字节生服后端一面:这些问题你都答对了,什么时候入职?
面经
1.聊实习
2.violate关键字作用
3.若violate i=0, 有3个线程同时对其+1,i的值是多少;若AtomicInteger i=0, 同样的操作,i的值是多少
4.网页中输入url,其过程;为什么是4次挥手,而不是3次挥手
5.tcp/ip模型和OSI7层模型对应关系
6.了解redis分布式集群吗;什么是缓存击穿,如何解决
7.打开一个app时会弹出广告,如何做到每个用户访问只弹出一次广告
8.redis持久化方式
9.cookie和session的区别
10.sql语句执行很慢该如何排查
11.了解分布式吗,CAP理论
12.了解过mq吗;说说mq的组成
13.若一个访问链接很长,如何设计一个短链接;如果使用哈希算法,存在哈希冲突了生成重复短链接怎么办
手撕:反转链表(自己建表,写用例,ACM模式)
参考回答
聊聊你的实习经历
「面试官」:首先,欢迎你来参加今天的面试。我们先聊聊你的实习经历吧,能给我分享一下你最近的实习经历吗?
『求职者』:谢谢面试官。我最近在一家互联网公司实习,担任Java后端开发实习生。在实习期间,我主要参与了公司的一个电商平台项目。
我的主要工作包括:
- 开发和优化商品管理模块的RESTful API
- 参与设计和实现了一个基于Redis的商品缓存系统,显著提升了系统响应速度
- 协助团队进行代码重构,提高了代码的可维护性
- 参与了日常的code review,这让我学到了很多编码最佳实践
通过这次实习,我不仅提升了自己的编码能力,还学习了如何在团队中协作,以及如何将理论知识应用到实际项目中。这次经历让我对Java后端开发有了更深入的理解。
volatile关键字的作用
「面试官」:听起来你的实习经历很充实。那么让我们进入一些技术问题。你能解释一下Java中volatile关键字的作用吗?
『求职者』:当然可以。volatile是Java中的一个关键字,它主要有两个作用:
- 保证可见性: 当一个变量被声明为volatile时,它会保证变量的值在被修改后,能立即被其他线程看到。这是因为volatile变量的所有写操作都会直接刷新到主内存中,而读操作会直接从主内存中读取。
- 防止指令重排序: volatile关键字能够防止jvm对代码进行指令重排序优化。这保证了程序执行的顺序性,在某些情况下很重要。
需要注意的是,volatile不能保证原子性。这意味着诸如 i++ 这样的操作在多线程环境下仍然可能产生竞态条件。
volatile和AtomicInteger的区别
「面试官」:很好。那么,如果有一个 volatile int i = 0,有3个线程同时对其进行 +1 操作,最终 i 的值是多少?如果换成 AtomicInteger i = new AtomicInteger(0),结果又会是什么?
『求职者』:这是一个很好的问题,让我来解释一下:
- 对于 volatile int i = 0:
- 最终的结果是不确定的,可能是1、2或3。
- 虽然volatile保证了可见性,但是 i++ 操作不是原子的。它实际上包含了读取、增加、写入三个步骤。
- 在多线程环境下,这三个步骤可能被打断,导致最终结果小于3。
- 对于 AtomicInteger i = new AtomicInteger(0):
- 最终的结果一定是3。
- AtomicInteger 保证了操作的原子性。它的 incrementAndGet() 方法是原子操作,能够保证在多线程环境下的安全性。
- 即使多个线程同时调用 incrementAndGet(),也能保证每次操作都是原子的,不会丢失任何一次增加操作。
这个例子很好地说明了 volatile 和 AtomicInteger 的区别:volatile 只能保证可见性,而 AtomicInteger 可以保证原子性。
网页中输入URL的过程
「面试官」:理解得很清楚。现在让我们转向网络方面的问题。能否描述一下当我们在网页中输入URL,直到页面显示,这个过程中发生了什么?另外,为什么TCP是4次挥手,而不是3次挥手?
『求职者』:当然,我来解释一下这个过程:
- URL解析:浏览器首先会解析URL,分离出协议、主机名、端口等信息。
- DNS解析:浏览器会查找该域名对应的IP地址。首先查找浏览器缓存,然后是操作系统缓存,再到本地DNS服务器,最后到根DNS服务器。
- 建立TCP连接:找到IP后,浏览器会与服务器建立TCP连接,这里会经历三次握手。
- 发送HTTP请求:建立连接后,浏览器会发送HTTP请求到服务器。
- 服务器处理请求并返回HTTP响应:服务器接收到请求,进行处理,然后返回响应。
- 浏览器解析渲染页面:浏览器接收到HTML、CSS、JavaScript等资源,开始解析和渲染页面。
- 断开连接:数据传输完成后,通过四次挥手断开TCP连接。
关于为什么是四次挥手而不是三次:
- 四次挥手的原因是TCP连接是全双工的,每个方向都需要单独进行关闭。
- 当一方发送FIN报文时,只是表示这一方不再发送数据了,但还可以接收数据。
- 另一方收到FIN后,可能还有数据需要发送,所以先发送ACK,等到所有数据都发送完毕后,才能发送自己的FIN。
- 因此,关闭连接需要四次交互:
- 客户端发送FIN
- 服务器回复ACK
- 服务器发送FIN
- 客户端回复ACK
如果是三次挥手,就无法保证双方都能gracefully关闭连接,可能会导致数据丢失。
TCP/IP模型和OSI7层模型的对应关系
「面试官」:非常详细的解答。那么你能说说TCP/IP模型和OSI 7层模型的对应关系吗?
『求职者』:当然可以。TCP/IP模型和OSI 7层模型是两种不同的网络协议模型,它们之间有一定的对应关系。让我用一个简单的表格来说明:

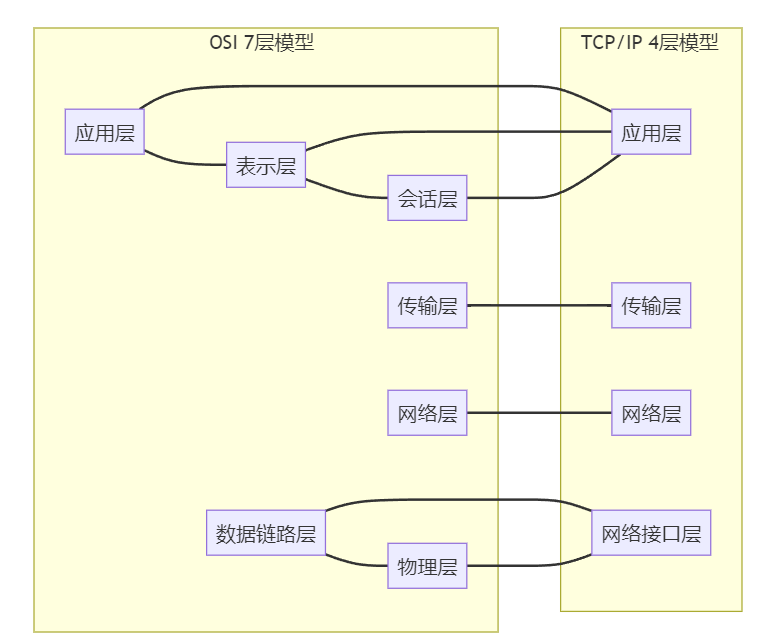
- 应用层:
- OSI模型:应用层、表示层、会话层
- TCP/IP模型:应用层
- 协议:HTTP、FTP、SMTP等
- 传输层:
- 两个模型都有传输层
- 协议:TCP、UDP
- 网络层:
- 两个模型都有网络层
- 协议:IP、ICMP、ARP
- 网络接口层:
- OSI模型:数据链路层、物理层
- TCP/IP模型:网络接口层
- 协议:Ethernet、Wi-Fi
主要区别在于,TCP/IP模型更加简化,将OSI模型的应用层、表示层和会话层合并为一个应用层,将数据链路层和物理层合并为网络接口层。这种简化使得TCP/IP模型更加实用和广泛应用。
Redis分布式集群
「面试官」:很好的解释。现在让我们谈谈数据库。你了解Redis分布式集群吗?另外,什么是缓存击穿,如何解决?
『求职者』:是的,我对Redis分布式集群有一定了解。
Redis分布式集群是Redis提供的分布式数据库解决方案,它可以将数据自动分片存储在多个节点上,每个节点存储整个数据集的一部分。主要特点包括:
- 数据分片:数据自动分散到多个节点,每个节点负责一部分slot。
- 高可用性:支持主从复制,当主节点故障时,从节点可以自动升级为主节点。
- 线性扩展:可以通过增加节点来提高集群的存储容量和性能。
- 去中心化:所有节点都是对等的,没有中心节点。
关于缓存击穿:
缓存击穿是指一个热点key在缓存中过期的瞬间,大量并发请求直接打到数据库,导致数据库压力激增的现象。
解决方案:
- 互斥锁:
- 当缓存失效时,不是所有请求都去数据库查询,而是先获得锁的线程去查询数据库,其他线程等待。
- 这样可以防止大量并发请求直接打到数据库。
- 热点数据永不过期:
- 对于一些热点数据,可以设置为永不过期,或者较长的过期时间。
- 同时可以采用后台异步更新的策略,保证数据的最终一致性。
- 资源保护:
- 对数据库的访问增加限流和降级机制,防止数据库被大量请求击垮。
- 提前更新:
- 对于可以预见的热点数据,可以在即将过期前,提前去更新缓存。
- 二级缓存:
- 设置一个为时很短的缓存作为一级缓存,一个为时较长的缓存作为二级缓存。
- 即使一级缓存失效,也可以利用二级缓存来减轻数据库压力。
通过这些方法,我们可以有效地防止和缓解缓存击穿问题,保护后端数据库。
APP广告弹出控制
「面试官」:非常好。那么,如果我们要实现一个功能:打开一个APP时会弹出广告,但要求每个用户访问只弹出一次广告,你会如何设计这个功能?
『求职者』:这是一个很有趣的问题,涉及到用户体验和数据存储。我会这样设计这个功能:
- 用户标识:
- 首先,我们需要一个唯一的用户标识。这可以是用户登录后的ID,或者对于未登录用户,可以生成一个设备唯一标识符(如UDID)。
- 数据存储:
- 我们需要存储用户是否已经看过广告的信息。有几种方案:a. 本地存储:
b. 远程存储:
c. 混合方案:
- 使用SharedPreferences(Android)或UserDefaults(iOS)存储一个布尔值。
- 优点:快速,不需要网络请求。
- 缺点:用户卸载重装APP后状态会重置。
- 在服务器端数据库中存储用户ID和广告展示状态。
- 优点:可以跨设备同步,更可靠。
- 缺点:需要网络请求,可能影响加载速度。
- 本地存储和远程存储结合使用。
- 优点:兼顾了速度和可靠性。
- 实现流程:
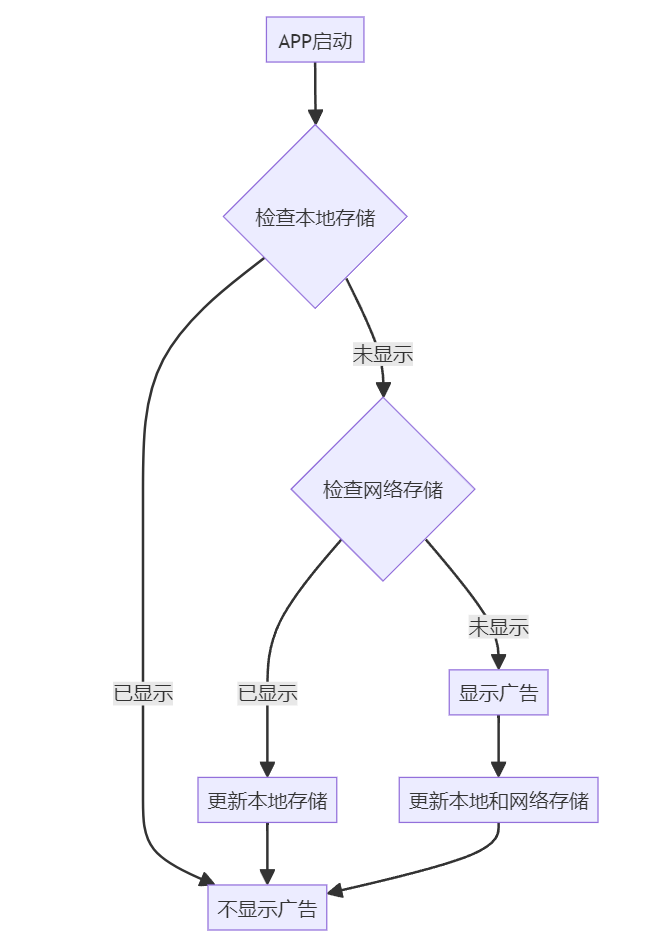
- 额外考虑:
- 网络问题处理:如果无法连接到服务器,可以默认显示广告。
- 广告更新:可以设置一个时间间隔,比如每周或每月重置一次状态,以便显示新的广告。
- A/B测试:可以为不同用户组设置不同的广告显示策略。
- 隐私考虑:
- 确保遵守相关的数据隐私法规,如GDPR。
- 在APP的隐私政策中说明这一功能。
通过这种设计,我们可以确保每个用户只会看到一次广告,同时保持良好的用户体验和系统性能。
Redis持久化方式
「面试官」:你对Redis的理解很不错。那么你能详细说说Redis的持久化方式吗?
『求职者』:当然可以。Redis提供了两种主要的持久化方式:RDB(Redis Database)和AOF(Append Only File)。
- RDB(Redis Database):RDB是Redis默认的持久化方式。它通过**快照(snapshot)**的方式,将某一时刻的所有数据都写入到一个RDB文件中。
-
优点:
-
文件紧凑:RDB文件是一个紧凑的单一文件,非常适合用于备份。
-
恢复速度快:适合大规模的数据恢复。
-
性能影响小:父进程在保存RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作。
-
缺点:
-
数据丢失风险:两次快照之间的数据可能会丢失。
-
耗时:对于大数据集,fork可能会很耗时。
- AOF(Append Only File):AOF持久化会将每一个写操作追加到文件中。
-
优点:
-
数据安全性高:可以设置不同的fsync策略。
-
易于理解和解析:AOF文件是一个只进行追加的日志文件。
-
缺点:
-
文件体积大:对于相同数据集,AOF文件通常比RDB文件大。
-
速度可能慢于RDB:根据fsync策略,AOF的速度可能会慢于RDB。
- 混合持久化:从Redis 4.0开始,Redis支持RDB和AOF的混合持久化。
- 在这种方式下,Redis重写AOF文件时,会先将当前数据以RDB方式写入新的AOF文件,再将重写缓冲区的增量命令以AOF方式追加到文件末尾。
- 这种方式结合了RDB和AOF的优点,既能快速加载又能避免丢失过多数据。
选择哪种持久化方式取决于您的具体需求。如果能承受数分钟的数据丢失,RDB是很好的选择。如果要求更高的数据安全性,可以选择AOF。在实际应用中,混合使用这两种方式往往能够提供最佳的数据安全性和性能。
Cookie和Session的区别
「面试官」:非常全面的回答。现在让我们转向Web开发相关的问题。你能解释一下Cookie和Session的区别吗?
『求职者』:当然可以。Cookie和Session都是用于跟踪用户状态的机制,但它们有很大的不同:
- 存储位置:
- Cookie:存储在客户端(通常是浏览器)
- Session:存储在服务器端
- 安全性:
- Cookie:相对不安全,因为存储在客户端,可能被篡改或窃取
- Session:相对安全,因为数据存储在服务器,客户端只存储一个Session ID
- 存储容量:
- Cookie:容量较小,通常不超过4KB
- Session:容量更大,受服务器内存限制
- 生命周期:
- Cookie:可以设置过期时间,如果不设置,默认为浏览器会话结束时过期
- Session:通常由服务器控制,可以设置过期时间,也可能在用户关闭浏览器后自动失效
- 跨域支持:
- Cookie:支持跨域,可以通过设置domain来实现
- Session:默认不支持跨域
- 数据类型:
- Cookie:只能存储字符串
- Session:可以存储任意数据类型
- 性能影响:
- Cookie:每次HTTP请求都会携带Cookie,可能影响性能
- Session:仅在服务器端处理,不影响请求性能,但可能增加服务器负载
- 应用场景:
- Cookie:适用于记住用户偏好设置、购物车等不敏感信息
- Session:适用于存储用户登录状态、敏感数据等
在实际应用中,我们经常结合使用Cookie和Session。例如,我们可以在Cookie中存储Session ID,而将具体的用户数据存储在服务器端的Session中,这样既保证了安全性,又提供了良好的用户体验。
SQL语句执行很慢的排查
「面试官」:很好的解释。那么,如果一个SQL语句执行很慢,你会如何排查问题?
『求职者』:当遇到SQL语句执行很慢的情况,我会按以下步骤进行排查:
- 使用EXPLAIN分析执行计划:
- EXPLAIN可以显示MySQL如何执行查询,包括表的读取顺序、索引使用情况等。
- 关注
type、key、rows等字段,判断索引使用是否正确,扫描的行数是否过多。
- 检查索引使用情况:
- 确保WHERE子句、JOIN条件、ORDER BY和GROUP BY中的列有适当的索引。
- 使用
SHOW INDEX FROM table_name查看表的索引情况。
- 查看慢查询日志:
- 开启MySQL的慢查询日志,分析哪些查询经常出现在日志中。
- 使用
pt-query-digest等工具分析慢查询日志。
- 检查表的数据量:
- 使用
SHOW TABLE STATUS查看表的行数和数据大小。 - 考虑是否需要分表或分区来优化大表。
- 优化查询语句:
- 避免使用
SELECT *,只选择需要的列。 - 优化 JOIN 操作,确保 JOIN 的字段有索引。
- 使用 LIMIT 限制结果集大小。
- 检查服务器资源使用情况:
- 使用
top、iostat等工具检查CPU、内存、磁盘I/O的使用情况。 - 考虑是否需要升级硬件或优化MySQL配置。
- 使用性能剖析工具:
- 使用 MySQL 的 Performance Schema 或 Percona 的 pt-pmp 等工具进行更深入的性能分析。
- 检查锁等待情况:
- 使用
SHOW PROCESSLIST查看当前运行的查询。 - 检查是否有长时间的锁等待。
- 考虑查询重写:
- 某些情况下,可能需要重写查询,如使用子查询替代 JOIN,或者反之。
- 检查数据库设计:
- 评估是否需要进行数据库的范式化或反范式化。
- 检查是否有不必要的触发器或存储过程影响性能。
通过这些步骤,我们通常可以找出SQL语句执行慢的原因,并采取相应的优化措施。优化是一个迭代的过程,可能需要多次尝试才能达到最佳效果。
分布式系统和CAP理论
「面试官」:非常详细的回答。现在,你能谈谈你对分布式系统的理解吗?特别是CAP理论?
『求职者』:当然,我很乐意分享我对分布式系统和CAP理论的理解。
分布式系统是由多个独立计算机组成的系统,这些计算机通过网络相互连接和通信,对外表现为一个统一的整体。分布式系统的主要目标是提高系统的可用性、可靠性和性能。
CAP理论是分布式系统设计中的一个重要理论,由Eric Brewer提出。CAP代表:
- 一致性(Consistency):
- 所有节点在同一时间具有相同的数据。
- 任何一个写操作都要等待所有节点同步完成。
- 可用性(Availability):
- 每个请求都能得到一个响应,无论响应成功或失败。
- 系统能够一直处理客户端的请求,而不会出现长时间的不响应。
- 分区容错性(Partition Tolerance):
- 系统中部分节点故障或网络故障时,系统仍能继续运行。
- 即使网络分区导致节点间通信失败,系统也能继续提供服务。
CAP理论指出,在一个分布式系统中,最多只能同时满足这三项中的两项。
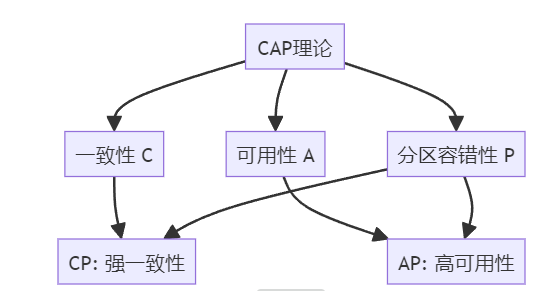
在实际应用中,我们通常会根据业务需求在这三者之间做出权衡:
- CP系统:保证一致性和分区容错性,但可能牺牲可用性。
- 例如:HBase、ZooKeeper
- AP系统:保证可用性和分区容错性,但可能牺牲一致性。
- 例如:Cassandra、CouchDB
- CA系统:在实际的分布式系统中很少见,因为网络分区是不可避免的。
需要注意的是,CAP理论中的取舍并非绝对的。在实际系统中,我们通常会采用一些策略来在这三者之间取得平衡:
- 最终一致性:允许系统在一段时间后达到一致状态。
- 读写分离:通过不同的节点处理读和写操作。
- 分布式事务:通过两阶段提交等方式保证跨节点操作的一致性。
理解CAP理论对于设计和选择分布式系统架构非常重要,它帮助我们在不同的需求之间做出正确的权衡。
消息队列(MQ)的理解
「面试官」:很好的解释。那么,你了解消息队列(MQ)吗?能谈谈MQ的组成以及它在分布式系统中的作用吗?
『求职者』:当然,我很乐意分享我对消息队列(Message Queue,简称MQ)的理解。
消息队列是一种异步的服务间通信方式,是分布式系统中重要的组件之一。它可以理解为一个存储消息的容器,生产者(Producer)向其中添加消息,消费者(Consumer)从中获取消息。
MQ的基本组成部分包括:
- 生产者(Producer):
- 负责产生消息并将其发送到消息队列。
- 消费者(Consumer):
- 从消息队列中获取消息并进行处理。
- 消息代理(Broker):
- 消息队列的服务器,负责存储和转发消息。
- 队列(Queue)或主题(Topic):
- 存储消息的逻辑容器。
- 消息(Message):
- 传输的数据本身。

MQ在分布式系统中的主要作用包括:
- 解耦:
- 允许不同系统或模块之间通过消息进行通信,而不需要直接调用。
- 降低系统间的依赖性,提高系统的可维护性和扩展性。
- 异步处理:
- 允许非关键路径的操作异步进行,提高系统响应速度。
- 例如:用户注册后发送欢迎邮件,可以通过MQ异步处理。
- 流量削峰:
- 在高并发场景下,可以缓冲短时间内的高峰请求。
- 防止突发流量对后端系统造成冲击。
- 数据分发:
- 实现一对多的消息推送,如发布-订阅模式。
- 可靠性:
- 通过消息持久化,确保在系统故障时不会丢失数据。
- 顺序保证:
- 某些MQ实现可以保证消息的顺序性,这在某些场景下非常重要。
- 缓冲:
- 允许消费者以自己的速度处理消息,不会因为生产速度过快而崩溃。
常见的MQ产品包括:
- RabbitMQ:支持多种协议,易于部署和使用。
- Kafka:高吞吐量,适合大数据场景。
- RocketMQ:阿里巴巴开源的消息中间件,在金融场景中表现出色。
- ActiveMQ:Apache旗下的开源消息中间件,成熟稳定。
每种MQ都有其特点和适用场景,选择时需要根据具体需求进行评估。
短链接设计
「面试官」:非常好的解释。现在,假设我们需要设计一个短链接服务,如果一个访问链接很长,如何设计一个短链接?如果使用哈希算法,存在哈希冲突了生成重复短链接怎么办?
『求职者』:设计短链接服务是一个有趣的系统设计问题。我会这样设计:
- 基本流程:
- 接收长URL
- 生成短码
- 存储长URL和短码的映射
- 返回短链接
- 短码生成方法:a. 哈希算法:
b. 计数器方法:
c. 随机生成:
- 使用MD5或SHA-256对长URL进行哈希
- 取哈希结果的前6-8位作为短码
- 维护一个全局递增计数器
- 将计数器的值转换为62进制(0-9, a-z, A-Z)
- 随机生成6-8位的字符串
- 处理哈希冲突:如果使用哈希算法,确实可能出现冲突。解决方法包括:a. 链式法:
b. 开放寻址法:
c. 重新哈希:
- 当发生冲突时,在原有短码后附加一个计数器
- 例如:abc123 -> abc123-1 -> abc123-2
- 当发生冲突时,尝试下一个可用的短码
- 例如:如果abc123被占用,尝试abc124,以此类推
- 当发生冲突时,对原始URL加上一个salt值,然后重新哈希
- 例如:hash(url + "1"), hash(url + "2"),直到找到未被使用的短码
- 数据存储:
- 使用关系型数据库(如MySQL)存储长URL和短码的映射
- 使用Redis等缓存系统提高读取性能
- 系统架构:
graph TD
A[负载均衡器] --> B[Web服务器]
B --> C[短链接生成服务]
C --> D[数据库]
C --> E[缓存]
F[重定向服务] --> D
F --> E
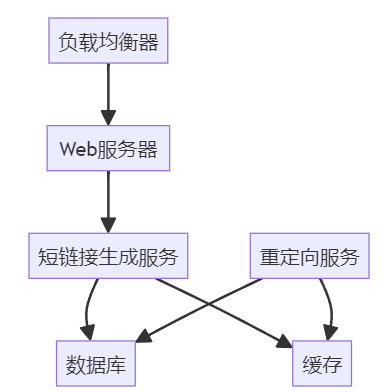
- 优化考虑:
- 使用布隆过滤器快速判断短码是否存在
- 实现分布式锁避免并发问题
- 考虑短链接的过期策略
- 安全性考虑:
- 实现访问频率限制,防止滥用
- 提供短链接预览功能,避免钓鱼链接
这种设计可以有效地处理长URL到短链接的转换,同时解决了哈希冲突的问题。
反转链表(手撕代码)
「面试官」:很好的系统设计思路。现在,我们来做一个编程题。请你实现一个函数,用于反转一个单链表。你需要自己定义链表结构,实现反转函数,并写出测试用例。请使用Java语言。
『求职者』:好的,我来实现这个反转链表的函数。我会使用Java语言,并按照ACM模式来编写代码。
import java.util.*;
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class Main {
// 反转链表的函数
public static ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode current = head;
while (current != null) {
ListNode nextTemp = current.next;
current.next = prev;
prev = current;
current = nextTemp;
}
return prev;
}
// 用于打印链表的辅助函数
public static void printList(ListNode head) {
while (head != null) {
System.out.print(head.val + " ");
head = head.next;
}
System.out.println();
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读入链表节点的数量
int n = scanner.nextInt();
ListNode dummy = new ListNode(0);
ListNode current = dummy;
// 构建链表
for (int i = 0; i < n; i++) {
int val = scanner.nextInt();
current.next = new ListNode(val);
current = current.next;
}
System.out.println("Original list:");
printList(dummy.next);
// 反转链表
ListNode reversed = reverseList(dummy.next);
System.out.println("Reversed list:");
printList(reversed);
scanner.close();
}
}
这段代码实现了以下功能:
- 定义了
ListNode类来表示链表节点。 - 实现了
reverseList函数来反转链表。 - 提供了
printList辅助函数来打印链表。 - 在
main函数中,我们:
- 读取用户输入来构建链表
- 打印原始链表
- 反转链表
- 打印反转后的链表
使用示例: 输入:
5
1 2 3 4 5
输出:
Original list:
1 2 3 4 5
Reversed list:
5 4 3 2 1
这个实现的时间复杂度是 O(n),其中 n 是链表的长度。空间复杂度是 O(1),因为我们只使用了常数级的额外空间。
这种实现方式满足了ACM模式的要求,可以直接在Online Judge系统中运行和测试。
「面试官」:非常好的实现。你能解释一下反转链表的过程吗?为什么这种方法可以成功反转链表?
『求职者』:当然,我很乐意解释反转链表的过程。
反转链表的核心思想是改变每个节点的next指针,让它指向前一个节点而不是后一个节点。我们通过遍历链表来实现这一点。让我用一个图来说明这个过程:
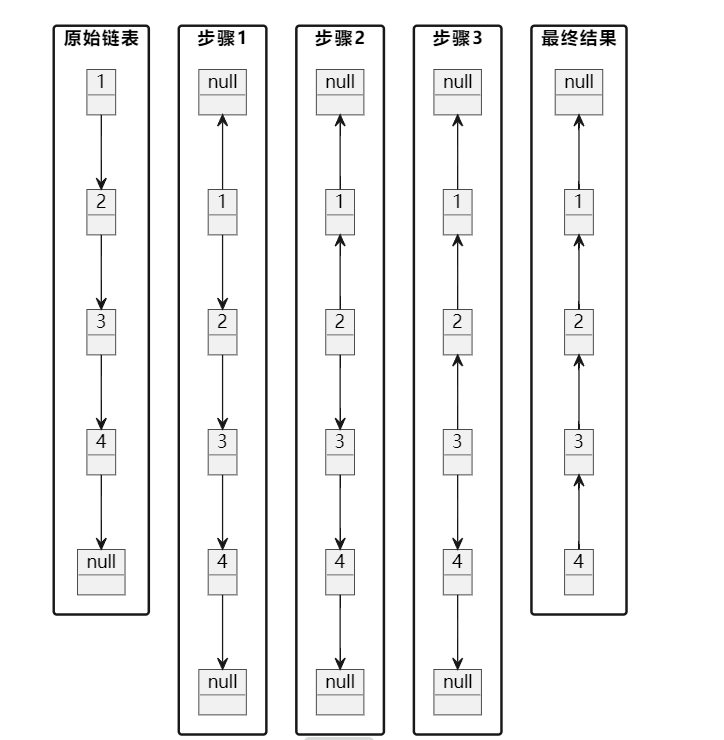
解释一下代码中的关键步骤:
- 我们使用三个指针:
prev、current和nextTemp。
prev指向当前节点的前一个节点current指向当前正在处理的节点nextTemp用于暂存当前节点的下一个节点
- 在每次迭代中:
- 我们首先保存
current.next到nextTemp,因为我们即将改变current.next - 然后将
current.next指向prev,这就完成了当前节点的反转 - 接着,我们将
prev和current都向前移动一步,为下一次迭代做准备
- 循环继续,直到
current变为 null,这意味着我们已经处理完了所有节点 - 最后,我们返回
prev,因为在循环结束时,prev指向的是新的头节点(原来的尾节点)
这种方法之所以有效,是因为它巧妙地利用了三个指针来保持对必要信息的跟踪,同时逐步改变链表的结构。通过每次改变一个节点的指向,我们最终达到了反转整个链表的目的。
这个算法的优点是:
- 时间复杂度为 O(n):我们只需要遍历链表一次。
- 空间复杂度为 O(1):我们只使用了固定数量的额外空间(三个指针),不论链表多长。
这种就地反转的方法是处理链表反转问题的最优解之一,既高效又节省空间。
「面试官」:excellent!这次面试到此结束,你的表现很出色。谢谢你的时间。
『求职者』:非常感谢您的肯定和这次面试机会。我也从中学到了很多,期待有机会能加入您的团队,为公司做出贡献。再次感谢您的时间,祝您工作顺利!
#2023毕业生求职有问必答#收录网络上的各个公司,包括但不限于阿里、字节、腾讯、小红书等公司的面经,并给出参考答案。 什么?!你不会面试?🤨 看这个就对了!😄 OfferNow!
