
【Kafka从成神到升仙系列 二】生产者如何将消息放入到内存
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄(回复 "技术书籍" 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
往期推荐
Kafka从入门到成神系列
一、引言
初学一个技术,怎么了解该技术的源码至关重要。
对我而言,最佳的阅读源码的方式,那就是:不求甚解,观其大略
你如果进到庐山里头,二话不说,蹲下头来,弯下腰,就对着某棵树某棵小草猛研究而不是说先把庐山的整体脉络研究清楚了,那么你的学习方法肯定效率巨低而且特别痛苦。
最重要的还是慢慢地打击你的积极性,说我的学习怎么那么不 happy 啊,怎么那么没劲那,因为你的学习方法错了,大体读明白,先拿来用,用着用着,很多道理你就明白了。
先从整体上把关源码,再去扣一些细节问题。
举个简单的例子:
如果你刚接触 HashMap,你刚有兴趣去看其源码,在看 HashMap 的时候,有一个知识:当链表长度达到 8 之后,就变为了红黑树,小于 6 就变成了链表,当然,还和当前的长度有关。
这个时候,如果你去深究红黑树、为什么是 8 不是别的,又去查 泊松分布,最终会慢慢的搞死自己。
所以,正确的做法,我们先把这一部分给略过去,知道这个概念即可,等后面我们把整个庐山看完之后,再回过头抠细节。
当然,本章我们讲述 Kafka中的生产者消息如何发送到缓冲区
二、生产者
消息系统通常由生产者、消费者、消息代理三大部分组成,生产者将消息写入消息代理,消费者从消息代理中读取消息。
对于消息代理而育,生产者和消费者都属于客户端。
1. 属性配置
我们首先看下 Kafka 的生产者日常使用代码:
public void KafkaProducerTest(){
// Kafka生产者的属性配置
Properties props = new Properties();
// 设置生产者id
props.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo"); //
// bootstrap.servers 是Kafka集群的IP地址。多个时,使用逗号隔开
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 是否重试
props.put("enable.idempotence",true);
// 失败重试的次数
props.put("retries", 3);
// 16K 分析我们 msg 的大小,尽量触发批量发送,减少内存碎片和系统调用的复杂度
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "16384");
// 32M 可调优
props.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432");
// 60秒,当我们的生产者 send 阻塞时,会阻塞60S,如果60S还不能发的话,则直接返回
props.setProperty(ProducerConfig.MAX_BLOCK_MS_CONFIG, "60000");
// 同步和异步
props.setProperty(ProducerConfig.LINGER_MS_CONFIG, "0");
props.setProperty(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, "1048576");
// 未通过acks确认的发送请求 等于 1 的时候。主要是为了保障单分区的消息顺序性
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
// 32KB TCP发送的缓冲区大小 -1:系统的默认值
props.setProperty(ProducerConfig.SEND_BUFFER_CONFIG, "32768");
// 32KB TCP接受的缓冲区大小 -1:系统的默认值
props.setProperty(ProducerConfig.RECEIVE_BUFFER_CONFIG, "32768");
// 初始化
KafkaProducer<String, String> producer = new KafkaProducer<>( props, new StringSerializer(), new StringSerializer());
// 发送
producer.send(msg);
}
我们将一些配置信息写入到 Properties 里面,当我们 Kafka 生产者启动时,会自动读取其配置。
2 Kafak 实例化
当我们构建 Kafka实例 时,我们的 KafkaProducer 的代码如下:代码只展示重要部分
@SuppressWarnings("unchecked")
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
Metadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors interceptors,
Time time) {
try {
// 读取配置文件
this.producerConfig = config;
// 读取生产者ID
String clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
// 事务ID
String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG));
// 这里可以根据配置的 class 选择分区使用的算法
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
// 序列化key
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,Serializer.class);
// 序列化value
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,Serializer.class);
// 最大请求的大小
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 内存缓存的大小
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 生产者sender阻塞的时间
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
// 幂等性和事务
this.transactionManager = configureTransactionState(config, logContext, log);
// 实例化我们的 客户端记录收集器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
config.getInt(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
// 启动我们的sender线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics);
}
2.1 消息分区算法
我们实例化的代码中,有初始化分区算法:this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
我们介绍下分区的类构成:PartitionInfo
public class PartitionInfo {
private final String topic; // 主题名称
private final int partition; // 分区编号
private final Node leader; // 分区的leader副本
private final Node[] replicas; // 分区的所有副本
private final Node[] inSyncReplicas; // 分区中处于ISR的副本
}
在我们 org.apache.kafka.clients.producer.Partitioner,可实现该接口,实现自己的分区算法
Kafka 为我们提供的默认分区算法:DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取所有的分区
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
// 当前分区的个数
int numPartitions = partitions.size();
if (keyBytes == null) {
// 原子的累加器
int nextValue = counter.getAndIncrement();
// 存活的分区
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
// 去模存活的分区
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 没有存活的分区直接模所有的分区
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// 如果有key的话,直接按照key的hash进行分区,这也是kafka按照key值分区的原因
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
我们可以看到,分区算法中可以按照 key 值进行区分,也从侧面证明了我们之前所讲的,可以通过 Kafka 按 key 分区的算法,将我们的业务定义唯一 key 进行分区。
2.2 客户端记录收集器
我们之前实例化的时候,有这么一个实例的创建:RecordAccumulator 也就是我们的记录收集器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
config.getInt(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
这个收集器后面发送消息的时候会讲到,这里先大概的了解其作用即可
我们的生产者会将消息发送到我们的 RecordAccumulator ,再去通知我们的 Sender 线程去进行获取发送
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTDrWoTV-1648741455816)(C:\Users\黄良帅\AppData\Roaming\Typora\typora-user-images\image-20220329235147256.png)]](https://img-blog.csdnimg.cn/0cf86bc83e104333bb7ccba09f84dc8f.png)
2.3 幂等和事务
实例化代码中:this.transactionManager = configureTransactionState(config, logContext, log);
主要读取我们 ProducerConfig 的配置,看有没有配置了幂等和事务的配置项:
ENABLE_IDEMPOTENCE_CONFIG:enable.idempotenceRANSACTIONAL_ID_CONFIG = transactional.id
2.4 Sender 线程
// 启动我们的sender线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
这里我们简单的熟悉一下 Sender ,和上面 RecordAccumulator 一样,我们发送消息的时候会进行详细讲解
点进我们的 Sender,我们发现这个类实现了 Runnable
public class Sender implements Runnable {}
而我们的 KafkaThread 则继承了 Thread 类
public class KafkaThread extends Thread {}
这一块,学过多线程的应该都懂接下来该怎么做了吧,对的,直接将实现 Runnable 的类丢进 Thread 中
然后,启动我们的 Sender 线程
ioThread.start();
3. 消息的发送
3.1 幂等性和事务
我们点开 Producer.send(msg) 的源码,可以看到如下:
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 拦截器:可以在发送消息之前修改消息的内容,比如加密、解密、修改信息等等
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
我们继续追 doSend(interceptedRecord, callback); 的逻辑:同样,我们会删除一些不重要的代码
// 发送消息
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
ClusterAndWaitTime clusterAndWaitTime;
// 等待当前的元数据更新:这里的更新主要依靠我们的 Sender 线程去进行更新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
Cluster cluster = clusterAndWaitTime.cluster;
// key 和 value 的序列化
byte[] serializedKey;
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue;
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 使用实例化的分区算法算出所在的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// 生产者回调将确保调用“回调”和拦截器回调
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 是否开启了幂等和事务,是的话,添加一下
if (transactionManager != null && transactionManager.isTransactional()){
transactionManager.maybeAddPartitionToTransaction(tp);
}
// 将消息发送到我们的记录收集器中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);
// 如果当前batch满了或者是一个新的batch,唤醒我们的 sender
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}
}
元数据的更新,我们会在 Sender 线程讲解,前面的分区算法,我们之前已经讲解过,将其略过
到了开启幂等和事务这个地方:
// 这个地方我们在初始化 KafkaProducer 的时候,初始化过
if (transactionManager != null && transactionManager.isTransactional()){
transactionManager.maybeAddPartitionToTransaction(tp);
}
public synchronized void maybeAddPartitionToTransaction(TopicPartition topicPartition) {
// 一些异常的捕捉
failIfNotReadyForSend();
// 看当前的分区是否已经被记录了,如果记录了直接返回即可
if (isPartitionAdded(topicPartition) || isPartitionPendingAdd(topicPartition)){
return;
}
log.debug("Begin adding new partition {} to transaction", topicPartition);
// 将当前分区加入到 newPartitionsInTransaction 中
newPartitionsInTransaction.add(topicPartition);
}
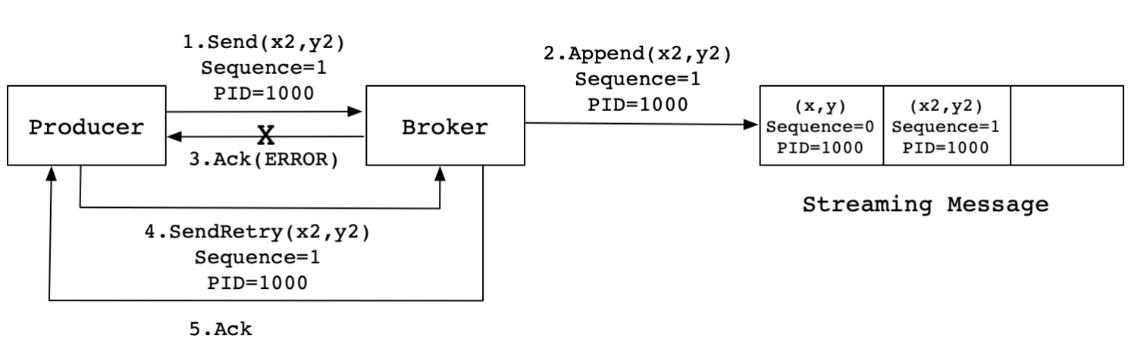
这里的幂等性主要由:sequenceNumber 和 producerId 来进行把控,具体分析将在 Sender 线程中
这里先用一张图概括其作用
3.2 记录收集器的添加
这里我们需要提前讲述一下关于 RecordAccumulator 的数据结构
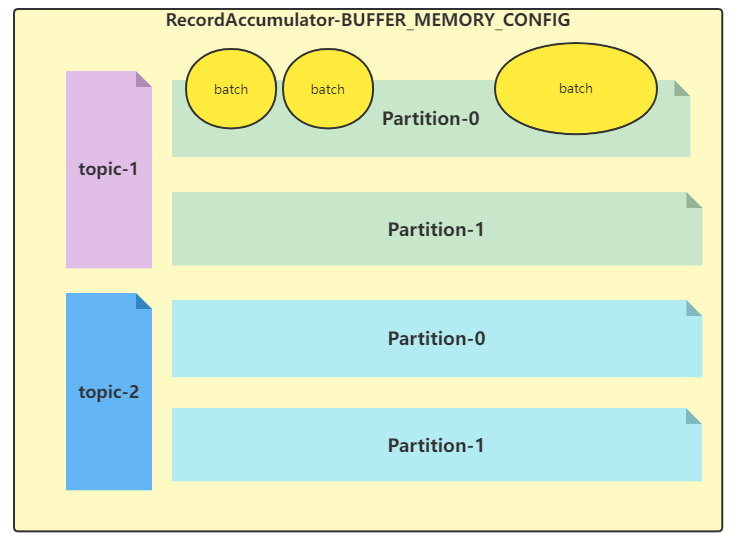
在我们的 RecordAccumulator 中,有一种数据结构如下:private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
每一个分区对应着一个双端队列,双端队列里面存放着 RecordBatch,RecordBatch 的大小取决于我们一开始的配置 BATCH_SIZE_CONFIG
- 如果当前消息大于batch的大小:申请一个大的batch存放该消息
- 如果当前消息小于batch的大小:直接放入即可
另外,我们 RecordAccumulator 的大小和配置 BUFFER_MEMORY_CONFIG 有关
我们来看下具体的源码,了解生产者怎么样把消息发送到 RecordAccumulator 里面
3.2.1 整体流程图
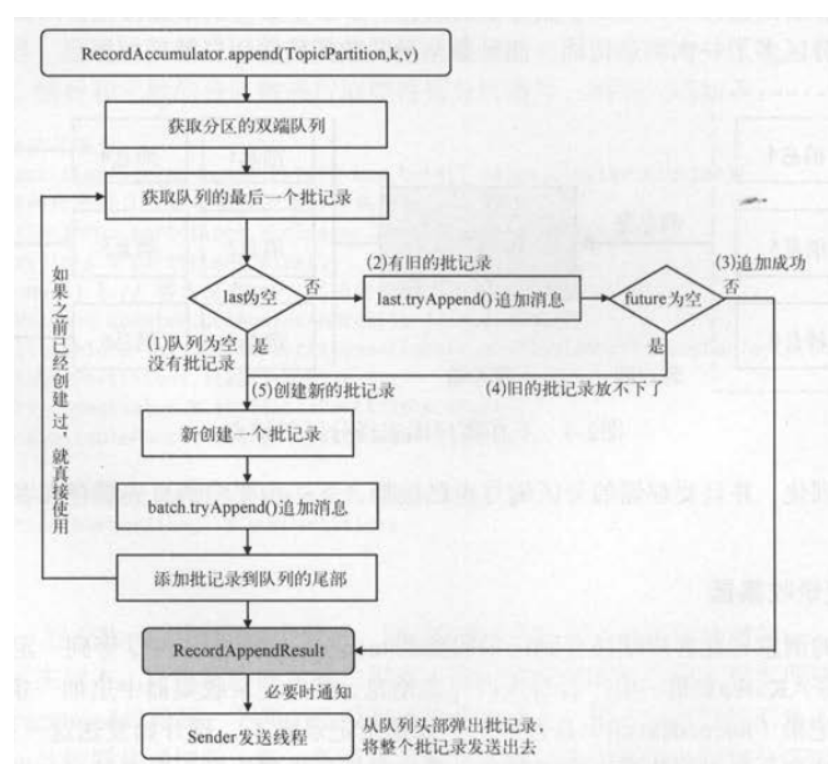
3.2.2 源码流程图

3.2.3 源码注释
// 将消息发送到我们的记录收集器中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);
// 消息进行添加
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// 数值的累加
appendsInProgress.incrementAndGet();
try {
// 获取该分区的双端队列
Deque<RecordBatch> dq = getOrCreateDeque(tp);
// 加锁,线程安全
synchronized (dq) {
// 尝试向里面添加数据
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
// 如果我们添加成功的话,就直接返回我们的结果即可
if (appendResult != null)
return appendResult;
}
// 我们没有正在进行的记录批次,请尝试分配新的批次
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
// 分配给定大小的缓冲区
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 需要检查producer在获取出列锁后是否再次关闭。.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
// 尝试向里面添加数据
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
// 将我们当前的缓存区放到池里面,标记其为空闲
free.deallocate(buffer);
return appendResult;
}
// 构建了一个可以写的消息的内存
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
// 申请了一个RecordBatch的空的批次
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
// 再次添加,这个地方肯定会添加进去
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
// 将这个批次放入到我们队列的尾部
dq.addLast(batch);
// 保存尚未确认的记录批
incomplete.add(batch);
// 直接返回一个结果:
// 参数2:或者当前的队列大于1或者是不是满了
// 参数3:如果是一个新的批次
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
/**
* 根据分区获取该分区的双端队列
* 如果存在,则直接返回
* 不存在,则创建一个空的
*/
private Deque<RecordBatch> getOrCreateDeque(TopicPartition tp) {
// 根据我们的分区获取双端队列
// 双端队列存在很多个RecordBatch
Deque<RecordBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<RecordBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque)
{
// 获取该队列的最后一个批记录
RecordBatch last = deque.peekLast();
/**
* 如果最后一个为空
* 直接返回 null
* 如果最后一个不为空
* 直接在最后一个批次进行添加
*/
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future == null)
last.records.close();
else
return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
}
return null;
}
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
// 主要检查我们当前的这个批次里面还能不能添加消息(key,value)
if (!this.records.hasRoomFor(key, value)) {
return null;
} else {
// 如果可以添加的话
// 向我们当前的 batch 添加消息
long checksum = this.records.append(offsetCounter++, timestamp, key, value);
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
this.lastAppendTime = now;
// 初始化我们的 FutureRecordMetadata
// 已经追加成功了
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
if (callback != null)
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
三、总结
本章主要讲解了以下知识
- 如何创建一个Kafka的生产者及发送消息
new KafkaProducer()producer.send(msg)
- 实例化源代码进行的操作
- 初始化消息分区算法
- 初始化
key/value的分区算法 - 初始化我们的幂等和事务
transactionManager - 初始化我们的记录收集器
RecordAccumulator - 初始化我们的
Sender线程
- 消息发送进行的操作
- 幂等性和事务:将当前的分区放入到幂等记录中
- 记录收集器的添加
- 获取当前分区的双端队列,如果没有则创建
- 获取当前分区队列的最后一个
batch,如果存在,看是否还能添加消息,如果不能,则创建一个新的batch - 将当前
batch添加到双端队列里面
- 如果当前
bathch满了或者创建了一个新的batch,唤醒我们的Sender线程
下一章将讲解 Snder 线程,主要讲述 Sender 线程
- 如何初始化连接到 Broker
- 如何实现幂等和事务
- 如何将消息拉取成功并发送到Broker
- 如何实现
Sender到Broker的网络交互
喜欢 kafka 的可以点个关注吆,后续会继续更新其源码文章。
我是爱敲代码的小黄,我们下次再见。
#Java##面试##中间件##大厂##算法# 查看7道真题和解析
查看7道真题和解析