
面试八股文对校招的用处有多大?操作系统原理篇
前言
1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
操作系统
系统编程
网络原理
网络编程
mysql
redis
服务器
RPG
本文为第五篇,后续会陆续更新。 共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接: https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i 需要的同学自取即可。
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
五、操作系统原理
01.线程和进程的区别、应用场景
一. 两者区别
进程是分配资源的基本单位;线程是系统调度和分派的基本单位。 属于同一进程的线程,堆是共享的,栈是私有的。 属于同一进程的所有线程都具有相同的地址空间。
多进程的优点:
①编程相对容易:通常不需要考虑锁和同步资源的问题。 ②更强的容错性:比起多线程的一个好处是一个进程崩溃了不会影响其他进程。 ③有内核保证的隔离:数据和错误隔离。 对于使用如C/C++这些语言编写的本地代码,错误隔离是非常有用的:采用多进程架构的程序一般可以做到一定程度的自恢复;(master守护进程监控所有worker进程,发现进程挂掉后将其重启)。
多线程的优点:
①创建速度快,方便高效的数据共享 共享数据:多线程间可以共享同一虚拟地址空间;多进程间的数据共享就需要用到共享内存、信号量等IPC技术。 ②较轻的上下文切换开销:不用切换地址空间,不用更改寄存器,不用刷新TLB。 ③提供非均质的服务:如果全都是计算任务,但每个任务的耗时不都为1s,而是1ms-1s之间波动;这样,多线程相比多进程的优势就体现出来,它能有效降低“简单任务被复杂任务压住”的概率。
二. 应用场景
1. 多进程应用场景
nginx主流的工作模式是多进程模式(也支持多线程模型) 几乎所有的web server服务器服务都有多进程的,至少有一个守护进程配合一个worker进程,例如apached,httpd等等以d结尾的进程包括init.d本身就是0级总进程,所有你认知的进程都是它的子进程; chrome浏览器也是多进程方式。 (原因:①可能存在一些网页不符合编程规范,容易崩溃,采用多进程一个网页崩溃不会影响其他网页;而采用多线程会。②网页之间互相隔离,保证安全,不必担心某个网页中的恶意代码会取得存放在其他网页中的敏感信息。) redis也可以归类到“多进程单线程”模型(平时工作是单个进程,涉及到耗时操作如持久化或aof重写时会用到多个进程)
2. 多线程应用场景
线程间有数据共享,并且数据是需要修改的(不同任务间需要大量共享数据或频繁通信时)。 提供非均质的服务(有优先级任务处理)事件响应有优先级。 单任务并行计算,在非CPU Bound的场景下提高响应速度,降低时延。 与人有IO交互的应用,良好的用户体验(键盘鼠标的输入,立刻响应) 案例: 桌面软件,响应用户输入的是一个线程,后台程序处理是另外的线程:memcached
3. 选什么?
①需要频繁创建销毁的优先用线程(进程的创建和销毁开销过大) 这种原则最常见的应用就是Web服务器了,来一个连接建立一个线程,断了就销毁线程,要是用进程,创建和销毁的代价是很难承受的
②需要进行大量计算的优先使用线程(CPU频繁切换) 所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。 这种原则最常见的是图像处理、算法处理。
③强相关的处理用线程,弱相关的处理用进程 什么叫强相关、弱相关?理论上很难定义,给个简单的例子就明白了。 一般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。 当然这种划分方式不是一成不变的,也可以根据实际情况进行调整。
④可能要扩展到多机分布的用进程,多核分布的用线程
⑤都满足需求的情况下,用你最熟悉、最拿手的方式 至于“数据共享、同步”、“编程、调试”、“可靠性”这几个维度的所谓的“复杂、简单”应该怎么取舍,我只能说:没有明确的选择方法。但我可以告诉你一个选择原则:如果多进程和多线程都能够满足要求,那么选择你最熟悉、最拿手的那个。
02.多线程中各种锁,读写锁,互斥锁
在操作系统中,常见的锁类型包括:互斥锁(Mutex Lock)、读写锁(Read-Write Lock)、自旋锁(Spin Lock)、条件变量(Condition Variable)、信号量(Semaphore)递归锁(Recursive Lock)、屏障(Barrier)等。
1.互斥锁(Mutex Lock)
互斥锁(Mutex Lock)是一种常见的线程同步机制,用于保护共享资源在多线程环境下的互斥访问。它提供了两个基本操作:加锁(Lock)和解锁(Unlock)。
互斥锁的原理和实现方式可以有多种,常见的实现包括使用原子操作、互斥变量、硬件指令等。下面是一个常见的互斥锁实现原理的简要分析:
- 原子操作实现:原子操作是一种不可中断的操作,能够保证在多线程环境下的原子性。互斥锁的实现中,常用的原子操作是比较并交换(Compare and Swap,CAS)操作。具体实现中,互斥锁内部维护一个标志位,用于表示锁的状态。加锁操作通过原子的CAS操作将标志位从未锁定状态修改为锁定状态,如果修改成功则表示获取锁成功,否则需要重试。解锁操作将标志位恢复为未锁定状态。
- 互斥变量实现:互斥变量是一种特殊的变量,它具有原子性操作和线程同步的特性。互斥锁的实现中,互斥变量被用作一个标志位,用于表示锁的状态。加锁操作通过原子的测试和设置操作来获取互斥变量的值,如果互斥变量的值为未锁定状态,则将其设置为锁定状态,表示获取锁成功。解锁操作将互斥变量的值恢复为未锁定状态。
- 硬件指令实现:一些处理器架构提供了特定的硬件指令来支持互斥锁的实现。这些指令通常能够在单个指令级别上执行锁的加锁和解锁操作,具有较高的性能和效率。这些硬件指令可以保证锁的操作是原子的,从而实现线程的同步和互斥访问。
无论使用哪种具体的实现方式,互斥锁的目标都是保护共享资源的访问,使得在同一时刻只有一个线程能够访问共享资源,其他线程需要等待。互斥锁的加锁操作和解锁操作通常需要保证原子性,以避免多线程环境下的竞争条件和数据不一致的问题。
总结来说,互斥锁是一种常见的线程同步机制,用于实现多线程环境下共享资源的互斥访问。它的实现原理可以包括原子操作、互斥变量、硬件指令等方式,旨在保证对共享资源的原子性操作和线程的同步访问。
2.读写锁(Read-Write Lock)
读写锁(Read-Write Lock)是一种多线程同步机制,用于在读操作和写操作之间提供更好的并发性。读写锁允许多个线程同时进行读操作,但在写操作时需要独占访问。它包含两种状态:读模式和写模式。
读写锁的原理和实现方式可以有多种,下面是一个常见的读写锁实现原理的简要分析:
- 读优先的实现方式:在读写锁的实现中,维护一个计数器用于记录当前进行读操作的线程数量。当没有写操作时,读操作可以并发进行,读计数器递增。写操作需要独占访问,所以在进行写操作之前需要等待所有读操作结束,即读计数器为0。读操作和写操作之间的互斥访问可以通过互斥锁来实现。
- 写优先的实现方式:在读写锁的实现中,维护一个写标志位用于表示当前是否有进行写操作。当没有进行写操作时,读操作可以并发进行,读操作不会修改共享资源,所以是安全的。写操作需要独占访问,所以在进行写操作之前需要等待所有读操作结束,并设置写标志位。读操作和写操作之间的互斥访问可以通过互斥锁来实现。
无论是哪种具体的实现方式,读写锁的目标是提高读操作的并发性,允许多个线程同时进行读操作,并保证在写操作时的独占访问。读操作之间可以并发进行,但读操作和写操作之间需要互斥访问,以保证数据的一致性。
读写锁的选择和使用取决于具体的应用场景。如果读操作频繁且并发性要求较高,可以选择读优先的实现方式;如果写操作较为频繁且需要保证写操作的原子性和独占访问,可以选择写优先的实现方式。
总结来说,读写锁是一种多线程同步机制,用于在读操作和写操作之间提供更好的并发性。它的实现原理可以包括读优先和写优先两种方式,旨在实现读操作的并发访问和写操作的独占访问。
3.自旋锁(Spin Lock)
自旋锁(Spin Lock)是一种多线程同步机制,用于保护临界区代码,以防止多个线程同时访问共享资源。与互斥锁不同,自旋锁不会使线程进入阻塞状态,而是在获取锁时不断循环检查锁是否可用,直到获取到锁为止。
以下是自旋锁的详细原理分析:
- 初始化:自旋锁的初始状态为未锁定状态,可以理解为锁处于可用状态。
- 获取锁:当一个线程想要进入临界区代码时,它会尝试获取自旋锁。如果锁处于未锁定状态,线程可以立即获取锁,进入临界区执行操作。如果锁处于锁定状态,线程会进入自旋等待状态。
- 自旋等待:当一个线程发现自旋锁已经被其他线程锁定时,它会进入自旋等待状态。在自旋等待期间,线程会不断循环检查锁的状态是否变为可用。这里的循环是一个忙等待的过程,线程会一直占用CPU资源进行检查,直到锁被释放。
- 释放锁:当线程完成了临界区的操作,它会释放自旋锁,将锁的状态设置为未锁定状态,以允许其他线程获取锁。
自旋锁的优点是避免了线程的上下文切换和进程阻塞,适用于临界区的代码执行时间短、线程竞争不激烈的情况下。然而,自旋锁也存在一些缺点,例如在自旋等待期间,线程会占用CPU资源,导致其他线程无法执行,可能会造成资源浪费。因此,自旋锁适用于多核CPU上的多线程并发操作,其中线程等待锁的时间较短。
在实际应用中,自旋锁的实现可以依赖于底层硬件提供的原子操作指令,或者通过软件的方式实现。具体的实现方式可以根据操作系统和编程语言的不同而有所差异。
4.条件变量(Condition Variable)
条件变量(Condition Variable)是一种多线程同步机制,用于在多个线程之间进行通信和协调。它允许一个或多个线程等待某个条件满足后才继续执行,从而避免了线程的忙等待。
以下是条件变量的详细原理分析:
- 创建条件变量:在使用条件变量之前,需要先创建一个条件变量对象。条件变量通常与互斥锁配合使用,因此在创建条件变量之前,还需要创建一个互斥锁。
- 等待条件:当一个线程发现某个条件不满足时,它可以调用条件变量的等待函数来等待条件满足。等待函数会使线程进入阻塞状态,并释放之前持有的互斥锁,允许其他线程进入临界区。
- 条件满足时的唤醒:当某个线程改变了共享数据,使得某个条件满足时,它可以调用条件变量的唤醒函数来唤醒等待该条件的线程。被唤醒的线程会重新竞争互斥锁,获取锁后继续执行。
- 再次检查条件:被唤醒的线程在获取互斥锁后,会再次检查条件是否满足。如果条件仍然不满足,线程可能会继续等待或执行其他操作。
条件变量的原理是基于等待队列的机制。当一个线程调用等待函数时,它会将自己加入到条件变量的等待队列中,并释放互斥锁。当条件满足时,唤醒函数会从等待队列中选择一个或多个线程,并通知它们重新竞争互斥锁。
需要注意的是,条件变量的使用必须与互斥锁配合使用,以确保线程在等待条件和修改共享数据时的线程安全性。互斥锁用于保护共享数据的访问,条件变量用于等待和唤醒线程。
在实际应用中,条件变量的实现通常是由操作系统提供的,底层会使用原子操作或其他同步机制来实现等待和唤醒的过程。编程语言和操作系统的不同可能会导致条件变量的具体实现方式有所差异。
5.信号量(Semaphore)
信号量(Semaphore)是一种多线程同步机制,用于控制对共享资源的访问。它通过一个计数器和一组等待队列来实现对资源的控制。
以下是信号量的详细原理分析:
- 创建信号量:在使用信号量之前,需要先创建一个信号量对象,并初始化计数器的初始值。计数器表示可用资源的数量。
- 获取资源:当一个线程需要访问共享资源时,它会尝试获取信号量。如果信号量的计数器大于0,表示有可用资源,线程可以继续执行;如果计数器等于0,表示没有可用资源,线程需要进入等待状态。
- 释放资源:当一个线程使用完共享资源后,需要释放信号量,以便其他线程可以获取资源。释放操作会将计数器加1,并可能唤醒等待队列中的某个线程。
- 等待和唤醒:等待操作会将线程加入到信号量的等待队列中,并将线程置于阻塞状态。当信号量的计数器发生变化(释放资源或其他线程释放信号量)时,等待队列中的线程可能会被唤醒,重新竞争信号量。
信号量的原理是基于计数器和等待队列的机制。计数器用于记录可用资源的数量,等待队列用于保存等待访问资源的线程。获取信号量时,如果计数器大于0,则线程可以继续执行;否则,线程需要进入等待状态。释放信号量时,计数器会增加,并且可能唤醒等待队列中的某个线程。
需要注意的是,信号量并不限定只能有一个线程访问资源,可以通过适当设置计数器的初始值来控制并发访问的数量。
在实际应用中,信号量的实现通常由操作系统提供,底层可能会使用原子操作、互斥锁或其他同步机制来实现对计数器和等待队列的操作。编程语言和操作系统的不同可能会导致信号量的具体实现方式有所差异。
6.递归锁(Recursive Lock)
也称为可重入锁,是一种特殊类型的互斥锁。与普通的互斥锁不同,递归锁允许同一个线程多次获取该锁而不会造成死锁。 递归锁(Recursive Lock)是一种同步机制,允许同一个线程多次获取同一个锁而不会产生死锁。它允许线程在持有锁的情况下继续获取该锁,而不会被阻塞。
以下是递归锁的详细原理分析:
- 锁的获取:当一个线程尝试获取递归锁时,它会先检查锁的状态。如果锁当前没有被其他线程持有,线程可以成功获取锁,并将锁的状态设置为属于该线程。如果锁已经被当前线程持有,线程也可以成功获取锁,并将锁的状态计数器加1,表示该线程多次获取锁的次数。
- 锁的释放:当一个线程释放递归锁时,它会先检查锁的状态。如果锁的状态计数器大于1,表示该线程还持有锁,只需要将计数器减1即可。如果锁的状态计数器等于1,表示该线程是最后一个持有锁的线程,需要将锁的状态清空,并唤醒等待队列中的某个线程。
- 等待和唤醒:递归锁的等待和唤醒机制与其他锁的机制类似。当一个线程尝试获取已被其他线程持有的递归锁时,它会被放入等待队列中,并进入阻塞状态。当递归锁的状态被释放时,可能会唤醒等待队列中的某个线程,使其有机会再次尝试获取锁。
递归锁的原理是基于锁的状态和计数器的机制。锁的状态用于标识锁的持有者,计数器用于记录线程获取锁的次数。线程在获取锁时,会根据锁的状态和计数器来决定是否可以成功获取锁。在释放锁时,线程会根据计数器的值来判断是否需要真正释放锁,或者只是减少计数器的值。
递归锁的设计目的是解决同一个线程多次获取同一个锁的需求,避免死锁的发生。它允许线程在持有锁的情况下继续获取该锁,而不会被阻塞。但需要注意,递归锁的使用也需要谨慎,避免出现无限递归获取锁的情况,导致程序陷入死循环。
7.屏障(Barrier)
屏障(Barrier)是一种同步机制,用于确保多个线程在某个点上同步等待,并在满足条件时同时开始执行后续操作。屏障可以用于协调线程的执行顺序,确保线程在某个共同点上进行同步操作。
以下是屏障的详细原理分析:
- 创建屏障:在程序中,可以通过特定的屏障接口或函数来创建一个屏障。屏障通常与一个计数器相关联,用于追踪到达屏障点的线程数量。
- 线程到达屏障点:当线程到达屏障点时,它会通过屏障接口或函数来通知屏障。屏障会将到达的线程数量加1,并检查是否已经达到了预定的数量。
- 等待和同步:如果到达屏障点的线程数量还没有达到预定的数量,那么线程会被阻塞,等待其他线程到达屏障点。一旦到达的线程数量达到预定的数量,屏障会触发一个信号,通知所有等待的线程可以开始执行后续操作。
- 后续操作:一旦屏障触发信号,所有等待的线程会同时开始执行后续操作。这些操作可以是并行执行的,因为屏障保证了所有线程在同一个点上同步等待。
屏障的原理是基于计数器和同步机制。计数器用于追踪到达屏障点的线程数量,同步机制用于阻塞和唤醒线程,确保线程在达到预定数量时同时开始执行后续操作。
屏障的作用是在多线程环境中协调线程的执行顺序,确保线程在某个共同点上同步等待,并在满足条件时同时开始执行后续操作。它可以用于解决线程之间的同步问题,确保多个线程在某个关键点上进行同步操作,从而避免竞态条件和不确定性的结果。
03.内存池
1.前言
通常的进程发起申请内存的动作之后,会在系统的空闲内存区寻找合适大小的内存块(底层分配函数__alloc_node_mask),如果满足就直接分配,如果不满足就会向上查找。如果过大就会进行分裂,一部分分给申请进程,一部分放入空闲区。释放时需要找到这个块对应的伙伴,如果伙伴也为空闲,就进行合并,放入高阶空闲链表,如果不空闲就放入对应链表。同时对于多线程申请和释放内存,需要加锁。这样的默认的分配方式考虑到了系统中的大部分情况,具有通用性,但是无可避免的会产生内部碎片,而且加锁,解锁的开销也很大。
如果可以对特定进程设计适合他自己的内存管理方式,那么它的性能应该会有提升。
2.内存池
程序可以通过系统的内存分配方法预先分配一大块内存来做一个内存池,之后程序的内存分配和释放都由这个内存池来进行操作和管理,当内存池不足时再向系统申请内存。
我们通常使用malloc等函数来为用户进程分配内存。它的执行过程通常是由用户程序发起malloc申请内存的动作,在标准库找到对应函数,对不满128k的调用brk()系统调用来申请内存(申请的内存是堆区内存),接着由操作系统来执行brk系统调用。
我们知道malloc是在标准库,真正的申请动作需要操作系统完成。所以由应用程序到操作系统就需要3层。内存池是专为应用程序提供的专属的内存管理器,它属于应用程序层。所以程序申请内存的时候就不需要通过标准库和操作系统,明显降低了开销。
2.1 内存池的分类
对于线程安全来说,内存池可以分为单线程内存池和多线程内存池。单线程内存池整个生命周期只被一个线程使用,因而不需要考虑互斥访问的问题;多线程内存池有可能被多个线程共享,因此则需要在每次分配和释放内存时加锁。相对而言,单线程内存池性能更高,而多线程内存池适用范围更广。
从可分配内存大小来说,可以分为固定内存池和可变内存池。所谓固定内存池是指应用程序每次从内存池中分配出来的内存单元大小事先已经确定,是固定不变的;而可变内存池则每次分配的内存单元大小可以按需变化,应用范围更广,而性能比固定内存池要低。
2.2 内存池的工作原理
固定内存池的设计如图:
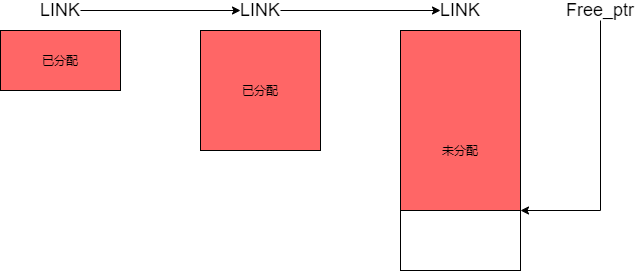
固定内存池的内存块实际上是由链表连接起来的,前一个总是后一个的2倍大小。当内存池的大小不够分配时,向系统申请内存,大小为上一个的两倍,并且使用一个指针来记录当前空闲内存单元的位置。当我们要需要一个内存单元的时候,就会随着链表去查看每一个内存块的头信息,如果内存块里有空闲的内存单元,将该地址返回,并且将头信息里的空闲单元改成下一个空闲单元。 当应用程序释放某内存单元,就会到对应的内存块的头信息里修改该内存单元为空闲单元。
2.3 线程安全
对于单线程来说,不需要考虑互斥访问的问题,但是对于多线程来说内存池可能会被多个线程共享,所以需要给内存池加上一个锁,来进行保护。
如果出现程序中有大量线程申请释放内存,那么这种方案下锁的竞争将会非常激烈,线程这样的场景下使用该方案不会有很好的性能。
所以就有了一种方法的诞生----------->TLS线程本地存储(线程局部存储)。
TLS的作用是能将数据和执行的特定的线程联系起来。它可以让程序中由所有线程使用的全局变量,都产生自己的副本。也就是这个变量每个线程都有自己的私有,它们之间的操作互不干扰,不会影响。
在这样的背景下,我们可以设计出线程本地存储+内存池的方式,这样线程都有了自己的内存池,且彼此之间不会产生影响,也就不需要加锁。
2.4 内存池的设计
提前创建
假设服务器程序比较简单,处理请求的时候只使用一种对象,提前创建出一些需要的对象,比如数据结构,我们可以用的时候拿出来,不用的时候还回去就可以,只需要标记使用的和未使用的。这种比较简单。
可申请不同大小的内存
这种方法使得用户程序在请求过程中只申请内存,之后当处理完请求之后才一次性释放所有内存,这样可以降低内存申请和释放的开销,而且能减少内部碎片。
除了这两种还有其他的设计方法,可以自己设计。
因为内存池并不是一种通用的内存管理模式,它是一种比较特定的,固定某种场景去使用,属于私人定制。
3.linux内存池
在内核中有不少地方内存分配不允许失败。内存池作为一个在这些情况下确保分配的方式,内核开发者创建了一个已知为内存池(或者是 “mempool” )的抽象,内核中内存池真实地只是相当于后备缓存,它尽力一直保持一个空闲内存列表给紧急时使用,而在通常情况下有内存需求时还是从公共的内存中直接分配,这样的做法虽然有点霸占内存的嫌疑,但是可以从根本上保证关键应用在内存紧张时申请内存仍然能够成功。
3.1 数据结构
typedef struct mempool_s {
spinlock_t lock; /*保护内存池的自旋锁*/
int min_nr; /*内存池中最少可分配的元素数目*/
int curr_nr; /*尚余可分配的元素数目*/
void **elements; /*指向元素池的指针*/
void *pool_data; /*内存源,即池中元素真实的分配处*/
mempool_alloc_t *alloc; /*分配元素的方法*/
mempool_free_t *free; /*回收元素的方法*/
wait_queue_head_t wait; /*被阻塞的等待队列*/
} mempool_t;
内存池的创建函数mempool_create
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data)
{
return mempool_create_node(min_nr,alloc_fn,free_fn, pool_data,-1);
}
这个函数指定了,内存池大小,分配方法,释放发法,分配源。创建完成之后,会从分配源(pool_data)中分配内存池大小(min_nr)个元素来填充内存池。
内存池的释放函数mempool_destory
void mempool_destroy(mempool_t *pool)
{
while (pool->curr_nr) {
void *element = remove_element(pool);
pool->free(element, pool->pool_data);
}
kfree(pool->elements);
kfree(pool);
}
他是依次将元素对象从池中移除,再释放给pool_data,最后释放池对象。
内存池分配对象的函数:mempool_alloc。mempool_alloc的作用是从指定的内存池中申请/获取一个对象。
void *mempool_alloc(mempool_t *pool, gfp_t gfp_mask)
{
void *element;
unsigned long flags;
wait_queue_entry_t wait;
gfp_t gfp_temp;
VM_WARN_ON_ONCE(gfp_mask & __GFP_ZERO);
might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);
gfp_mask |= __GFP_NOMEMALLOC; /* don't allocate emergency reserves */
gfp_mask |= __GFP_NORETRY; /* don't loop in __alloc_pages */
gfp_mask |= __GFP_NOWARN; /* failures are OK */
gfp_temp = gfp_mask & ~(__GFP_DIRECT_RECLAIM|__GFP_IO);
repeat_alloc:
element = pool->alloc(gfp_temp, pool->pool_data);//先从后备源中申请内存
if (likely(element != NULL))
return element;
spin_lock_irqsave(&pool->lock, flags);
if (likely(pool->curr_nr)) {
element = remove_element(pool);/*从内存池中提取一个对象*/
spin_unlock_irqrestore(&pool->lock, flags);
/* paired with rmb in mempool_free(), read comment there */
smp_wmb();
/*
* Update the allocation stack trace as this is more useful
* for debugging.
*/
kmemleak_update_trace(element);
return element;
}
/*
* We use gfp mask w/o direct reclaim or IO for the first round. If
* alloc failed with that and @pool was empty, retry immediately.
*/
if (gfp_temp != gfp_mask) {
spin_unlock_irqrestore(&pool->lock, flags);
gfp_temp = gfp_mask;
goto repeat_alloc;
}
/* We must not sleep if !__GFP_DIRECT_RECLAIM */
if (!(gfp_mask & __GFP_DIRECT_RECLAIM)) {
spin_unlock_irqrestore(&pool->lock, flags);
return NULL;
}
/* Let's wait for someone else to return an element to @pool */
init_wait(&wait);
prepare_to_wait(&pool->wait, &wait, TASK_UNINTERRUPTIBLE);//加入等待队列
spin_unlock_irqrestore(&pool->lock, flags);
/*
* FIXME: this should be io_schedule(). The timeout is there as a
* workaround for some DM problems in 2.6.18.
*/
io_schedule_timeout(5*HZ);
finish_wait(&pool->wait, &wait);
goto repeat_alloc;
}
EXPORT_SYMBOL(mempool_alloc);
函数先从后备源中申请内存,当从后备源无法成功申请到时,才会从内存池中申请内存使用,因此可以发现内核内存池(mempool)其实是一种后备池,在内存紧张的情况下才会真正从池中获取,这样也就能保证在极端情况下申请对象的成功率,但也不一定总是会成功,因为内存池的大小毕竟是有限的,如果内存池中的对象也用完了,那么进程就只能进入睡眠,也就是被加入到pool->wait的等待队列,等待内存池中有可用的对象时被唤醒,重新尝试从池中申请元素。
内存池回收对象的函数:mempool_free
void mempool_free(void *element, mempool_t *pool)
{
unsigned long flags;
if (unlikely(element == NULL))
return;
/*
* Paired with the wmb in mempool_alloc(). The preceding read is
* for @element and the following @pool->curr_nr. This ensures
* that the visible value of @pool->curr_nr is from after the
* allocation of @element. This is necessary for fringe cases
* where @element was passed to this task without going through
* barriers.
*
* For example, assume @p is %NULL at the beginning and one task
* performs "p = mempool_alloc(...);" while another task is doing
* "while (!p) cpu_relax(); mempool_free(p, ...);". This function
* may end up using curr_nr value which is from before allocation
* of @p without the following rmb.
*/
smp_rmb();
/*
* For correctness, we need a test which is guaranteed to trigger
* if curr_nr + #allocated == min_nr. Testing curr_nr < min_nr
* without locking achieves that and refilling as soon as possible
* is desirable.
*
* Because curr_nr visible here is always a value after the
* allocation of @element, any task which decremented curr_nr below
* min_nr is guaranteed to see curr_nr < min_nr unless curr_nr gets
* incremented to min_nr afterwards. If curr_nr gets incremented
* to min_nr after the allocation of @element, the elements
* allocated after that are subject to the same guarantee.
*
* Waiters happen iff curr_nr is 0 and the above guarantee also
* ensures that there will be frees which return elements to the
* pool waking up the waiters.
*/
if (unlikely(pool->curr_nr < pool->min_nr)) {
spin_lock_irqsave(&pool->lock, flags);
if (likely(pool->curr_nr < pool->min_nr)) {//当前可分配的是否小于内存大小,
add_element(pool, element);
spin_unlock_irqrestore(&pool->lock, flags);
wake_up(&pool->wait);
return;
}
spin_unlock_irqrestore(&pool->lock, flags);
}
pool->free(element, pool->pool_data);
}
EXPORT_SYMBOL(mempool_free);
其实原则跟mempool_alloc是对应的,释放对象时先看池中的可分配元素如果小于池中最少的可分配元素,那么久需要把元素放到内存池中。相反就要把它放到后备源中。
4.总结
用户程序的内存池通常是特殊的,适用于特定场景的专属内存管理法。内核态的内存池则是保证系统中的一些关键应用在内存紧缺的时候确保能够申请内存成功。他们的用途不同,但是做法确是如出一辙。
04.内存管理
1.为什么要进行内存管理?
计算机内存虽然速度较快,但由于容量限制(一般8-32GB),不能一次性将所有的用户进程和系统程序全部装入内存,因此操作系统必须对内存空间进行合理的划分和有效的动态分配。
2.内存管理的主要功能:
- 地址转换:将程序中的逻辑地址转换成内存中的物理地址(抽象)
- 存储保护:保证个个作业在自己的内存空间内运行,互不干扰(保护)
- 内存的分配与回收:当作业或进程创建后系统会为他们分配内存空间,当结束后内存空间也会被回收。
- 内存空间的扩充:利用虚拟存储技术或自动覆盖技术,从逻辑上扩充内存(虚拟化)
- 进程间通信(共享)
3.内存分配的两种方式
3.1 连续分配方式
连续分配方式是指为一个进程分配一个连续的内存空间;
连续分配方式主要包括单一连续分配、固定分区分配和动态分区分配。
3.1.1 单一连续分配
整个内存直接交由一个程序独占,当其他程序需要使用的时候,需要覆盖(Overlay)整个内存,即一次只能运行一个程序;
优点:简单高效,无外部碎片。 缺点:可能存在大量内部碎片,内存利用率低,且只能用于单用户。
3.1.2 固定分区分配
将用户内存空间划分为若干固定大小的区域,每个区域只装入一个进程。
- 优点:程序可能太大放入不了任何一个分区。
- 缺点:程序太小独占一个分区,造成内部碎片。
3.1.3 动态分区分配
在程序装入内存时,根据进程的大小动态地建立分区,并使得分区的大小正好适合进程的需要,因此系统中分区的大小和数目是可变的。
- 优点:一开始内存利用率较高。
- 缺点:随着时间推移,内存中会产生越来越多的小的内存块,内存的利用率也随之下降,这些碎片成为外部碎片。操作系统可以通过对进程进行碎片整理来解决碎片问题。
3.2 离散分配方式
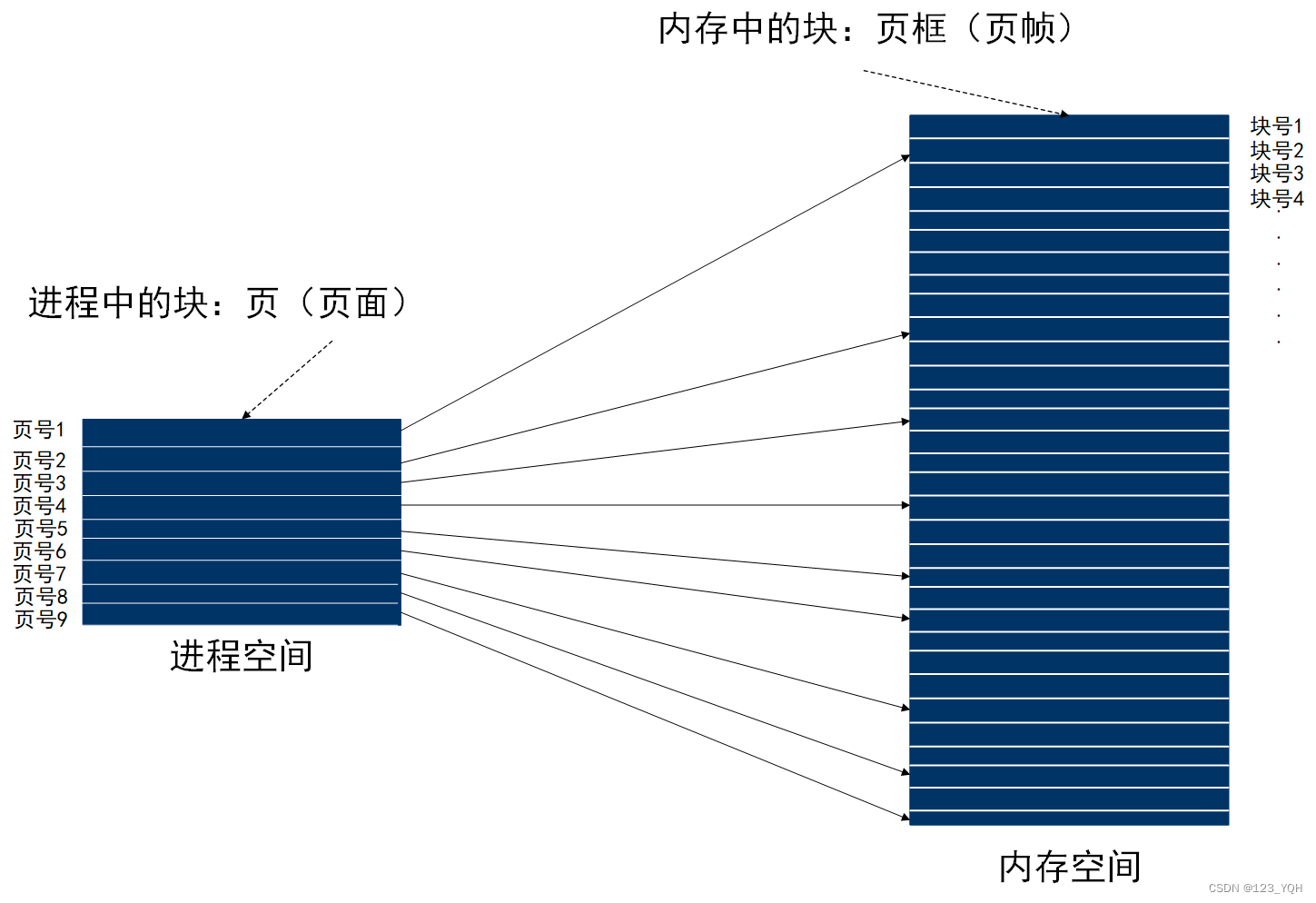
由于连续分配方式会形成许多内存碎片,内存使用率极低;从而产生了离散分配方式,即将一个进程分散地装入到许多不相邻的内存分区中。把主存空间划分为大小相等且固定地块,块相对较小,作为主存地基本单位。每个进程以块为单位进行划分,进程在执行时,以块为单位逐个申请主存中地块空间。
3.2.1 分页存储(页式存储)
3.2.1.1 基本概念
- 进程中的块:页或页面
- 页或页面的编号:页号
- 内存中的块:页框或页帧
- 页框的编号:块号或页帧号
- 页表:每个进程页号对应块号的映射表
- 页表项:页号 + 块号
- 逻辑地址:页号 + 页内偏移量
- 物理地址:块号 + 块内偏移量
- 块的大小=页的大小,所以块内偏移量=页内偏移量
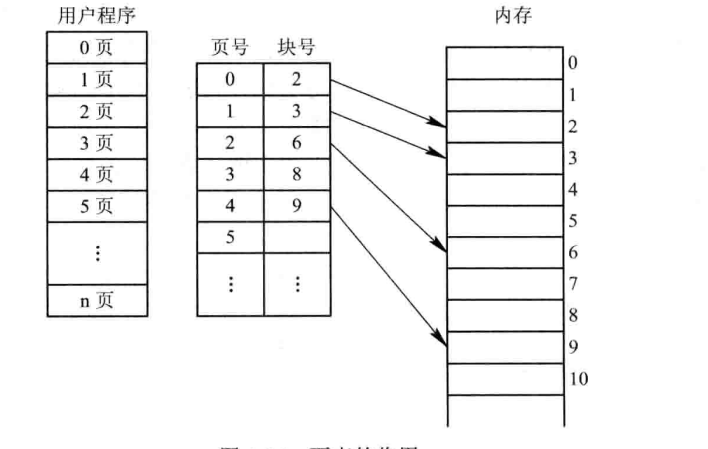
3.2.1.2 逻辑地址转换为物理地址
- 根据页面大小(4K)可计算出页内地址的位数(4k=2的12次方,二进制位数是12位,等同于十六进制是3位)
- 页内地址位数(3位十六进制)结合逻辑地址(5148H)计算出页内地址(148H)和页号(5H)
- 页号结合页表,即可得出块号(假设页号5对应的块号7)
- 块号(7H)+ 块内地址(等于页内地址,即148H)= 物理地址(7148H)
3.2.2 分段存储(段式存储)
逻辑空间分为若干个段,每个段定义了一组有完整逻辑意义的信息(如主程序段、子程序段、数据段等),段长度不等
3.2.2.1 基本概念
- 逻辑地址:(段号, 段内偏移量),(0,30)
- 物理地址:(基址,段内地址),(40,70)
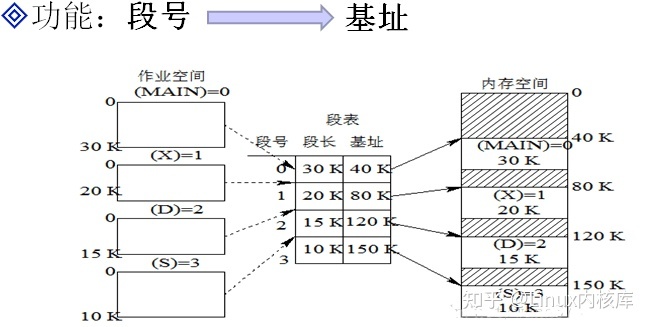
3.2.2.2 地址映射
- 根据段号从段表中找到段长和基址
- 判断段内偏移量是否小于段长
- 根据基址和段长计算出物理地址
3.2.2.3 分段与分页的区别
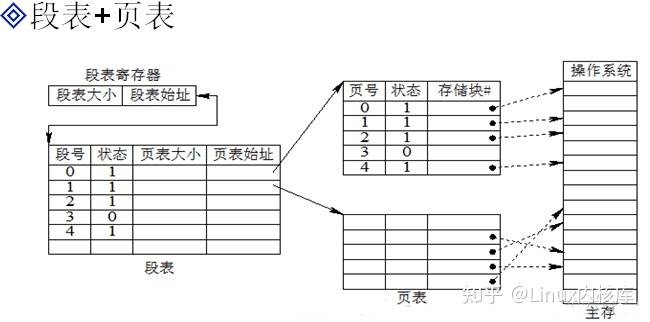
3.2.3 段页式存储
综合分段和分页存储方式,先按逻辑结构分段,再将每个段分页。
地址结构
地址映射
- 逻辑地址----- >(段号、段内页号、页内地址)
- 段表寄存器--- >段表始址
- 段号+段表始址---- >页表始址
- 页表始址+段内页号----->存储块号
- 块号+页内地址------>物理地址
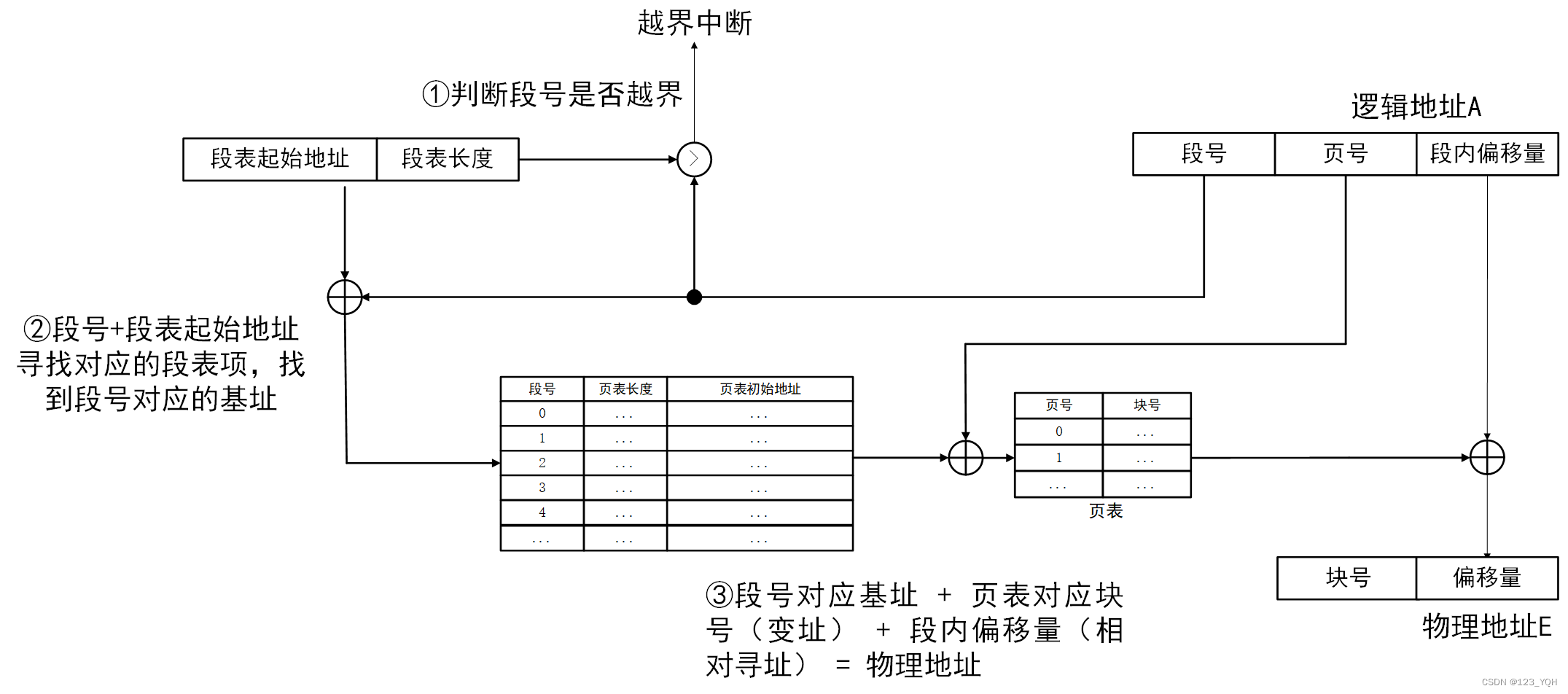
- 在被调进程的PCB中取出段表始址和段表长度,装入段表寄存器
- 段号与控制寄存器的页表长度比较,若页号大于等于段表长度,发生地址越界中断,停止调用,否则继续
- 由段号结合段表始址求出页表始址和页表大小
- 页号与段表的页表大小比较,若页号大于等于页表大小,发生地址越界中断,停止调用,否则继续
- 由页表始址结合段内页号求出存储块号
- 存储块号&页内地址,即得物理地址
05.内存写漏
**内存泄漏:**当应用程序请求使用一段内存时,操作系统会为其分配特定的内存空间。当应用程序使用完内存后,应该通知操作系统释放内存,以便其他应用程序继续使用。但有些应用程序编写得不够规范,不会向操作系统表明该内存已不再使用。如果这种情况多次出现,操作系统可能出现“急需”内存的情况,这将严重地影响操作系统性能。
当攻击者发现内存泄漏(Memory Leak)场景时,也意味着有了发动新的拒绝服务(Denial of Service,DoS)攻击的机会。例如,当发现UNIX应用程序和Telnet 协议的某个特定版本存在内存泄漏时,攻击者将无限放大问题的严重性。攻击者会不断地向这些存在脆弱性的操作系统发送Telnet 请求。而操作系统不停地为这些网络请求分配资源,这将导致越来越多的内存被分配出去,却不会释放任何资源以归还给操作系统。最终,操作系统将耗尽内存资源并进入停顿状态。
注意:内存泄漏可能发生在操作系统、应用程序和软件驱动程序中。
有两种主要的安全对策可以防止内存泄漏问题∶撰写更规范的代码,正确释放内存;使用垃圾收集器(Garbage Collector),这类软件可运行特定算法来识别未真正使用却宣称已占用的内存资源,然后通知操作系统将该内存标记为“可用”状态。不同类型的垃圾收集器适用于不同的操作系统和编程语言。
06.如果频繁进行内存的分配释放会有什么问题吗?
频繁的分配释放内存,导致缺页中断次数很高。而缺页中断的处理是由系统在内核态完成的,所以system cpu利用率偏高,导致性能问题的产生。
解决办法:
将动态内存改为静态分配,或者启动的时候,用malloc为每个线程分配,然后保存在threaddata里面。但是,由于这个模块的特殊性,静态分配,或者启动时候分配都不可行。另外,Linux下默认栈的大小限制是10M,如果在栈上分配几M的内存,有风险。 禁止malloc调用mmap分配内存,禁止内存紧缩。 在进程启动时候,加入以下两行代码: mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存 mallopt(M_TRIM_THRESHOLD, -1); // 禁止内存紧缩
注意:
-
Linux内存分配,在超过128K时,就会调用mmap,而不是移动brk指针。当munmap时,会把内存释放掉。
-
释放掉的内存数大于128K时,会调用brk紧缩逻辑。
以上两点都会把内存释放掉,导致下次申请内存时还会产生缺页中断。
07.如果频繁分配释放的内存很大(>128k),怎么处理?
如果频繁分配和释放的内存很大(>128k),可以考虑使用以下策略来处理:
- 使用内存池技术:预先分配一定数量的大块内存作为备用,并在需要时直接从池中获取空闲内存块。这样做可以减少系统开销和避免碎片化。
- 手动管理内存:对于较大的内存块,可以手动管理其生命周期。即在程序启动时申请一定数量的内存块,并将其缓存在一个列表中。在需要使用这些内存块时,直接从列表中取出一个可用的内存块进行操作,并在使用完成后将其放回列表中。这种方式虽然会增加代码复杂度,但是可以有效地避免频繁进行大块内存分配和释放带来的问题。
- 优化算法实现:如果无法避免频繁进行大块内存分配和释放操作,可以尝试优化相关算法实现,以减少这些操作对程序性能的影响。例如,可以考虑通过重复利用已有数据、缓冲或者临时变量等方式减少大量重复创建对象、数组等数据结构带来的开销。
08.虚拟内存以及堆栈溢出相关的问题,堆栈溢出怎么处理等等。
堆栈溢出是一种常见的安全漏洞。在编程中,堆栈是用于存储函数调用信息和局部变量的一种数据结构。当程序执行函数调用时,会将函数的返回地址、参数和局部变量等信息压入堆栈中。当函数返回时,这些信息会从堆栈中弹出。如果在函数执行过程中,局部变量过多或者函数调用嵌套过深,就可能导致堆栈溢出,从而使程序崩溃或被攻击者利用。
- 增加堆栈空间
可以通过增加堆栈空间来避免堆栈溢出。在编译时,可以通过调整编译器的参数来增加堆栈空间。例如,在GCC编译器中,可以使用-fstack-protector-all参数来增加堆栈空间。这样可以在程序运行时检测堆栈溢出,并在出现溢出时立即终止程序运行,从而保护系统安全。
- 优化代码
可以通过优化代码来避免堆栈溢出。一些常见的优化方法包括减少局部变量的使用、减少函数调用层数、避免递归调用等。
- 使用堆内存
可以使用堆内存来代替堆栈,从而避免堆栈溢出。在使用堆内存时,需要注意及时释放已经使用的内存,避免内存泄漏。
- 使用异常处理机制
allyally块中释放已经使用的资源。
堆栈溢出是一种常见的安全漏洞,需要采取相应的措施来避免。可以通过增加堆栈空间、优化代码、使用堆内存、使用异常处理机制等方式来解决堆栈溢出问题。在编程中,需要注意及时释放已经使用的内存,避免内存泄漏,从而保护系统的安全。
09.分段和分页的区别
页和分段系统有许多相似之处,但在概念上两者完全不同,主要表现在: 1、页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要. 段是信息的逻辑单位,它含有一组其意义相对完整的信息.分段的目的是为了能更好的满足用户的需要. 2、页的大小固定且由系统确定,把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面. 段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分. 3、分页的作业地址空间是维一的,即单一的线性空间,程序员只须利用一个记忆符,即可表示一地址. 分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址.
10.进程间通信原理和方式
进程间通信(IPC)是指不同进程之间进行数据交换和共享资源的过程。在现代操作系统中,进程是基本的运行单元,不同进程之间需要进行通信来完成协作任务。常用的进程间通信方式有以下几种:
- 管道(Pipe):管道是一种半双工的通信方式,可以实现父子进程之间或者兄弟进程之间的通信。管道有两个端口,分别连接到两个进程中,在一个端口写入数据,在另一个端口读取数据。
- 命名管道(FIFO):命名管道也是一种半双工的通信方式,可以实现无关联进程之间的通信。与管道不同的是,命名管道在文件系统中存在一个特定名称,并且可以通过该名称访问。
- 信号量(Semaphore):信号量是一种锁机制,用于保护临界区资源和控制并发访问。多个进程可以通过使用相同的信号量来互斥地访问某些资源。
- 共享内存(Shared Memory):共享内存允许多个进程直接访问同一个物理地址空间上的内存区域,避免了复制数据和上下文切换等开销。
- 消息队列(Message Queue):消息队列是一种异步通信方式,允许进程将数据发送到一个队列中,并由另一个进程从该队列中读取数据。
- 套接字(Socket):套接字是一种网络编程的通信方式,可以实现不同计算机上的进程之间进行通信。
11.fork()读时共享写时拷贝
父子进程之间在刚fork后。父子相同处: 全局变量、.data、.bbs、.text、栈、堆、环境变量、用户ID、宿主目录(进程用户家目录)、进程工作目录、信号处理方式等等,即0~3G的用户空间是完全一样的。父子不同处: 1.进程ID 2.fork返回值 3.父进程ID 4.进程运行时间 5.闹钟(定时器) 6.未决信号集
似乎,子进程复制了父进程0-3G用户空间内容,以及父进程的PCB(内核模块在物理内存只有一份),但pid等不同。真的每fork一个子进程都要将父进程的0-3G地址空间完全拷贝一份,然后在映射至物理内存吗?当然不是,父子进程间遵循读时共享写时复制的原则。这样设计,无论子进程执行父进程的逻辑还是执行自己的逻辑都能节省内存开销。
读时共享写时复制这一机制是由MMU来实现的。
注意:只有进程空间的各段的内容要发生变化时(子进程或父进程进行写操作时,都会引起复制),才会将父进程的内容复制一份给子进程。在fork之后两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。即父子进程在逻辑上仍然是严格相互独立的两个进程,各自维护各自的参数,只是在物理上实现了读时共享,写时复制。
父子进程一直共享:1. 文件描述符(打开文件的结构体) ,注意不是共享文件描述符本身这个整形数,而是共享同一个文件对应的FILE *结构体指针,其实一个文件打开后只能有一个FILE结构体,因此对于多有的进程都是共享这一个结构体,不仅仅只是父子进程。 2. mmap建立的映射区 (进程间通信详解)。
特别的,fork之后父进程先执行还是子进程先执行不确定。取决于内核所使用的调度算法。
12.互斥锁+条件变量
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
一直以来都理解错了,不是使用条件变量再加上一对互斥锁,而是条件变量内部引入一个互斥锁,其实主要还是条件变量在起作用,这样会提高效率,看下面的例子。
while(true)
{
pthread_mutex_lock(&mutex);
iCount++;
pthread_mutex_unlock(&mutex);
}
//thread 2:
while(true)
{
pthread_mutex_lock(&mutex);
if(iCount >= 100)
{
iCount = 0;
}
pthread_mutex_unlock(&mutex);
}
这种实现下,就算 lock 空闲,thread2需要不断重复<加锁,判断,解锁>这个流程,会给系统带来不必要的开销。有没有一种办法让 thread2先被 block,等条件满足的时候再唤醒 thread2?这样 thread2 就不用不断进行重复的加解锁操作了?(现在只是互斥,想要实现一个同步)这就要用到条件变量了:
//thread1 :
while(true)
{
pthread_mutex_lock(&mutex);
iCount++;
pthread_mutex_unlock(&mutex);
pthread_mutex_lock(&mutex);
if(iCount >= 100)
{
pthread_cond_signal(&cond);
}
pthread_mutex_unlock(&mutex);
}
//thread2:
while(1)
{
pthread_mutex_lock(&mutex);
while(iCount < 100)
{
pthread_cond_wait(&cond, &mutex);
//这里的wait函数,在没有拿到信号之前,会一直处于阻塞等待的状态,不会像上一种情况不断的抢锁
//在这种情况下,wait住了就不会去抢锁,这样避免了线程之间的切换
}
printf("iCount >= 100\r\n");
iCount = 0;
pthread_mutex_unlock(&mutex);
}
需要注意的是,条件变量需要配合互斥锁来使用: 为什么要与pthread_mutex 一起使用呢? 这是为了应对 线程1在调用pthread_cond_wait()但线程1还没有进入wait cond的状态的时候,此时线程2调用了 cond_singal 的情况。 如果不用mutex锁的话,这个cond_singal就丢失了。如果等待时,条件不满足,那么就放锁,这样另一个线程就会拿到这个锁,继续运行,只有满足条件时,才会加锁。加了锁的情况是,线程2必须等到 mutex 被释放(也就是 pthread_cod_wait() 释放锁并进入wait_cond状态 ,此时线程2上锁) 的时候才能调用cond_singal.
简而言之就是,在thread 1 call pthread_cond_wait() 的时刻到 thread 1真正进入 wait 状态时,是存在着时间差的。如果在这段时间差内 thread2 调用了 pthread_cond_signal() 那这个 signal 信号就丢失了。给 wait 加锁可以防止同时有另一个线程在 signal。
使得效率变高是其一,
另外使用条件变量,避免了死锁的发生:
以上是关于效率问题,此外互斥锁还有一个缺点就是会造成死锁。 例如线程A和线程B都需要独占使用2个资源,但是他们都分别先占据了一个资源,然后又相互等待另外一个资源的释放,这样就形成了一个死锁。 条件变量起到了阻塞和唤醒线程的作用,所以通常互斥锁要和条件变量配合。 为了解决以上问题,条件变量常和互斥锁一起使用,条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其它的某个线程改变了条件变量,它将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。
13.如果非堆内存一直在增长,可能哪个区域的内存出了问题(Java)
如果非堆内存(Native Memory)一直在增长,那么可能是以下几个区域的内存出了问题:
- 直接内存(Direct Memory):直接内存是一种使用Native Memory进行分配和管理的Java堆外内存。它通常用于高性能IO操作中,例如NIO。如果应用程序中有大量使用直接内存的操作,并且没有正确地释放这些内存,则会导致非堆内存占用过多。
- 线程栈(Thread Stack):线程栈是每个线程独立拥有的一块空间,用于保存线程执行时所需要的数据。如果线程栈空间不足或者没有正确地释放线程资源,则会导致非堆内存占用过多。
- 本地方法栈(Native Method Stack):本地方法栈是Java虚拟机调用本地方法时使用的一块空间,用于保存本地方法执行时所需要的数据。如果应用程序中存在大量使用本地方法并且没有正确释放本地资源,则会导致非堆内存占用过多。
- 内核缓冲区(Kernel Buffer):当Java应用程序与操作系统交互时,如进行网络IO、文件IO等操作时,可能会涉及到操作系统的内核缓冲区。如果应用程序中存在大量频繁进行网络IO、文件IO等操作,并且没有正确释放资源,则会导致非堆内存占用过多。
为了解决非堆内存过度增长的问题,我们需要通过工具分析具体的内存使用情况,并找到导致内存泄漏或者资源未正确释放的原因。常用的工具包括JVM自带的jmap、jstat等命令以及第三方工具如VisualVM、MAT等。通过这些工具,我们可以定位问题所在并进行相应的优化和调整。
14.堆和栈的区别。什么情况下会往堆里放
堆和栈是两种内存分配方式,它们的主要区别在于:
- 分配方式:栈采用后进先出(LIFO)的方式进行内存分配和释放,而堆则没有固定的分配方式,可以随意进行内存分配和释放。
- 内存管理:栈的内存由编译器自动管理,程序员无需手动申请或者释放,因此容易出现溢出等问题;而堆的内存需要由程序员手动申请并进行相应的管理。
- 存储内容:栈主要用于保存方法执行时的局部变量、方法参数等数据,以及方法调用时所需保存的返回地址等信息;而堆则主要用于保存对象、数组等复杂数据结构。
往堆里放数据通常发生在以下情况下:
- 对象创建:当程序中创建一个新对象时,需要在堆上为该对象分配空间,并初始化其成员变量。
- 数组创建:当程序中创建一个新数组时,需要在堆上为该数组分配空间,并初始化其元素。
- 动态字符串操作:当程序中进行字符串拼接、截取等动态操作时,需要在堆上为生成的新字符串分配空间。
15.fork函数返回值是怎么实现的
一、初识fork函数
在Linux中fork函数时是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
man fork
在Linux下执行上述命令可以看到fork函数的相关信息如下:
进程调用fork函数时会以该进程为父进程创建出子进程,父子进程代码共享,但进程具有独立性,父子进程也不例外,这里的共享只是指的是子进程采用写时拷贝去拷贝父进程的数据,父子进程的数据是两块不同的空间。
-
分配新的内存块和内核数据结构给子进程
-
将父进程部分数据结构内容拷贝至子进程
-
添加子进程到系统进程列表当中
-
fork返回,开始调度器调度
二、fork函数的返回值
我们都知道一个函数有且只能有一个返回值,但fork函数是一个很特别的函数,fork函数可以有两个返回值,第一种情况fork函数调用失败时返回-1;第二种情况fork函数调用成功创建子进程时,父进程返回子进程的pid(pid指的是进程的编号),子进程返回0。
在Linux下编译好如下代码后,跑起来就可以知道是不是如上所说了
int main()
{
int ret = fork();
if (ret < 0) {
perror("fork");
return 1;
}
else if (ret == 0) { //child
// getpid是一个返回当前进程pid的函数
printf("I am child : %d!, ret: %d\n", getpid(), ret);
}
else { //father
printf("I am father : %d!, ret: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}
我们可以看到结果如下:

一个函数只能有一个返回值,按理说上边的if、else if、else三条语句中只会执行一条,但我们可可以看到的确有两条语句被执行了,打印出了两条信息,说明了fork函数确实是存在两个返回值的,fork函数的返回值也的确如我们所说父进程返回子进程的pid,子进程返回0,fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
那一个函数是怎么能够有两个返回值的呢? 先来看一段代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { //child,子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { //parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
return 0;
}
在此代码中定义了一个全局变量g_val,全局变量是存在静态区的,生命周期是整个程序的生命周期,对其进行修改其值是会变为修改后的值的,父进程sleep了3秒钟,保证了子进程先跑完,然后再去执行父进程的,既然在子进程中已经将g_val的值修改为100,那么在父进程中的g_val是否也会是100呢?来看如下运行结果:

可以看到子进程和父进程中的g_val的地址都是一样的,可是这个相同的地址里存的值却不一样,我们平常对指针进行解引用操作拿到的都是这个指针指向的内容,指向的内容是唯一的,可这里的g_val却出现了两个值,未免太魔幻了!
其实,这里的地址都是虚拟的地址,父子进程的两个的地址只是在虚拟地址空间上是一样的,但通过父子进程各自的页表映射到真实的物理内存中的地址时,这两个g_val的物理内存的地址是不一样的,这就能够解释为什么g_val会存在两个值的问题了。
反过来再看fork函数的两个返回值也是类似的,fork函数之后,父进程创建了子进程,进程之间是独立的,父子进程都会有一块自己的虚拟地址空间,pid_t id = fork(); 这个id只是在父子进程的虚拟地址空间上是一样的,但通过各自的页表映射到物理内存时是两个不同的的地址,所以才会存在两个返回值。
16.用户级线程和内核级线程的区别
线程的实现可以分两类:用户级线程,内核级线程和混合式线程。
用户级线程是指不需要内核支持而在用户程序中实现的线程,它的内核的切换是由用户态程序自己控制内核的切换,不需要内核的干涉。但是它不能像内核级线程一样更好的运用多核CPU。
优点:
(1) 线程的调度不需要内核直接参与,控制简单。
(2) 可以在不支持线程的操作系统中实现。
(3) 同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起,可以节约更多的系统资源。
缺点:
(1) 一个用户级线程的阻塞将会引起整个进程的阻塞。
(2) 用户级线程不能利用系统的多重处理,仅有一个用户级线程可以被执行。
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态。可以很好的运用多核CPU,就像Windows电脑的四核八线程,双核四线程一样。
优点:
(1)当有多个处理机时,一个进程的多个线程可以同时执行。
(2) 由于内核级线程只有很小的数据结构和堆栈,切换速度快,当然它本身也可以用多线程技术实现,提高系统的运行速率。
缺点:
(1) 线程在用户态的运行,而线程的调度和管理在内核实现,在控制权从一个线程传送到另一个线程需要用户态到内核态再到用户态的模式切换,比较占用系统资源。(就是必须要受到内核的监控)
关联性
(1) 它们之间的差别在于性能。
(2) 内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
(3) 用户级线程的创建、撤消和调度不需要OS内核的支持。
(4) 用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
(5) 在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
(6) 用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
17.线程池和线程开销
线程池和线程开销是两个相关但不同的概念。
线程池是一种管理和复用线程的机制,它在应用程序启动时创建一组线程,并将这些线程放入一个队列中等待任务。当应用程序需要执行一个任务时,它会从线程池中获取一个空闲的线程来执行该任务。这种方式可以减少因频繁创建和销毁线程而产生的性能开销,提高应用程序的性能和可靠性。
而线程开销是指创建、调度、上下文切换等操作所需的时间和资源。每个线程都需要占用一定的内存空间、CPU时间片以及其他系统资源,如果同时运行过多的线程,会导致系统负荷过重、响应变慢甚至崩溃。
因此,在使用线程时需要权衡好并发性与性能之间的关系,并采取适当的优化策略。例如,在高并发情况下可以使用线程池来复用已有的空闲线程,避免频繁地创建和销毁;在低并发情况下可以考虑使用轻量级进程(如协程)或者事件驱动模型来替代传统多进程/多线程模型,以降低系统开销。
18.线程切换的到底是什么
线程切换指的是在操作系统中,当一个进程(或者线程)正在执行时,由于某种原因需要暂停当前进程(或者线程),并将CPU资源分配给其他进程(或者线程)执行。这个过程被称为上下文切换。
在进行线程切换时,操作系统会保存当前线程的上下文(包括寄存器、栈指针、程序计数器等信息),然后加载目标线程的上下文,并将CPU控制权转交给目标线程。当目标线程执行完毕后,再恢复之前被暂停的线程继续执行。
虽然看起来简单,但是由于每次切换都需要保存和恢复大量的信息,所以它会消耗一定的时间和资源。而且如果频繁地进行线程切换,还可能导致CPU缓存失效、竞争条件等问题,从而降低系统性能和稳定性。
因此,在编写多线程程序时应该尽量减少不必要的线程切换。例如可以使用同步机制(如锁、信号量等)来避免竞争条件;合理设置任务调度优先级来减少不必要的抢占;采用异步模型来避免阻塞等待等情况。
19.线程同步共享怎么实现
线程同步的方式主要有: 临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore)、事件(Event)。
他们的主要区别和特点如下:
1)临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。在任意时刻只允许一个线程对共享资源进行访问, 如果有多个线程试图访问公共资源,那么在有一个线程进入后,其他试图访问公共资源的线程将被挂起,并一直等到进入临界区的线程离开,临界区在被释放后,其他线程才可以抢占。
2)互斥量:采用互斥对象机制。 只有拥有互斥对象的线程才有访问公共资源的权限,因为互斥对象只有一个,所以能保证公共资源不会同时被多个线程访问。
互斥不仅能实现同一应用程序的公共资源安全共享,还能实现不同应用程序的公共资源安全共享。
3)信号量:它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。
4)事 件: 通过通知操作的方式来保持线程的同步,还可以方便实现对多个线程的优先级比较的操作。
很多人可能不太了解线程同步什么意思,我们要怎么样才能保持他们同步,我们今天要讨论的就是这个问题,希望对大家有所帮助。
首先我们要知道什么是同步就是有时候在进行多线程的程序设计中需要实现多个线程共享同一段代码,接下来就是怎么设置同步。
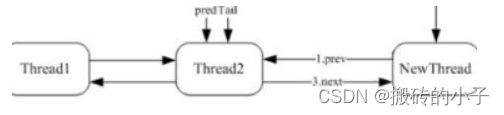
接下来我们要做的第一步就是不要让多个线程无序地访问共享资源,对关键代码进行归结放在一个代码块,不要分离。
接下来就是保持关键 代码的 原子性,只要有访问时,同时只有一个关键代码可以使用,这样就同步了。

接下来还是利用互斥锁实现关键代码的同步访问,采用同步法,对关键字修饰做出相关设置

最后是将每一个线程的开始都从这个方法开始,这样只能等一个结束之后下一个再开始,这样就可以同步进行了。
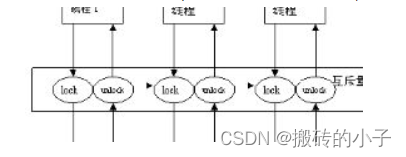
20.互斥同步的方法
1.临界区(Critical Section):适合一个进程内的多线程访问公共区域或代码段时使用,防止多个线程同时访问一个变量或者代码段。
2.互斥量(Mutex):适合不同进程内多线程访问公共区域或者代码段时使用,可以一进程内多线程使用,也可以多个进程多线程使用。
3.事件(EVENT):通过线程间触发事件实现同步互斥,适用于后一线程需要等待前一个线程数据输出使用
4.信号量(Semaphore):与临界区和互斥量不同,可以实现多个线程同时访问公共区域数据,原理与操作系统中的PV操作类似,先设置一个访问公共区域的线程最大连接数,每一个线程访问共享区资源数就减一,直到资源数小于等于零。
下面为同步互斥使用流程
互斥:
关键段CS :
创建或初始化 InitializeCriticalSection(PCRITICAL_SECTION lpCriticalSection)
销毁 DeleteCriticalSection(LPCRITICAL_SECTION lpCriticalSection)
进入关键区域 EnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection)
离开关键区域 LeaveCriticalSection(LPCRITICAL_SECTION lpCriticalSection)
互斥量Mutex:
创建或初始化 CreateMutex(LPSECURITY_ATTRIBUTES lpMutexAttributes,
BOOL bInitialOwner,
LPCTSTR lpName)
销毁 CloseHandle (HANDLE hMutex)
进入互斥区域 WaitForSingleObject(HANDLE hMutex, INFINITE)
离开互斥区域 ReleaseMutex(HANDLE hMutex)
同步:
事件Event
创建 CreateEvent(LPSECURITY_ATTRIBUTES lpEventAttributes,
BOOL bManualReset,
BOOL bInitialState,
LPCTSTR lpName)
销毁 CloseHandle(HANDLE hEvent)
使事件触发 SetEvent(HANDLE hEvent)
使事件未触发 ResetEvent(HANDLE hEvent)
信号量Semaphore
创建 CreateSemaphore( LPSECURITY_ATTRIBUTES lpSemaphoreAttributes,
LONG lInitialCount,
LONG lMaximumCount,
LPCTSTR lpName)
销毁 CloseHandle(ANDLE hSemaphore)
递减计数 WaitForSingleObject(HANDLE hSemaphore, INFINITE)
递增计数 ReleaseSemaphore(HANDLE hSemaphore,
LONG lReleaseCount,
LPLONG lpPreviousCount )
21.信号量和自旋锁的区别
信号量:信号量本质上是一个整数值,和PV函数一起使用保证临界区的原子性。在linux内核中用于互斥。信号量可以被休眠
自旋锁:不能被休眠(如中断处理程序),一个自旋锁是一个互斥设备,它只能是两个值,锁定和解锁。自旋锁通常比信号量性能更高,但当存在自旋锁时,等待执行忙循环的处理器做不了任何有用的工作。
区别:
1、 自旋锁会导致死循环,锁定期间不允许阻塞,因此要求锁定的临界区小;
信号量允许阻塞,可以使用于临界区大的情况。
2、自旋锁实际上是忙等待,自旋锁可能导致系统死锁,自旋锁期间不能调用可能引起调度的函数。如:copy_from_user(),copy_to_user(),kamlloc().
信号量:进程获取不到信号量的时候,不会自旋而是进入睡眠的等待状态。
22.查看磁盘、cpu 占用、内存占用命令
1.查看磁盘占用命令:
Linux系统:df -h
Windows系统:dir /s
2.查看CPU占用命令:
Linux系统:top、htop
Windows系统:Task Manager(任务管理器)
3.查看内存占用命令:
Linux系统:free -m
Windows系统:Task Manager(任务管理器)
23.linux虚拟地址空间结构/动态库地址无关代码
本文主要描述了Linux系统上关于位置无关代码PIC,位置无关可执行程序PIE及地址空间布局随机化ASLR三个主要特性的原理及联系。第一部分首先介绍了应用程序地址空间的基础知识作为铺垫;第二部分重点讲解PIC的实现原理;第三部分简单介绍了PIE的概念;第四部分讲解ASLR和PIE如何配合工作,以实验的方式来说明二者的联系。
本文主要基于Linux X86平台和X64平台讲解,水平有限,如果有错误,敬请指正。
一、程序虚拟地址空间及位置有关代码概述
Linux进程从磁盘加载到内存中运行的过程中,内核会为进程分配虚拟地址空间,虚拟地址空间被划分为一块块的区域(Segment),其中最重要的几个区域如下:
图1 - 应用程序虚拟地址空间说明
内核地址空间,对所有应用来说都是相同的,这部分地址空间应用无法直接访问。内核地址空间不是本文关注的重点,我们重点关注应用程序的重要的一些SEGMENT。
表1 - 应用程序重要segment描述
如果系统没有开启地址随机化(ASLR - Address Space Layout Randomization,地址随机化,后文会介绍),则Linux会将上面表格中的各个segment的地址空间放到一个固定的地址上面。
我们写一个实际的程序来看看在一个Linux X86_64的机器上各个segment的地址是如何排布的,程序如下,覆盖了我们关心的segment。
图2 - 虚拟地址空间演示程序
编译
gcc -o addr_test addr_test.c -static
(此处使用静态链接,以便演示位置相关代码的特征)
我们运行这个程序3次,会发现所有的地址都是一个固定值。这是因为在没有开ASLR特性时,系统不会随机化分配程序的虚拟地址空间,程序所有的地址都是按照固定的规则来生成。
图3 - 固定segment地址分布
通过objdump命令反汇编后可以看到,对于全局变量和函数调用的访问,汇编指令跟的地址都是固定的,这样的代码我们就称它为位置相关的。
图4 - 位置相关代码汇编语句实例
这种代码,由于地址是写死的,只能加载到指定地址上运行,一旦加载地址有变化,由于代码里访问的变量、函数地址是固定的,加载地址变化后程序无法正常执行。
固定地址的方式虽然简单,但是无法实现一些高级特性比如动态库支持。动态库的代码会通过mmap()系统调用来映射到进程的虚拟地址空间,不同的进程中,同一个动态库映射的虚拟地址是不确定的。如果动态库的实现上使用位置相关的代码,则无法达到其任意地址运行的目的,这种情况下我们就需要引入位置无关代码PIC的概念了。
另外,我们可以看到,在没有开启地址随机化特性的系统上,由于程序各个segment的地址是固定的,黑客在攻击时会更加简单(感兴趣的同学可以搜索一下Ret2shellcode或Ret2libc攻击),此时需要引入PIE的概念搭配ASLR一起来防护。
二、位置无关代码PIC和动态库的实现
PIC,全称Position Independent Code。位置无关代码是指代码无论被加载到哪个地址上都可以正常执行。gcc选项中添加-fPIC会产生相关代码。
关键点#1 - 代码段和数据段的偏移
代码段和数据段之间的偏移,在链接的时候由链接器给出,对于PIC来说非常重要。当链接器将各个目标文件的所有p组合到一起的时候,链接器完全知道每个p的大小和它们之间的相对位置。
图5 - 代码段和数据段偏移示例
如上图所示,示例中这里TEXT和DATA时紧紧挨着的,其实无论DATA和TEXT是否是相邻的,链接器都能知道这两个段的偏移。根据这个偏移,可以计算出在TEXT段内任意一条指令相对于DATA段起始地址的相对偏移量。如上图,无论TEXT段被放到了哪个虚拟地址上,假设一条mov指令在TEXT内部的0xe0偏移处,那么我们可以知道,DATA段的相对偏移位置就是:TEXT段的大小 - mov指令在TEXT内部的偏移 = 0xXXXXE000 - 0xXXXX00E0 = 0xDF20
关键点#2 - X86上指令相对偏移的计算
如果使用相对位置进行处理,可以看到代码能够做到位置无关。但在X86平台上mov指令对于数据的引用需要一个绝对地址,那应该怎么办呢?
从“关键点1”里的描述来看,我们如果知道了当前指令的地址,那么就可以计算出数据段的地址。X86平台上没有获取当前指令指针寄存器IP的值的指令(X64上可以直接访问RIP),但可以通过一个小技巧来获取。来看一段伪代码:
图6 - X86平台获取指令地址汇编
这段代码在实际运行时,会有以下的事情发生:
- 当cpu执行 call STUB的时候,会将下一条指令的地址保存到stack上,然后跳到标签STUB处执行。
- STUB处的指令是pop ebx,这样就将 "pop ebx"这条指令所在的地址从stack弹出放到了ebx寄存器中,这样就得到了IP寄存器的值。
1.全局偏移表GOT
在理解了前面的几点后,来看看在X86上是如何实现位置无关的数据引用的,此特性是通过全局偏移表global offset table(GOT)来实现的。
GOT是一张在data p中保存的一张表,里面记录了很多地址字段 (entry)。假设一条指令想要引用一个变量,并不是直接去用绝对地址,而是去引用GOT里的一个entry。GOT表在data p中的地址是明确的,GOT的entry包含了变量的绝对地址。
图7 - 代码地址和GOT表entry关系
如上图,根据"关键点1"和“关键点2”,我们可以先获取到当前IP的值,然后计算得到GOT表的绝对地址,由于变量的地址entry在GOT表中的偏移也是已知的,因此可以实现位置无关的数据访问。
以一条绝对地址的mov指令的伪代码为例(X86平台):
图8 - 位置相关mov指令示例
如果要变成位置无关的代码,则要多几个步骤
图9 - 结合GOT实现位置无关的mov指令示例
通过上面的步骤,就可以实现代码访问变量的地址无关化。但是还有一个问题,这个GOT表里存储的VAR_ADDR值又是怎么变成实际的绝对地址的呢?
假设有一个libtest.so,有一个全局变量g_var,我们通过readelf -r libtest.so后,会看到如下的输出
图10 - rel.dyn段全局变量重定向描述字段
动态加载器会解析rel.dyn段,当它看到重定向类型为R_386_GLOB_DAT的时候,会做如下操作:将符号g_var实际的地址值替换到偏移0x1fe4处(也就是将Sym.Value的值替换为实际地址值)
2.函数调用的位置无关化实现
从理论上讲,函数的PIC实现也可以通过和数据引用GOT表相同的方式实现位置无关。不直接使用函数的地址,而是通过查GOT来找到实际的函数绝对地址。但实际上函数的PIC特性并不是这么做的,实际情况会复杂一些。为什么不按照和数据引用一样的方式,先来看一个概念:延迟绑定。
对于动态库的函数来说,在没有加载到程序的地址空间前,函数的实际地址都是未知的,动态加载器会处理这些问题,解析出实际地址的过程,这个过程称之为绑定。绑定的动作会消耗一些时间,因为加载器要通过特殊的查表、替换操作。
如果动态库有成百上千个函数接口,而实际的进程只用到了其中的几十个接口,如果全部都在加载的时候进行绑定操作,没有意义并且非常耗时。因此提出了延迟绑定的概念,程序只有在使用到对应接口时才实时地绑定接口地址。
因为有了延迟绑定的需求,所以函数的PIC实现和数据访问的PIC有所区别。为了实现延迟绑定,就额外增加了一个间接表PLT(过程链接表)。
PLT搭配GOT实现延迟绑定的过程如下:
第一次调用函数
图11 - 首次调用PIC函数时PLT,GOT关系
首先跳到PLT表对应函数地址PLT[n],然后取出GOT中对应的entry。GOT[n]里保存了实际要跳转的函数的地址,首次执行时此值为PLT[n]的prepare resolver的地址,这里准备了要解析的函数的相关参数,然后到PLT[0]处调用resolver进行解析。
resolver函数会做几件事情:
(1)解析出代码想要调用的func函数的实际地址A
(2)用实际地址A覆盖GOT[n]保存的plt_resolve_addr的值
(3)调用func函数
首次调用后,上图的链接关系会变成下图所示:
图12 - 首次调用PIC函数后PLT,GOT关系
随后的调用函数过程,就不需要再走resolver过程了
三、位置无关可执行程序PIE
PIE,全称Position Independent Executable。2000年早期及以前,PIC用于动态库。对于可执行程序来讲,仍然是使用绝对地址链接,它可以使用动态库,但程序本身的各个segment地址仍然是固定的。随着ASLR的出现,可执行程序运行时各个segment的虚拟地址能够随机分布,这样就让攻击者难以预测程序运行地址,让缓存溢出攻击变得更困难。OS在使能ASLR的时候,会检查可执行程序是否是PIE的可执行程序。gcc选项中添加-fPIE会产生相关代码。
四、Linux ASLR机制和PIE的关系
ASLR的全称为 Address Space Layout Randomization。在Linux 2.6.12 中被引入到 Linux 系统,它将进程的某些虚拟地址进行随机化,增大了入侵者预测目的地址的难度,降低应用程序被攻击成功的风险。
在Linux系统上,ASLR有三个级别
表2 - ASLR级别描述
ASLR的级别通过两种方式配置:
echo level > /proc/sys/kernel/randomize_va_space
或
sysctl -w kernel.randomize_va_space=level
例子:
echo 0 > /proc/sys/kernel/randomize_va_space 关闭地址随机化
或
sysctl -w kernel.randomize_va_space=2 最大级别的地址随机化
我们还是以文章开头的那个程序来说明ASLR在不同级别下时如何表现的,首先在ASLR关闭的情况下,相关地址不变,输出如下:
图13 - ASLR=0时虚拟地址空间分配情况
我们把ASLR级别设置为1,运行两次,看看结果:
图14 - ASLR=1时虚拟地址空间分配情况
可以看到STACK和MMAP的地址发生了变化。堆、数据段、代码段仍然是固定地址。
接下来我们把ASLR级别设置为2,运行两次,看看结果:
图15 - ASLR=2,PIE不启用时虚拟地址空间分配情况
可以看到此时堆的地址也发生了变化,但是我们发现BSS,DATA,TEXT段的地址仍然是固定的,不是说ASLR=2的时候,是完全随机化吗?
这里就引出了PIE和ASLR的关系了。从上面的实验可以看出,如果不对可执行文件做一些特殊处理,ASLR即使在设置为完全随机化的时候,也仅能对STACK,HEAP,MMAP等运行时才分配的地址空间进行随机化,而可执行文件本身的BSS,DATA,TEXT等没有办法随机化。结合文章前面讲到的PIE相关知识,我们也很容易理解这一点,因为编译和链接过程中,如果没有PIE的选项,生成的可执行文件里都是位置相关的代码。如果OS不管这一点,ASLR=2时也将BSS,DATA,TEXT等随意排布,可想而知程序根本不能正常运行起来。
明白了原因,我们在编译时加入PIE选项,然后在ASLR=2时重新运行一下看看结果如何
图16 - ASLR=2,PIE启用时虚拟地址空间分配情况
可以看到在PIE打开的情况下,搭配ASLR=2,可以实现各个段的虚拟地址完全随机化分布。
24.top命令排查高占有率进程/top命令的占用率怎么算的
Linux top命令的cpu使用率和内存使用率
前言
NAME
top - display Linux processes
一、cpu使用率
1.1 top简介
top程序提供当前运行系统的动态实时视图,它可以显示系统概要信息以及当前由Linux内核管理的进程或线程列表。
top - 17:25:17 up 20:23, 2 users, load average: 0.03, 0.04, 0.05
Tasks: 214 total, 1 running, 213 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.2 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
其中cpu这一行中各个字段的意思:
us, user : time running un-niced user processes
sy, system : time running kernel processes
ni, nice : time running niced user processes
id, idle : time spent in the kernel idle handler
wa, IO-wait : time waiting for I/O completion
hi : time spent servicing hardware interrupts
si : time spent servicing software interrupts
st : time stolen from this vm by the hypervisor
us、sy、ni、id、wa、hi、si 和 st 这几个指标之和为 100。
其中 us 和 ni字段都是表示CPU执行用户态程序的时间,普通任务的优先级范围是:nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。一般默认进程的nice值都是0,ni字段代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。us字段代表较高优先级用户态 CPU 时间,也就是进程的 nice 值为 -20-0 之间时的 CPU 时间。
us + ni 表示 CPU执行用户态程序的总时间。
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比:

事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即:


图片来自于 极客时间:Linux内核技术实战
CPU 利用率监控通常是去解析 /proc/stat 文件,而这些文件中就包含了这些细化的指标:
[root@localhost ~]# cat /proc/stat
cpu 362243 144 278184 132387798 6781 0 326 0 0 0
cpu0 80305 9 63425 33112465 1511 0 196 0 0 0
cpu1 90016 61 69153 33099320 1089 0 34 0 0 0
cpu2 96296 54 73135 33089050 464 0 38 0 0 0
cpu3 95625 19 72468 33086963 3715 0 56 0 0 0
各个字段的含义:
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。包括了 guest_nice 时间。
system(通常缩写为 sys),代表内核态 CPU 时间。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
与top命令显示的字段意义一样,只不过多显示了两个字段 guest 和 guest_nice
但我们按1后,top命令会显示每个cpu的使用率:
top - 17:42:13 up 20:40, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 213 total, 1 running, 212 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 1.0 us, 0.7 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
1.2 cpu使用率的来源
使用strace跟踪 top系统调用:
[root@localhost]# strace -e open top -n 1 2>top_log
top命令默认3S刷新一次,我这里加了 -n 1 只输出一次结果,不随时间刷新,方便跟踪 top 命令:
NAME
top - display Linux processes
-n :Number-of-iterations limit as: -n number
Specifies the maximum number of iterations, or frames, top should produce before ending.
关于cpu的信息是解析/proc/stat获取:
[root@localhost]# cat top_log | grep /proc/stat
open("/proc/stat", O_RDONLY) = 4
关于每个进程的cpu使用情况是从/proc/pid/stat文件中获取:
open("/proc/stat", O_RDONLY) = 4
open("/proc/uptime", O_RDONLY) = 5
open("/proc/1/stat", O_RDONLY) = 7
open("/proc/1/statm", O_RDONLY) = 7
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 7
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 7
open("/lib64/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 7
open("/etc/passwd", O_RDONLY|O_CLOEXEC) = 7
open("/proc/2/stat", O_RDONLY) = 7
open("/proc/2/statm", O_RDONLY) = 7
open("/proc/3/stat", O_RDONLY) = 7
open("/proc/3/statm", O_RDONLY) = 7
open("/proc/5/stat", O_RDONLY) = 7
open("/proc/5/statm", O_RDONLY) = 7
open("/proc/7/stat", O_RDONLY) = 7
open("/proc/7/statm", O_RDONLY) = 7
open("/proc/8/stat", O_RDONLY) = 7
open("/proc/8/statm", O_RDONLY) = 7
open("/proc/9/stat", O_RDONLY) = 7
open("/proc/9/statm", O_RDONLY) = 7
open("/proc/10/stat", O_RDONLY) = 7
open("/proc/10/statm", O_RDONLY) = 7
open("/proc/11/stat", O_RDONLY) = 7
open("/proc/11/statm", O_RDONLY) = 7
open("/proc/12/stat", O_RDONLY) = 7
open("/proc/12/statm", O_RDONLY) = 7
open("/proc/13/stat", O_RDONLY) = 7
open("/proc/13/statm", O_RDONLY) = 7
open("/proc/14/stat", O_RDONLY) = 7
open("/proc/14/statm", O_RDONLY) = 7
open("/proc/16/stat", O_RDONLY) = 7
open("/proc/16/statm", O_RDONLY) = 7
open("/proc/17/stat", O_RDONLY) = 7
open("/proc/17/statm", O_RDONLY) = 7
open("/proc/18/stat", O_RDONLY) = 7
open("/proc/18/statm", O_RDONLY) = 7
open("/proc/19/stat", O_RDONLY) = 7
open("/proc/19/statm", O_RDONLY) = 7
open("/proc/21/stat", O_RDONLY) = 7
open("/proc/21/statm", O_RDONLY) = 7
open("/proc/22/stat", O_RDONLY) = 7
open("/proc/22/statm", O_RDONLY) = 7
open("/proc/23/stat", O_RDONLY) = 7
open("/proc/23/statm", O_RDONLY) = 7
open("/proc/24/stat", O_RDONLY) = 7
1.3 内核相关源码
// linux-3.10/include/linux/kernel_stat.h
/*
* 'kernel_stat.h' contains the definitions needed for doing
* some kernel statistics (CPU usage, context switches ...),
* used by rstatd/perfmeter
*/
enum cpu_usage_stat {
CPUTIME_USER,
CPUTIME_NICE,
CPUTIME_SYSTEM,
CPUTIME_SOFTIRQ,
CPUTIME_IRQ,
CPUTIME_IDLE,
CPUTIME_IOWAIT,
CPUTIME_STEAL,
CPUTIME_GUEST,
CPUTIME_GUEST_NICE,
NR_STATS,
};
struct kernel_cpustat {
u64 cpustat[NR_STATS];
};
DECLARE_PER_CPU(struct kernel_cpustat, kernel_cpustat);
/* Must have preemption disabled for this to be meaningful. */
#define kcpustat_this_cpu (&__get_cpu_var(kernel_cpustat))
#define kcpustat_cpu(cpu) per_cpu(kernel_cpustat, cpu)
// linux-3.10/kernel/sched/core.c
DEFINE_PER_CPU(struct kernel_cpustat, kernel_cpustat);
EXPORT_PER_CPU_SYMBOL(kernel_cpustat);
[root@localhost ~]# cat /proc/kallsyms | grep '\<kernel_cpustat\>'
0000000000015b00 A kernel_cpustat
[root@localhost ~]# cat /proc/kallsyms | grep '\<__per_cpu_start\>'
0000000000000000 A __per_cpu_start
[root@localhost ~]# cat /proc/kallsyms | grep '\<__per_cpu_end\>'
000000000001d000 A __per_cpu_end
kernel_cpustat 在 _per_cpu_start 和 __per_cpu_end 范围内,是内核中的per-cpu变量。
更新cpu的使用率数据 cpu_usage_stat ,是在时钟中断中完成的,时钟中断处理程序每次都会调用 account_process_tick 函数来更新 cpu_usage_stat结构体:
-
// linux-3.10/kernel/sched/cputime.c /* * Account a single tick of cpu time. * @p: the process that the cpu time gets accounted to * @user_tick: indicates if the tick is a user or a system tick */ void account_process_tick(struct task_struct *p, int user_tick) { cputime_t one_jiffy_scaled = cputime_to_scaled(cputime_one_jiffy); struct rq *rq = this_rq(); if (vtime_accounting_enabled()) return; if (sched_clock_irqtime) { irqtime_account_process_tick(p, user_tick, rq); return; } // 统计CPUTIME_STEAL if (steal_account_process_tick()) return; if (user_tick) (1) 统计用户时间(包括 CPUTIME_USER 和 CPUTIME_NICE ) account_user_time(p, cputime_one_jiffy, one_jiffy_scaled); else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET)) (2) 统计内核时间(包括 CPUTIME_SYSTEM、CPUTIME_IRQ 和 CPUTIME_SOFTIRQ ) account_system_time(p, HARDIRQ_OFFSET, cputime_one_jiffy, one_jiffy_scaled); else (3) 统计空闲时间(包括 CPUTIME_IOWAIT 和 CPUTIME_IDLE) account_idle_time(cputime_one_jiffy); }
(1) 统计用户时间(包括 CPUTIME_USER 和 CPUTIME_NICE )
-
// linux-3.10/kernel/sched/cputime.c /* * Account user cpu time to a process. * @p: the process that the cpu time gets accounted to * @cputime: the cpu time spent in user space since the last update * @cputime_scaled: cputime scaled by cpu frequency */ void account_user_time(struct task_struct *p, cputime_t cputime, cputime_t cputime_scaled) { int index; /* Add user time to process. */ p->utime += cputime; p->utimescaled += cputime_scaled; account_group_user_time(p, cputime); index = (TASK_NICE(p) > 0) ? CPUTIME_NICE : CPUTIME_USER; /* Add user time to cpustat. */ task_group_account_field(p, index, (__force u64) cputime); /* Account for user time used */ acct_account_cputime(p); }(2) 统计内核时间(包括 CPUTIME_SYSTEM、CPUTIME_IRQ 和 CPUTIME_SOFTIRQ )
-
// linux-3.10/kernel/sched/cputime.c * Account system cpu time to a process. * @p: the process that the cpu time gets accounted to * @hardirq_offset: the offset to subtract from hardirq_count() * @cputime: the cpu time spent in kernel space since the last update * @cputime_scaled: cputime scaled by cpu frequency */ void account_system_time(struct task_struct *p, int hardirq_offset, cputime_t cputime, cputime_t cputime_scaled) { int index; if ((p->flags & PF_VCPU) && (irq_count() - hardirq_offset == 0)) { // 统计 CPUTIME_GUEST 和 CPUTIME_GUEST_NICE account_guest_time(p, cputime, cputime_scaled); return; } if (hardirq_count() - hardirq_offset) index = CPUTIME_IRQ; else if (in_serving_softirq()) index = CPUTIME_SOFTIRQ; else index = CPUTIME_SYSTEM; __account_system_time(p, cputime, cputime_scaled, index); }(3) 统计空闲时间(包括 CPUTIME_IOWAIT 和 CPUTIME_IDLE)
-
// linux-3.10/kernel/sched/cputime.c /* * Account for idle time. * @cputime: the cpu time spent in idle wait */ void account_idle_time(cputime_t cputime) { u64 *cpustat = kcpustat_this_cpu->cpustat; struct rq *rq = this_rq(); if (atomic_read(&rq->nr_iowait) > 0) cpustat[CPUTIME_IOWAIT] += (__force u64) cputime; else cpustat[CPUTIME_IDLE] += (__force u64) cputime; }(4)统计CPUTIME_STEAL
-
/* * Account for involuntary wait time. * @cputime: the cpu time spent in involuntary wait */ void account_steal_time(cputime_t cputime) { u64 *cpustat = kcpustat_this_cpu->cpustat; cpustat[CPUTIME_STEAL] += (__force u64) cputime; }(5)统计 CPUTIME_GUEST 和 CPUTIME_GUEST_NICE
-
// linux-3.10/kernel/sched/cputime.c /* * Account guest cpu time to a process. * @p: the process that the cpu time gets accounted to * @cputime: the cpu time spent in virtual machine since the last update * @cputime_scaled: cputime scaled by cpu frequency */ static void account_guest_time(struct task_struct *p, cputime_t cputime, cputime_t cputime_scaled) { u64 *cpustat = kcpustat_this_cpu->cpustat; /* Add guest time to process. */ p->utime += cputime; p->utimescaled += cputime_scaled; account_group_user_time(p, cputime); p->gtime += cputime; /* Add guest time to cpustat. */ if (TASK_NICE(p) > 0) { cpustat[CPUTIME_NICE] += (__force u64) cputime; cpustat[CPUTIME_GUEST_NICE] += (__force u64) cputime; } else { cpustat[CPUTIME_USER] += (__force u64) cputime; cpustat[CPUTIME_GUEST] += (__force u64) cputime; } }从 account_guest_time 函数中我们可以看到 guest cpu time 是被统计到了 用户态 cpu 时间中,即: user(通常缩写为 us),代表用户态 CPU 时间,包括了 guest 时间。CPUTIME_NICE成员中包含了CPUTIME_GUEST_NICE成员。 nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,包括了 guest_nice 时间。CPUTIME_USER成员包含了CPUTIME_GUEST成员。
二、内存使用率
2.1 总内存有关的数据
KiB Mem : 7890812 total, 6313084 free, 501864 used, 1075864 buff/cache
KiB Swap: 8126460 total, 8126460 free, 0 used. 7008280 avail Mem
默认情况下,第1行显示物理内存:total = free + used + buff/cache
运行top后,按E可以切换内存大小显示的单位:
GiB Mem : 7.5 total, 6.0 free, 0.5 used, 1.0 buff/cache
GiB Swap: 7.7 total, 7.7 free, 0.0 used. 6.7 avail Mem
2.2 进程使用内存有关的数据
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
17487 root 20 0 162148 2324 1548 R 6.2 0.0 0:00.01 top
1 root 20 0 193800 6972 4200 S 0.0 0.1 0:18.30 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.17 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:01.04 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
其中与进程内存有关的字段VIRT、RES、SHR和%MEM
VIRT -- Virtual Memory Size (KiB)
The total amount of virtual memory used by the task. It includes all code, data and shared libraries plus pages that have been swapped out and pages that have been mapped but not
used.
RES -- Resident Memory Size (KiB)
The non-swapped physical memory a task is using.
RES 中有一些物理内存是被一些进程给共享的。
SHR -- Shared Memory Size (KiB)
The amount of shared memory available to a task, not all of which is typically resident. It simply reflects memory that could be potentially shared with other processes.
%MEM -- Memory Usage (RES)
A task's currently used share of available physical memory.
运行top后,按g,在按3进入内存模式:
PID %MEM VIRT RES CODE DATA SHR nMaj nDRT %CPU COMMAND
5736 1.3 3269676 100932 16 2134452 40200 85 0 0.0 gnome-shell
4635 0.4 358196 29168 4 94984 7028 1 0 0.0 firewalld
5265 0.3 264324 26332 2284 90140 10616 0 0 0.0 X
5184 0.3 1012032 21440 468 641332 12948 0 0 0.0 libvirtd
4533 0.2 620088 17908 108 529600 5352 2 0 0.0 polkitd
5177 0.2 573828 17408 4 304768 6116 1 0 0.0 tuned
......
在内存模式中,我们可以看到各个进程内存的 %MEM、VIRT、RES、CODE、DATA、SHR、nMaj、nDRT,这些信息通过 strace 来跟踪 top 进程,你会发现这些信息都是从 /proc/[pid]/statm 和 /proc/[pid]/stat 这个文件里面读取的。 除了 nMaj(Major Page Fault, 主缺页中断,指内容不在内存中然后从磁盘中来读取的页数)外,%MEM 则是从 RES 计算而来的,其余的内存信息都是从 statm 文件里面读取的,如下是 top 命令中的字段和 statm 中字段的对应关系:
[root@localhost]# cat /proc/1/statm
48450 1743 1050 353 0 37524 0

CODE -- Code Size (KiB)
The amount of physical memory devoted to executable code, also known as the Text Resident Set size or TRS.
DATA -- Data + Stack Size (KiB)
The amount of physical memory devoted to other than executable code, also known as the Data Resident Set size or DRS.
nMaj -- Major Page Fault Count
The number of major page faults that have occurred for a task. A page fault occurs when a process attempts to read from or write to a virtual page that is not currently present in
its address space. A major page fault is when auxiliary storage access is involved in making that page available.
与nMaj相对应的还有nMin:
nMin -- Minor Page Fault count
The number of minor page faults that have occurred for a task. A page fault occurs when a process attempts to read from or write to a virtual page that is not currently present in
its address space. A minor page fault does not involve auxiliary storage access in making that page available.
major fault与minor fault的区别:
major fault: user space address触发缺页异常时,若被访问的地址映射的物理页已经被swap到磁盘空间,需要从磁盘中将页面换入。 user space address触发缺页异常时,若被访问的地址空间是被mmap映射到磁盘文件的话且page cache中还未缓存文件内容,需要通过磁盘IO将内容读入page cache。
minor fault: 当user space address触发缺页异常时,kernel可直接从buddy system中分配出内存用来满足该缺页异常即minor page fault 简单来说,major fault和minor fault的区别就是是否会触发读写磁盘的动作。
来源于Linux内存管理:缺页异常(一)
nDRT -- Dirty Pages Count
The number of pages that have been modified since they were last written to auxiliary storage. Dirty pages must be written to auxiliary storage before the corresponding physical mem‐
ory location can be used for some other virtual page.
2.3 内存使用率的来源
总的内存使用率数据来源:/proc/meminfo
open("/proc/meminfo", O_RDONLY) = 6
open("/proc/meminfo", O_RDONLY|O_CLOEXEC) = 8
每个进程内存使用率数据来源:/proc/pid/statm
open("/proc/2/stat", O_RDONLY) = 7
open("/proc/2/statm", O_RDONLY) = 7
open("/proc/3/stat", O_RDONLY) = 7
open("/proc/3/statm", O_RDONLY) = 7
open("/proc/5/stat", O_RDONLY) = 7
open("/proc/5/statm", O_RDONLY) = 7
open("/proc/7/stat", O_RDONLY) = 7
open("/proc/7/statm", O_RDONLY) = 7
open("/proc/8/stat", O_RDONLY) = 7
open("/proc/8/statm", O_RDONLY) = 7
open("/proc/9/stat", O_RDONLY) = 7
open("/proc/9/statm", O_RDONLY) = 7
open("/proc/10/stat", O_RDONLY) = 7
open("/proc/10/statm", O_RDONLY) = 7
open("/proc/11/stat", O_RDONLY) = 7
open("/proc/11/statm", O_RDONLY) = 7
open("/proc/12/stat", O_RDONLY) = 7
open("/proc/12/statm", O_RDONLY) = 7
open("/proc/13/stat", O_RDONLY) = 7
open("/proc/13/statm", O_RDONLY) = 7
open("/proc/14/stat", O_RDONLY) = 7
open("/proc/14/statm", O_RDONLY) = 7
open("/proc/16/stat", O_RDONLY) = 7
open("/proc/16/statm", O_RDONLY) = 7
open("/proc/17/stat", O_RDONLY) = 7
open("/proc/17/statm", O_RDONLY) = 7
open("/proc/18/stat", O_RDONLY) = 7
open("/proc/18/statm", O_RDONLY) = 7
open("/proc/19/stat", O_RDONLY) = 7
open("/proc/19/statm", O_RDONLY) = 7
open("/proc/21/stat", O_RDONLY) = 7
open("/proc/21/statm", O_RDONLY) = 7
open("/proc/22/stat", O_RDONLY) = 7
open("/proc/22/statm", O_RDONLY) = 7
......
三、 pmap pmap可以查看进程的内存使用情况:
NAME
pmap - report memory map of a process
DESCRIPTION
The pmap command reports the memory map of a process or processes.
-x, --extended
Show the extended format.
-X Show even more details than the -x option. format changes according to /proc/PID/smaps
pmap 来展示 sshd 进程地址空间里的部分内容:
17873: sshd: root@notty
Address Kbytes RSS Dirty Mode Mapping
00005651ff6d4000 800 464 0 r-x-- sshd
00005651ff99b000 16 16 16 r---- sshd
00005651ff99f000 4 4 4 rw--- sshd
00005651ff9a0000 36 36 36 rw--- [ anon ]
000056520036b000 276 176 176 rw--- [ anon ]
00007f80cad53000 32 28 0 r-x-- libnss_sss.so.2
00007f80cad5b000 2044 0 0 ----- libnss_sss.so.2
00007f80caf5a000 4 4 4 r---- libnss_sss.so.2
00007f80caf5b000 4 4 4 rw--- libnss_sss.so.2
00007f80caf5c000 120 24 0 r-x-- libgssrpc.so.4.2
00007f80caf7a000 2048 0 0 ----- libgssrpc.so.4.2
00007f80cb17a000 4 4 4 r---- libgssrpc.so.4.2
00007f80cb17b000 4 4 4 rw--- libgssrpc.so.4.2
00007f80cb17c000 108 40 0 r-x-- proxymech.so
00007f80cb197000 2048 0 0 ----- proxymech.so
00007f80cb397000 4 4 4 r---- proxymech.so
00007f80cb398000 4 4 4 rw--- proxymech.so
00007f80cb399000 12 12 0 r-x-- pam_lastlog.so
00007f80cb39c000 2044 0 0 ----- pam_lastlog.so
00007f80cb59b000 4 4 4 r---- pam_lastlog.so
00007f80cb59c000 4 4 4 rw--- pam_lastlog.so
00007f80cb59d000 12 8 0 r-x-- libpam_misc.so.0.82.0
00007f80cb5a0000 2044 0 0 ----- libpam_misc.so.0.82.0
00007f80cb79f000 4 4 4 r---- libpam_misc.so.0.82.0
00007f80cb7a0000 4 4 4 rw--- libpam_misc.so.0.82.0
......
每一行表示一种类型的内存(Virtual Memory Area),每一列的含义如下: (1)Mapping,用来表示文件映射中占用内存的文件,比如 sshd 这个可执行文件,或者堆[heap],或者栈[stack],或者其他,等等。 (2)Mode,它是该内存的权限,比如,“r-x”是可读可执行,它往往是代码段 (Text Segment);“rw-”是可读可写,这部分往往是数据段 (Data Segment);“r–”是只读,这往往是数据段中的只读部分。 (3)Address、Kbytes、RSS、Dirty,Address 和 Kbytes 分别表示起始地址和虚拟内存的大小,RSS(Resident Set Size)则表示虚拟内存中已经分配的物理内存的大小,Dirty 则表示内存中数据未同步到磁盘的字节数。
其中 RSS是指进程地址空间已映射的物理内存(进程地址空间与物理内存页面建立了页表映射),这个物理内存有可能是Shared方式来映射的,那这块物理内存就是Shared memory。也就是说RSS的本质是物理内存是否映射到了进程的地址空间,而和映射属性无关,因此 RSS会包括Shared memory。
可以看到,通过 pmap 我们能够清楚地观察一个进程的整个的地址空间,包括它们分配的物理内存大小,这非常有助于我们对进程的内存使用概况做一个大致的判断。比如说,如果地址空间中[heap]太大,那有可能是堆内存产生了泄漏;再比如说,如果进程地址空间包含太多的 vma(可以把 maps 中的每一行理解为一个 vma),那很可能是应用程序调用了很多 mmap 而没有 munmap;再比如持续观察地址空间的变化,如果发现某些项在持续增长,那很可能是那里存在问题。
pmap 同样也是解析的 /proc 里的文件,具体文件是 /proc/[pid]/maps 和 /proc/[pid]/smaps,其中 smaps 文件相比 maps 的内容更详细,可以理解为是对 maps 的一个扩展。你可以对比 /proc/[pid]/maps 和 pmaps 的输出,你会发现二者的内容是一致的。
通过strace命令可以看到pmap解析的是/proc/[pid]/maps文件:
strace -e open pmap -x `pidof sshd` 2>pmap_log
open("/proc/self/maps", O_RDONLY) = 3
open("/proc/17873/stat", O_RDONLY) = 3
open("/proc/17873/cmdline", O_RDONLY) = 3
open("/proc/17873/smaps", O_RDONLY) = 3
open("/usr/lib64/gconv/gconv-modules.cache", O_RDONLY) = 4
open("/proc/17869/stat", O_RDONLY) = 3
open("/proc/17869/cmdline", O_RDONLY) = 3
open("/proc/17869/smaps", O_RDONLY) = 3
open("/proc/17239/stat", O_RDONLY) = 3
open("/proc/17239/cmdline", O_RDONLY) = 3
open("/proc/17239/smaps", O_RDONLY) = 3
open("/proc/17235/stat", O_RDONLY) = 3
open("/proc/17235/cmdline", O_RDONLY) = 3
open("/proc/17235/smaps", O_RDONLY) = 3
open("/proc/17141/stat", O_RDONLY) = 3
open("/proc/17141/cmdline", O_RDONLY) = 3
open("/proc/17141/smaps", O_RDONLY) = 3
open("/proc/17137/stat", O_RDONLY) = 3
open("/proc/17137/cmdline", O_RDONLY) = 3
open("/proc/17137/smaps", O_RDONLY) = 3
open("/proc/5174/stat", O_RDONLY) = 3
open("/proc/5174/cmdline", O_RDONLY) = 3
open("/proc/5174/smaps", O_RDONLY) = 3
25.谈谈进程创建后在Linux中的内存分布?(回答内存四区,虚拟地址空间,栈内存堆内存)
1.内存分布
以32位系统为例,共有4G的寻址能力,进程在内存中的分布如下图所示。Linux默认将高地址的1G空间分配给内核,称为内核空间,剩下的3G空间分配给进程使用,称为用户空间。
用户空间从低地址空间到高地址空间包含如下5个部分:
- 代码段(text segment):存放程序的可执行二进制代码
- 数据段(data segment):存放程序中已经初始化且初值不为0的全局变量和静态局部变量,数据段属于静态内存分配
- BSS段:存放未初始化的全局变量和静态局部变量;初值为0的全局变量和静态局部变量
- 堆(heap):用于存放程序运行时动态分配的内存段,可动态扩张或者缩减
- 栈(stack):由编译器自动分配释放,它存放如下信息:
- 函数内部声明的非静态局部变量
- 记录函数调用过程的相关维护信息(称为栈帧)
- 内存映射区域:可以用于内存映射,或者装在动态链接库
2.栈
一个栈的实例如下图所示:
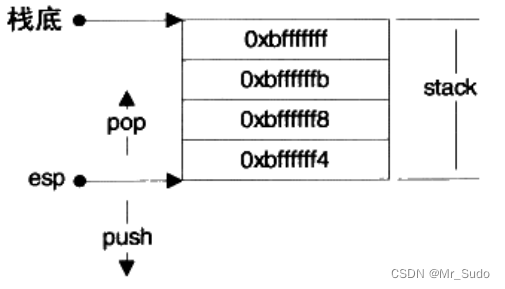
esp寄存器指向栈顶,通过控制esp寄存器可以实现数据的压缩和弹出。栈在程序的运行中非常重要,保存了一个函数调用所需维护的信息,通常被称为栈帧(Stack Frame),一个栈帧通常包含如下几个部分:
- 函数的返回地址和参数
- 临时变量:函数的非静态局部变量和编译器自动生成的其他临时变量
- 保存的上下文:函数在调用前后需要保持不变的寄存器
一个函数的栈帧通常使用ebp和esp这两个寄存器来划定范围。esp寄存器始终指向栈的顶部,ebp指向栈帧的一个固定位置,ebp寄存器又被称为帧指针。一个常见的栈帧如下图所示:
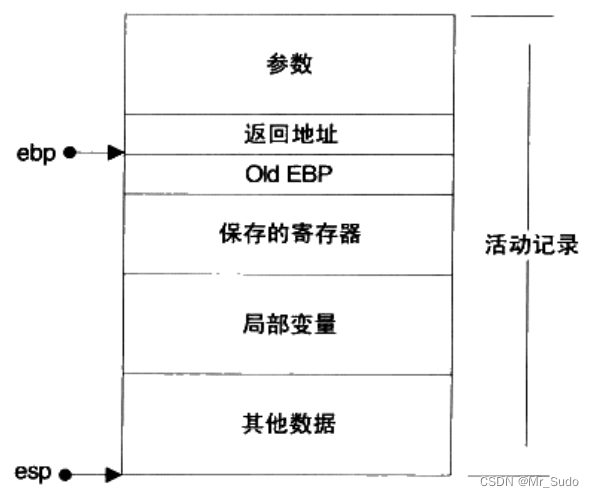
3.堆
程序可以在堆上自由地申请空间使用,例如使用malloc申请内存空间。在实际实现过程中,程序会像操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间。这样可以避免每次申请内存都使用系统调用,带来的性能开销。
堆空间管理涉及到如下两个系统调用:
- brk(): 设置进程数据段的结束地址,即它可以扩大和缩小数据段。如果将数据段的结束地址向高地址移动,扩大的那部分空间可以被程序使用。Glibc中还有一个函数叫sbrk(),它以一个增量作为参数,即增加(或减少)的空间大小,返回值是增加(减少)后数据段的结束地址,sbrk()是对brk()系统调用的包装。
- mmap(): 它的作用是向操作系统申请一段虚拟地址空间,该虚拟空间可以映射到某个文件,如果不将该地址映射到某个文件时,这块虚拟空间称为匿名空间,匿名空间可以拿来作为堆空间。
26.在Linux系统下,使用for循环,一直进行new操作,会发生heap-overflow吗?如果不会,原因呢?(答应该不会,Linux系统可能会对此情况进行处理,面试官追问如果不用C++而用Java呢,答Java虚拟机等,胡扯了一些)
在Linux系统下,使用for循环一直进行new操作,可能会发生heap-overflow。原因是当我们使用new操作时,它会从堆上分配一段内存,如果我们不释放这些内存,就会出现内存泄漏的问题。随着时间的推移和循环次数的增加,堆中分配的内存也会越来越多,最终导致heap-overflow。
但是,在实际情况中,并不一定会出现heap-overflow。这是因为在Linux系统下,堆的大小默认情况下是可以动态扩展的,当堆中没有足够的空间时,操作系统会自动扩展堆的大小。此外,在Linux系统下还有一个叫做OOM Killer(Out Of Memory Killer)的机制,在系统内存不足时可以杀死某个进程来释放内存资源。
因此,在实际编程中应该避免出现无限循环并进行大量new操作导致heap-overflow等问题。建议合理利用RAII(Resource Acquisition Is Initialization)技术来管理对象生命周期和资源释放,并且使用智能指针等工具来帮助我们避免手动管理内存带来的风险。
27.死锁的概念,进程调度算法怎么解决死锁
一、什么是死锁

**死锁(Deadlock):**是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。称此时系统处于死锁状态或系统产生了死锁。 称这些永远在互相等待的进程为死锁进程。 所占用的资源或者需要它们进行某种合作的其它进程就会相继陷入死锁,最终可能导致整个系统处于瘫痪状态。
学到这里,我们可能会对前面提到的几个名词感到困惑,死锁,饥饿,死循环一样吗?都代表什么意思呢?

死锁和饥饿是操作系统导致的问题,而死循环则是被管理者的问题,也就是程序员的问题。
针对上面银行家算法,防止死锁发生可采取的措施:
(1)最多允许4个哲学家同时坐在桌子周围。 (2)仅当一个哲学家左右两边的筷子都可用时,才允许他拿筷子。
(3)给所有哲学家编号,奇数号的哲学家必须首先拿左边的筷子,偶数号的哲学家则反之。
这里给出一个不会发生死锁的哲学家进餐过程的算法描述。

semaphore S[5] = {1,1,1,1,1};//5双筷子
semaphore mutex = 4;//最多允许4个哲学家
Pi()
{
while(1)
{
P(mutex);
P(S[i]);
拿起左边的叉子;
P(S[i+1]mod5);
拿起右边的叉子;
吃通心粉;
放下左边的叉子;
V(S[i]);
放下右边的叉子;
V(S[i+1]mod5);
V(mutex);
}
}
二、产生死锁的必要条件

互斥条件
不可剥夺条件
占有并请求条件
循环等待条件
三、产生死锁的原因

主要原因有两个:竞争临界资源和进程推进顺序不当。
总之就是对不可剥夺资源的不合理分配,可能导致死锁。
一个小问题:
一个OS有20个进程,竞争使用65个同类资源,申请方式是逐个进行的,一旦某个进程获得它所需要的全部资源,则立即归还所有资源。每个进程最多使用三个资源。若仅考虑这类资源,该系统有无可能产生死锁,为什么?
**答:不可能。**因为死锁产生的原因有两点:系统资源不足或推进顺序不当,在本题中,进程所需的最大资源数为60,而系统共有该类资源65个,其资源数已足够系统内各进程使用。
四、死锁的处理策略

五、死锁概念总结

六、死锁的预防
死锁的预防是通过破坏产生死锁的必要条件之一,是系统不会产生死锁。简单方法是在系统运行之前就采取措施,即在系统设计时确定资源分配算法,消除发生死锁的任何可能性。该方法虽然比较保守、资源利用率低,但因简单明了并且安全可靠,仍被广泛采用。这是一种预先的静态策略。
破坏互斥条件

破坏不可剥夺条件

破坏请求和保持条件

破坏循环等待条件

产生死锁的四个必要条件中,互斥条件和不可剥夺条件由共享资源本身的使用特性所决定的,因此不好破坏,相反还应加以保证,实用的死锁预防办法就是通过破坏产生死锁的占用并请求条件和循环等待条件。
总结

七、死锁的避免
安全序列
王道考研的老师在将安全序列的时候,举了一个银行给BAT三家公司借钱的例子用来引出银行家算法,很有意思。

这时候如果将30亿借给了B公司,那么手里还有10亿元,这10亿已经小于3家公司最小的最多还会借的钱数,没有公司能够达到提出的最大要求,这样银行的钱就会打水漂了!!!
如果是这种情况呢?

这样按照T->B->A的顺序借钱是没有问题的,是安全的。
按照A->T->B的顺序借钱也是没有问题的。
这样我们就会得到安全序列、不安全序列和死锁的关系了。

注意:
(1)系统在某一时刻的安全状态可能不唯一,但这不影响对系统安全性的判断。 (2)安全状态是非死锁状态,而不安全状态并不一定是死锁状态。即系统处于安全状态一定可以避免死锁,而系统处于不安全状态则仅仅可能进入死锁状态。

原因是如果进入了不安全状态,但是没有进程去请求资源,并且有进程提前归还了一些资源,这样就不会死锁。
银行家算法

银行家问题的本质:
要设法保证系统动态分配资源后不进入不安全状态,以避免可能产生的死锁。
即:每当进程提出资源请求且系统的资源能够满足该请求时,系统将判断如果满足此次资源请求,系统状态是否安全,如果判断结果为安全,则给该进程分配资源,否则不分配资源,申请资源的进程将阻塞。

当Pi发出资源请求后,系统按下述步骤进行检查:
1.如果Requesti > Needi,则出错。
2.如果Requesti>Available,则Pi 阻塞;
3.系统试探把要求的资源分配给进程Pi,并修改下面数据结构中的数值:
Availablei=Availablei-Requesti;
Allocationi=Allocationi+Requesti;
Needi = Needi- Requesti;
\4. 系统执行安全性算法,检查此次资源分配后,系统是否处于安全状态。若安全,正式将资源分配给进程Pi,以完成本次分配;否则,将试探分配作废,恢复原来的资源分配状态,让进程Pi等待。

银行家算法从避免死锁的角度上说是非常有效的,但是,从某种意义上说,它缺乏实用价值,因为很少有进程能够在运行前就知道其所需资源的最大值,而且进程数也不是固定的,往往在不断地变化(如新用户登录或退出),况且原本可用的资源也可能突然间变成不可用(如磁带机可能坏掉)。因此,在实际中,如果有,也只有极少的系统使用银行家算法来避免死锁。
八、死锁的检测和解除
死锁的检测和恢复技术是指定期启动一个软件检测系统的状态,若发现有死锁存在,则采取措施恢复之。
死锁的检测

检查死锁的办法就是由软件检查系统中由进程和资源构成的有向图是否构成一个或多个环路,若是,则存在死锁,否则不存在。 由于死锁是系统中的恶性小概率事件,死锁检测程序的多次执行往往都不会调用一次死锁解除程序,而这却增加了系统开销,因此在设计操作系统时需要权衡检测精度与时间开销。
死锁的解除
常见的死锁解除方法有以下两种: (1)撤消进程法 撤消全部死锁进程:代价太大,该做法很少用。 最小代价撤消法:首先计算死锁进程的撤消代价,然后依次选择撤消代价最小的进程,逐个地撤消死锁进程,回收资源给其他进程,直至死锁不复存在。进程的撤消代价往往与进程的优先级、占用处理机的时间等成正比。 (2)挂起进程法 (剥夺资源) 使用挂起/激活机构挂起一些进程,剥夺它们的资源以解除死锁,待条件满足时,再激活进程。目前挂起法比较受到重视。
显然,无论哪一种解除死锁的方法,都需要很大的开销。但是死锁的检测与解除办法不对系统的资源分配等加任何限制,因此是对付死锁的诸办法中导致资源利用率最高的一种办法,在对安全性要求高的大型系统中常用。
根据银行家算法,引出了这样一个公式的证明。

28.讲讲进程管理
1.基本介绍
- 在LINUX中,每个执行的程序(代码)都称为一个进程。每一个进程都分配一个ID号。
- 每一个进程,都会对应一个父进程,而这个父进程可以复制多个子进程。例如www服务器。
- 每个进程都可能以两种方式存在的。前台与后台,所谓前台进程就是用户目前的屏幕上可以进行操作的。后台进程则是实际在操作,但由于屏幕上无法看到的进程,通常使用后台方式执行。
- 一般系统的服务都是以后台进程的方式存在,而且都会常驻在系统中。直到关机才才结束。
2.显示系统执行的进程
基本介绍:
ps命令可以不加任何参数。(英文全拼:process status)命令用于显示当前进程的状态,类似windows 的任务管理器。
语法:ps [选项]
命令选项:
| -A | 列出所有的进程 |
| -w | 显示加宽可以显示较多的资讯 |
| -a | 显示当前终端的所有进程信息 |
| -u | 以用户的格式显示进程信息 |
| -x | 显示后台进程运行的参数 |
ps -aux | more 输出格式 :
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
- USER: 进程拥有者
- PID: pid(进程号)
- %CPU: 进程占用的 CPU 使用率
- %MEM: 进程占用的物理内存的百分比
- VSZ: 进程占用的虚拟内存大小(单位KB)
- RSS: 进程占用的物理内存大小(单位KB)
- TTY: 终端的次要装置号码 (minor device number of tty)
- STAT: 该行程的状态:
- D: 无法中断的休眠状态 (通常 IO 的进程)
- R: 正在执行中
- S: 静止状态
- T: 暂停执行
- Z: 不存在但暂时无法消除(僵尸进程)
- W: 没有足够的记忆体分页可分配
- <: 高优先序的行程
- N: 低优先序的行程
- L: 有记忆体分页分配并锁在记忆体内
- START: 进程开始时间
- TIME: 执行的时间,即进程使用CPU的总时间
- COMMAND:所执行的指令和参数
2.1 ps -ef 以全格式显示当前所有的进程,查看进程的父进程
-e 显示所有进程 -f 全格式
ps -ef | more输出格式:
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低﹔数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
如果想单独查看某个进程,可用 ps -aux | grep 进程名 和 ps -ef | grep 进程名
3.pstree命令
pstree命令将所有行程以树状图显示,树状图将会以 pid (如果有指定) 或是以 init 这个基本行程为根 (root),如果有指定使用者 id,则树状图会只显示该使用者所拥有的行程。
语法:pstree [选项]
命令选项:
- -a:显示每个进程的完整命令,包含路径、参数或是常驻服务的标识
- -c:不使用精简标识法
- -h:列出树状图时,特别标明现在执行的进程
- -H:此参数的效果和指定-h参数类似,但特别标明指定的进程
- -I:采用长列格式显示树状图
- -n:用进程识别码排序。默认是以进程名称来排序
- -p:显示进程号
- -u:显示用户名称
- -U:使用UTF-8列绘图字符
4.top 命令
top命令用于实时显示 process 的动态。
语法:top [选项]
命令选项:
- -d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
- -q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
- -c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
- -S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来
- -s : 安全模式,将交谈式指令取消, 避免潜在的危机
- -i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程
- -n : 更新的次数,完成后将会退出 top
- -b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内
输入top指令后的交互操作说明:
P:以CPU使用率排序,默认是此选项 M:以内存使用率排序 N:以PID排序 q:退出top
5.进程控制
语法:kill [信号代码] PID
功能: kill命令用来终止一个进程。向指定的进程发送信号,是Linux下进程管理的常用命令。通常,终止一个前台进程可以使用Ctrl+C组合键,但是,对于一个后台进程就须用kill命令来终止,就需要先使用ps/pidof/pstree/top等工具获取进程PID,然后使用kill命令来杀掉该进程。kill命令是通过向进程发送指定的信号来结束相应进程的。默认信号为SIGTERM(15),可终止指定的进程。如果仍无法终止该进程,可以使用SIGKILL(9)信号强制终止进程。kill 命令的各信号代码及其功能如下:
- -0:给所有在当前进程组中的进程发送信号
- -1:给所有进程号大于1的进程发送信号
- -9:强行终止进程
- -15(默认):终止进程
- -17:将进程挂起
- -19:将挂起的进程激活
- -a:终止所有进程
- -l:kill-l[signal],指定信号的名称列表。若不加选项,则-l参数会列出全部信号名称
- -P:模拟发送信号。显示进程的ID,不发送信号
- -s:指明发送给进程的信号,例如-9(强行终止),默认发送TERM信号
- -u:指定用户 killall [-signal] <进程名> 杀死指定名字的进程 pkill [options] pattern 通过程序的名字,直接杀死所有进程 xkill 杀死桌面上图形界面的程序
6.进程的优先级
6.1 nice
语法:nice [-n ADJUST] [--adjustment= ADJUST] [--help] [--version] [command [arg...]]
功能:进程的优先级,用nice值来表示。nice命令可以调整程序运行的优先级,让使用者在执进程序时,指定一个优先级,称为nice值(ADJUST)
范围从-20~19,数值越小优先级越高,数值越大优先级越低,默认ADJUST是10。
选项 -n ADJUST 或 --adjustment=ADJUST,功能是将原优先级增加ADJUST。
6.2 renice
语法:renice priority [ [ -p ] pids ] [ [ -g ] pgrps ] [ [ -u ] users ]
功能:renice命令允许用户修改一个正在运行的进程的优先权等级。
例如:将进程PID为456及123的进程与进程拥有者为aaa及root的优先权等级分别加1。
renice +1 456 -u aaa root -p 123
7.系统和服务管理
systemd的主要工具
- systemctl:查询和控制systemd系统和系统服务管理器的状态
- journalctl:查询系统的journal(日志)
- systemd-cgls:以树形列出正在运行的进程,可以递归显示linux控制组内容
7.1 服务启动与停止
systemctl start [unit type] 启动服务
systemctl stop [unit type] 停止服务
systemctl restart [unit type] 重启服务
systemctl status [unit type] 查看服务状态
应用举例:
启动网络服务
systemctl start network.service
停止网络服务
systemctl stop network.service
重启网络服务
systemctl restart network.service
查看网络服务状态
systemctl status network.serivce
7.2 设置开机启动/不启动
systemctl enable [unit type] 设置服务开机启动
systemctl disable [unit type] 设备服务禁止开机启动
应用举例:
停止cup电源管理服务
systemctl stop cups.service
禁止cups服务开机启动
systemctl disable cups.service
查看cups服务状态
systemctl status cups.service
重新设置cups服务开机启动
systemctl enable cups.service
7.3 查看系统上上所有的服务
systemctl 列出所有的系统服务
systemctl list-units 列出所有启动unit
systemctl list-unit-files 列出所有启动文件
systemctl list-units –type=service –all 列出所有service类型的unit
systemctl list-units –type=service –all grep cpu 列出 cpu电源管理机制的服务
systemctl list-units –type=target –all 列出所有target
7.4 电源管理
systemctl poweroff 系统关机
systemctl reboot 重新启动
systemctl suspend 进入睡眠模式
systemctl hibernate 进入休眠模式
systemctl rescue 强制进入救援模式
systemctl emergency 强制进入紧急救援模式
8.服务的运行级别(runlevel)
查看或者修改默认级别:vi /etc/inittab
修改文件里的数字
Linux系统有7种运行级别(runlevel)∶常用的是级别3和5
- 运行级别0∶系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 运行级别1∶单用户工作状态,root权限,用于系统维护,禁止远程登陆
- 运行级别2∶多用户状态(没有NFS),不支持网络
- 运行级别3∶完全的多用户状态(有NFS),登陆后进入控制台命令行模式
- 运行级别4:系统末使用﹔保留
- 运行级别5:X11控制台,登陆后进入图形GUI模式
- 运行级别6∶系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
9.chkconfig指令
介绍:
通过chkconfig命令可以给每个服务的各个运行级别设置自启动/关闭
基本语法:
- 查看某个运行级别里的某个服务:
chkconfig --list | grep 服务名或chkconfig 服务名 --list - 开启或关闭某个运行级别里的某个服务,如:
chkconfig --level 5 服务名 on/off
 查看20道真题和解析
查看20道真题和解析