第九章关系查询处理和关系优化-第一节:查询处理
查询处理是关系数据库管理系统执行查询语句的过程,其任务是把用户提交给关系数据库管理系统的查询语句转换为高效的查询执行计划
一:查询处理步骤
关系数据库管理系统查询处理可以分为4个阶段:
- 查询分析
- 查询检查
- 查询优化
- 查询执行
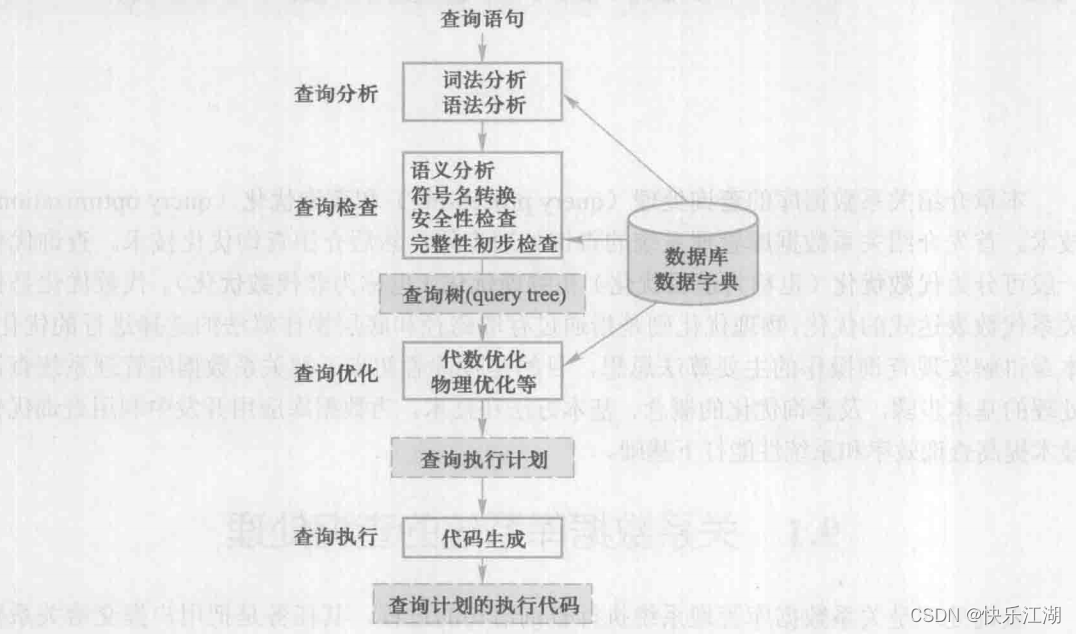
(1)查询分析
任务:对查询语句进行扫描,分析词法、语法是否符合SQL语法规则
- 如果没有语法错误转入下一步
- 如果有语法错误则在报告中显示错误
(2)查询检查
任务:
- 对合法的查询语句进行语义检查,即根据数据字典中有关的模式定义检查语句中的数据库对象,如关系名、属性名是否存在和有效
- 如果是对视图的操作,则要用视图消解方法把对视图的操作转换成对基本表的操作
- 还要对权限、完整性约束进行检查,如果违反则拒绝查询
- 检查通过后,把SQL查询语句转化为内部表示,也即等价的关系代数表达式
- 在此过程中,要把数据库对象的外部名称换为内部表示
- RDBMS一般用查询树(又称为语法分析树)来表示扩展的关系代数表达式
(3)查询优化
任务:每个查询都会有许多可供选择的执行策略和操作算法,查询优化就是选择一个高效执行的查询处理策略。按照优化的层次一般可以将查询优化分为
- 代数优化:是指关系代数表达式的优化,也即按照一定规则,通过对关系代数表达式进行等价变换,改变代数表达式中操作的次序和组合,使查询更高效
- 物理优化:是指存取路径和底层操作算法的选择。选择依据可以是基于规则的(rule based)、基于代价的(cost based)、基于语义的(semantic based)
(4)查询执行
依据优化器得到的执行策略生成查询执行计划,由 代码生成器(code generator) 生成执行这个查询计划的代码,然后加以执行,回送查询结果。
二:实现查询操作的算法示例
(1)选择操作的实现
以简单的单表选择为例,如下
SELECT* FROM STUDENT WHERE<条件表达式>
<条件表达式>可以有以下几种情况
- :无条件
- :Sno='201215121'
- :Sage > 20
- :Sdept='CS' AND Sage > 20
选择操作只涉及一个关系,典型的实现方法有
①:全表扫描
思想:假设可以使用的内存块为块
- 按照物理次序读
Student的块到内存 - 检查内存的每个元组,如果满足选择条件,则输出
- 如果
Student还有其他块未被处理,重复即可
优缺点:
- 优点:只需要用很少的内存(最少为1块)就可以运行,且控制简单。适用于规模较小的表
- 缺点:对于规模大的表进行顺序扫描,当选择率低时会使效率很低
②:索引(或散列)扫描
思想:如果选择条件中的属性上有索引(例如+树索引或索引),可以用索引扫描。通过索引先找到满足条件的元组指针,再通过元组指针在查询的基本表中找到元组。 一般来说,当选择率低于10%时建立索引才有意义
- 以 2为例:Sno='201215121',并且Sno上有索引,则可以使用索引得到Sno为'201215121'元组的指针,然后通过元组指针在Student表中检索到该学生
- 以 3为例:Sage>20, 并且Sage上有B+树索引,则可以使用B+树索引找到Sage=20的索引项,以此为入口点在B+树的顺序集上得到Sage>20的所有元组指针,然后通过这些元组指针到
Student表中检索到所有年龄大于20的学生 - 以 4为例: Sdept='CS' AND Sage>20, 如果
Sdept和Sage上都有索引,一种算法是,分别用上面两种方法找到Sdept='CS'的一组元组指针和Sage>20的另一组元组指针,求这两组指针的交集,再到Student表中检索,就得到计算机系年龄大于20岁的学生;另一种算法是,找到Sdept='CS'的一组元组指针,通过这些元组指针到Student表中检索,并对得到的元组检查另一些选择条件(如Sage>20) 是否满足,把满足条件的元组作为结果输出
(2)连接操作的实现
连接操作是查询处理中最常用也是最耗时的操作之一 。不失一般性,这里通过例子简单介绍 等值连接(或自然连接) 最常用的几种算法思想
SELECT * FROM Student,SC WHERE Student.Sno=SC.Sno;
①:嵌套循环方法(nested loop)
思想:对外层循环(Student表)的每一个元组,检索内层循环(SC表)中的每一个元组,并检查这两个元组在连接属性(Sno) 上是否相等。如果满足连接条件,则串接后作为结果输出,直到外层循环表中的元组处理完为止
②:排序-合并方法(sort-merge join)
思想:
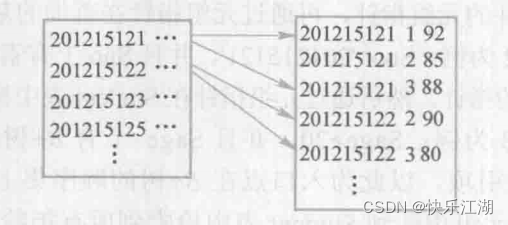
- 如果参与连接的表没有排好序,首先对
Student表和SC表按连接属性Sno排序 - 取Student表中第一个
Sno,依次扫描SC表中具有相同Sno的元组,把它们连接起来 - 当扫描到
Sno不相同的第 一个SC元组时,返回Student表扫描它的下一 个元组,再扫描SC表中具有相同Sno的元组,把它们连接起来
重复上述步骤直至Student扫描完毕
③:索引连接(index join)
思想:
- 在
SC表上已经建立了属性Sno的索引 - 对
Student中每一个元组,由Sno值通过SC的索引查找相应的SC元组 - 把这些
SC元组和Student元组连接起来
循环执行第二步和第三步,直至Student中的元组处理完毕
④:哈希连接(hash join)
思想:它把连接属性作为hash码,用同一个hash函数把Student表和SC表中的元组散列到hash表中
- 划分阶段(创建阶段):即创建hash表。对包含较少元组的表( 如
Student表)进行一遍处理,把它的元组按hash函数(hash码是连接属性)分散到hash表的桶中 - 试探阶段(连接阶段):对另一个表(
SC表)进行一遍处理,把SC表的元组也按同一个hash函数(hash 码是连接属性)进行散列,找到适当的hash桶,并把SC元组与桶中来自Student表并与之相匹配的元组连接起来。
数据库系统概论王珊第五版笔记 文章被收录于专栏
数据库系统概论王珊第五版笔记

 查看42道真题和解析
查看42道真题和解析


