
面试八股文对校招的用处有多大?系统编程篇
前言
1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
系统编程
网络原理
网络编程
mysql
redis
服务器
RPG
本文为第六篇,后续会陆续更新。 共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接: https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i 需要的同学自取即可。
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
六、系统编程
01.除了MQ和websocket之外,你还能想到什么异步通信的办法?
除了MQ和WebSocket之外,异步通信的方法还有以下几种:
- HTTP长连接:客户端与服务端建立一次连接后保持长时间的连接,可以实现双向通信。
- Comet技术:在客户端发送请求到服务端后,服务端不会立即返回结果,而是等待事件发生或超时后再返回结果。
- AJAX轮询:客户端通过定时发送请求来获取最新数据,但这种方式会导致频繁的网络请求和资源浪费。
- SignalR:一个基于ASP.NET框架的开源库,支持服务器与客户端之间实时、双向通信。
- WebSocket+STOMP协议:使用WebSocket作为底层协议,并结合STOMP协议实现异步通信。 STOMP协议是一种简单的消息传递协议,可以使得客户端与服务器之间进行异步通信。
02.为什么要用多线程。多进程可以吗(webserver的)
》多线程是为了使得多个线程并行的工作以完成多项任务,以提高系统的效率。线程是在同一时间需要完成多项任务的时候被实现的。 使用线程的好处有以下几点: ·使用线程可以把占据长时间的程序中的任务放到后台去处理 ·用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度 ·程序的运行速度可能加快 ·在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较游泳了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
》在Windows中,进行CPU分配是以线程为单位的,一个进程可能由多个线程组成,这时情况更加复杂,但简单地说,有如下关系: 总线程数<= CPU数量:并行运行 总线程数> CPU数量:并发运行 并行运行的效率显然高于并发运行,所以在多CPU的计算机中,多任务的效率比较高。但是,如果在多CPU计算机中只运行一个进程(线程),就不能发挥多CPU的优势。
多任务操作系统(如Windows)的基本原理是:操作系统将CPU的时间片分配给多个线程,每个线程在操作系统指定的时 间片内完成(注意,这里的多个线程是分属于不同进程的).操作系统不断的从一个线程的执行切换到另一个线程的执行,如此往复,宏观上看来,就好像是多个线 程在一起执行.由于这多个线程分属于不同的进程,因此在我们看来,就好像是多个进程在同时执行,这样就实现了多任务.
进程间通讯(以下简称IPC)问题
既然不可能把整个系统放入一个进程,那就必然会碰到IPC的问题。下面就来说一下该如何选择IPC。
各种操作系统里面,有很多稀奇古怪的IPC类型。由于要考虑跨平台,首先砍掉一批(关于IPC的跨平台问题,我在“跨平台开发”系列中会提 到)。剩下的IPC类型中,能够进行数据传输的IPC就不多了,主要有如下几种:套接字(以下简称Socket)、共享内存、管道、文件。
其中Socket是我强烈推荐的IPC方式,理由如下:使用Socket可以天然地支持分布式部署;使用Socket可以比较容易地实现多种编 程语言的混合(比如C++、Java、Python、Flex都支持Socket);使用Socket还可以省掉了一大坨“锁操作”的代码。
列位看官中,或许有人在担心Socket的性能问题,其实大可不必多虑。当两个进程在本机上进行Socket通讯时,由于可以使用 localhost环回地址,数据不用经过物理网卡,操作系统内核还可以进行某些优化。这种情况下,Socket相对其它几种IPC机制,不会有太大的性 能偏差。
最后再补充一下,Socket方式也可以有效防止扯皮问题。举个例子:张三写了一个进程A,李四写了一个进程B,进程A通过Socket方式发 数据给进程B。突然有一天,两个进程的通讯出故障了。然后张三就说是李四接收数据出错;李四就说张三发送数据出错。这时候怎么办捏?很简单,随便找个 Sniffer软件当场抓一下数据包并Dump出来看,问题就水落石出了。
为啥还要线程?
上面说了这么多进程的好处,有同学要问了:“那线程有什么用捏?”总的来说,使用线程出于两方面的考虑:性能因素和编码方便。
1、性能因素
由于某些操作系统(比如Windows)中的进程比较重型,如果频繁创建进程或者创建大量进程,会导致操作系统的负载过高。举例如下:
假设你要开发一个类似Web Server的应用。你针对每一个客户端请求创建一个对应的进程用于进行数据交互(是不是想起了古老的CGI :-)。一旦这个系统扩容,用户的并发连接数一增加,你的应用立马死翘翘。
上面的例子表明,跨平台软件系统的进程数要保持相对稳定。如果你的进程数会随着某些环境因素呈线性增长,那就相当不妙了(顺带说一下,如果线程数会随着环境因素呈线性增长,也相当不妙)。而根据业务逻辑的单元划分进程,顺便能达到“进程数的相对稳定”的效果。
2、编码方面
由于业务逻辑内部的数据耦合比较紧密。如果业务逻辑内部的并发也用进程来实现,可能会导致大量的IPC编码(任意两个进程之间只要有数据交互,就得写一坨IPC代码)。这或许会让相关的编程人员怨声载道。
当然,编码方面的问题也不是绝对的。假如你的系统有很成熟且方便易用的IPC库,可以比较透明地封装IPC相关操作,那这方面的问题也就不存在了。
关于多进程和多线程,教科书上最经典的一句话是“进程是资源分配的最小单位,线程是CPU调度的最小单位”,这句话应付考试基本上够了,但如果在工作中遇到类似的选择问题,那就没有这么简单了,选的不好,会让你深受其害。
经常在网络上看到有的XDJM问“多进程好还是多线程好?”、“Linux下用多进程还是多线程?”等等期望一劳永逸的问题,我只能说:没有最好,只有更好。根据实际情况来判断,哪个更加合适就是哪个好。
我们按照多个不同的维度,来看看多线程和多进程的对比(注:因为是感性的比较,因此都是相对的,不是说一个好得不得了,另外一个差的无法忍受)。
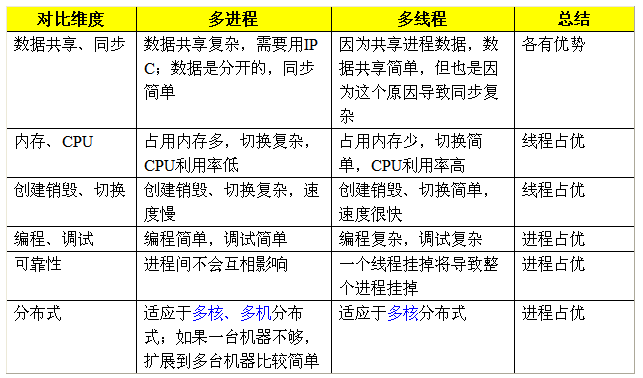
》多进程和多线程:没有绝对的好与坏,只有哪个更加合适的问题。我们来看实际应用中究竟如何判断更加合适。
1)需要频繁创建销毁的优先用线程 原因请看上面的对比。 这种原则最常见的应用就是Web服务器了,来一个连接建立一个线程,断了就销毁线程,要是用进程,创建和销毁的代价是很难承受的 2)需要进行大量计算的优先使用线程 所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。 这种原则最常见的是图像处理、算法处理。 3)强相关的处理用线程,弱相关的处理用进程 什么叫强相关、弱相关?理论上很难定义,给个简单的例子就明白了。 一 般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。 当然这种划分方式不是一成不变的,也可以根据实际情况进行调整。 4)可能要扩展到多机分布的用进程,多核分布的用线程 原因请看上面对比。 5)都满足需求的情况下,用你最熟悉、最拿手的方式 至于“数据共享、同步”、“编程、调试”、“可靠性”这几个维度的所谓的“复杂、简单”应该怎么取舍,我只能说:没有明确的选择方法。但我可以告诉你一个选择原则:如果多进程和多线程都能够满足要求,那么选择你最熟悉、最拿手的那个。 需要提醒的是:虽然我给了这么多的选择原则,但实际应用中基本上都是“进程+线程”的结合方式,千万不要真的陷入一种非此即彼的误区。
03.为什么要用线程池,线程池中的线程是怎么运作的?
1、为什么使用线程池?
线程池是运用场景最多的并发框架,几乎所有需要一步或者并发执行任务的程序都可以使用线程池。使用线程池一般有以下三个好处:
①降低资源的消耗,通过重复利用已经创建的线程降低线程创建和销毁造成的消耗。
②提高相应速度,当任务到达的时候,任务可以不需要等到线程创建就能立刻执行。
③提高线程的可管理性,线程是稀缺资源,使用线程池可以统一的分配、调优和监控。
2、线程池的实现原理
当线程池提交一个任务到线程池后,执行流程如下:
线程池先判断核心线程池里面的线程是否都在执行任务。如果不是都在执行任务,则创建一个新的工作线程来执行任务。如果核心线程池中的线程都在执行任务,则判断工作队列是否已满。如果工作队列没有满,则将新提交的任务存储到这个工作队列中,如果工作队列满了,线程池则判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理 ,也就是拒接策略。

具体:
(1)如果当前线程少于corePoolSize,就创建新的线程来执行任务,但是这一步会获取全局锁。
(2)如果当前运行的线程大于等于corePoolSize,则将任务加入BlockingQueue。
(3)如果无法将任务加入队列中, 队列已满的话,则创建新的线程处理任务。这一步需要全局锁。
(4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用 RejectedExecutionHandler.rejectedExecution()方法。
执行execute()方法时,尽可能 地避免获取全局锁。

线程池参数介绍:
1)corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线 程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任 务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法, 线程池会提前创建并启动所有基本线程。
2)runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几 个阻塞队列。
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原 则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通 常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用 移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工 厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
3)maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并 且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如 果使用了无界的任务队列这个参数就没什么效果。
4)ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设 置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线 程设置有意义的名字。
5)RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状 态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法 处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。
AbortPolicy:直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以, 如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。 ·TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟 (MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒 (NANOSECONDS,千分之一微秒)
04.生产者消费者,信号量的使用
生产者消费者问题是同步问题。有一个固定大小的缓冲区,生产者生产商品并将其输入缓冲区。消费者从缓冲区中删除项目并消费它们。
当消费者从缓冲区中消费商品时,生产者不应将商品生产到缓冲区中,反之亦然。因此,缓冲区只能一次由生产者或使用者访问。
生产者消费者问题可以使用信号量解决。生产者和消费者过程的代码如下:
1.生产者过程
下面给出了定义生产者流程的代码-
do {
.
. PRODUCE ITEM
.
wait(empty);
wait(mutex);
.
. PUT ITEM IN BUFFER
.
signal(mutex);
signal(full);
} while(1);
在上面的代码中,互斥,空和满是信号量。此处互斥锁初始化为1,empty初始化为n(缓冲区的最大大小),full初始化为0。
互斥信号量确保相互排斥。空和满信号量计算缓冲区中的空和满空间数量。
物料生产后,对空物料进行等待操作。这表明缓冲区中的空白空间已减少了1。然后对互斥量执行等待操作,以使使用者进程不会受到干扰。
将项目放入缓冲区后,对互斥锁和满载进行信号操作。前者指示使用者进程现在可以执行,而后者指示缓冲区已满1。
2.消费者流程
下面给出了定义使用者流程的代码:
do {
wait(full);
wait(mutex);
. .
. REMOVE ITEM FROM BUFFER
.
signal(mutex);
signal(empty);
.
. CONSUME ITEM
.
} while(1);
等待操作完全执行。这表明缓冲区中的项减少了1。然后对互斥量执行等待操作,以使生产者过程不会干扰。
然后将该项目从缓冲区中删除。之后,对互斥锁和空寄存器执行信号操作。前者指示使用者进程现在可以起作用,而后者指示缓冲区中的空白空间增加了1。
05.队列空时,消费者和生产者会发生什么?线程池请求队列是用什么实现的?(链表)
我们都了解线程池的作用,这里不多做赘述。
首先来看线程池的构造函数:
public ThreadExecutor(int corePoolSize, //线程池中的线程数
int maximumPoolSize, //线程池中的最大线程数
long keepAliveTime, //线程数超过指定数值后,多余的空闲线程的存活时间
TimeUnit unit, //线程池维护线程所允许的空闲时间的单位
BlockingQueue<Runnable> workQueue, //被提交但未被执行的任务等待队列
ThreadFactory threadFactory, //线程工厂,用于创建线程
RejectedExecutionHandler handler) //拒绝策略,当提交的任务太多,不够线程处理后,如何拒绝任务
我们看到线程池构造函数有7个参数,参数的作用如上图注释。
线程池中维护的任务队列有许多不同功能的实现,今天我们学习以下四种:
1.直接提交队列:使用的是SynchronousQueue实现的队列。提交到这个队列的任务不是真的保存在队列中,而是立即将任务提交给线程执行,如果线程池中没有线程,则立即创建线程执行,如果线程池中线程数大于最大线程数,则会执行拒绝策略,任务拒绝执行。
2.有界的任务队列: 使用的是ArrayBlockingQueue实现的队列。按照先进先出的算法处理任务。使用它时必须设定一个最大容量参数,当有任务提交到线程池中,首先判断线程池中线程数如果小于核心线程数,则立即创建新线程执行任务,若大于核心线程数则将任务提交到任务队列。如果任务队列满了,再创建新的线程执行任务。直到线程数达到最大线程数。
3.无界任务队列:使用的是LinkedBlockingQueue实现的队列。按照先进先出的算法处理任务。使用时和有界队列正好相反,任务队列没有固定容量,如果线程池中线程大于核心线程数,会将任务一直提交到任务队列,直到内存耗尽。
4.无界优先任务队列:PriorityBlockingQueue实现的队列。不是按照先进先出的算法执行,而是按照任务的优先级进行执行。
如何实现不同功能的线程池的呢?
1.newFixedThreadPool 固定线程数线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
我们看到,ThreadPoolExecutor的构造函数,核心线程数和最大线程数被设置成大小一样,第三个参数,线程存活时间设置成0L,意思是当线程池中有线程空闲时,立刻被停止。第四个参数,使用无界队列作为任务队列,意思是当线程数大于核心线程数时,提交到任务队列,直到内存耗尽。
2.newSingleThreadExecutor 单线程线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
ThreadPoolExecutor的构造函数,核心线程数和最大线程数被设置成1,线程存活时间0L,无界任务队列。保证只有一个线程工作。
3.newCachedThreadExecutor 可缓存线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以看到核心线程数为0,最大线程数无穷大,存活时间60L,任务队列是直接提交队列。如果线程池中没有空闲线程,将任务提交到任务队列,直接创建线程去执行,如果空闲60s,由于核心线程数为0,则会被回收。
06.C++多线程并发问题(场景千万级数量级怎么处理)
C++11标准在标准库中为多线程提供了组件,这意味着使用C++编写与平台无关的多线程程序成为可能,而C++程序的可移植性也得到了有力的保证。另外,并发编程可提高应用的性能,这对对性能锱铢必较的C++程序员来说是值得关注的。
1. 何为并发
并发指的是两个或多个独立的活动在同一时段内发生。生活中并发的例子并不少,例如在跑步的时候你可能同时在听音乐;在看电脑显示器的同时你的手指在敲击键盘。这时我们称我们大脑并发地处理这些事件,只不过我们大脑的处理是有次重点的:有时候你会更关注你呼吸的频率,而有时候你更多地被美妙的音乐旋律所吸引。这时我们可以说大脑是一种并发设计的结构。这种次重点在计算机程序设计中,体现为某一个时刻只能处理一个操作。
与并发相近的另一个概念是并行。它们两者存在很大的差别。并行就是同时执行,计算机在同一时刻,在某个时间点上处理两个或以上的操作。判断一个程序是否并行执行,只需要看某个时刻上是否多两个或以上的工作单位在运行。一个程序如果是单线程的,那么它无法并行地运行。利用多线程与多进程可以使得计算机并行地处理程序(当然 ,前提是该计算机有多个处理核心)。
- 并发:同一时间段内可以交替处理多个操作:
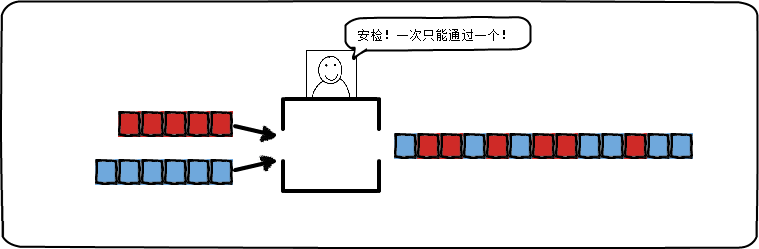
图中整个安检系统是一个并发设计的结构。两个安检队列队首的人竞争这一个安检窗口,两个队列可能约定交替着进行安检,也可能是大家同时竞争安检窗口(通信)。后一种方式可能引起冲突:因为无法同时进行两个安检操作。在逻辑上看来,这个安检窗口是同时处理这两个队列。
- 并行:同一时刻内同时处理多个操作:
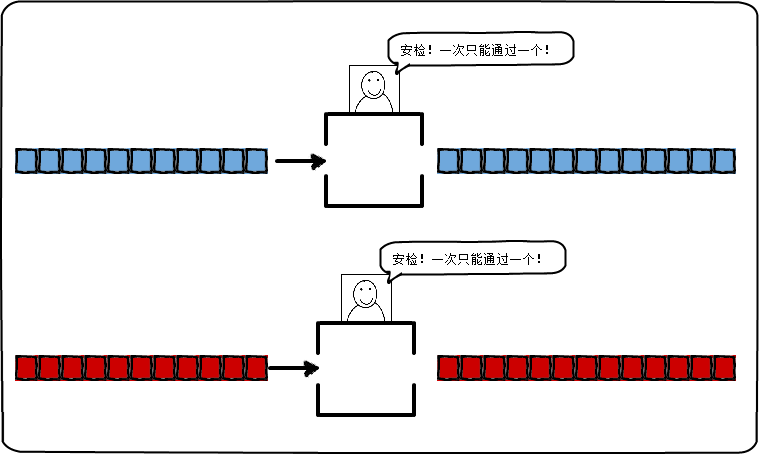
图中整个安检系统是一个并行的系统。在这里,每个队列都有自己的安检窗口,两个队列中间没有竞争关系,队列中的某个排队者只需等待队列前面的人安检完成,然后再轮到自己安检。在物理上,安检窗口同时处理这两个队列。
并发的程序设计,提供了一种方式让我们能够设计出一种方案将问题(非必须地)并行地解决。如果我们将程序的结构设计为可以并发执行的,那么在支持并行的机器上,我们可以将程序并行地执行。因此,并发重点指的是程序的设计结构,而并行指的是程序运行的状态。并发编程,是一种将一个程序分解成小片段独立执行的程序设计方法。
2.并发的基本方式途径
多线程与多进程是并发的两种途径。 想象两个场景:
- 场景一:你和小伙伴要开发一个项目,但小伙伴们放寒假都回家了,你们只能通过QQ聊天、手机通话、发送思维导图等方式来进行交流,总之你们无法很方便地进行沟通。好处是你们各自工作时可以互不打扰。
- 场景二:你和小伙伴放假都呆在学校实验室中开发项目,你们可以聚在一起使用头脑风暴,可以使用白板进行观点的阐述,总之你们沟通变得更方便有效了。有点遗憾的是你在思考时可能有小伙伴过来问你问题,你受到了打扰。
这两个场景描绘了并发的两种基本途径。每个小伙伴代表一个线程,工作地点代表一个处理器。场景一中每个小伙伴是一个单线程的进程,他们拥有独立的处理器,多个进程同时执行;场景二中只有一个处理器,所有小伙伴都是属于同一进程的线程。
2.1 多进程并发
多个进程独立地运行,它们之间通过进程间常规的通信渠道传递讯息(信号,套接字,文件,管道等),这种进程间通信不是设置复杂就是速度慢,这是因为为了避免一个进程去修改另一个进程,操作系统在进程间提供了一定的保护措施,当然,这也使得编写安全的并发代码更容易。 运行多个进程也需要固定的开销:进程的启动时间,进程管理的资源消耗。
2.2 多线程并发
在当个进程中运行多个线程也可以并发。线程就像轻量级的进程,每个线程相互独立运行,但它们共享地址空间,所有线程访问到的大部分数据如指针、对象引用或其他数据可以在线程之间进行传递,它们都可以访问全局变量。进程之间通常共享内存,但这种共享通常难以建立且难以管理,缺少线程间数据的保护。因此,在多线程编程中,我们必须确保每个线程锁访问到的数据是一致的。
3. C++中的并发与多线程
C++标准并没有提供对多进程并发的原生支持,所以C++的多进程并发要靠其他API——这需要依赖相关平台。 C++11 标准提供了一个新的线程库,内容包括了管理线程、保护共享数据、线程间的同步操作、低级原子操作等各种类。标准极大地提高了程序的可移植性,以前的多线程依赖于具体的平台,而现在有了统一的接口进行实现。
C++11 新标准中引入了几个头文件来支持多线程编程:(所以我们可以不再使用 CreateThread 来创建线程,简简单单地使用 std::thread 即可。)
- < thread > :包含std::thread类以及std::this_thread命名空间。管理线程的函数和类在 中声明.
- < atomic > :包含std::atomic和std::atomic_flag类,以及一套C风格的原子类型和与C兼容的原子操作的函数。
- < mutex > :包含了与互斥量相关的类以及其他类型和函数
- < future > :包含两个Provider类(std::promise和std::package_task)和两个Future类(std::future和std::shared_future)以及相关的类型和函数。
- < condition_variable > :包含与条件变量相关的类,包括std::condition_variable和std::condition_variable_any。
3.1 初试多线程
1、主进程等待子线程
#include <iostream>``#include <thread>``#include <Windows.h>`` ` `using` `namespace` `std;`` ` `void` `thread01()``{`` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Thread 01 is working !"` `<< endl;`` ``Sleep(100);`` ``}``}``void` `thread02()``{`` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Thread 02 is working !"` `<< endl;`` ``Sleep(200);`` ``}``}`` ` `int` `main()``{`` ``thread` `task01(thread01);`` ``thread` `task02(thread02);`` ``task01.join();`` ``task02.join();`` ` ` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Main thread is working !"` `<< endl;`` ``Sleep(200);`` ``}`` ``system``(``"pause"``);``}
2.主进程和子进程互不干扰
#include <iostream>``#include <thread>``#include <Windows.h>`` ` `using` `namespace` `std;`` ` `void` `thread01()``{`` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Thread 01 is working !"` `<< endl;`` ``Sleep(100);`` ``}``}``void` `thread02()``{`` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Thread 02 is working !"` `<< endl;`` ``Sleep(200);`` ``}``}`` ` `int` `main()``{`` ``thread` `task01(thread01);`` ``thread` `task02(thread02);`` ``task01.detach();`` ``task02.detach();`` ` ` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Main thread is working !"` `<< endl;`` ``Sleep(200);`` ``}`` ``system``(``"pause"``);``}
3.带参数的子线程
#include <iostream>``#include <thread>``#include <Windows.h>`` ` `using` `namespace` `std;`` ` `//定义带参数子线程``void` `thread01(``int` `num)``{`` ``for` `(``int` `i = 0; i < num; i++)`` ``{`` ``cout << ``"Thread 01 is working !"` `<< endl;`` ``Sleep(100);`` ``}``}``void` `thread02(``int` `num)``{`` ``for` `(``int` `i = 0; i < num; i++)`` ``{`` ``cout << ``"Thread 02 is working !"` `<< endl;`` ``Sleep(200);`` ``}``}`` ` `int` `main()``{`` ``thread` `task01(thread01, 5); ``//带参数子线程`` ``thread` `task02(thread02, 5);`` ``task01.detach();`` ``task02.detach();`` ` ` ``for` `(``int` `i = 0; i < 5; i++)`` ``{`` ``cout << ``"Main thread is working !"` `<< endl;`` ``Sleep(200);`` ``}`` ``system``(``"pause"``);``}
4.多线程竞争的情况
有两个问题,一是有很多变量被重复输出了,而有的变量没有被输出;二是正常情况下每个线程输出的数据后应该紧跟一个换行符,但这里大部分却是另一个线程的输出。
这是由于第一个线程对变量操作的过程中,第二个线程也对同一个变量进行各操作,导致第一个线程处理完后的输出有可能是线程二操作的结果。针对这种数据竞争的情况,可以使用线程互斥对象mutex保持数据同步。
mutex类的使用需要包含头文件mutex:
#include <iostream>``#include <thread>``#include <Windows.h>``#include <mutex>`` ` `using` `namespace` `std;`` ` `mutex mu; ``//线程互斥对象`` ` `int` `totalNum = 100;`` ` `void` `thread01()``{`` ``while` `(totalNum > 0)`` ``{`` ``mu.lock(); ``//同步数据锁`` ``cout << totalNum << endl;`` ``totalNum--;`` ``Sleep(100);`` ``mu.unlock(); ``//解除锁定`` ``}``}``void` `thread02()``{`` ``while` `(totalNum > 0)`` ``{`` ``mu.lock();`` ``cout << totalNum << endl;`` ``totalNum--;`` ``Sleep(100);`` ``mu.unlock();`` ``}``}`` ` `int` `main()``{`` ``thread` `task01(thread01);`` ``thread` `task02(thread02);`` ``task01.detach();`` ``task02.detach();`` ``system``(``"pause"``);``}
3.2 在类中使用子线程的一个问题
当我们再类中使用子线程我们会发现,我们不能把初始函数设置为类的成员函数,必须要把成员函数设置成static类型的才可以,但是这有设计到一个问题,就是static的类成员函数不能调用非static的变量成员,下面是一个两全其美的方法:
thread` `sendtask(bind(&client::sendata, ``this``));``//其中client是类的名字
这样就可以解决我们的问题。
07.哪几种常见的 signal? SIGSEGV... -> 正常终止程序的信号?-> kill 进程,几号信号?
常见的信号有很多种,以下列举几种常见的:
- SIGSEGV:表示程序访问了无效的内存地址。
- SIGABRT:表示程序自己调用了abort()函数来终止程序。
- SIGINT:表示程序收到了中断信号(通常是由用户按下Ctrl+C发送的)。
- SIGTERM:表示程序收到了终止信号(通常是由kill命令发送的,默认为15号信号)。
- SIGKILL:表示强制杀死进程(无法被阻塞、处理或忽略),一般用于紧急情况。它会立即终止进程,不管进程是否正在执行任务。
- SIGPIPE:表示向已关闭的管道或Socket写数据时,系统会发送这个信号给进程,以提示进程该操作已失败。
正常终止程序可以通过exit()函数来实现,也可以使用return语句从main函数返回0来实现。kill进程使用kill命令,在Linux系统中默认发送15号信号(SIGTERM)。
08.什么情况下会使用静态变量
静态变量是指在程序运行期间只分配一次内存,并且在整个程序运行期间都存在的变量。通常情况下,我们会根据以下几种情况来使用静态变量:
- 需要在多个函数中共享同一个变量:由于局部变量的作用域只在当前函数中有效,因此如果需要在多个函数中共享同一个变量,则需要定义为全局变量或者静态变量。
- 需要保护变量不被修改:如果定义了一个全局变量,那么任何一个函数都可以修改它的值,这可能会导致出现难以调试的问题。而将该全局变量定义为static类型后,就可以保证该变量只能被定义所在的文件访问到,从而避免出现这种问题。
- 需要统计某些数据:有时候我们需要对某些数据进行统计(例如记录某个函数被调用的次数),则可以使用静态局部变量,在每次调用该函数时累加其值,从而达到统计目的。
- 为了提高效率:由于静态变量只会分配一次内存空间,并且不需要动态地分配和释放内存,因此相比于动态分配内存的方式,使用静态变量可以提高程序的效率和响应速度。
总之,静态变量在程序中有着广泛的应用场景,能够帮助我们更好地管理和使用变量。
09.多线程读写同一个静态变量你是怎么解决的
在多线程环境下,对于同一个静态变量的读写操作可能会产生数据竞争,因此需要采取相应的措施来解决这个问题。以下是一些可能的解决方案:
- 使用互斥锁:可以使用互斥锁来保护静态变量,在每次访问该变量时先获得锁,并在完成操作后释放锁。这样可以确保同时只有一个线程能够访问该变量,避免出现数据竞争问题。
- 使用原子操作:某些编程语言提供了原子操作(atomic operation)来保证对于某个共享变量的读写操作是不可分割的。在使用原子操作时,即使多个线程同时访问该变量也不会发生数据竞争问题。
- 避免共享状态:如果可能的话,尽量避免多个线程直接对同一个静态变量进行读写操作,而是通过其他方式实现各自之间的通信和协作。例如可以使用消息队列、管道等机制来传递数据。
总之,在处理多线程环境下的静态变量时需要格外小心,必须采取相应的措施来避免数据竞争和其他潜在的并发问题。
10.用过无锁编程吗,知道原子量吗
无锁编程是一种并发编程技术,通过避免使用传统的锁机制来实现线程安全。在无锁编程中,每个线程都可以独立地执行自己的操作,而不需要等待其他线程释放锁资源。这种方式可以提高程序的并发性能和可扩展性。
无锁编程通常涉及对共享数据进行原子化操作。原子化操作是指当多个线程同时访问同一个变量时,仅有一个线程能够修改该变量,并且在该线程修改期间其它线程不能够同时修改该变量。这样就保证了数据的一致性和正确性。
无锁编程常用于高并发场景下,例如网络服务器、数据库等需要处理大量请求的系统。与传统加锁机制相比,无锁编程可以减少竞争情况下所需等待的时间,从而提高程序的响应速度和吞吐率。
在实践中,无锁编程需要考虑一些细节问题以确保程序正确性和效率优化。例如,在选择适当的原子化操作时需要注意其复杂度和成本;在处理共享内存时需要注意内存屏障等问题;在使用原子化类型时要小心对其进行正确、有效的初始化等。
原子量是一种并发编程中的数据类型,能够确保多个线程同时访问同一个变量时,仅有一个线程能够修改该变量,并且在该线程修改期间其它线程不能够同时修改该变量。这样可以保证数据的一致性和正确性。
原子量通常是由硬件或操作系统提供支持的,能够实现基本的原子化操作,例如读、写、加、减等。在C++11标准中引入了std::atomic模板类来实现原子化操作,包括std::atomic, std::atomic, std::atomic等类型。
使用原子量进行并发编程时需要注意以下问题:
- 原子化操作应该尽可能地简单和快速,以避免因为过度竞争而导致程序效率下降;
- 在使用原子量时要小心处理内存屏障等问题;
- 原子化操作只能解决单个变量的问题,如果需要对多个变量进行原子化操作,则需要使用更高级别的同步机制;
- 在使用自定义类型进行原子化操作时,需要保证其正确、有效地初始化。