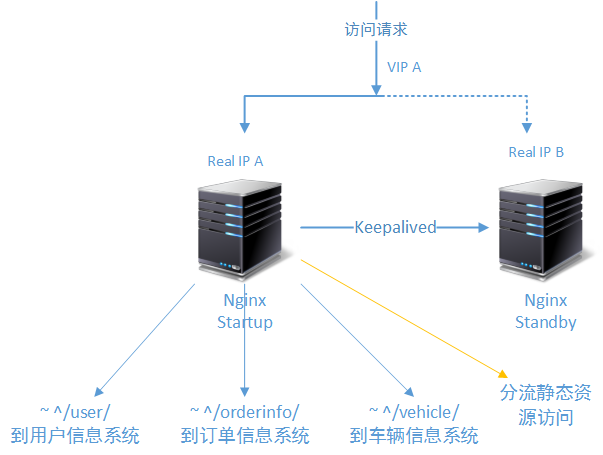
2.3、解决方案三:LVS(DR)+ Keepalived+ Nginx方案
在第三版本架构方案中,为了保证负载层足够稳定的状态下,适应更大的访问吞吐量还要应付可能的访问洪峰,我们加入了LVS技术。LVS负责第一层负载,然后再将访问请求转发到后端的若干台Nginx上。LVS的DR工作模式,只是将请求转到后端,后端的Nginx服务器必须有一个外网IP,在收到请求并处理完成后,Nginx将直接发送结果到请求方,不会再经LVS回发(具体的LVS工作原理介绍将在后文中详细介绍)。

这里要注意的是:
- 有了上层的LVS的支撑Nginx就不再需要使用Keepalived作为热备方案。因为首先Nginx不再是单个节点进行负载处理,而是一个集群多台Nginx节点;另外LVS对于下后端的服务器自带基于端口的健康检查功能;
- LVS是单节点处理的,虽然LVS是非常稳定的,但是为了保证LVS更稳定的工作,我们还是需要使用Keepalived为 LVS做一个热备节点,以防不时之需。
2.4、解决方案四:DNS轮询 + LVS(DR)+ Keepalived + Nginx方案
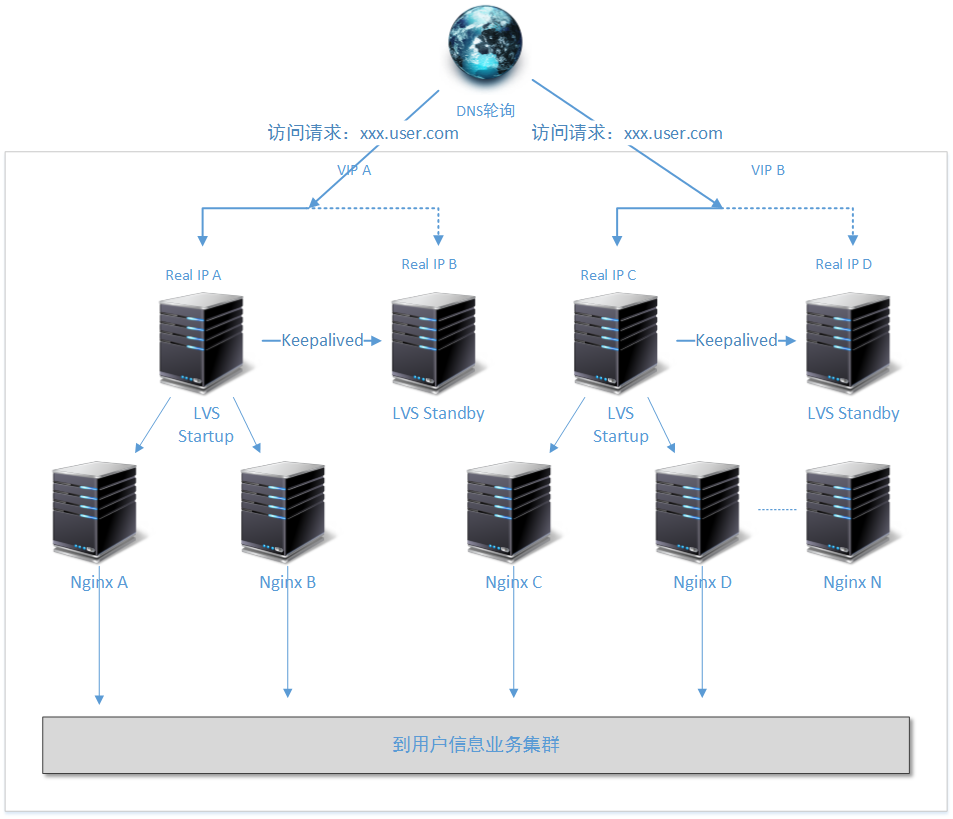
场景四中,为了满足平均上亿的日PV访问,在对业务进行外网暴露的基础上,我们在互联网的最前端做了一个DNS轮询。然后将(对用户信息系统)访问压力首先分摊到两个对称LVS组上,再由每个组向下继续分拆访问压力。
注意上图的负载层方案的不同:
- 首先我们不在像前面的方案中,使用目录名分割业务系统了,而是直接将业务系统的访问使用不同的二级域名进行拆分。这样的变化有利于每个业务系统都拥有自己独立的负载均衡层。
- 请注意上图中的细节,这个负载均衡层是专门为“用户信息子系统”提供负载均衡支撑的,而可能还存在的“订单子系统”、“车辆信息子系统”都会有他们独立的负载均衡层。
- 在LVS下方的Nginx服务可以实现无限制的扩展,同样的就像场景三种所给出的解决方案一样,Nginx本身不在需要Keepalived保持热备,而是全部交由上层的LVS进行健康情况检查。而即使有一两台Nginx服务器出现故障,对整个负载集群来说问题也不大。
方案扩展到了这一步,LVS层就没有必要再进行扩展新的节点了。为什么呢?根据您的业务选择的合适的LVS工作模式,两个LVS节点的性能足以支撑地球上的所有核心WEB站点。如果您对LVS的性能有疑惑,请自行谷歌百度。这里我们提供了一份参考资料:《LVS性能,转发数据的理论极限》http://www.zhihu.com/question/21237968
3、为什么没有独立的LVS方案
在下一篇文章《架构设计:负载均衡层设计方案(2)——LVS、keepalived、Nginx安装和核心原理解析》中我们将提到这个问题。实际上通过本篇文章的架构演进分析,一些读者都可以看出端倪。如果用一句话说明其中的原因,那就是LVS为了保证其性能对配置性有所牺牲,单独使用的话往往无法满足业务层对负载层灵活分配请求的要求。
4、说明
4.1、术语说明
- TPS: 衡量业务层处理性能的重要指标(每秒钟request/事务的处理数量)。业务服务处理一个完整的业务过程,并向上层返回处理结果的过程就是一个 request/事务。那么在一秒钟内整个业务系统能够完成多少个这样的过程,其衡量单位就是TPS。TPS不但和系统架构有很大的关系(特别是业务层和业务通信层的架构祥泰),和物理环境、代码质量的关系也非常密切。
- PV: 网页浏览数是评价网站流量最常用的指标之一,简称为PV。Page Views中的Page一般是指普通的html网页,也包含php、jsp等动态产生的html内容。注意是完整的显示一个Page成为一个PV。但是一个PV,一般需要多次HTTP请求,以便获取多个静态资源,这是需要注意的。
- UV: Unique Visitor 一个独立IP,在一个单位时间内(例如一日/一小时)对系统的一个PV请求,成为一个UV(重复的PV不在进行计数)。
- RUV: Repeat User Visitor 一个独立用户,在一个单位时间内(例如一日/一小时)对系统的一个PV请求,并且重复的访问要进行计数。
10.为什么用vector实现缓冲区,有没有想过别的数据结构
使用vector实现缓冲区的主要原因是其动态数组的特性。在缓冲区中,需要频繁地进行数据的插入和删除操作,而vector提供了高效的插入和删除元素的接口。此外,vector还能够动态调整内存大小,在需要时可以自动扩容,避免了手动管理内存空间带来的复杂性。
当然,在实现缓冲区时也可以考虑其他数据结构。例如:
- 队列:队列是一种先进先出(FIFO)的数据结构,在处理缓冲区时可以将队列作为底层数据结构。每次有新的数据加入时,将其添加到队列尾部;每次需要取出数据时,则从队列头部取出即可。
- 链表:链表是一种常用的线性数据结构,它通过指针将若干个节点串联起来。在处理缓冲区时,可以使用单向或双向链表来实现。每次有新的数据加入时,将其添加到链表尾部;每次需要取出数据时,则从链表头部取出即可。
- 栈:栈是一种后进先出(LIFO)的数据结构,在处理缓冲区时可以将栈作为底层数据结构。每次有新的数据加入时,将其添加到栈顶;每次需要取出数据时,则从栈顶取出即可。

 查看5道真题和解析
查看5道真题和解析