
面试八股文对校招的用处有多大?数据结构与算法篇
前言
1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。
2.本系列发布内容分为12篇 分别是:
数据结构与算法
GDB
设计模式
操作系统
系统编程
网络原理
网络编程
mysql
redis
服务器
RPG
本文为第二篇,后续会陆续更新。 共计200+道八股文。
3.本系列的200+道为整理的八股文系列的一小部分。完整整理完的八股文面试题共计1000+道,100W字左右,体量太大,故此处放至百度云盘链接: https://pan.baidu.com/s/1IOxQs0ifbSPGgxK7Yz7BtQ?pwd=zl1i
提取码:zl1i 需要的同学自取即可。
4.八股文对于面试的同学来说仅作为参考使用,不能作为面试上岸的唯一准备,还是要结合自身的技术能力和项目,同步发育。
最后祝各位同学都能拿到自己满意的offer,成功上岸!
二、数据结构与算法
01.数组和链表区别和优缺点
1.链表与数组的区别
(1)数组的元素个数是固定的,而组成链表的结点个数可按需要增减;
(2)数组元素的存诸单元在数组定义时分配,链表结点的存储单元在程序执行时动态向系统申请;
(3)数组中的元素顺序关系由元素在数组中的位置(即下标)确定,链表中的结点顺序关系由结点所包含的指针来体现。
(4)对于不是固定长度的列表,用可能最大长度的数组来描述,会浪费许多内存空间。
(5)对于元素的插人、删除操作非常频繁的列表处理场合,用数组表示是不适宜的。若用链表实现,会使程序结构清晰,处理的方法也较为简便。
2.数组的优点
随机访问性强
查找速度快
3.数组的缺点
插入和删除效率低
可能浪费内存
内存空间要求高,必须有足够的连续内存空间。
数组大小固定,不能动态拓展
4.链表的优点
插入删除速度快
内存利用率高,不会浪费内存
大小没有固定,拓展很灵活。
5.链表的缺点
不能随机查找,必须从第一个开始遍历,查找效率低
02.快速排序
1.简介
快速排序是对冒泡排序的一种改进, 它是不稳定的。由C. A. R. Hoare在1962年提出的一种划分交换排序,采用的是分治策略(一般与递归结合使用),以减少排序过程中的比较次数,它的最好情况为O(nlogn),最坏情况为O(n^2),平均时间复杂度为O(nlogn)。
2.基本思想
选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小。然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以达到全部数据变成有序。
3.步骤
(1) 从数列中挑出一个基准值。 (2) 将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边),在这个分区退出之后,该基准就处于数列的中间位置。 (3) 递归地把基准值前面的子数列和基准值后面的子数列进行排序。
注意:基准元素/左游标/右游标都是针对单趟排序而言的, 也就是说在整个排序过程的多趟排序中,各趟排序取得的基准元素/左游标/右游标一般都是不同的。对于基准元素的选取,原则上是任意的,但是一般我们选取数组中第一个元素为基准元素(假设数组随机分布)。
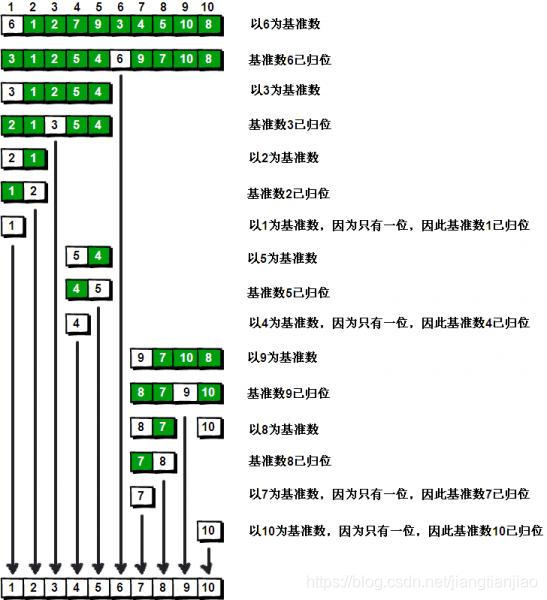
排序过程示意图如下
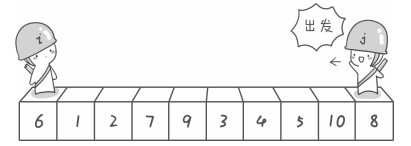
选取上述数组的第一个元素6作为基准元,左游标是 i 哨兵,右游标是 j 哨兵,它们遵循的规则如下: 一、左游标向右扫描, 跨过所有小于基准元素的数组元素, 直到遇到一个大于或等于基准元素的数组元素, 在那个位置停下。二、右游标向左扫描, 跨过所有大于基准元素的数组元素, 直到遇到一个小于或等于基准元素的数组元素,在那个位置停下。
第一步:哨兵 j 先开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵 j 先开始出动,哨兵 j 逐步向左挪动,直到找到一个小于 6 的元素停下来。接下来哨兵 i 再逐步向右挪动,直到找到一个大于 6 的元素停下来。最后哨兵 i 停在了数字 7 面前,哨兵 j 停在了数字 5 面前。
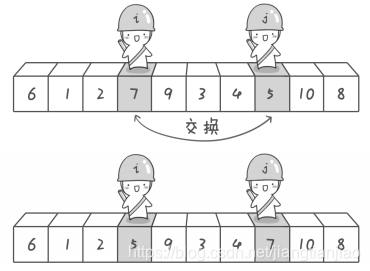
到此第一次交换结束,接着哨兵 j 继续向左移动,它发现 4 比基准数 6 要小,那么在数字4面前停下来。哨兵 i 也接着向右移动,然后在数字 9 面前停下来,然后哨兵 i 和 哨兵 j 再次进行交换。
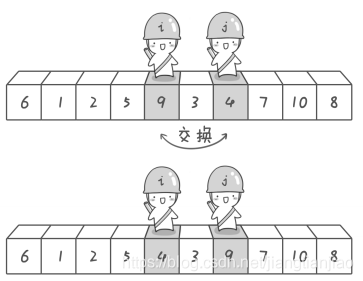
第二次交换结束,哨兵 j 继续向左移动,然后在数字 3 面前停下来;哨兵 i 继续向右移动,但是它发现和哨兵 j 相遇了。那么此时说明探测结束,将数字 3 和基准数字 6 进行交换。
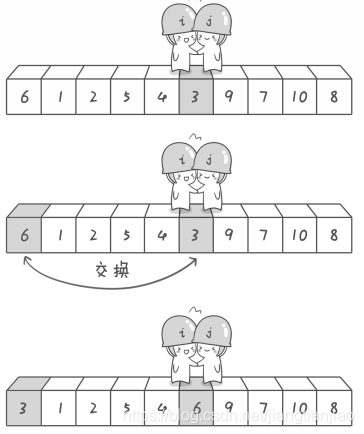
到此第一趟探测真正结束,此时以基准点6为分界线,左边的数组元素都小于等于6,右边的数组元素都大于等于6。左边序列为3,1,2,5,4。右边序列为9,7,10,8。此时对于左边序列而言,以数字3为基准元素,重复上面的探测,探测完毕之后的序列为2,1,3,5,4。对于右边序列而言,以数字9为基准元素,也重复上面的探测,一步一步的划分最后排序完全结束。
快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。 下图描述了整个算法的处理过程。
4.常规快速排序法
public class QuickSort {
// 数组array中下标为i和j位置的元素进行交换
private static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
private static void recQuickSort(int[] array, int left, int right) {
if (right <= left) {
return;
} else {
int partition = partitionIt(array, left, right);
recQuickSort(array, left, partition - 1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归
recQuickSort(array, partition + 1, right); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归
}
}
private static int partitionIt(int[] array, int left, int right) {
// 为什么j加一个1,而i没有加1,是因为下面的循环判断是从--j和++i开始的。
// 而基准元素选的array[left]即第一个元素,所以左游标从第二个元素开始比较。
int i = left;
int j = right + 1;
int pivot = array[left];// pivot为选取的基准元素
while (true) {
while (i < right && array[++i] < pivot) {
}
while (j > 0 && array[--j] > pivot) {
}
if (i >= j) { // 左右游标相遇时停止
break;
} else {
swap(array, i, j); // 左右游标未相遇时交换各自所指元素
}
}
swap(array, left, j); // 基准元素和游标相遇时所指元素交换为最后一次交换
return j; // 一趟排序完成,返回基准元素位置(注意这里基准元素已经交换位置了)
}
public static void sort(int[] array) {
recQuickSort(array, 0, array.length - 1);
}
public static void main(String[] args) {
//int[] array = {7,3,5,2,9,8,6,1,4,7};
int[] array = {9, 9, 8, 7, 6, 5, 4, 3, 2, 1};
sort(array);
for (int i : array) {
System.out.print(i + " ");
}
// 打印结果为:1 2 3 4 5 6 7 7 8 9
}
}
5.三数取中法
避免分组一边倒的情况,比如逆序数组,选取第一个元素作为基准点,即最大元素是基准点,那么第一次循环,左游标要执行到最右边,而右游标执行一次,然后两者进行交换。这也会划分成很多的子数组。
在快排的过程中,每一次我们要取一个元素作为枢纽值,以这个数字来将序列划分为两部分。在此我们采用三数取中法,也就是取左端、中间、右端三个数,然后进行排序,将中间数作为枢纽值。
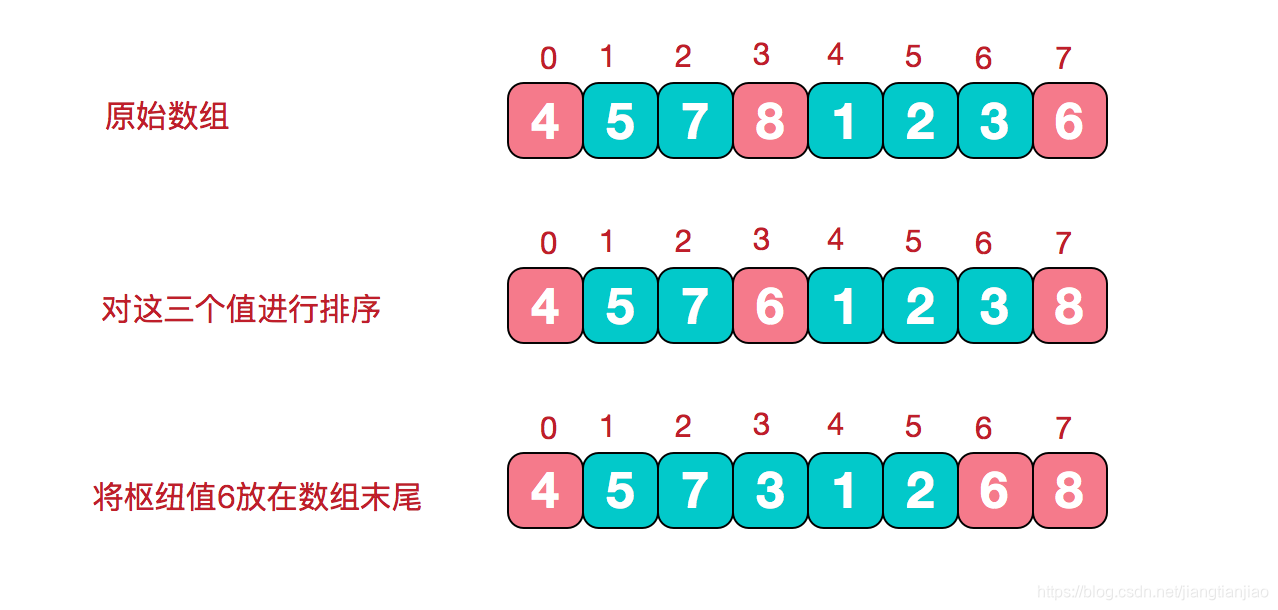
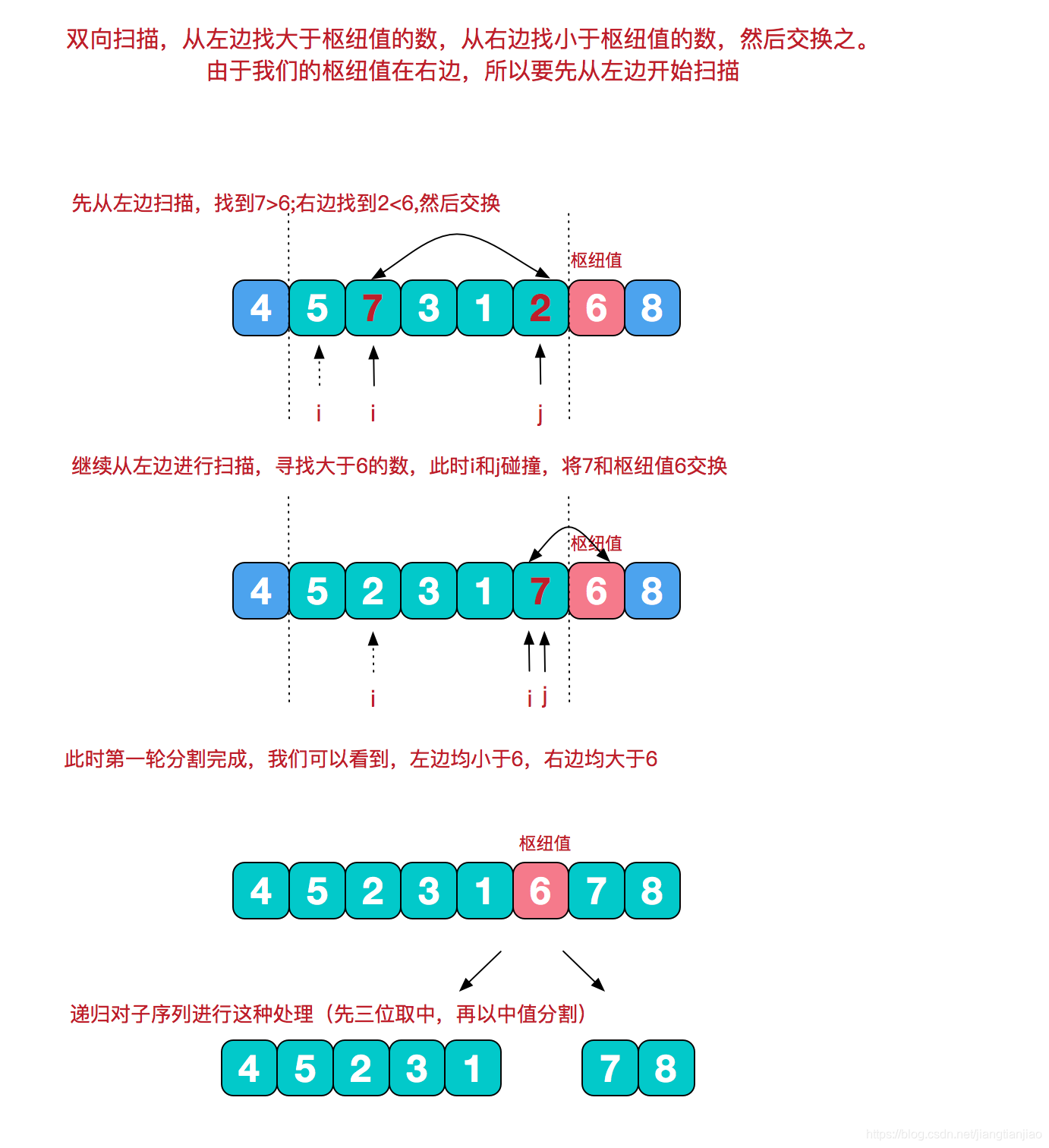
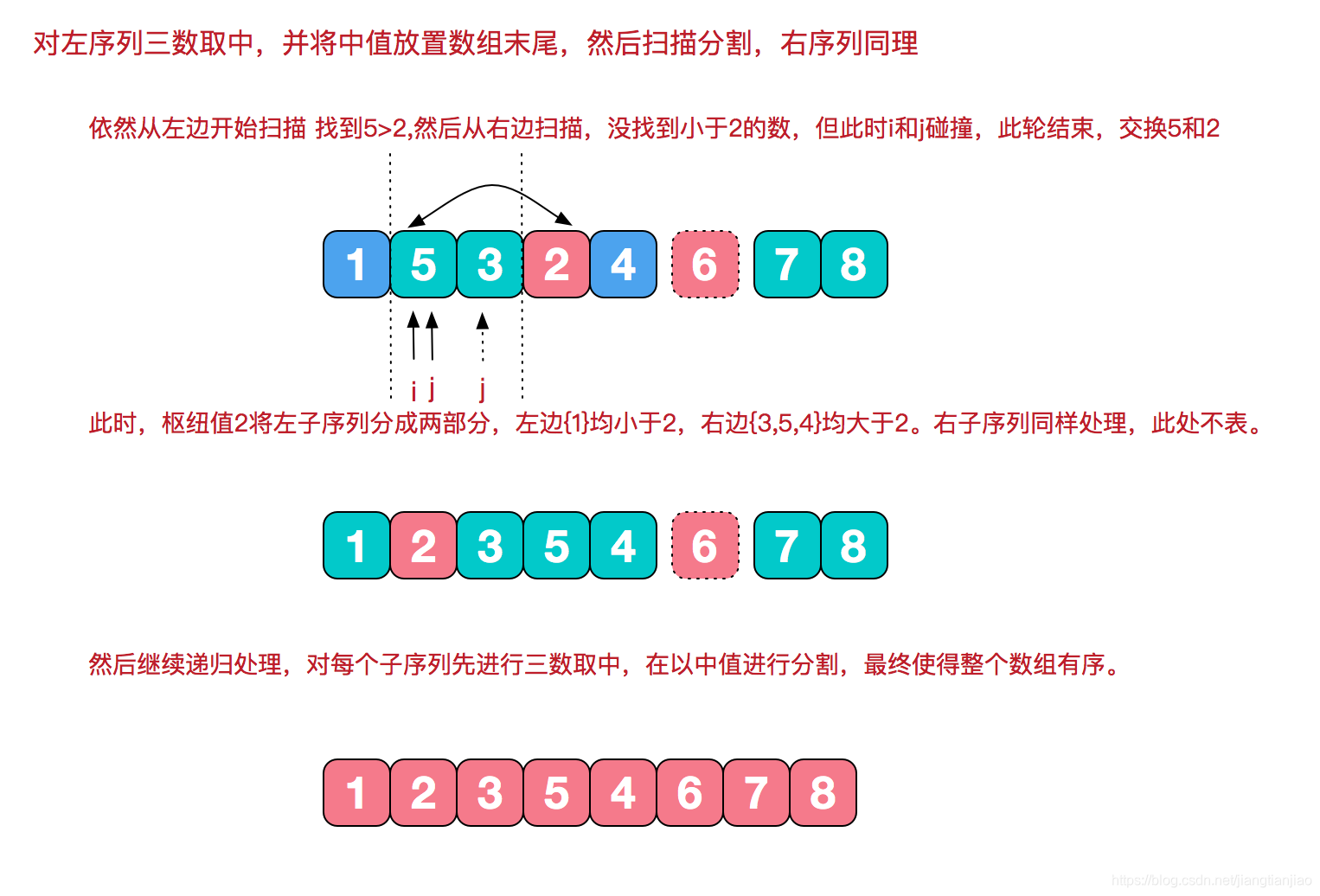
public class QuickSort {
public static void main(String[] args) {
int[] arr = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
quickSort(arr, 0, arr.length - 1);
System.out.println("排序结果:" + Arrays.toString(arr));
}
/**
* @param arr
* @param left 左指针
* @param right 右指针
*/
public static void quickSort(int[] arr, int left, int right) {
if (left < right) {
// 获取枢纽值,并将其放在当前待处理序列末尾
dealPivot(arr, left, right);
// 枢纽值被放在序列末尾
int pivot = right - 1;
int i = left; // 左指针
int j = right - 1; // 右指针
while (true) {
while (arr[++i] < arr[pivot]) {
}
while (j > left && arr[--j] > arr[pivot]) {
}
if (i < j) {
swap(arr, i, j);
} else {
break;
}
}
if (i < right) {
swap(arr, i, right - 1);
}
quickSort(arr, left, i - 1);
quickSort(arr, i + 1, right);
}
}
/**
* 处理枢纽值
*
* @param arr
* @param left
* @param right
*/
public static void dealPivot(int[] arr, int left, int right) {
int mid = (left + right) / 2;
if (arr[left] > arr[mid]) {
swap(arr, left, mid);
}
if (arr[left] > arr[right]) {
swap(arr, left, right);
}
if (arr[right] < arr[mid]) {
swap(arr, right, mid);
}
swap(arr, right - 1, mid);
}
/**
* 交换元素通用处理
*
* @param arr
* @param a
* @param b
*/
private static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
03.堆排序是怎么做的
堆是一种叫做完全二叉树[1]的数据结构。
1.堆的性质
- 大顶堆:每个节点的值都大于或者等于它的左右子节点的值: arr[i] >= arr[2i + 1] && arr[i] >= arr[2i + 2]
- 小顶堆:每个节点的值都小于或者等于它的左右子节点的值: arr[i] <= arr[2i + 1] && arr[i] <= arr[2i + 2]
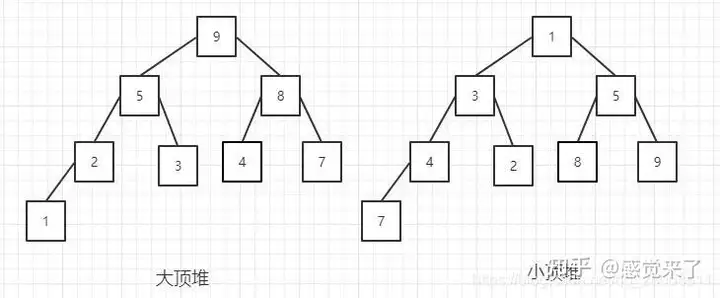
把这种逻辑结构映射到数组: [9, 5, 8, 2, 3, 4, 7, 1] 和 [1, 3, 5, 4, 2, 8, 9, 7]
2.堆排序
堆排序的基本思想是:
- 将带排序的序列构造成一个大顶堆,根据大顶堆的性质,当前堆的根节点(堆顶)就是序列中最大的元素;
- 将堆顶元素和最后一个元素交换,然后将剩下的节点重新构造成一个大顶堆;
- 重复步骤2,如此反复,从第一次构建大顶堆开始,每一次构建,我们都能获得一个序列的最大值,然后把它放到大顶堆的尾部。最后,就得到一个有序的序列了。
举例演示过程:
假设给定的无序序列arr是:【4, 5, 8, 2, 3, 9, 7, 1】
- 1 将无序序列构建成一个大顶堆。
首先我们将现在的无序序列看成一个堆结构,一个没有规则的二叉树,将序列里的值按照从上往下,从左到右依次填充到二叉树中
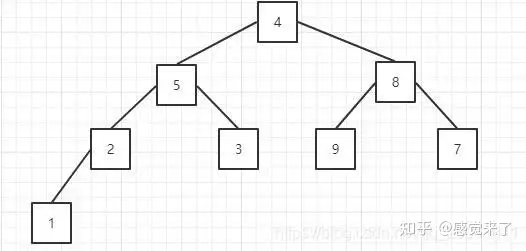
根据大顶堆的性质,每个节点的值都大于或者等于它的左右子节点的值。从下往上的方式不需要考虑父节点,因为当前节点调整完之后,当前节点必然比它的所有子节点都大。
如何知道最后一个非叶子节点的位置,也就是索引值?
对于一个完全二叉树,在填满的情况下(非叶子节点都有两个子节点),每一层的元素个数是上一层的二倍,根节点数量是1,所以最后一层的节点数量,一定是之前所有层节点总数+1,所以,我们能找到最后一层的第一个节点的索引,即节点总数/2(根节点索引为0),这也就是第一个叶子节点,所以第一个非叶子节点的索引就是第一个叶子结点的索引-1。那么对于填不满的二叉树呢?这个计算方式仍然适用,当我们从上往下,从左往右填充二叉树的过程中,第一个叶子节点,一定是序列长度/2,所以第一个非叶子节点的索引就是arr.length / 2 -1。
现在找到了最后一个非叶子节点,即元素值为2的节点,比较它的左右节点的值,是否比他大,如果大就换位置。这里因为1<2,所以,不需要任何操作,继续比较下一个,即元素值为8的节点,它的左节点值为9比它本身大,所以需要交换:
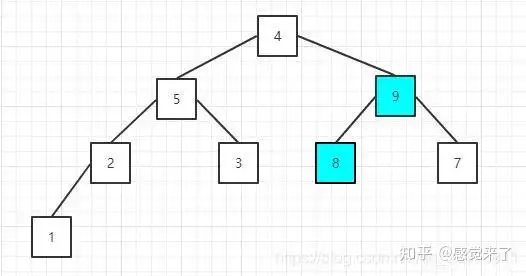
交换后的序列:[4 5 9 2 3 8 7 1]
因为元素8没有子节点,所以继续比较下一个非叶子节点,元素值为5的节点,它的两个子节点值都比本身小,不需要调整;然后是元素值为4的节点,也就是根节点,因为9>4,所以需要调整位置
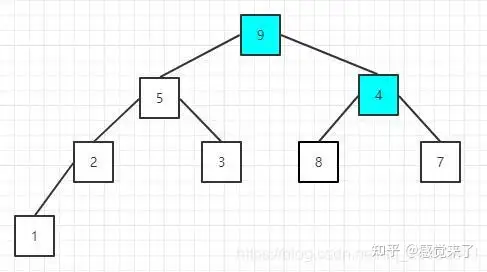
交换后的序列为:[9 5 4 2 3 8 7 1]
此时,原来元素值为9的节点值变成4了,而且它本身有两个子节点,所以,这时需要再次调整该节点
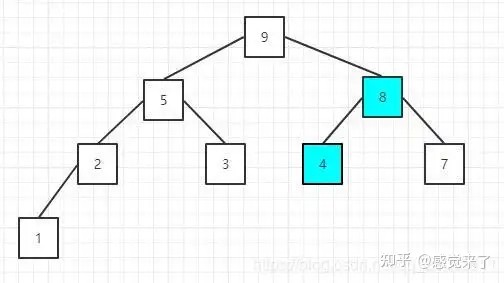
交换后的序列为:[9 5 8 2 3 4 7 1]
到此,大顶堆就构建完毕了。满足大顶堆的性质。
- 2 排序序列,将堆顶的元素值和尾部的元素交换
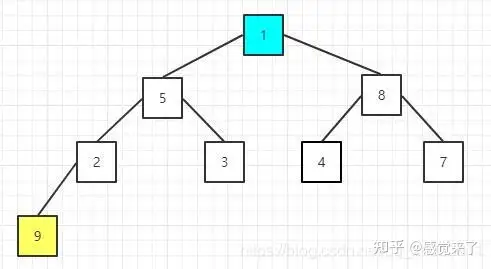
交换后的序列为:[1 5 8 2 3 4 7 9]
然后将剩余的元素重新构建大顶堆,其实就是调整根节点以及其调整后影响的子节点,因为其他节点之前已经满足大顶堆性质。
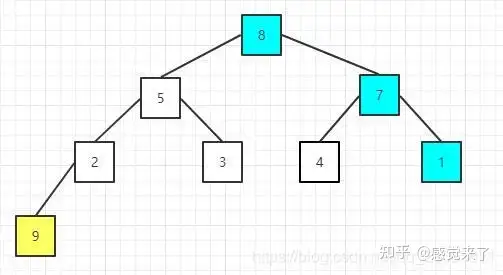
交换后的序列为:[8 5 7 2 3 4 1 9]
然后,继续交换,堆顶节点元素值为8与当前尾部节点元素值为1的进行交换
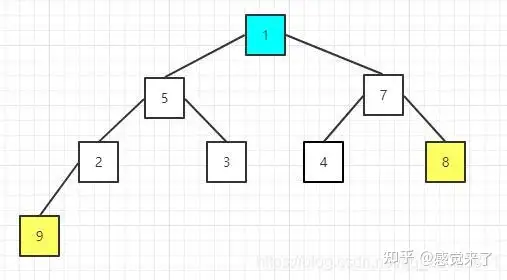
交换后的序列为:[1 5 7 2 3 4 8 9]
重新构建大顶堆
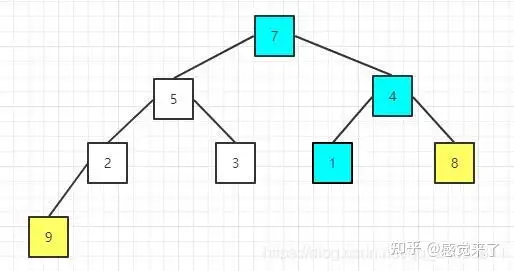
交换后的序列为:[7 5 4 2 3 1 8 9]
重复上述过程,直至数组所有遍历一遍:
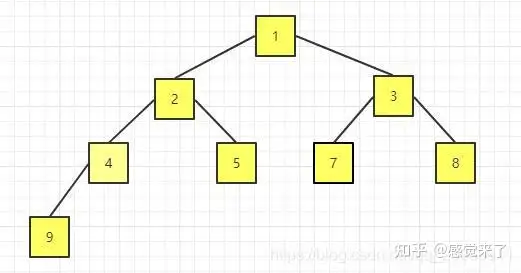
交换后的序列为:[1 2 3 4 5 7 8 9]
3.堆排序的代码实现
# 堆排序
import math
import heapq
class HeapSort(object):
def heapSort(self, arr):
if not arr or len(arr) == 0:
return
N = len(arr)
# 构建大顶堆,这里就是把排序序列,变成一个大顶堆结构数组
self.buildMaxHeap(arr, N)
# 交换堆顶和当前末尾的节点,重置大顶堆
for i in range(N - 1, -1, -1):
self.swap(arr, 0, i)
N -= 1
self.buildMaxHeap(arr, N)
return arr
def buildMaxHeap(self, arr, N):
# 从最后一个非叶节点开始向前遍历,调整节点性质,使之成为大顶堆
for i in range(math.floor(N / 2) - 1, -1, -1):
self.heapify(arr, i, N)
def heapify(self, arr, i, N):
# 先根据堆性质, 找出它左右节点的索引
left = 2 * i + 1
right = 2 * i + 2
largestIndex = i # 默认当前节点(父节点)是最大值
if left < N and arr[left] > arr[largestIndex]:
largestIndex = left
if right < N and arr[right] > arr[largestIndex]:
largestIndex = right
if largestIndex != i:
# 如果最大值不是当前非叶子节点的值,那么就把当前节点和最大值的子节点值互换
self.swap(arr, i, largestIndex)
# 因为互换之后,子节点的值变了,如果该子节点也有自己的子节点,仍需要再次调整。
self.heapify(arr, largestIndex, N)
def swap(self, arr, i, j):
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
def python_func(self, arr):
# python 堆排序的函数库
heap = []
for num in arr:
heapq.heappush(heap, num)
heapsort = [heapq.heappop(heap) for _ in range(len(heap))]
print(heapsort)
if __name__ == '__main__':
so = HeapSort()
arr = [4, 5, 8, 2, 3, 9, 7, 1, 1]
print(so.heapSort(arr))
print(so.python_func(arr))
4. 复杂度分析
因为堆排序无关乎初始序列是否已经排序已经排序的状态,始终有两部分过程,构建初始的大顶堆的过程时间复杂度为O(n),交换及重建大顶堆的过程中,需要交换n-1次,重建大顶堆的过程根据完全二叉树的性质,[log2(n-1),log2(n-2)...1]逐步递减,近似为nlogn。所以它最好和最坏的情况时间复杂度都是O(nlogn),空间复杂度O(1)。
04.冒泡排序
冒泡排序是一种简单的排序算法,它也是一种稳定排序算法。其实现原理是重复扫描待排序序列,并比较每一对相邻的元素,当该对元素顺序不正确时进行交换。一直重复这个过程,直到没有任何两个相邻元素可以交换,就表明完成了排序。
一般情况下,称某个排序算法稳定,指的是当待排序序列中有相同的元素时,它们的相对位置在排序前后不会发生改变。
假设待排序序列为 (5,1,4,2,8),如果采用冒泡排序对其进行升序(由小到大)排序,则整个排序过程如下所示: \1) 第一轮排序,此时整个序列中的元素都位于待排序序列,依次扫描每对相邻的元素,并对顺序不正确的元素对交换位置,整个过程如图 1 所示。
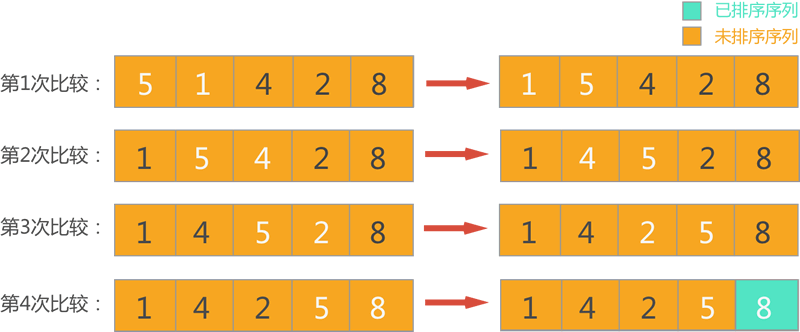 图 1 第一轮排序(白色字体表示参与比较的一对相邻元素)
图 1 第一轮排序(白色字体表示参与比较的一对相邻元素)
从图 1 可以看到,经过第一轮冒泡排序,从待排序序列中找出了最大数 8,并将其放到了待排序序列的尾部,并入已排序序列中。
\2) 第二轮排序,此时待排序序列只包含前 4 个元素,依次扫描每对相邻元素,对顺序不正确的元素对交换位置,整个过程如图 2 所示。
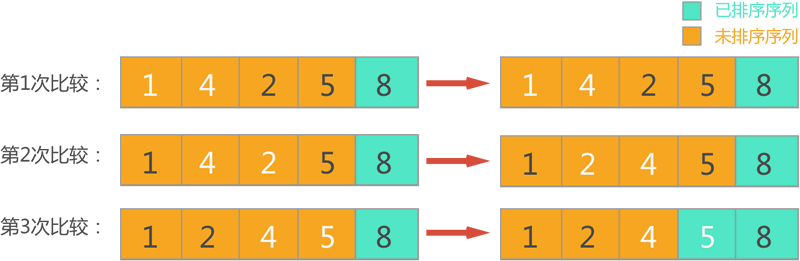 图 2 第二轮排序
图 2 第二轮排序
可以看到,经过第二轮冒泡排序,从待排序序列中找出了最大数 5,并将其放到了待排序序列的尾部,并入已排序序列中。
\3) 第三轮排序,此时待排序序列包含前 3 个元素,依次扫描每对相邻元素,对顺序不正确的元素对交换位置,整个过程如图 3 所示。
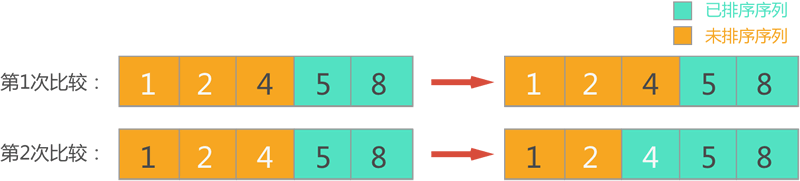 图 3 第三轮排序
图 3 第三轮排序
经过本轮冒泡排序,从待排序序列中找出了最大数 4,并将其放到了待排序序列的尾部,并入已排序序列中。
\4) 第四轮排序,此时待排序序列包含前 2 个元素,对其进行冒泡排序的整个过程如图 4 所示。
 图 4 第四轮排序
图 4 第四轮排序
经过本轮冒泡排序,从待排序序列中找出了最大数 2,并将其放到了待排序序列的尾部,并入已排序序列中。
\5) 当进行第五轮冒泡排序时,由于待排序序列中仅剩 1 个元素,无论再进行相邻元素的比较,因此直接将其并入已排序序列中,此时的序列就认定为已排序好的序列(如图 5 所示)。
 图 5 冒泡排序好的序列
图 5 冒泡排序好的序列
冒泡排序的实现代码为(C 语言):
#include <stdio.h>
//交换 a 和 b 的位置的函数
#define N 5
int a[N] = { 5,1,4,2,8 };
void swap(int *a, int *b);
//这是带输出的冒泡排序实现函数,从输出结果可以分析冒泡的具体实现流程
void BubSort_test();
//这是不带输出的冒泡排序实现函数,通过此函数,可直接对数组 a 中元素进行排序
void BubSort_pro();
int main()
{
BubSort_test();
return 0;
}
void swap(int *a, int *b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
}
//这是带输出的冒泡排序实现函数,从输出结果,可以看到冒泡的具体实现流程
void BubSort_test() {
for (int i = 0; i < N; i++) {
//对待排序序列进行冒泡排序
for (int j = 0; j + 1 < N - i; j++) {
//相邻元素进行比较,当顺序不正确时,交换位置
if (a[j] > a[j + 1]) {
swap(&a[j], &a[j + 1]);
}
}
//输出本轮冒泡排序之后的序列
printf("第%d轮冒泡排序:", i + 1);
for (int i = 0; i < N; i++) {
printf("%d ", a[i]); }
printf("\n");
}
}
//这是不带输出的冒泡排序实现函数,通过此函数,可直接对数组 a 中元素进行排序
void BubSort_pro() {
for (int i = 0; i < N; i++) {
//对待排序序列进行冒泡排序
for (int j = 0; j + 1 < N - i; j++) {
//相邻元素进行比较,当顺序不正确时,交换位置
if (a[j] > a[j + 1]) {
swap(&a[j], &a[j + 1]);
}
}
}
}
运行结果为:
第1轮冒泡排序:1 4 2 5 8
第2轮冒泡排序:1 2 4 5 8
第3轮冒泡排序:1 2 4 5 8
第4轮冒泡排序:1 2 4 5 8
第5轮冒泡排序:1 2 4 5 8
通过分析冒泡排序的实现代码可以得知,该算法的最差时间复杂度为O(n2),最优时间复杂度为O(n),平均时间复杂度为 O(n2)。
05.二分查找(复杂度)
1、什么是二分查找?
二分查找又叫折半查找,是一种高效简单的查找算法,通常用于在有序的数组中查找某个元素,例如从{1,2,4,6,8,9,10,23,24}的数组中中查找值是8的元素,就可以采用二分查找法。
2、二分查找的思想是什么?
二分查找的思想:给你一个有序的序列,取中间元素和目标元素进行对比,取其中的一半,丢弃另一半,快速缩小目标元素所在的位置。主要思想还是:快速缩小目标元素所在的区间。
3、二分查找的前置条件是什么?
在序列中查找某个数,采用二分查找法,则该序列应该满足的条件是:
3.1 序列必须是有序的,升序或者降序都可以,这个条件主要是二分查找时需要和序列中的中间元素进行比较来排除一半的元素,如果是无序的,则比较无意义 。
3.2 序列必须是顺序存储元素的,顺序存储元素主要是可以快速的获取中间元素(可以通过索引),不然只能通过遍历来获取中间的元素,但是这种做法无意义,因为直接找该元素的时间复杂度为O(n),遍历获取中间元素再比较还不如直接查找。
以上两个条件都满足的最常见的数据结构就是:有序数组。
4、二分查找的步骤是什么?
在序列中查找某个元素,二分查找步骤为:
- 序列的长度为0或者为null,或者目标元素不存在返回-1
- 取出序列的中间元素将其和目标元素进行对比,如果相同则返回中间元素的索引
- 如果中间元素大于目标元素,则目标元素所在区域在中间元素的左侧,则将左侧的序列作为一个新的序列,从步骤1重新开始
- 如果中间元素小于目标元素,则目标元素所在区域在中间元素的右侧,则将右侧的序列作为一个新的序列,从步骤1重新开始。
5、二分查找的代码
普通的二分查找:
private static int binarySearch(int[] arr, int target) {
if (arr == null || arr.length == 0) {
return -1;
}
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int middle = (low + high) / 2;
if (arr[middle] == target) {
return middle;
} else if (arr[middle] > target) {
high = middle - 1;
} else if (arr[middle] < target) {
low = middle + 1;
}
}
return -1;
}
递归的二分查找:
private static int binarySearch(int[] arr, int low, int high, int target) {
if (low <= high) {
int middle = (low + high) / 2;
if (arr[middle] == target) {
return middle;
} else if (arr[middle] > target) {
return binarySearch(arr, low, middle - 1, target);
} else if (arr[middle] < target) {
return binarySearch(arr, middle + 1, high, target);
}
}
return -1;
}
6、二分查找的总结
二分查找的时间复杂度为:O(logn),空间复杂度为:O(1) 序列必须是有序和顺序存储的,比如有序数组
7、二分查找的类比
二分查找类似于:寻找一张纸上的一个点,可以确定其在哪一边,我们的方法是对折,查找,对折,再查找,简单高效。
06.hash表数据很大。rehash的代价很高,怎么办
当哈希表的数据量很大时,确实会面临rehash代价高的问题。为了解决这个问题,可以考虑以下两种方法:
- 增加初始容量:在创建哈希表时,可以设置一个较大的初始容量,这样可以减少扩容的次数和代价。同时,在插入元素时,也可以提前预留一定的空间。
- 使用增量式rehash:将rehash操作分批进行,每次只将部分桶中的数据搬移到新哈希表中,并且在该阶段内维护两个哈希表。通过这种方式可以避免一次性大规模地重新哈希所有数据造成的代价高昂问题。
07.二叉树前序遍历非递归
二叉树前序遍历
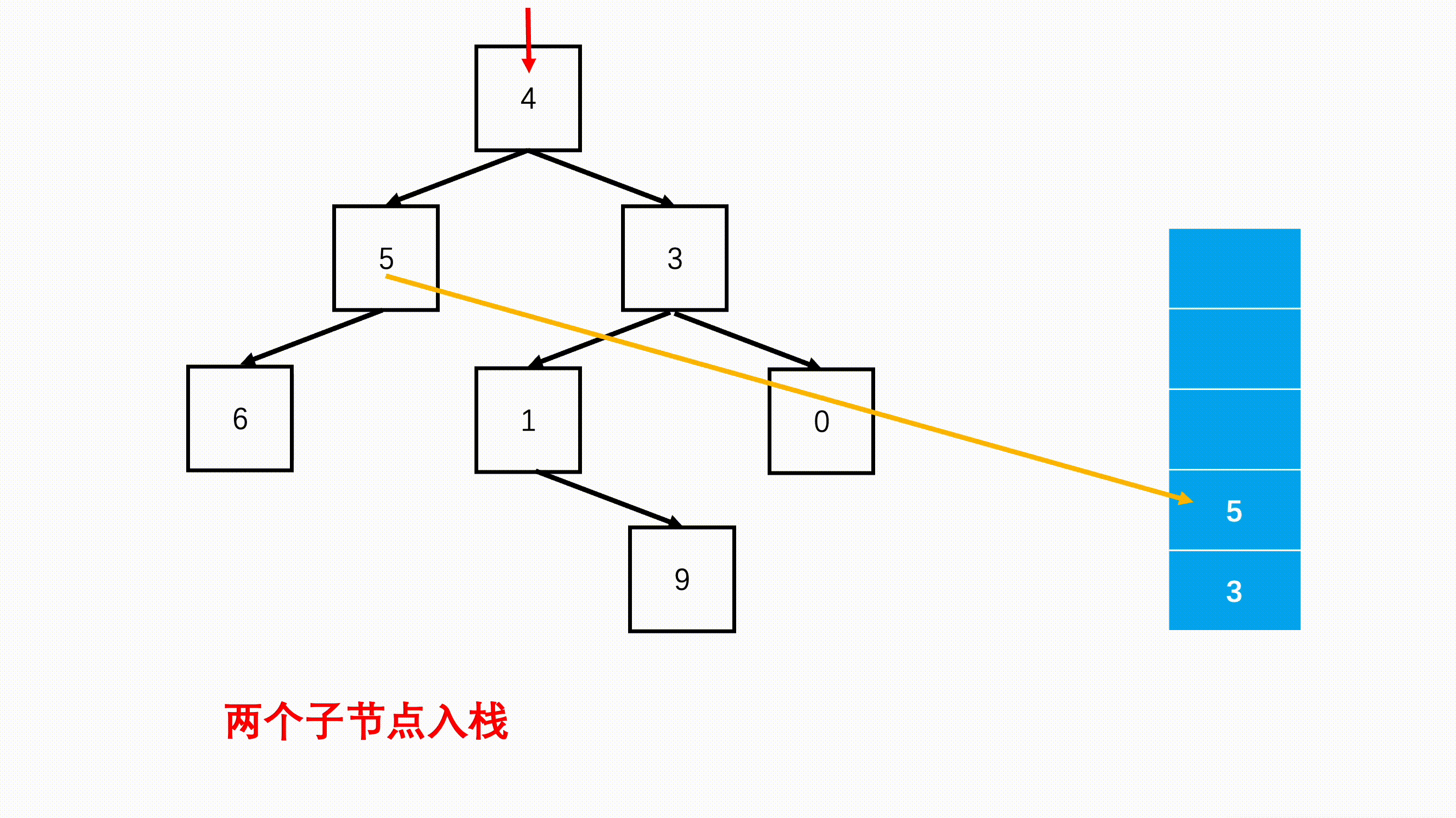
口诀:根左右
知识点:栈
栈是一种仅支持在表尾进行插入和删除操作的线性表,这一端被称为栈顶,另一端被称为栈底。元素入栈指的是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;元素出栈指的是从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
思路:
我们都知道递归,是不断调用自己,计算内部实现递归的时候,是将之前的父问题存储在栈中,先去计算子问题,等到子问题返回给父问题后再从栈中将父问题弹出,继续运算父问题。因此能够递归解决的问题,我们似乎也可以用栈来试一试。
根据前序遍历“根左右”的顺序,首先要遍历肯定是根节点,然后先遍历左子树,再遍历右子树。递归中我们是先进入左子节点作为子问题,等左子树结束,再进入右子节点作为子问题。
具体做法:
- step 1:优先判断树是否为空,空树不遍历。
- step 2:准备辅助栈,首先记录根节点。
- step 3:每次从栈中弹出一个元素,进行访问,然后验证该节点的左右子节点是否存在,存的话的加入栈中,优先加入右节点。
import java.util.*;
public class Solution {
public int[] preorderTraversal (TreeNode root) {
//添加遍历结果的数组
List<Integer> list = new ArrayList();
Stack<TreeNode> s = new Stack<TreeNode>();
//空树返回空数组
if(root == null)
return new int[0];
//根节点先进栈
s.push(root);
while(!s.isEmpty()){
//每次栈顶就是访问的元素
TreeNode node = s.pop();
list.add(node.val);
//如果右边还有右子节点进栈
if(node.right != null)
s.push(node.right);
//如果左边还有左子节点进栈
if(node.left != null)
s.push(node.left);
}
//返回的结果
int[] res = new int[list.size()];
for(int i = 0; i < list.size(); i++)
res[i] = list.get(i);
return res;
}
}
关键点:为了能保证下一轮优先访问左节点,优先将右节点推入栈中。
优先将右子节点挂入栈中,然后下一轮先访问左子节点。同样将它挂入栈中,依据栈的后进先出原则,下一轮循环必然它要先出来,如此循环,原先父问题的右子节点被不断推入栈深处,只有左子树全部访问完毕,才会弹出继续访问。
小结:
在二叉树的遍历中,尤其是深度优先搜索(DFS),递归是最常用的一种解法,但是往往有的时候,不要求我们用递归的方式进行求解。通过非递归的方式,去遍历二叉树,那么这个时候,我们一定要想到用栈去代替递归,记住遍历的顺序。就能解决这类的问题。
同时,中序和后序也是利用栈的特点进行非递归的遍历。值得我们反复练习。
08.链表反转
-
反转链表总体有两种方法,迭代与递归,在迭代过程中需要注意细节,比如反转链表需要同时跟踪两个节点,递归需要注意临界条件与递归函数的意义。
-
本题中,迭代方法实时跟踪pre与cur节点,并实时更新,比较巧妙的是pre节点初始值的设置
-
而递归,需要理解递归函数的意义,也就是返回的是反转链表的头节点,以及本节点next的设置
-
本题相较上面一题控制为链表区间反转,同样有两个思路
-
迭代:
-
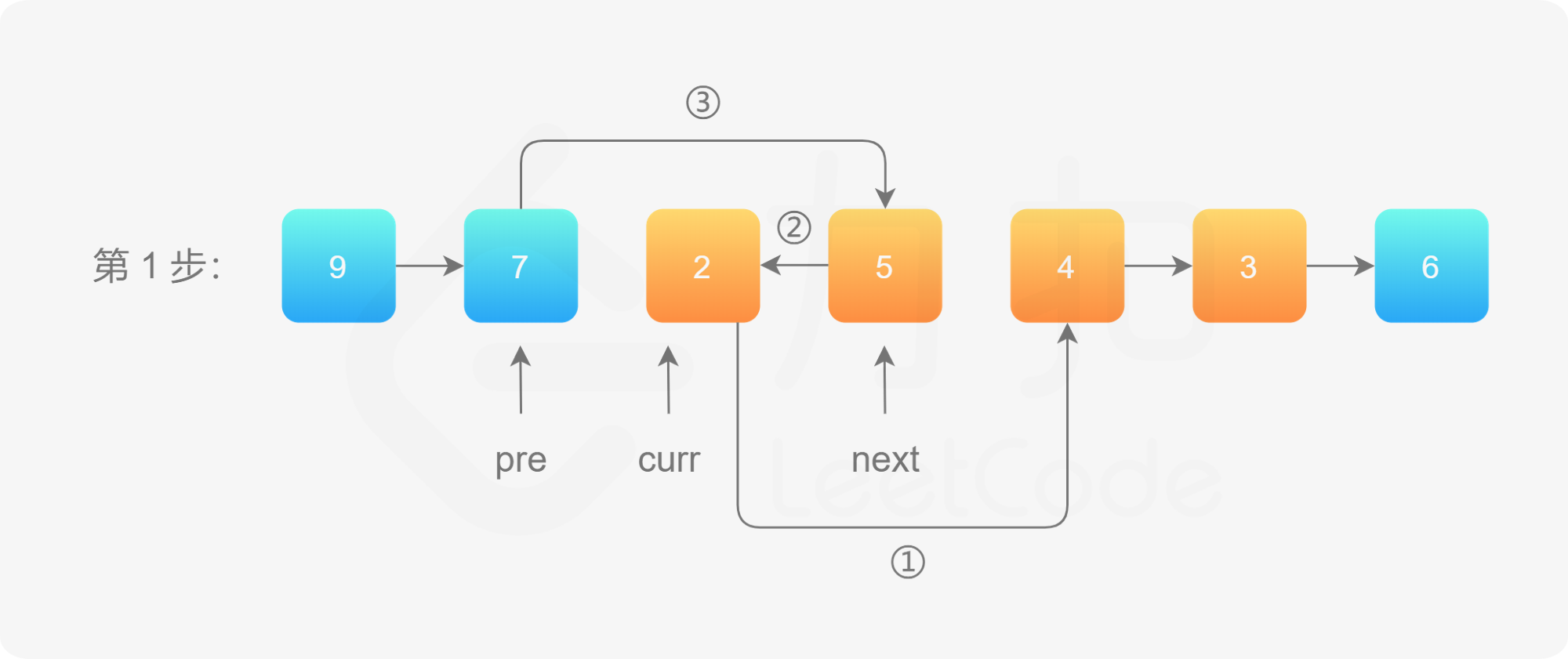
-
将curr节点的下一个节点插入到pre节点之后
-
需要考量的是边界,如果整个链表反转,在原链表之上是无法进行的,需要加入哨兵
-
// 设置 dummyNode 是这一类问题的一般做法 ListNode dummyNode = new ListNode(-1); dummyNode.next = head; ListNode pre = dummyNode; for (int i = 0; i < left - 1; i++) { pre = pre.next; //跟踪到指定位置 } ListNode cur = pre.next; ListNode next; for (int i = 0; i < right - left; i++) { //穿针引线 next = cur.next; cur.next = next.next; next.next = pre.next; pre.next = next; } return dummyNode.next;
-
-
哨兵技巧
-
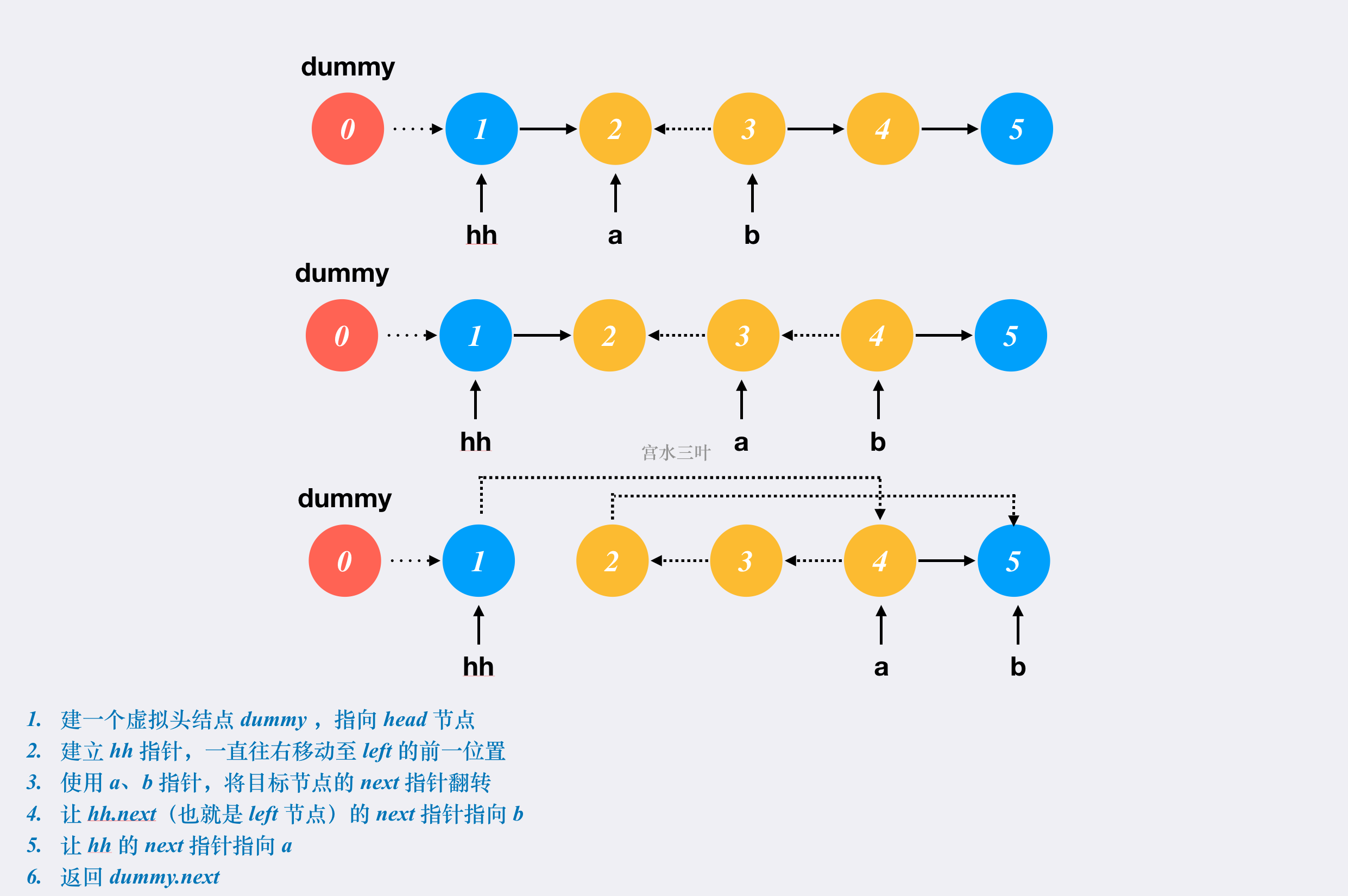
-
ListNode dummy = new ListNode(0); dummy.next = head; r -= l; ListNode hh = dummy; while (l-- > 1) hh = hh.next; ListNode a = hh.next, b = a.next; while (r-- > 0) { ListNode tmp = b.next; b.next = a; a = b; b = tmp; } hh.next.next = b; hh.next = a; return dummy.next;
-
-
迭代方法的一点思考,迭代过程中需要至少跟踪两组信息方便反转,同时在本题中由于是区间反转,还需要记录反转开始,而反转的开始考虑到临界条件,可以通过设置哨兵解决。
-
-
递归
-
反转整个链表是非常轻松的,如果反转链表前面指定长度的一部分呢?
-
需要记录长度信息:
-
ListNode successor = null; // 后驱节点 // 反转以 head 为起点的 n 个节点,返回新的头结点 ListNode reverseN(ListNode head, int n) { if (n == 1) { // 记录第 n + 1 个节点 successor = head.next; return head; } // 以 head.next 为起点,需要反转前 n - 1 个节点 ListNode last = reverseN(head.next, n - 1); head.next.next = head; // 让反转之后的 head 节点和后面的节点连起来 head.next = successor; return last; } -
现在我们已经知道了反转前N个节点,我们可以找到需要反转的部分链表的头信息,反转指定长度即可
-
ListNode reverseBetween(ListNode head, int m, int n) { // base case if (m == 1) { return reverseN(head, n); } // 前进到反转的起点触发 base case head.next = reverseBetween(head.next, m - 1, n - 1); return head; }
-
09.二叉树输出每一层最右边的节点
二叉树输出每一层最右边的节点,可以使用层次遍历来实现。在层次遍历过程中,记录每一层最后一个访问的节点即可。
具体实现步骤如下:
- 创建一个队列,并将根节点入队;
- 循环遍历队列,当队列不为空时进行以下操作:
- 遍历当前队列中的所有节点,将它们的左右子节点依次入队;
- 记录当前队列中最后一个访问的节点。
- 将每一层的最后一个节点加入结果集并返回。
代码实现如下:
java复制代码public List<TreeNode> getRightNodes(TreeNode root) {
List<TreeNode> res = new ArrayList<>();
if (root == null) {
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int size = queue.size();
TreeNode rightmost = null; // 记录每一层最右边的结点
for (int i = 0; i < size; i++) {
TreeNode curr = queue.poll();
if (curr.left != null) {
queue.offer(curr.left);
}
if (curr.right != null) {
queue.offer(curr.right);
}
rightmost = curr; // 更新rightmost为当前结点
}
res.add(rightmost); // 将该层最右边的结点加入结果集
}
return res;
}
时间复杂度:O(n),其中n为二叉树节点数,因为每个节点只会被访问一次。
空间复杂度:O(m),其中m为二叉树最大宽度,即队列中的元素个数。在最坏情况下,队列中同时存储了所有叶子节点,即m=n/2(完全二叉树)。
10.千万级数组如何求最大k个数?(用最小堆反之最大堆)千万数据范围有限,0到1000,有很多重复的,按频率排序怎么处理?
针对千万级数组求最大k个数,可以使用最小堆实现。
具体步骤如下:
- 创建一个大小为k的最小堆(Java中可以使用PriorityQueue来实现);
- 遍历整个数组,将每个元素加入到堆中;
- 如果堆的大小超过了k,则弹出堆顶元素(即当前最小值);
- 遍历完整个数组后,堆中剩余的k个元素就是原始数组中的最大k个数。
代码实现如下:
java复制代码public static List<Integer> getTopK(int[] nums, int k) {
PriorityQueue<Integer> minHeap = new PriorityQueue<>(k); // 创建大小为k的最小堆
for (int num : nums) {
minHeap.offer(num); // 将num加入到堆中
if (minHeap.size() > k) {
minHeap.poll(); // 如果堆的大小超过了k,则弹出堆顶元素
}
}
List<Integer> res = new ArrayList<>(minHeap);
Collections.sort(res, Collections.reverseOrder()); // 最后将结果从大到小排序
return res;
}
时间复杂度:O(nlogk),其中n为数组长度。因为每次插入和删除操作都要花费log(k)的时间,而一共进行n次操作。
空间复杂度:O(k),因为需要维护一个大小为k的最小堆。
对于有重复元素且按频率排序的问题,可以使用HashMap来统计每个元素出现的频率,并将元素和其对应的频率存储在一个自定义类中。然后再以此类作为元素插入到最小堆中。
具体步骤如下:
- 创建一个HashMap,遍历整个数组,在HashMap中统计每个元素出现的频率;
- 创建一个大小为k的最小堆(Java中可以使用PriorityQueue来实现);
- 遍历HashMap,将其中所有元素按照出现频率加入到堆中;
- 如果堆的大小超过了k,则弹出堆顶元素(即当前最小值);
- 遍历完整个HashMap后,堆中剩余的k个元素就是原始数组中出现频率最高的k个数。
代码实现如下:
java复制代码public static List<Integer> getTopKFrequent(int[] nums, int k) {
Map<Integer, Integer> frequency = new HashMap<>();
for (int num : nums) {
frequency.put(num, frequency.getOrDefault(num, 0) + 1); // 统计每个数字出现的次数
}
PriorityQueue<Map.Entry<Integer, Integer>> minHeap = new PriorityQueue<>(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o1.getValue() - o2.getValue(); // 按照value从小到大排序
}
});
for (Map.Entry<Integer, Integer> entry : frequency.entrySet()) {
minHeap.offer(entry); // 将entry加入到堆中
if (minHeap.size() > k) {
minHeap.poll(); // 如果堆的大小超过了k,则弹出堆顶元素
}
}
List<Integer> res = new ArrayList<>();
while (!minHeap.isEmpty()) {
res.add(minHeap.poll().getKey()); // 将所有元素从小到大取出并加入结果集中
}
Collections.reverse(res); // 最后将结果反转为从大到小排序
return res;
}
时间复杂度:O(nlogk),其中n为数组长度。因为HashMap的遍历和PriorityQueue的操作都需要花费log(k)的时间,而一共进行n次操作。
空间复杂度:O(n+k),因为需要维护一个大小为k的最小堆和一个HashMap来存储每个元素出现的频率。
11.计算二叉树层高
计算二叉树的层高可以使用递归或迭代两种方法。
- 递归
计算二叉树的层高,可以通过递归遍历二叉树的每一层,并将每个节点的左右子节点分别作为一个新的子树进行递归。最终得到的结果是整个树中左右子树层数的较大值加上1,即为该二叉树的层高。
代码如下:
java复制代码public static int getDepth(TreeNode root) {
if (root == null) {
return 0;
}
int leftDepth = getDepth(root.left); // 左子树深度
int rightDepth = getDepth(root.right); // 右子树深度
return Math.max(leftDepth, rightDepth) + 1; // 返回左右子树深度较大值加上1
}
时间复杂度:O(n),其中n为二叉树中节点数。
空间复杂度:O(h),其中h为二叉树的高度,递归时系统调用堆栈所需空间。
- 迭代
使用迭代方式计算二叉树的层高,则需要借助队列数据结构来保存每一层中所有节点信息。首先将整棵二叉树的跟节点入队,然后在循环体中依次取出队列头部元素,并将其左右子节点入队,同时记录下每一层节点的个数。当队列为空时,所记录的层数即为二叉树的层高。
代码如下:
java复制代码public static int getDepth(TreeNode root) {
if (root == null) {
return 0;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int depth = 0;
while (!queue.isEmpty()) {
depth++; // 记录当前层数
int levelSize = queue.size(); // 记录当前层中节点数
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
if (node.left != null) {
queue.offer(node.left); // 将左子节点入队
}
if (node.right != null) {
queue.offer(node.right); // 将右子节点入队
}
}
}
return depth;
}
时间复杂度:O(n),其中n为二叉树中节点数。
空间复杂度:O(w),其中w为二叉树最大宽度(即所有层中节点个数的最大值),需要使用队列来保存每一层中的所有节点信息。
12.给一个连续非空子数组,找它乘积最大的(动态规划)
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 32-位 整数。
子数组 是数组的连续子序列。
示例 1:
输入: nums = [2,3,-2,4] 输出: 6 解释: 子数组 [2,3] 有最大乘积 6。 示例 2:
输入: nums = [-2,0,-1] 输出: 0 解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
提示:
1 <= nums.length <= 2 * 1 0 4 10^410 4
-10 <= nums[i] <= 10 nums 的任何前缀或后缀的乘积都 保证 是一个 32-位 整数
刚开始的想法是连续的数的乘积,当再乘下一个数的时候,如果乘积变小了就应该重新开始计数,实际是错误的([-2,3,4])。
考虑当前位置如果是一个负数的话,那么我们希望以它前一个位置结尾的某个段的积也是个负数,这样就可以负负得正,并且我们希望这个积尽可能「负得更多」,即尽可能小。如果当前位置是一个正数的话,我们更希望以它前一个位置结尾的某个段的积也是个正数,并且希望它尽可能地大。于是这里我们可以再维护一个 f m i n ( i ) f_{min}(i)f min
(i),它表示以第 ii 个元素结尾的乘积最小子数组的乘积,那么我们可以得到这样的动态规划转移方程:
from copy import deepcopy
class Solution:
def maxProduct(self, nums: list) -> int:
maxF = deepcopy(nums)
minF = deepcopy(nums)
for i in range(1, len(nums)):
maxF[i] = max(maxF[i-1] * nums[i], minF[i-1] * nums[i], nums[i])
minF[i] = min(minF[i-1] * nums[i], maxF[i-1] * nums[i], nums[i])
return max(maxF)
13.排序算法. 哪些是稳定的,哪些不稳定的
一、稳定排序算法
1、冒泡排序
2、鸡尾酒排序
3、插入排序
4、桶排序
5、计数排序
6、合并排序
7、基数排序
8、二叉排序树排序
二、不稳定排序算法
1、选择排序
2、希尔排序
3、组合排序
4、堆排序
5、平滑排序
6、快速排序
14.树的深度和高度。一开始分别用了一个层序遍历和一个dfs,然后面试官问能否都在一个dfs里面呢,提示了一下在dfs是否可以传一个参数,然后解决了。
树中的深度、高度及层数相关概念
深度是从上往下数的,高度是从下往上数的,深度和高度都涉及到节点的层数(经过学习发现,深度、高度概念在不同的教材中有不同的定义,主要看高度深度的初值为几,有的为0,有的为1)。
(1).定义一(初值为0):节点的深度是根节点到这个节点所经历的边的个数
节点的高度是该节点到叶子节点的最长路径(边数)
树的高度等于根节点的高度
具体如下图所示(参考1):

(2).定义二(初值为1):节点的深度是根节点到这个节点的最长路径上的节点数
节点的高度是该节点到最远叶子节点的最长路径上的节点数
具体如下图所示(参考2):
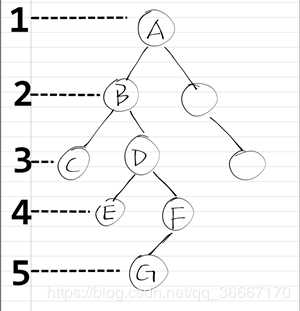
此外还有最小深度的概念。最小深度是从根节点到最近叶子节点的最短路径上的节点数量(初值为1)。
15.布隆过滤器介绍
Bloom Filter是一种时空效率都很高的随机数据结构,通过一个位数组和多哈希函数来解决海量数据的判重问题,适用于不严格要求100%正确的场合,也可以用来对数据进行初步过滤。
Bloom Filter的原理与Bitmap十分类似,区别仅在于使用k个而不是单个哈希函数,以降低因哈希碰撞冲突造成的误判。
Bloom Filter一般需要提供两个接口:
- 将元素加入集合
- 给定元素,判断集合中是否存在
1.初始化
初始集合bits[m]是个全为0的位数组。
2.添加元素
在添加元素时,分别计算出k个哈希值hi,并将bits[hi]置成1。
3.判断存在性
给定元素,分别计算出k个哈希值hi,只要有一个bits[hi]是0,则该元素一定不在集合中;反之,如果全部bits[hi]都是1,那么该元素有很大概率存在于集合中。
4.示例代码
以下代码简单实现了个Bloom Filter。
class BloomFilter(object):
def __init__(self, size):
self.size = 2 ** size
self.bits = [False] * self.size
self.keys = [131, 151, 233]
def get_hash(self, word, p):
h = 0
for i in word:
h = (h * p + ord(i)) & (self.size - 1)
return h
def insert(self, word):
for x in self.keys:
h = self.get_hash(word, x)
self.bits[h] = True
def might_contain(self, word):
for x in self.keys:
h = self.geth(word, x)
if not self.bits[h]:
return False
return True
16.为什么不用布隆过滤器
- 误判率较高:由于布隆过滤器使用哈希函数进行元素映射,因此可能会出现哈希冲突。如果多个元素被映射到相同的位数组位置上,就会导致误判率增加。
- 集合动态变化:布隆过滤器一旦初始化完成,就无法修改其大小。如果需要向其中添加或删除元素,则必须重新构建一个新的布隆过滤器。
- 空间占用较高:为了保证误判率在可接受范围内,布隆过滤器需要设置足够大的位数组和多个哈希函数。这样就会占用比较大的存储空间。
- 不支持元素查询:由于布隆过滤器只能告诉你一个元素是否可能存在于集合中,而不能直接返回该元素本身。因此,在需要查找具体元素的场景中,它并不是最佳选择。
17.数据结构相关,图的种类,表示方法,图有哪些经典算法+描述算法
一、图的种类:
- 无向图:边没有方向,可以任意往返。
- 有向图:边有方向,只能单向移动。
- 完全图:每个顶点都与其他所有顶点相连的无向图。
- 加权图:每条边都赋予一个权值的图,如最短路径问题就是基于加权图解决的。
- 二分图:可以将所有顶点分成两部分,并且同一部分内的顶点之间没有边相连,不同部分内的顶点之间有且仅有一条边相连。
二、表示方法:
- 邻接矩阵:使用二维数组来表示节点和边之间的关系。如果两个节点之间有连接,则对应位置为1或者具体权值;否则为0或者空缺。适用于稠密图。
- 邻接表:使用链表来表示节点和边之间的关系。每个节点对应一个链表,存储该节点所连接到的所有其他节点以及对应权值。适用于稀疏图。
三、经典算法:
- 广度优先搜索(BFS):从起始节点开始,依次访问离它最近的未访问过的邻居节点,并标记已访问过。重复这个过程直到找到目标节点,或者遍历完所有可达节点。
- 深度优先搜索(DFS):从起始节点开始,选择一个未访问过的邻居节点作为下一个待访问的节点,并继续递归执行此操作。直到找到目标节点,或者遍历完所有可达节点。
- 最短路径算法(Dijkstra算法):求解有权图中两个顶点之间的最短路径。通过动态规划思想和贪心策略来实现。首先初始化距离数组和标记数组,然后通过循环找到当前距离最小的顶点,并更新它与其他顶点之间的距离值。
- 最小生成树算法(Prim算法、Kruskal算法):在无向加权连通图中,找出一棵边权值和最小的生成树。Prim算法以某一顶点为起点,每次将与其相邻且尚未被访问的边中权值最小的一条加入集合;Kruskal算法则是从所有边中选取权值最小且不构成回路的边依次加入集合。
- 拓扑排序:对有向无环图进行排序,使得任何一个有向边连接的起点都排在该边指向的终点之前。实现方法包括深度优先搜索和Kahn算法。
- 关键路径:在有向无环图中,找到一条从起点到终点的路径,使得该路径上的所有任务完成时间最短。计算方法包括先求解每个任务的最早开始时间和最晚开始时间,然后根据这些数据来计算关键路径。
18.求最大的k个数字,解法:优先队列(堆)或者快速排序
一、题目
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。

二、思路解析
1.理解题意 根据示例明确题意,知道主要考察的是排序算法。
2.快速排序 我们可以用快速排序来解决这个问题,先对原数组排序,再返回倒数第 kk 个位置,这样平均时间复杂度是 O(n \log n)O(nlogn),但其实我们可以做的更快。 快速排序是一个典型的分治算法。
3.基于堆排序 我们也可以使用堆排序来解决这个问题——建立一个大根堆,做 k - 1k−1 次删除操作后堆顶元素就是我们要找的答案。在很多语言中,都有优先队列或者堆的的容器可以直接使用,但是在面试中,面试官更倾向于让更面试者自己实现一个堆。搞懂「建堆」、「调整」和「删除」的过程。
4.暴力解法 5.优先队列
三、代码
1.基于快速排序C++
class Solution {
public:
int quickSelect(vector<int>& a, int l, int r, int index) {
int q = randomPartition(a, l, r);
if (q == index) {
return a[q];
} else {
return q < index ? quickSelect(a, q + 1, r, index) : quickSelect(a, l, q - 1, index);
}
}
inline int randomPartition(vector<int>& a, int l, int r) {
int i = rand() % (r - l + 1) + l;
swap(a[i], a[r]);
return partition(a, l, r);
}
inline int partition(vector<int>& a, int l, int r) {
int x = a[r], i = l - 1;
for (int j = l; j < r; ++j) {
if (a[j] <= x) {
swap(a[++i], a[j]);
}
}
swap(a[i + 1], a[r]);
return i + 1;
}
int findKthLargest(vector<int>& nums, int k) {
srand(time(0));
return quickSelect(nums, 0, nums.size() - 1, nums.size() - k);
}
};
2.基于快速排序java
class Solution {
Random random = new Random();
public int findKthLargest(int[] nums, int k) {
return quickSelect(nums, 0, nums.length - 1, nums.length - k);
}
public int quickSelect(int[] a, int l, int r, int index) {
int q = randomPartition(a, l, r);
if (q == index) {
return a[q];
} else {
return q < index ? quickSelect(a, q + 1, r, index) : quickSelect(a, l, q - 1, index);
}
}
public int randomPartition(int[] a, int l, int r) {
int i = random.nextInt(r - l + 1) + l;
swap(a, i, r);
return partition(a, l, r);
}
public int partition(int[] a, int l, int r) {
int x = a[r], i = l - 1;
for (int j = l; j < r; ++j) {
if (a[j] <= x) {
swap(a, ++i, j);
}
}
swap(a, i + 1, r);
return i + 1;
}
public void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
3.基于堆排序C++
class Solution {
public:
void maxHeapify(vector<int>& a, int i, int heapSize) {
int l = i * 2 + 1, r = i * 2 + 2, largest = i;
if (l < heapSize && a[l] > a[largest]) {
largest = l;
}
if (r < heapSize && a[r] > a[largest]) {
largest = r;
}
if (largest != i) {
swap(a[i], a[largest]);
maxHeapify(a, largest, heapSize);
}
}
void buildMaxHeap(vector<int>& a, int heapSize) {
for (int i = heapSize / 2; i >= 0; --i) {
maxHeapify(a, i, heapSize);
}
}
int findKthLargest(vector<int>& nums, int k) {
int heapSize = nums.size();
buildMaxHeap(nums, heapSize);
for (int i = nums.size() - 1; i >= nums.size() - k + 1; --i) {
swap(nums[0], nums[i]);
--heapSize;
maxHeapify(nums, 0, heapSize);
}
return nums[0];
}
};
4.基于堆排序Java
class Solution {
public int findKthLargest(int[] nums, int k) {
int heapSize = nums.length;
buildMaxHeap(nums, heapSize);
for (int i = nums.length - 1; i >= nums.length - k + 1; --i) {
swap(nums, 0, i);
--heapSize;
maxHeapify(nums, 0, heapSize);
}
return nums[0];
}
public void buildMaxHeap(int[] a, int heapSize) {
for (int i = heapSize / 2; i >= 0; --i) {
maxHeapify(a, i, heapSize);
}
}
public void maxHeapify(int[] a, int i, int heapSize) {
int l = i * 2 + 1, r = i * 2 + 2, largest = i;
if (l < heapSize && a[l] > a[largest]) {
largest = l;
}
if (r < heapSize && a[r] > a[largest]) {
largest = r;
}
if (largest != i) {
swap(a, i, largest);
maxHeapify(a, largest, heapSize);
}
}
public void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
5.暴力解法Java
import java.util.Arrays;
public class Solution {
public int findKthLargest(int[] nums, int k) {
int len = nums.length;
Arrays.sort(nums);
return nums[len - k];
}
}
6.暴力解法C++
#include <iostream>
#include <vector>
using namespace std;
class Solution {
public:
int findKthLargest(vector<int> &nums, int k) {
int size = nums.size();
sort(begin(nums), end(nums));
return nums[size - k];
}
};
7.优先队列Java
import java.util.Comparator;
import java.util.PriorityQueue;
public class Solution {
public int findKthLargest(int[] nums, int k) {
int len = nums.length;
// 使用一个含有 k 个元素的最小堆,PriorityQueue 底层是动态数组,为了防止数组扩容产生消耗,可以先指定数组的长度
PriorityQueue<Integer> minHeap = new PriorityQueue<>(k, Comparator.comparingInt(a -> a));
// Java 里没有 heapify ,因此我们逐个将前 k 个元素添加到 minHeap 里
for (int i = 0; i < k; i++) {
minHeap.offer(nums[i]);
}
for (int i = k; i < len; i++) {
// 看一眼,不拿出,因为有可能没有必要替换
Integer topElement = minHeap.peek();
// 只要当前遍历的元素比堆顶元素大,堆顶弹出,遍历的元素进去
if (nums[i] > topElement) {
// Java 没有 replace(),所以得先 poll() 出来,然后再放回去
minHeap.poll();
minHeap.offer(nums[i]);
}
}
return minHeap.peek();
}
}
四、总结
1.基于快速排序的选择 时间复杂度:O(n), 空间复杂度:O(logn),递归使用栈空间的空间代价的期望为 O(logn)。
2.基于堆排序 时间复杂度:O(nlogn),建堆的时间代价是 O(n),删除的总代价是 O(klogn),因为 k<n,故渐进时间复杂为O(nlogn)。 空间复杂度:O(logn),即递归使用栈空间的空间代价。
3.暴力解法 时间复杂度:O(NlogN),这里 N 是数组的长度,算法的性能消耗主要在排序,JDK 默认使用快速排序,因此时间复杂度为 O(NlogN); 空间复杂度:O(logN),这里认为编程语言使用的排序方法是「快速排序」,空间复杂度为递归调用栈的高度,为 logN。 4.优先队列 时间复杂度:O(NlogK),遍历数据O(N),堆内元素调整O(logK); 空间复杂度:O(K)。
19.一个大数问题,解法:转换为字符串解决,这题没写好,leetcode应该有很多类似的问题
大数是指计算的数值非常大或者对运算的精度要求非常高,用已知的数据类型无法精确表示的数值。
大数问题主要有以下四种:
==================================
-
大数相加
-
大数相乘
-
大数阶乘
-
大数幂乘
==================================
下面我们一起解决这四种问题。
1.Problem 1 大数相加
一般的int,long等类型无法精确表达数值。
我们就考虑以字符串的形式读入这两个数,利用vector来表示这两个数值,
代码:
1 string s1, s2;
2 cin>>s1>>s2;
3 int i;
4 vector<int> v1(s1.size()), v2(s2.size());
5 for(i = 0; i < s1.size(); i++)
6 {
7 v1[i] = s1[i] - '0';
8 }
9 for(i = 0; i < s2.size(); i++)
10 {
11 v2[i] = s2[i] - '0';
12 }
利用vector的空间可以无限扩展,因此我们利用vector来模拟计算这两个数的相加。
根据加法规则我们可以知道,个位与个位相加,十位与十位相加...
代码:
1 vector<int> f(vector<int> v1, vector<int> v2)
2 { #将两个数字的位置倒过来,个位数字放在最前面,例如:123,倒过来即为321
3 reverse(v1.begin(),v1.end());
4 reverse(v2.begin(),v2.end());
5 int maxsize = v1.size(); #比较两个数字的位数,找到最长的
6 if(v2.size() > maxsize)
7 {
8 maxsize = v2.size();
9 }
10 vector<int> v3(maxsize); #记录每一位计算的进位
11 int carry = 0;
12 int i;
13 for(int i = 0; i < maxsize; i++)
14 {
15 int t = carry;
16 if(i < v1.size())
17 t = t + v1[i];
18 if(i < v2.size())
19 t = t + v2[i]; #当相同位置上的数字相加超过10时,应该向高位进位
20 carry = t / 10;
21 v3[i] = t % 10;
22 } #若最高位相加之后,需要进位,那么我们需要扩展vector
23 if(carry > 0)
24 v3.push_back(carry); #最后将vector倒置,可以得到最终的相加结果
25 reverse(v3.begin(),v3.end());
26 return v3;
27 }
2.Problem 2 大数相乘
例如:
位置: 4 3 2 1 0
数值1: 4 3 2
数值2: * 4 5
------------------------------------
结果: 20 15 10
16 12 8
-----------------------------------
16 32 23 10
-----------------------------------
1 9 4 4 0
从上面的例子中我们可以看出位置i和位置j的结果放在i+j的位置,最后再依次进行进位操作。
代码:
这里要注意初始结果申请的空间,最后在输出的时候需要进行处理。
1 vector<int> m(vector<int> v1, vector<int> v2)
2 {
3 reverse(v1.begin(),v1.end());
4 reverse(v2.begin(),v2.end());
5 int maxsize = v1.size();
6 if(v2.size() > maxsize)
7 maxsize = v2.size();
8 maxsize *= 2;
9 vector<int> v3(maxsize, 0);
10 int carry = 0;
11 for(int i = 0; i < v1.size(); i++)
12 for(int j = 0; j < v2.size(); j++)
13 {
14 v3[i+j] += v1[i]*v2[j];
15 }
16 for(int i = 0; i < v3.size(); i++)
17 {
18 if(v3[i] >= 10)
19 {
20 v3[i+1] += v3[i]/10;
21 v3[i] = v3[i] % 10;
22 }
23 }
24 reverse(v3.begin(),v3.end());
25
26 return v3;
27 }
输出处理:因为开始申请的空间可能有部分没有用到,但是在倒置的时候最前面可能出现多个0,利用flag记录非0的起点。
代码:
int flag = 0;
while(v4[flag] == 0)
flag++;
for(i = flag; i < v4.size(); i++)
cout<<v4[i];
cout<<endl;
3.Problem 3大数阶乘
一般阶乘很快就会超过int的表达范围,因此同样采用上面大数相乘的思想来计算大数阶乘,这里需要注意的是开始输入的n不是一个大数,但是随着计算,结果会越来越大。
利用循环来计算大数阶乘。
代码:
1 vector<int> m(vector<int> v1, vector<int> v2)
2 {
3 reverse(v1.begin(),v1.end());
4 reverse(v2.begin(),v2.end());
5 int maxsize = v1.size();
6 if(v2.size() > maxsize)
7 maxsize = v2.size();
8 maxsize *= 2;
9 vector<int> v3(maxsize, 0);
10 int carry = 0;
11 for(int i = 0; i < v1.size(); i++)
12 for(int j = 0; j < v2.size(); j++)
13 {
14 v3[i+j] += v1[i]*v2[j];
15 }
16 for(int i = 0; i < v3.size(); i++)
17 {
18 if(v3[i] >= 10)
19 {
20 v3[i+1] += v3[i]/10;
21 v3[i] = v3[i] % 10;
22 }
23 }
24 reverse(v3.begin(),v3.end());
25
26 return v3;
27 }
28
29 vector<int> intTovector(int x)
30 {
31 vector<int> v;
32 while (x)
33 {
34 v.push_back(x%10);
35 x /= 10;
36 }
37 reverse(v.begin(),v.end());
38 return v;
39 }
40
41 vector<int> pre(vector<int> v)
42 {
43 vector<int> v1;
44 int flag = 0;
45 while(v[flag] == 0)
46 flag++;
47 for(int i = flag; i < v.size(); i++)
48 v1.push_back(v[i]);
49 return v1;
50 }
51
52 void p(vector<int> v)
53 {
54 for(int j = 0; j < v.size(); j++)
55 cout<<v[j];
56 cout << endl;
57 }
58
59 vector<int> jiecheng(int n)
60 {
61 vector<int> v1(1,1);
62 if(n == 1)
63 return v1;
64 vector<int> v2(1,2);
65 if(n == 2)
66 return v2;
67 vector<int> v3 = v2;
68 for(int i = 3; i <= n; i++)
69 {
70 vector<int> t1 = intTovector(i);
71 p(t1);
72 vector<int> t2 = v3;
73 p(t2);
74 v3 = pre(m(t1,t2));
75 p(v3);
76 cout << "===============" <<endl;
77 }
78 return v3;
79 }
4.Problem 4大数幂乘
一般阶乘很快就会超过int的表达范围,因此同样采用上面大数相乘的思想来循环计算大数阶乘。
代码:
1 vector<int> micheng(int n, int s)
2 {
3 vector<int> v = intTovector(n);
4 for(int i = 1; i < s; i++)
5 {
6 v = pre(m(v,intTovector(n)));
7
8 }
9 return v;
10 }
20.hash解决冲突 ( 开放定址法、链地址法、再哈希法、建立公共溢出区 ),四种方式详细的过程、思路
1.开放定址法
开放定址法是指在哈希表中发生冲突时,顺序地去检查表中的其他位置,直到找到一个空闲位置为止。具体过程如下:
- 当要插入一个元素时,首先根据哈希函数计算出该元素应该存储的位置。
- 如果该位置已经被占用了,则按照一定的规则(如线性探测、二次探测等)向后寻找下一个空闲位置。
- 重复上述步骤,直到找到一个空闲位置为止,并将元素存储在该位置。
这种方法简单易懂,而且不需要额外的数据结构来存储冲突的元素,但是可能会导致聚集现象(即越来越多的元素堆积在同一个区域),影响哈希表的性能。
2.链地址法
链地址法是指在哈希表中每个桶都维护一个链表,在发生冲突时将新元素插入到对应桶的链表末尾。具体过程如下:
- 当要插入一个元素时,首先根据哈希函数计算出该元素应该存储的桶号。
- 如果该桶为空,则直接将元素插入其中。
- 否则,在该桶对应的链表中查找元素是否已经存在。
- 如果不存在,则将新元素插入到该链表的末尾。
- 如果已经存在,则更新该元素的值。
这种方法避免了聚集现象,而且可以处理任意数量的冲突,但是需要额外的空间来存储链表指针,并且访问时需要依次遍历整个链表,性能可能较差。
3.再哈希法
再哈希法是指使用不同的哈希函数来解决冲突。具体过程如下:
- 当要插入一个元素时,首先根据第一个哈希函数计算出该元素应该存储的位置。
- 如果该位置已经被占用了,则按照第二个哈希函数重新计算出一个新位置。
- 重复上述步骤,直到找到一个空闲位置为止,并将元素存储在该位置。
这种方法避免了聚集现象,并且不需要额外的数据结构来存储冲突的元素,但是需要选择多个不同的哈希函数,并且每次都要重新计算哈希值,可能会影响性能。
4.建立公共溢出区
建立公共溢出区是指当发生冲突时,将所有冲突的元素都存储在同一区域内。具体过程如下:
- 当要插入一个元素时,首先根据哈希函数计算出该元素应该存储的位置。
- 如果该位置已经被占用了,则将新元素放到公共溢出区中。
- 重复上述步骤,直到所有元素都被插入为止。
21.链地址法和再哈希法之间的关联和区别,两者分别适用场景,两者底层的数据结构,关联和区别
链地址法和再哈希法都是解决哈希表中冲突的方法,它们之间的关联和区别如下:
- 关联
链地址法和再哈希法都需要使用额外的数据结构来存储冲突的元素。链地址法使用链表来存储在同一个桶内发生冲突的元素,而再哈希法则通过不同的哈希函数计算出新的位置,避免原有位置上已经存在其他元素。
- 区别
链地址法适用于处理高密度的数据集,即如果存在大量重复键值,则可以将它们存储在同一个桶内。因此,在负载因子较高时(即哈希表中填充了大量元素),使用链地址法可能比再哈希法更为合适。
而再哈希法适用于处理低密度或均匀分布的数据集。由于每次需要重新计算新位置,因此当负载因子较低时(即哈希表中只填充了一部分元素),使用再哈希法可能会比链地址法更为有效。
- 底层数据结构
在实现上,链地址法需要维护一个桶数组以及若干个单向链表;而再哈希法仅需要一个桶数组,并且不需要额外的数据结构来存储相同桶内的元素。因此,再哈希法可能比链地址法更节省空间。
总之,链地址法和再哈希法都是常见的哈希表冲突解决方法。在实际应用中,需要根据具体的数据集和负载情况来选择合适的方法。
22.链表和数组的底层结构设计、关联、区别、应用场景
数组和链表都是线性数据结构,它们有什么优缺点?两者都有一些优点和缺点,现在我们来看看数组和链表有什么区别,以及它们的一些优缺点和相关的应用场景。
例如,一个数组通常是一个被广泛实现为一个默认类型的数据类型,也就是说,一个数组中的元素的数据类型通常都是相同类型的,而且长度通常都是固定的,除了在某些弱类型语言中可能又例外,如JavaScript,但是一般都是推荐使用存储同一种数据类型的数据,数组在现代编程中被大量用到。但是,某些应用场景使用链表则不合适,例如当我们需要存储大量数据而又不知道要存储多少数据的时候,对于这种情况,可以使用链表进行储存。

1、数组(Array)和链表(Linked List)的区别
下表是数组和链表区别的详细描述:
| 数组是一个相似数据类型的数据集合 | 链表是一个有相同数据类型的有续集,其中每个元素使用指针链接 |
| 数组元素可以使用数组索引随机访问 | 链表不允许随机访问,元素只能被有序或顺序访问 |
| 数组的数据元素在内存中连续储存 | 元素可能存储在内存的任意地方,链表创建一个指针指向相应的数据 |
| 插入和删除操作非常耗时,时间为O(n),因为元素的内存地址是连续和固定的 | 链表的插入和删除操作非常快,时间为O(1) |
| 数组的内存是静态分配的,在编译期间完成 | 链表的内存分配是动态的,在运行时动态分配 |
| 数组的大小必须在数组的声明或初始化的时候指定 | 链表的大小随着元素的插入或删除变化 |
2、链表的优点
链表的优点如下:
- 链表的大小不固定,可以在运行时扩展或收缩。
- 插入和删除操作更快更容易。
- 内存分配在运行时的时候按照需要动态申请,比较灵活。
- 其它数据结构例如栈、队列和树可以很容易使用链表实现。
3、链表的缺点
链表的缺点如下:
- 相对于数组,链表的内存消耗更大,因为在链表中的结点需要额外储存一个指针,指针的储存需要额外的内存空间。
- 元素不能被随机访问。
- 逆向遍历单链表比较困难(但是可以实现的)。
4、链表的应用场景
链表的应用如下
- 链表可以用于实现栈、队列、树等数据结构。
- 链表也可以用于实现图,图邻接表的表示方式。
- 链表可以用于实现散列表,散列表的每个位置可以存储一个链表(开放地址散列法)
以上就是数组和链表的区别、优缺点和应用场景的内容。
23.死锁的概念,进程调度算法怎么解决死锁
0、死锁的概念和产生原因 概念:1、多个并发进程因争夺系统资源而产生相互等待的现象。
2、是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法 再向前推进
原理:当一组进程中的每个进程都在等待某个事件发生,而只有这组进程中的其他进程才能触发该事件,这就称这组进程发生了死锁。
产生原因:
a、竞争资源
产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞
产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
b. 进程间推进顺序非法
若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁
例如,当P1运行到P1:Request(R2)时,将因R2已被P2占用而阻塞;当P2运行到P2:Request(R1)时,也将因R1已被P1占用而阻塞,于是发生进程死锁
本质原因:
1)、系统资源有限。
2)、进程推进顺序不合理
1、产生的必要条件 互斥:每个资源要么已经分配给一个进程,要么就是可用的,P1进程占用资源时,别的进程无法使用
占有和等待:已经占有资源的额进程可以再请求新的资源
不可抢占:已经分配给进程的资源不能被强制性抢占,它只能被占有它的进程显式地释放,资源只能由资源占有者主动释放
环路等待:有两个或两个以上的进程组成环路,该环路中每个进程都在等待下一个进程所占有的资源
P1 占用了P2的资源,P2占用了P3的资源,P3占用了P1的资源,形成等待环路
2、处理方法: 鸵鸟策略 死锁检测和死锁恢复(不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。) 死锁预防(在程序运行之前预防) 死锁避免(在程序运行时避免发生死锁) A、鸵鸟策略: 解决死锁问题代价很高,当死锁对用户不会有多大危害时,或者发生的概率很低时,直接不用处理
Linux、Windows、Unix处理死锁的问题 大部分时间都是忽略它
B、死锁检测和死锁恢复(解除): 1、先检测:
此方法允许系统在运行过程中发生死锁。但可通过系统所设置的检测机构,及时地检测出死锁的发生,并精确地确定与死锁有关的进程和资源。检测方法包括定时检测、效率低时检测、进程等待时检测等。 2、解除死锁:
采取适当措施,从系统中将已发生的死锁清除掉。 这是与检测死锁相配套的一种措施。当检测到系统中已发生死锁时,须将进程从死锁状态中解脱出来。
常用的实施方法:撤销或挂起一些进程,以便回收一些资源,再将这些资源分配给已处于阻塞状态的进程,使之转为就绪状态,以继续运行。死锁的检测和解除措施,有可能使系统获得较好的资源利用率和吞吐量,但在实现上难度也最大。
如果我们在死锁检查时发现了死锁情况,那么就要努力消除死锁,使系统从死锁状态中恢复过来。
消除死锁的几种方式:
最简单、最常用的方法就是进行系统的重新启动,缺点:代价很大,它意味着在这之前所有的进程已经完成的计算工作都将付之东流,包括参与死锁的那些进程,以及未参与死锁的进程;
撤消进程,剥夺资源。终止参与死锁的进程,收回它们占有的资源,从而解除死锁。这时又分两种情况:一次性撤消参与死锁的全部进程,剥夺全部资源;或者逐步撤消参与死锁的进程,逐步收回死锁进程占有的资源。一般来说,选择逐步撤消的进程时要按照一定的原则进行,目的是撤消那些代价最小的进程,比如按进程的优先级确定进程的代价;考虑进程运行时的代价和与此进程相关的外部作业的代价等因素;
进程回退策略,即让参与死锁的进程回退到没有发生死锁前某一点处,并由此点处继续执行,以求再次执行时不再发生死锁。虽然这是个较理想的办法,但是操作起来系统开销极大,要有堆栈这样的机构记录进程的每一步变化,以便今后的回退,有时这是无法做到的。
死锁的解除补充:
如果利用死锁检测算法检测出系统已经出现了死锁 ,那么,常用的解除死锁的方法:
1、抢占资源:从一个或多个进程中抢占足够数量的资源分配给死锁进程,以解除死锁状态。
2、终止(或撤销)进程:终止或撤销系统中的一个或多个死锁进程,直至打破死锁状态。
a、终止所有的死锁进程。这种方式简单粗暴,但是代价很大,很有可能会导致一些已经运行了很久的进程前功尽弃。
b、逐个终止进程,直至死锁状态解除。该方法的代价也很大,因为每终止一个进程就需要使用死锁检测来检测系统当前是否处于死锁状态。另外,每次终止进程的时候终止那个进程呢?每次都应该采用最优策略来选择一个“代价最小”的进程来解除死锁状态。
一般根据如下几个方面来决定终止哪个进程:
进程的优先级
进程已运行时间以及运行完成还需要的时间
进程已占用系统资源
进程运行完成还需要的资源
终止进程数目
进程是交互还是批处理
C、死锁避免: 两种避免办法:
1、如果一个进程的请求会导致死锁,则不启动该进程
2、如果一个进程的增加资源请求会导致死锁 ,则拒绝该申请
D、死锁预防:(确保程序永远不会进入死锁状态): 打破四个必要条件之一就能有效预防死锁的发生;由于互斥条件是非共享资源所必须的,不仅不能改变,还应加以保证,所以,主要是破坏产生死锁的其他三个条件。
a、破坏“占有且等待”条件
方法1:所有的进程在开始运行之前,必须一次性地申请其在整个运行过程中所需要的全部资源。
方法2:该方法是对第一种方法的改进,允许进程只获得运行初期需要的资源,便开始运行,在运行过程中逐步释放掉分配到的已经使用完毕的资源,然后再去请求新的资源。这样的话,资源的利用率会得到提高,也会减少进程的饥饿问题。
b、破坏“不可抢占”条件
当一个已经持有了一些资源的进程在提出新的资源请求没有得到满足时,它必须释放已经保持的所有资源,待以后需要使用的时候再重新申请。这就意味着进程已占有的资源会被短暂地释放或者说是被抢占了。
该种方法实现起来比较复杂,且代价也比较大。释放已经保持的资源很有可能会导致进程之前的工作实效等,反复的申请和释放资源会导致进程的执行被无限的推迟,这不仅会延长进程的周转周期,还会影响系统的吞吐量。
c、破坏“循环等待”条件
可以通过定义资源类型的线性顺序来预防,可将每个资源编号,当一个进程占有编号为i的资源时,那么它下一次申请资源只能申请编号大于i的资源。
补充:
打破互斥条件:改造独占性资源为虚拟资源,大部分资源已无法改造。
打破不可抢占条件:当一进程占有一独占性资源后又申请一独占性资源而无法满足,则退出原占有的资源。
打破占有且申请条件:采用资源预先分配策略,即进程运行前申请全部资源,满足则运行不然就等待,这样就不会占有且申请。
打破循环等待条件:实现资源有序分配策略,对所有设备实现分类编号,所有进程只能采用按序号递增的形式申请资源

 查看5道真题和解析
查看5道真题和解析