算法工程师Python/C/C++高频面试题大汇总

写在前面
【三年面试五年模拟】栏目专注于分享AI行业中实习/校招/社招维度的必备面积知识点与面试方法,并向着更实战,更真实,更从容的方向不断优化迭代。也欢迎大家提出宝贵的意见或优化ideas,一起交流学习💪
大家好,我是Rocky。
本文是“三年面试五年模拟”之独孤九剑秘籍的特别系列,Rocky将独孤九剑秘籍前十二式的深度学习基础高频面试题梳理成汇总篇,分享给牛友们。
由于【三年面试五年模拟】系列都是Rocky在工作之余进行整理总结,难免有疏漏与错误之处,欢迎大家对可优化的部分进行指正,我将在后续的优化迭代版本中及时更正。
在【人人都是算法工程师】算法工程师的“三年面试五年模拟”之独孤九剑秘籍(先行版)中我们阐述了这个program的愿景与规划。
希望独孤九剑秘籍的每一式都能让江湖中的英雄豪杰获益。

关于作者
Rocky在校招期间拿到了北京,上海,杭州,深圳,广州等地的约10个算法offer,现在是一名AIGC算法研究员,目前在国内大厂专注于AI算法解决方案的实现与创新业务的应用落地。
在研究生期间,Rocky曾在京东研究院,星环科技,联想研究院,北大方正信产集团研究院,百融云创,中科院软件所等公司做算法实习生。
Rocky喜欢参加算法竞赛,多次获得CVPR,AAAI,Kaggle平台的算法竞赛全球冠军和Top成绩。
Rocky相信人工智能,数据科学,商业逻辑,金融工具,终身成长,以及顺应时代的潮流会赋予我们超能力。
Rocky多次进行创业实践,深刻理解商业模式,上下游,现金流,成本利润,产品销量等维度对公司生存的影响。
Rocky喜欢分享和交流,秉持着“也要学习也要酷”的生活态度,希望能和大家多多交流。CV算法,面试,简历,求职等问题都可直接和我交流~
也欢迎大家多多关注Rocky以及Rocky的牛客专栏《三年面试五年模拟之独孤九剑秘籍》,一起学习成长,给Rocky的创作带来更多动力!
So,enjoy:
正文开始
----【目录先行】----
-
Python中assert的作用?
-
Python中互换变量有不用创建临时变量的方法吗?
-
Python中的主要数据结构都有哪些?
-
Python中的可变对象和不可变对象?
-
Python中的None代表什么?
-
Python中和的区别?
-
Python中Numpy的broadcasting机制?
-
Python中的实例方法、静态方法和类方法三者区别?
-
Python中常见的切片操作
-
Python中如何进行异常处理?
-
Python中remove,del以及pop之间的区别?
-
C/C++中内存泄漏以及解决方法?
-
C/C++中野指针的概念?
-
C/C++中面向对象和面向过程的区别?
-
C/C++中常用容器功能汇总
-
C/C++中指针和引用的区别
-
C/C++中宏定义的相关知识
-
C/C++中typedef关键字的相关知识
-
Python中迭代器的概念?
-
Python中生成器的相关知识
-
Python中装饰器的相关知识
-
Python的深拷贝与浅拷贝?
-
Python是解释语言还是编译语言?
-
Python的垃圾回收机制
-
Python里有多线程吗?
-
Python中range和xrange的区别?
-
Python中列表和元组的区别?
-
Python中dict(字典)的底层结构?
-
常用的深度学习框架有哪些,都是哪家公司开发的?
-
PyTorch动态图和TensorFlow静态图的区别?
-
C/C++中面向对象的相关知识
-
C/C++中struct的内存对齐与内存占用计算?
-
C/C++中智能指针的定义与作用?
-
C/C++中程序的开发流程?
-
C/C++中数组和链表的优缺点?
-
C/C++中的new和malloc有什么区别?
【一】Python中assert的作用?
Python中assert(断言)用于判断一个表达式,在表达式条件为的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况。
Rocky直接举一些例子:
>>> assert True
>>> assert False
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
>>> assert 1 == 1
>>> assert 1 == 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
>>> assert 1 != 2
【二】Python中互换变量有不用创建临时变量的方法吗?
在Python中,当我们想要互换两个变量的值或将列表中的两个值交换时,我们可以使用如下的格式进行,不需要创建临时变量:
x, y = y, x
这么做的原理是什么呢?
首先一般情况下Python是从左到右解析一个语句的,但在赋值操作的时候,因为是右值具有更高的计算优先级,所以需要从右向左解析。
对于上面的代码,它的执行顺序如下:
先计算右值(这里是简单的原值,但可能会有表达式或者函数调用的计算过程), 在内存中创建元组(tuple),存储分别对应的值;计算左边的标识符,元组被分别分配给左值,通过解包(unpacking),元组中第一个标示符对应的值,分配给左边第一个标示符,元组中第二个标示符对应的值,分配给左边第二个标示符,完成了和的值交换。
【三】Python中的主要数据结构都有哪些?
- 列表(list)
- 元组(tuple)
- 字典(dict)
- 集合(set)
【四】Python中的可变对象和不可变对象?
可变对象与不可变对象的区别在于对象本身是否可变。
可变对象:list(列表) dict(字典) set(集合)
不可变对象:tuple(元组) string(字符串) int(整型) float(浮点型) bool(布尔型)
【五】Python中的None代表什么?
None是一个特殊的常量,表示空值,其和False,0以及空字符串不同,它是一个特殊Python对象, None的类型是NoneType。
None和任何其他的数据类型比较返回False。
>>> None == 0
False
>>> None == ' '
False
>>> None == None
True
>>> None == False
False
我们可以将None复制给任何变量,也可以给None赋值。
【六】Python中和的区别?
和主要用于函数定义。我们可以将不定数量的参数传递给一个函数。
这里的不定的意思是:预先并不知道函数使用者会传递多少个参数, 所以在这个场景下使用这两个关键字。
是用来发送一个非键值对的可变数量的参数列表给一个函数。
我们直接看一个例子:
def test_var_args(f_arg, *argv):
print("first normal arg:", f_arg)
for arg in argv:
print("another arg through *argv:", arg)
test_var_args('hello', 'python', 'ddd', 'test')
-----------------结果如下-----------------------
first normal arg: hello
another arg through *argv: python
another arg through *argv: ddd
another arg through *argv: test
允许我们将不定长度的键值对, 作为参数传递给一个函数。如果我们想要在一个函数里处理带名字的参数, 我们可以使用。
我们同样举一个例子:
def greet_me(**kwargs):
for key, value in kwargs.items():
print("{0} == {1}".format(key, value))
greet_me(name="yasoob")
-----------结果如下-------------
name == yasoob
【七】Python中Numpy的broadcasting机制?
Python的Numpy库是一个非常实用的数学计算库,其broadcasting机制给我们的矩阵运算带来了极大地方便。
我们先看下面的一个例子:
>>> import numpy as np
>>> a = np.array([1,2,3])
>>> a
array([1, 2, 3])
>>> b = np.array([6,6,6])
>>> b
array([6, 6, 6])
>>> c = a + b
>>> c
array([7, 8, 9])
上面的代码其实就是把数组和数组中同样位置的每对元素相加。这里和是相同长度的数组。
如果两个数组的长度不一致,这时候broadcasting就可以发挥作用了。
比如下面的代码:
>>> d = a + 5
>>> d
array([6, 7, 8])
broadcasting会把扩展成,然后上面的代码就变成了对两个同样长度的数组相加。示意图如下(broadcasting不会分配额外的内存来存取被复制的数据,这里只是方面描述):

我们接下来看看多维数组的情况:
>>> e
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
>>> e + a
array([[2., 3., 4.],
[2., 3., 4.],
[2., 3., 4.]])
在这里一维数组被扩展成了二维数组,和的尺寸相同。示意图如下所示:

我们再来看一个需要对两个数组都做broadcasting的例子:
>>> b = np.arange(3).reshape((3,1))
>>> b
array([[0],
[1],
[2]])
>>> b + a
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5]])
在这里和都被扩展成相同的尺寸的二维数组。示意图如下所示:

总结broadcasting的一些规则:
- 如果两个数组维数不相等,维数较低的数组的shape进行填充,直到和高维数组的维数匹配。
- 如果两个数组维数相同,但某些维度的长度不同,那么长度为1的维度会被扩展,和另一数组的同维度的长度匹配。
- 如果两个数组维数相同,但有任一维度的长度不同且不为1,则报错。
>>> a = np.arange(3)
>>> a
array([0, 1, 2])
>>> b = np.ones((2,3))
>>> b
array([[1., 1., 1.],
[1., 1., 1.]])
>>> a.shape
(3,)
>>> a + b
array([[1., 2., 3.],
[1., 2., 3.]])
接下来我们看看报错的例子:
>>> a = np.arange(3)
>>> a
array([0, 1, 2])
>>> b = np.ones((3,2))
>>> b
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> a + b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (3,) (3,2)
【八】Python中的实例方法、静态方法和类方法三者区别?
不用@classmethod和@staticmethod修饰的方法为实例方法。在类中定义的方法默认都是实例方法。实例方法最大的特点是它至少要包含一个self参数,用于绑定调用此方法的实例对象,实例方法通常可以用类对象直接调用。
采用@classmethod修饰的方法为类方法。类方法和实例方法相似,它至少也要包含一个参数,只不过类方法中通常将其命名为cls,Python会自动将类本身绑定给cls参数。我们在调用类方法时,无需显式为cls参数传参。
采用@staticmethod修饰的方法为静态方法。静态方法没有类似self、cls这样的特殊参数,因此Python的解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
【九】Python中常见的切片操作
[:n]代表列表中的第一项到第n项。我们看一个例子:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[:6])
---------结果---------
[1, 2, 3, 4, 5, 6]
[n:]代表列表中第n+1项到最后一项:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[6:])
---------结果---------
[7, 8, 9, 10]
[-1]代表取列表的最后一个元素:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[-1])
---------结果---------
10
[:-1]代表取除了最后一个元素的所有元素:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[:-1])
---------结果---------
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[::-1]代表取整个列表的相反列表:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[::-1])
---------结果---------
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[1:]代表从第二个元素意指读取到最后一个元素:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[1:])
---------结果---------
[2, 3, 4, 5, 6, 7, 8, 9, 10]
[4::-1]代表取下标为4(即第五个元素)的元素和之前的元素反转读取:
example = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(example[4::-1])
---------结果---------
[5, 4, 3, 2, 1]
【十】Python中如何进行异常处理?
一般情况下,在Python无法正常处理程序时就会发生一个异常。异常在Python中是一个对象,表示一个错误。当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
捕捉异常可以使用try,except和finally语句。
try和except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
try:
6688 / 0
except:
'''异常的父类,可以捕获所有的异常'''
print "0不能被除"
else:
'''保护不抛出异常的代码'''
print "没有异常"
finally:
print "最后总是要执行我"
【十一】Python中remove,del以及pop之间的区别?
remove,del以及pop都可以用于删除列表、字符串等里面的元素,但是具体用法并不相同。
- remove是剔除第一个匹配的值。
- del是通过索引来删除当中的元素。
- pop是通过索引来删除当中的元素,并且返回该元素;若括号内不添加索引值,则默认删除最后一个元素。
>>> a = [0, 1, 2, 1, 3]
>>> a.remove(1)
>>> a
[0, 2, 1, 3]
>>> a = [0, 1, 2, 1, 3]
>>> del a[1]
[0, 2, 1, 3]
>>> a = [0, 1, 2, 1, 3]
>>> a.pop(1)
1
>>> a
[0, 2, 1, 3]
【十二】C/C++中野指针的概念?
野指针也叫空悬指针,不是指向null的指针,是未初始化或者未清零的指针。
产生原因:
-
指针变量未及时初始化。
-
指针free或delete之后没有及时置空。
解决办法:
-
定义指针变量及时初始化活着置空。
-
释放操作后立即置空。
【十三】C/C++中内存泄漏以及解决方法?
内存泄漏是指己动态分配的堆内存由于某种原因导致程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
解决方法:
造成内存泄漏的主要原因是在使用new或malloc动态分配堆上的内存空间,而并未使用delete或free及时释放掉内存造成的。所以解决方法就是注意new/delete和malloc/free一定要配套使用。
【十四】C/C++中面向对象和面向过程的区别?
面向对象(Object Oriented Programming,OOP)编程模型首先抽象出各种对象(各种类),并专注于对象与对象之间的交互,对象涉及的方法和属性都封装在对象内部。
面向对象的编程思想是一种依赖于类和对象概念的编程方式,一个形象的例子是将大象装进冰箱:
- 冰箱是一个对象,大象也是一个对象。
- 冰箱有自己的方法,打开、存储、关闭等;大象也有自己的方法,吃、走路等。
- 冰箱有自己的属性:长、宽、高等;大象也有自己的属性:体重、高度、体积等。
面向过程(Procedure Oriented Programming,POP)编程模型是将问题分解成若干步骤(动作),每个步骤(动作)用一个函数来实现,在使用的时候,将数据传递给这些函数。
面向过程的编程思想通常采用自上而下、顺序执行的方式进行,一个形象的例子依旧是将大象装进冰箱:
- 打开冰箱。
- 把大象装进冰箱。
- 关闭冰箱。
面向对象和面向过程的区别:
-
安全性角度。面向对象比面向过程安全性更高,面向对象将数据访问隐藏在了类的成员函数中,而且类的成员变量和成员函数都有不同的访问属性;而面向过程并没有办法来隐藏程序数据。
-
程序设计角度。面向过程通常将程序分为一个个的函数;而面向对象编程中通常使用一个个对象,函数通常是对象的一个方法。
-
逻辑过程角度。面向过程通常采用自上而下的方法;而面向对象通常采用自下而上的方法。
-
程序扩展性角度。面向对象编程更容易修改程序,更容易添加新功能。
【十五】C/C++中常用容器功能汇总
vector(数组)
vector是封装动态数组的顺序容器。
成员函数:
- at():所需元素值的引用。
- front():访问第一个元素(返回引用)。
- back():访问最后一个元素(返回引用)。
- beign():返回指向容器第一个元素的迭代器。
- end():返回指向容器末尾段的迭代器。
- empty():检查容器是否为空。
- size():返回容器中的元素数。
- capacity():返回当前存储空间能够容纳的元素数。
- clear():清除内容。
- insert():插入元素。
- erase():擦除元素。
- push_back():将元素添加到容器末尾。
- pop_back():移除末尾元素。
- *max_element(v.begin(), v.end()):返回数组最大值。
- *min_element(v.begin(), v.end()):返回数组最小值。
queue(队列)
queue是容器适配器,他是FIFO(先进先出)的数据结构。
成员函数:
- front():访问第一个元素(返回引用)。
- back():访问最后一个元素(返回引用)。
- empty():检查容器是否为空。
- size():返回容器中的元素数。
- push():向队列尾部插入元素。
- pop():删除首个元素。
deque(双端队列)
deque是有下标顺序容器,它允许在其首尾两段快速插入和删除。
成员函数:
- front():访问第一个元素(返回引用)。
- back():访问最后一个元素(返回引用)。
- beign():返回指向容器第一个元素的迭代器。
- end():返回指向容器末尾段的迭代器。
- empty():检查容器是否为空。
- size():返回容器中的元素数。
- clear(): 清除内容。
- insert():插入元素。
- erase():擦除元素。
- push_back():将元素添加到容器末尾。
- pop_back():移除末尾元素。
- push_front():插入元素到容器起始位置。
- pop_front():移除首元素。
- at():所需元素值的引用。
set(集合)
集合基于红黑树实现,有自动排序的功能,并且不能存放重复的元素。
成员函数:
-
begin()--返回指向第一个元素的迭代器。
-
clear()--清除所有元素。
-
count()--返回某个值元素的个数。
-
empty()--如果集合为空,返回true。
-
end()--返回指向最后一个元素的迭代器。
-
erase()--删除集合中的元素。
-
find()--返回一个指向被查找到元素的迭代器。
-
insert()--在集合中插入元素。
-
size()--集合中元素的数目。
unordered_set(无序集合)
无序集合基于哈希表实现,不能存放重复的元素。元素类型必须可以比较是否相等,因为这可以确定元素什么时候相等。
成员函数:
- empty():检查容器是否为空。
- size():返回容器中的元素数。
- insert():插入元素。
- clear():清除内容。
- count():返回匹配特定键的元素数量。
- find():寻找带有特定键的元素。
- erase()--删除集合中的元素。
unordered_map
unordered_map是关联容器,含有带唯一键的键-值对。
搜索、插入和元素移除拥有平均常数时间复杂度。
元素在内部不以任何特定顺序排序,而是组织进桶中。元素放进哪个桶完全依赖于其键的哈希。这允许对单独元素的快速访问,因为一旦计算哈希,则它准确指代元素所放进的桶。
成员函数:
- empty():检查容器是否为空。
- size():返回可容纳的元素数。
- insert():插入元素。
- clear():清除内容。
- count():返回匹配特定键的元素数量。
- find():寻找带有特定键的元素。
- erase()--删除集合中的元素。
【十六】C/C++中指针和引用的区别
C语言的指针让我们拥有了直接操控内存的强大能力,而C++在指针基础上又给我们提供了另外一个强力武器引用。
首先我们来看一下C++中对象的定义:对象是指一块能存储数据并具有某种类型的内存空间。
一个对象a,它有值和地址&a。运行程序时,计算机会为该对象分配存储空间,来存储该对象的值,我们通过该对象的地址,来访问存储空间中的值。
指针p也是对象,它同样有地址&p和存储的值p,只不过,p存储的是其他对象的地址。如果我们要以p中存储的数据为地址,来访问对象的值,则要在p前加引用操作符,即。
对象有常量(const)和变量之分,既然指针本身是对象,那么指针所存储的地址也有常量和变量之分,指针常量是指,指针这个对象所存储的地址是不可改变的,而常量指针的意思就是指向常量的指针。
我们可以把引用理解成变量的别名。定义一个引用的时候,程序把该引用和它的初始值绑定在一起,而不是拷贝它。计算机必须在声明引用r的同时就要对它初始化,并且r一经声明,就不可以再和其他对象绑定在一起了。
实际上,我们也可以把引用看作是通过一个指针常量来实现的,指向的地址不变,地址里的内容可以改变。
接下来我们来看看指针和引用的具体区别:
- 指针是一个新的变量,要占用存储空间,存储了另一个变量的地址,我们可以通过访问这个地址来修改另一个变量。而引用只是一个别名,还是变量本身,不占用具体存储空间,只有声明没有定义。对引用的任何操作就是对变量本身进行操作,以达到修改变量的目的。
- 引用只有一级,而指针可以有多级。
- 指针传参的时候,还是值传递,指针本身的值不可以修改,需要通过解引用才能对指向的对象进行操作。引用传参的时候,传进来的就是变量本身,因此变量可以被修改。
- 引用它一定不为空,因此相对于指针,它不用检查它所指对象是否为空,这样就提高了效率。
- 引用必须初始化,而指针可以不初始化。
我们可以看下面的代码:
int a,b,*p,&r=a;//正确
r=3;//正确:等价于a=3
int &rr;//出错:引用必须初始化
p=&a;//正确:p中存储a的地址,即p指向a
*p=4;//正确:p中存的是a的地址,对a所对应的存储空间存入值4
p=&b//正确:p可以多次赋值,p存储b的地址
“&”不仅能表示引用,还可以表示成地址,还有可以作为按位与运算符。这个要根据具体情况而定。比如上面的例子,等号左边的,被解释为引用,右边的被解释成取地址。
引用的操作加了比指针更多的限制条件,保证了整体代码的安全性和便捷性。引用的合理使用可以一定程度避免“指针满天飞”的情况,可以一定程度上提升程序鲁棒性。并且指针与引用底层实现都是一样的,不用担心两者的性能差距。
【十七】C/C++中宏定义的相关知识
宏定义可以把一个名称指定成任何一个文本。在完成宏定义后,无论宏名称出现在源代码的何处,预处理器都会将其替换成指定的文本。
//define 宏名 文本
#define WeThinkIn 666688889999
//define 宏名(参数) 文本
#define R(a,b) (a/b)
//注:带参数的宏替换最好在表达式整体上加括号,避免结果受其他运算影响。
宏定义的优点:
- 方便程序修改,如果一个常量在程序中大量使用,我们可以使用宏定义为其设置一个标识符。当我们想修改这个常量时,直接修改宏定义处即可,不必在程序中海量寻找所有相关位置。
- 提高程序的运行效率,使用带参数的宏定义可以完成函数的功能,但同时又比函数节省系统开销,提升程序运行效率。(无需调用函数这个流程)
宏定义和函数的区别:
- 宏在预处理阶段完成替换,之后替换的文本参与编译,相当于是恒等代换过程,运行时不存在函数调用,执行起来更快;而函数调用在运行时需要跳转到具体调用函数。
- 宏定义没有返回值;函数调用具有返回值。
- 宏定义参数没有类型,不进行类型检查;函数参数具有类型,需要检查类型。
- 宏定义不是说明或者语句,结尾不用加分号。
- 宏定义必须写在函数之外,其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用# undef命令;而函数作用域在函数调用处。
【十八】C/C++中typedef关键字的相关知识
我们可以使用typedef关键字来定义自己习惯的数据类型名称,来替代系统默认的基本类型名称以及其他类型等名称。
在工业界中,我们一般在如下两个场景中会见到typedef的身影。
// 1.为基本数据类型定义新的类型名
typedef unsigned int WeThinkIn_int;
typedef char* WeThinkIn_point;
// 2.为自定义数据类型(结构体、共用体和枚举类型)定义简洁的类型名称
typedef struct target_Object
{
int x;
int y;
} WeThinkIn_Object;
typedef与宏定义的区别:
- 宏主要用于定义常量及书写复杂的内容;typedef主要用于定义类型别名。
- 宏替换发生在预处理阶段,属于文本恒等替换;typedef是编译中发挥作用。
- 宏定义参数没有类型,不进行类型检查;typedef参数具有类型,需要检查类型。
- 宏不是语句,不用在最后加分号;typedef是语句,要加分号标识结束。
- 注意对指针的操作,typedef char * p_char和#define p_char char *区别巨大。
【十九】Python中迭代器的概念?
可迭代对象是迭代器、生成器和装饰器的基础。简单来说,可以使用for来循环遍历的对象就是可迭代对象。比如常见的list、set和dict。
我们来看一个🌰:
from collections import Iterable
print(isinstance('abcddddd', Iterable)) # str是否可迭代
print(isinstance([1,2,3,4,5,6], Iterable)) # list是否可迭代
print(isinstance(12345678, Iterable)) # 整数是否可迭代
-------------结果如下----------------
True
True
False
当对所有的可迭代对象调用 dir() 方法时,会发现他们都实现了 iter 方法。这样就可以通过 iter(object) 来返回一个迭代器。
x = [1, 2, 3]
y = iter(x)
print(type(x))
print(type(y))
------------结果如下------------
<class 'list'>
<class 'list_iterator'>
可以看到调用iter()之后,变成了一个list_iterator的对象。可以发现增加了一个__next__方法。所有实现了__iter__和__next__两个方法的对象,都是迭代器。
迭代器是带状态的对象,它会记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出Stoplteration异常。
x = [1, 2, 3]
y = iter(x)
print(next(y))
print(next(y))
print(next(y))
print(next(y))
----------结果如下----------
1
2
3
Traceback (most recent call last):
File "/Users/Desktop/test.py", line 6, in <module>
print(next(y))
StopIteration
如何判断对象是否是迭代器,和判断是否是可迭代对象的方法差不多,只要把 Iterable 换成 Iterator。
Python的for循环本质上就是通过不断调用next()函数实现的,举个栗子,下面的代码先将可迭代对象转化为Iterator,再去迭代。这样可以节省对内存,因为迭代器只有在我们调用 next() 才会实际计算下一个值。
x = [1, 2, 3]
for elem in x:
...

itertools 库提供了很多常见迭代器的使用。
>>> from itertools import count # 计数器
>>> counter = count(start=13)
>>> next(counter)
13
>>> next(counter)
14
【二十】Python中生成器的相关知识
我们创建列表的时候,受到内存限制,容量肯定是有限的,而且不可能全部给他一次枚举出来。Python常用的列表生成式有一个致命的缺点就是定义即生成,非常的浪费空间和效率。
如果列表元素可以按照某种算法推算出来,那我们可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,最简单的方法是改造列表生成式:
a = [x * x for x in range(10)]
print(a)
b = (x * x for x in range(10))
print(b)
--------结果如下--------------
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
<generator object <genexpr> at 0x10557da50>
还有一个方法是生成器函数,通过def定义,然后使用yield来支持迭代器协议,比迭代器写起来更简单。
def spam():
yield"first"
yield"second"
yield"third"
for x in spam():
print(x)
-------结果如下---------
first
second
third
进行函数调用的时候,返回一个生成器对象。在使用next()调用的时候,遇到yield就返回,记录此时的函数调用位置,下次调用next()时,从断点处开始。
我们完全可以像使用迭代器一样使用 generator ,当然除了定义。定义一个迭代器,需要分别实现 iter() 方法和 next() 方法,但 generator 只需要一个小小的yield。
generator还有 send() 和 close() 方法,都是只能在next()调用之后,生成器处于挂起状态时才能使用的。
python是支持协程的,也就是微线程,就是通过generator来实现的。配合generator我们可以自定义函数的调用层次关系从而自己来调度线程。
【二十一】Python中装饰器的相关知识
装饰器允许通过将现有函数传递给装饰器,从而向现有函数添加一些额外的功能,该装饰器将执行现有函数的功能和添加的额外功能。
装饰器本质上还是一个函数,它可以让已有的函数不做任何改动的情况下增加功能。
接下来我们使用一些例子来具体说明装饰器的作用:
如果我们不使用装饰器,我们通常会这样来实现在函数执行前插入日志:
def foo():
print('i am foo')
def foo():
print('foo is running')
print('i am foo')
虽然这样写是满足了需求,但是改动了原有的代码,如果有其他的函数也需要插入日志的话,就需要改写所有的函数,这样不能复用代码。
我们可以进行如下改写:
import logging
def use_log(func):
logging.warning("%s is running" % func.__name__)
func()
def bar():
print('i am bar')
use_log(bar) #将函数作为参数传入
-------------运行结果如下--------------
WARNING:root:bar is running
i am bar
这样写的确可以复用插入的日志,缺点就是显式的封装原来的函数,我们希望能隐式的做这件事。
我们可以用装饰器来写:
import logging
def use_log(func):
def wrapper(*args, **kwargs):
logging.warning('%s is running' % func.__name__)
return func(*args, **kwargs)
return wrapper
def bar():
print('I am bar')
bar = use_log(bar)
bar()
------------结果如下------------
WARNING:root:bar is running
I am bar
其中,use_log函数就是装饰器,它把我们真正想要执行的函数bar()封装在里面,返回一个封装了加入代码的新函数,看起来就像是bar()被装饰了一样。
但是这样写还是不够隐式,我们可以通过@语法糖来起到bar = use_log(bar)的作用。
import logging
def use_log(func):
def wrapper(*args, **kwargs):
logging.warning('%s is running' % func.__name__)
return func(*args, **kwargs)
return wrapper
@use_log
def bar():
print('I am bar')
@use_log
def haha():
print('I am haha')
bar()
haha()
------------结果如下------------
WARNING:root:bar is running
I am bar
WARNING:root:haha is running
I am haha
这样子看起来就非常简洁,而且代码很容易复用。可以看成是一种智能的高级封装。
【二十二】Python的深拷贝与浅拷贝?
在Python中,用一个变量给另一个变量赋值,其实就是给当前内存中的对象增加一个“标签”而已。
>>> a = [6, 6, 6, 6]
>>> b = a
>>> print(id(a), id(b), sep = '\n')
66668888
66668888
>>> a is b
True(可以看出,其实a和b指向内存中同一个对象。)
浅拷贝是指创建一个新的对象,其内容是原对象中元素的引用(新对象与原对象共享内存中的子对象)。
注:浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含了其他对象的对象,如列表,类实例等等。而对于数字、字符串以及其他“原子”类型,没有拷贝一说,产生的都是原对象的引用。
常见的浅拷贝有:切片操作、工厂函数、对象的copy()方法,copy模块中的copy函数。
>>> a = [6, 8, 9]
>>> b = list(a)
>>> print(id(a), id(b))
4493469248 4493592128 #a和b的地址不同
>>> for x, y in zip(a, b):
... print(id(x), id(y))
...
4489786672 4489786672
4489786736 4489786736
4489786768 4489786768
# 但是他们的子对象地址相同
从上面的例子中可以看出,a浅拷贝得到b,a和b指向内存中不同的list对象,但是他们的元素指向相同的int对象,这就是浅拷贝。
深拷贝是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。
深拷贝只有一种方式:copy模块中的deepcopy函数。
我们接下来用一个包含可变对象的列表来确切地展示浅拷贝和深拷贝的区别:
>>> a = [[6, 6], [8, 8], [9, 9]]
>>> b = copy.copy(a) # 浅拷贝
>>> c = copy.deepcopy(a) # 深拷贝
>>> print(id(a), id(b)) # a和b地址不同
4493780304 4494523680
>>> for x, y in zip(a, b): # a和b的子对象地址相同
... print(id(x), id(y))
...
4493592128 4493592128
4494528592 4494528592
4493779024 4493779024
>>> print(id(a), id(c)) # a和c不同
4493780304 4493469248
>>> for x, y in zip(a, c): # a和c的子对象地址也不同
... print(id(x), id(y))
...
4493592128 4493687696
4494528592 4493686336
4493779024 4493684896
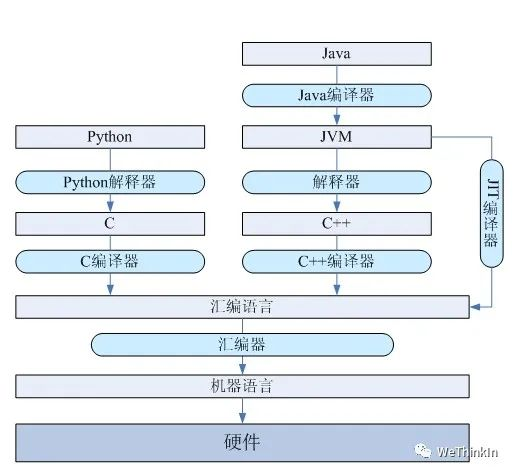
【二十三】Python是解释语言还是编译语言?
Python是解释语言。
解释语言的优点是可移植性好,缺点是运行需要解释环境,运行起来比编译语言要慢,占用的资源也要多一些,代码效率低。
编译语言的优点是运行速度快,代码效率高,编译后程序不可以修改,保密性好。缺点是代码需要经过编译才能运行,可移植性较差,只能在兼容的操作系统上运行。
【二十四】Python的垃圾回收机制
在Python中,使用引用计数进行垃圾回收;同时通过标记-清除算法解决容器对象可能产生的循环引用问题;最后通过分代回收算法提高垃圾回收效率。
【二十五】Python里有多线程吗?
Python里的多线程是假的多线程。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核,只有一个线程在解释器中运行。
对于I/O密集型任务,Python的多线程能起到作用,但对于CPU密集型任务,Python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其它的线程在这个线程等待I/O的时候运行。
如果是纯计算的程序,没有 I/O 操作,解释器会每隔 100 次操作就释放这把锁,让别的线程有机会执行(这个次数可以通过 sys.setcheckinterval 来调整)如果某线程并未使用很多I/O 操作,它会在自己的时间片内一直占用处理器和GIL。
缓解GIL锁的方法:多进程和协程(协程也只是单CPU,但是能减小切换代价提升性能)
【二十六】Python中range和xrange的区别?
首先,xrange函数和range函数的用法完全相同,不同的地方是xrange函数生成的不是一个list对象,而是一个生成器。
要生成很大的数字序列时,使用xrange会比range的性能优很多,因为其不需要一上来就开辟很大的内存空间。
Python 2.7.15 | packaged by conda-forge | (default, Jul 2 2019, 00:42:22)
[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> xrange(10)
xrange(10)
>>> list(xrange(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
xrange函数和range函数一般都用在循环的时候。具体例子如下所示:
>>> for i in range(0,7):
... print(i)
...
0
1
2
3
4
5
6
>>> for i in xrange(0,7):
... print(i)
...
0
1
2
3
4
5
6
在Python3中,xrange函数被移除了,只保留了range函数的实现,但是此时range函数的功能结合了xrange和range。并且range函数的类型也发生了变化,在Python2中是list类型,但是在Python3中是range序列的对象。
【二十七】Python中列表和元组的区别?
-
列表是可变的,在创建之后可以对其进行任意的修改。
-
元组是不可变的,元组一旦创建,便不能对其进行更改,可以元组当作一个只读版本的列表。
-
元组无法复制。
-
Python将低开销的较大的块分配给元组,因为它们是不可变的。对于列表则分配小内存块。与列表相比,元组的内存更小。当你拥有大量元素时,元组比列表快。
【二十八】Python中dict(字典)的底层结构?
Python的dict(字典)为了支持快速查找使用了哈希表作为底层结构,哈希表平均查找时间复杂度为O(1)。CPython 解释器使用二次探查解决哈希冲突问题。
【二十九】常用的深度学习框架有哪些,都是哪家公司开发的?
-
PyTorch:Facebook
-
TensorFlow:Google
-
Keras:Google
-
MxNet:Dmlc社区
-
Caffe:UC Berkeley
-
PaddlePaddle:百度
【三十】PyTorch动态图和TensorFlow静态图的区别?
PyTorch动态图:计算图的运算与搭建同时进行;其较灵活,易调节。
TensorFlow静态图:计算图先搭建图,后运算;其较高效,不灵活。

【三十一】C/C++中面向对象的相关知识
面向对象程序设计(Object-oriented programming,OOP)有三大特征 ——封装、继承、多态。
封装:把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。 关键字:public, protected, private。不写默认为 private。
-
public 成员:可以被任意实体访问。
-
protected 成员:只允许被子类及本类的成员函数访问。
-
private 成员:只允许被本类的成员函数、友元类或友元函数访问。
继承:基类(父类)——> 派生类(子类)
多态:即多种状态(形态)。简单来说,我们可以将多态定义为消息以多种形式显示的能力。多态是以封装和继承为基础的。
C++ 多态分类及实现:
-
重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
-
子类型多态(Subtype Polymorphism,运行期):虚函数
-
参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
-
强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
【三十二】C/C++中struct的内存对齐与内存占用计算?
什么是内存对齐?计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是有效对齐值的倍数。
什么是有效对齐值?计算机系统有默认对齐系数n,可以通过#pragma pack(n)来指定。有效对齐值就等与该对齐系数和结构体中最长的数据类型的长度两者最小的那一个值,比如对齐系数是8,而结构体中最长的是int,4个字节,那么有效对齐值为4。
为什么要内存对齐?假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的连续四个字节地址中。当4字节存取粒度的处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器,这需要做很多工作,整体效率较低。

struct内存占用如何计算?结构体的内存计算方式遵循以下规则:
-
数据成员对齐规则:第一个数据成员放在offset为0的地方,以后的每一个成员的offset都必须是该成员的大小与有效对齐值相比较小的数值的整数倍,例如第一个数据成员是int型,第二个是double,有效对齐值为8,所以double的起始地址应该为8,那么第一个int加上内存补齐用了8个字节
-
结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部有效对齐值的整数倍地址开始存储。(比如struct a中存有struct b,b里有char, int, double,那b应该从8的整数倍开始存储)
-
结构体内存的总大小,必须是其有效对齐值的整数倍,不足的要补齐。
我们来举两个🌰:
#include <stdio.h>
#pragma pack(8)
int main()
{
struct Test
{
int a;
//long double大小为16bytes
long double b;
char c[10];
};
printf("%d", sizeof(Test));
return 0;
}
struct的内存占用为40bytes
#include <stdio.h>
#pragma pack(16)
int main()
{
struct Test
{
int a;
//long double大小为16bytes
long double b;
char c[10];
}
printf("%d", sizeof(Test));
return 0;
}
struct的内存占用为48bytes
【三十三】C/C++中智能指针的定义与作用?
智能指针是一个类,这个类的构造函数中传入一个普通指针,析构函数中释放传入的指针。智能指针的类都是栈上的对象,所以当函数(或程序)结束时会自动被释放。
(注:不能将指针直接赋值给一个智能指针,一个是类,一个是指针。)
常用的智能指针:智能指针在C++11版本之后提供,包含在头文件中,主要是shared_ptr、unique_ptr、weak_ptr。unique_ptr不支持复制和赋值。当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果原来的unique_ptr 将存在一段时间,编译器将禁止这么做。shared_ptr是基于引用计数的智能指针。可随意赋值,直到内存的引用计数为0的时候这个内存会被释放。weak_ptr能进行弱引用。引用计数有一个问题就是互相引用形成环,这样两个指针指向的内存都无法释放。需要手动打破循环引用或使用weak_ptr。顾名思义,weak_ptr是一个弱引用,只引用,不计数。如果一块内存被shared_ptr和weak_ptr同时引用,当所有shared_ptr析构了之后,不管还有没有weak_ptr引用该内存,内存也会被释放。所以weak_ptr不保证它指向的内存一定是有效的,在使用之前需要检查weak_ptr是否为空指针。
智能指针的作用:C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,野指针,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
【三十四】C/C++中程序的开发流程?
开发一个C++程序的过程通常包括编辑、编译、链接、运行和调试等步骤。
编辑:编辑是C++程序开发过程的第一步,它主要包括程序文本的输入和修改。任何一种文本编辑器都可以完成这项工作。当用户完成了C++程序的编辑时,应将输入的程序文本保存为以.cpp为扩展名的文件(保存C++头文件时应以.h为扩展名)。
编译:C++是一种高级程序设计语言,它的语法规则与汇编语言和机器语言相比更接近人类自然语言的习惯。然而,计算机能够“看”懂的唯一语言是汇编语言。因此,当我们要让计算机“看”懂一个C++程序时,就必须使用编译器将这个C++程序“翻译”成汇编语言。编译器所做的工作实际上是一种由高级语言到汇编语言的等价变换。
汇编:将汇编语言翻译成机器语言指令。汇编器对汇编语言进行一系列处理后最终产生的输出结构称为目标代码,它是某种计算机的机器指令(二进制),并且在功能上与源代码完全等价。保存源代码和目标代码的文件分别称为源文件和目标文件( .obj)。
链接:要将汇编器产生的目标代码变成可执行程序还需要最后一个步骤——链接。链接工作是由“链接器”完成的,它将编译后产生的一个或多个目标文件与程序中用到的库文件链接起来,形成一个可以在操作系统中直接运行的可执行程序。(linux中的.o文件)
运行和调试:我们接下来就可以执行程序了。如果出现问题我们可以进行调试debug。
【三十五】C/C++中数组和链表的优缺点?
数组和链表是C/C++中两种基本的数据结构,也是两个最常用的数据结构。
数组的特点是在内存中,数组是一块连续的区域,并且数组需要预留空间。链表的特点是在内存中,元素的空间可以在任意地方,空间是分散的,不需要连续。链表中的元素都会两个属性,一个是元素的值,另一个是指针,此指针标记了下一个元素的地址。每一个数据都会保存下一个数据的内存的地址,通过此地址可以找到下一个数据。
数组的优缺点:
优点:查询效率高,时间复杂度可以达到O(1)。
缺点:新增和修改效率低,时间复杂度为O(N);内存分配是连续的内存,扩容需要重新分配内存。
链表的优缺点:
优点:新增和修改效率高,只需要修改指针指向即可,时间复杂度可以达到O(1);内存分配不需要连续的内存,占用连续内存少。
缺点:链表查询效率低,需要从链表头依次查找,时间复杂度为O(N)。
【三十六】C/C++中的new和malloc有什么区别?
new和malloc主要有以下三方面的区别:
-
malloc和free是标准库函数,支持覆盖;new和delete是运算符,支持重载。
-
malloc仅仅分配内存空间,free仅仅回收空间,不具备调用构造函数和析构函数功能,用malloc分配空间存储类的对象存在风险;new和delete除了分配回收功能外,还会调用构造函数和析构函数。
-
malloc和free返回的是void类型指针(必须进行类型转换),new和delete返回的是具体类型指针。
精致的结尾
Rocky后续会分享更多面试/实习/校招等高价值知识点,欢迎大家关注Rocky,为Rocky的义务劳动增加一些动力,谢谢大家!

三年面试五年模拟之独孤九剑秘籍专注于分享算法工程师校招/社招/实习中会遇到的高价值知识点。关注本专栏,不仅能助你拿到心仪的offer,也能让你构建算法工程师的完整知识结构。




