
Redis 数据持久化机制 RDB 和 AOF介绍
🍀java全知识点学习笔记 思维导图 面试跳槽必备 码云仓库地址 https://gitee.com/vx202158/vx202158.git 🍀
:palm_tree:单线程的Redis为什么这么快?
:herb: Redis的 " 单线程 "
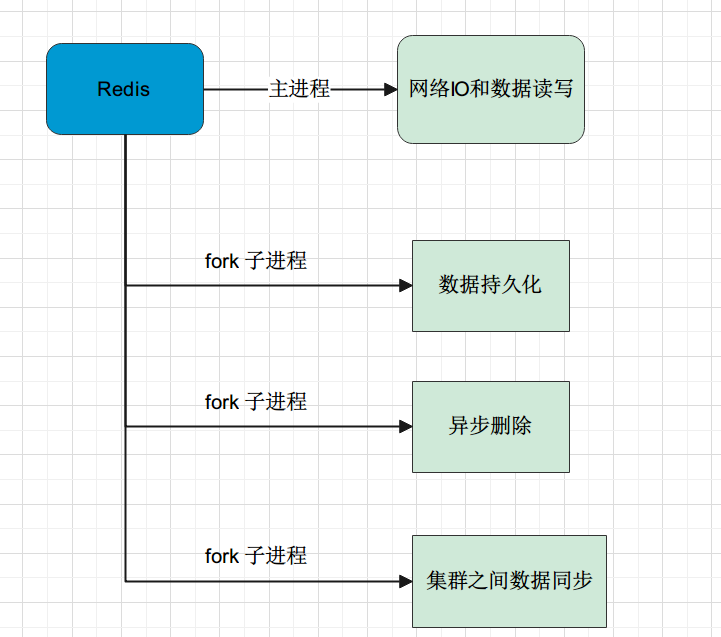
Redis的单线程指的的是Redis的 网络IO 和 数据读写 是由一个线程完成的
但Redis的 数据持久化 , 异步删除, 集群之间数据同步是由其他线程完成的
:herb: Redis快的原因
🍀 避免了维护多线程共享数据安全的开销
🍀 基于内存操作
🍀 ``高效的数据结构 跳表 和 哈希表
🍀采用多路IO复用,能在网络IO中并发处理大量的客户端请求
:palm_tree:Redis的数据持久化
由于Redis是基于内存操作的,数据都存储在内存中,如果一断电,数据必将丢失
Redis提供了两个数据持久化机制来解决这个问题
🍀AOF日志
🍀 RDB快照
:herb: AOF持久化机制
🍃 AOF持久化流程
客户端的请求写命令会被追加到AOF缓冲区 AOF缓冲区根据AOF持久化策略将操作同步到磁盘的AOF文件中 AOF文件超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量 Redis服务器重启时,会load加载AOF文件中的写操作
🍃 写后日志
写前日志
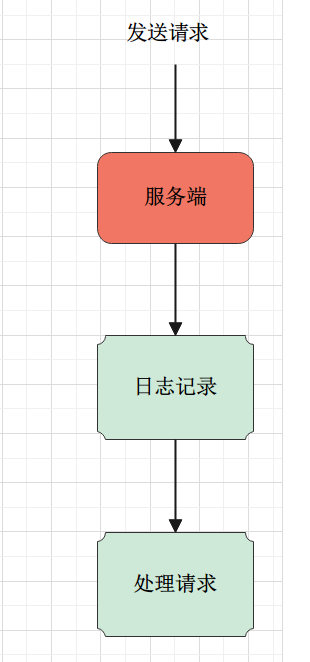
写后日志
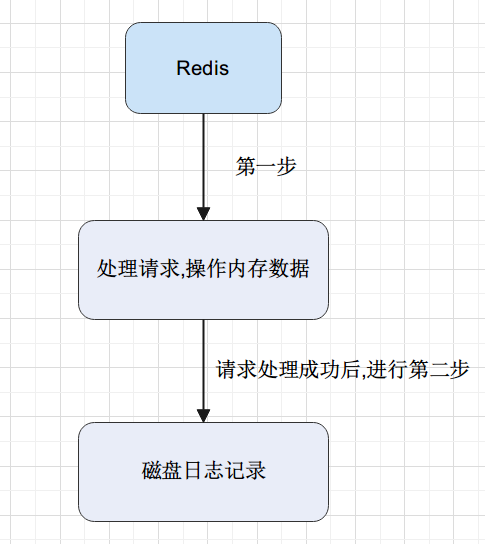
AOF为什么采用写后日志?
- 🍀首先要知道日志是用来恢复数据的 因此日志不能存储错误的命令 假如 采用写前日志,则需要对存入日志中的每一条命令进行检查,这样势必会带来性能开销 而redis就是为了追求速度 采用写后日志,只有能成功执行的命令才存入日志中 不用去对命令进行检查
- 🍀 由于Redis的读写操作是单线程的 采用写后日志 可以避免对 写操作的阻塞
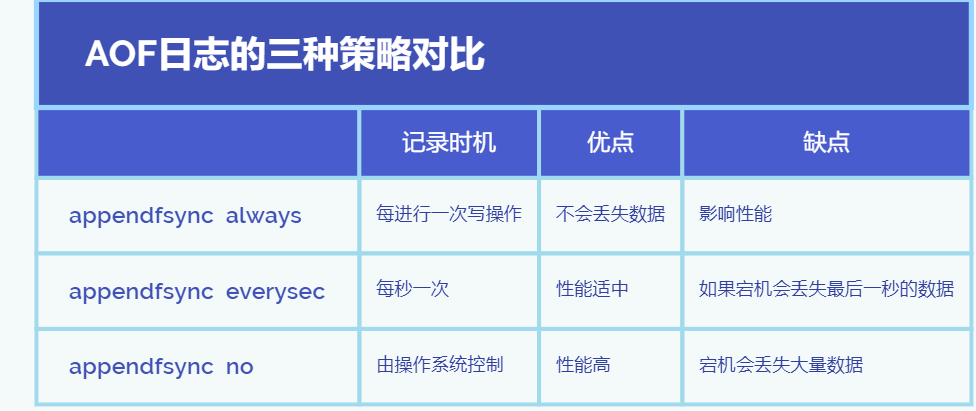
🍃日志记录的三种策略
🍀 appendfsync always 始终同步
🍀 appendfsync everysec 每秒同步一次
🍀 appendfsync no 不主动进行同步,把同步时机交给操作系统。
:cactus: 三者各有优缺点 :
appendfsync always 始终同步 每个写操作执行完毕后里面同步到日志文件中 性能较差但 数据 完整性 比较好
appendfsync everysec 每秒同步一次 每隔一秒钟进行一次同步,先将日志写到AOF文件的内存缓冲区,每隔一秒再把缓冲区的内容写入磁盘,如果宕机,本秒的数据可能丢失
appendfsync no 不主动进行同步,把同步时机交给操作系统 性能好,但是宕机会丢失大量数据
🍃AOF文件重写
由于AOF是记录每一条写操作命令,势必会让AOF文件越来越大,文件越大,恢复数据的时候越慢 因此需要对AOF文件进行重写
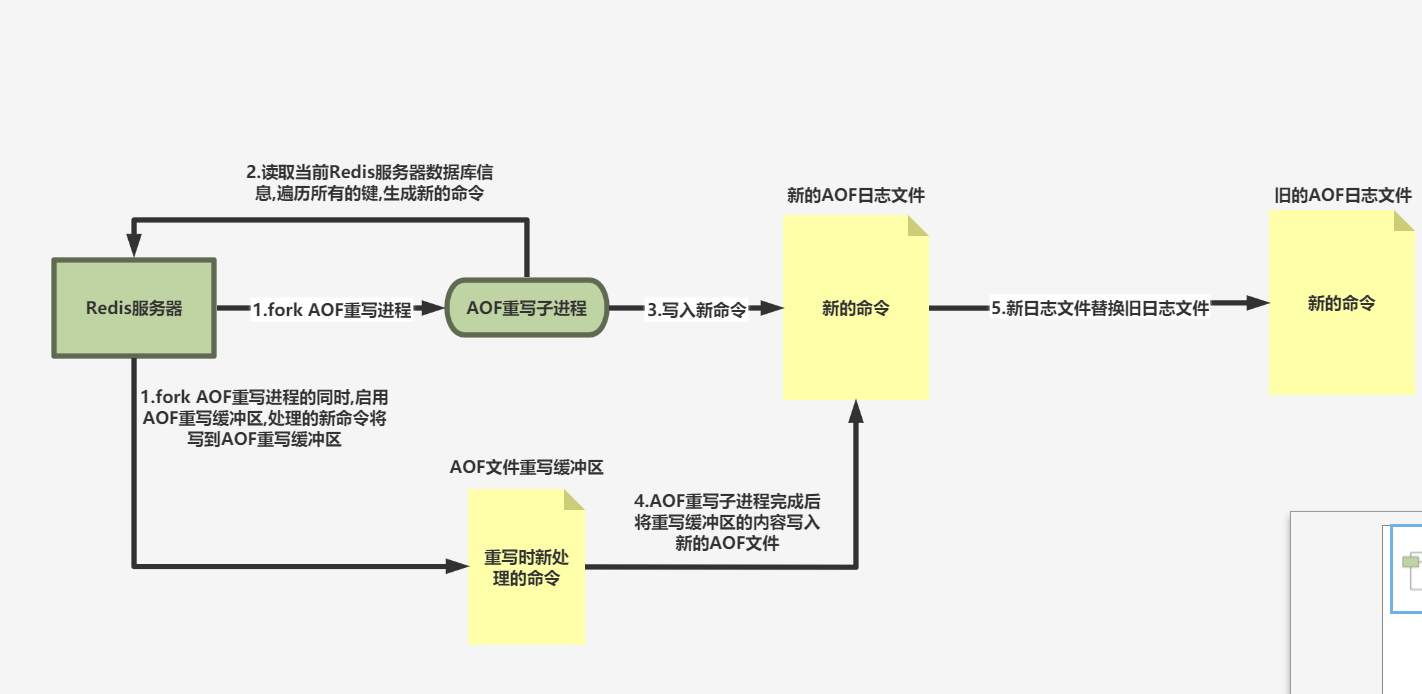
AOF重写的过程
fork 一条子进程 读取当前Redis服务器的数据库信息 遍历所有的键生成对应的新命令,写到新的AOF文件中 重写的时候,Redis服务器主进程依然能接受处理请求,AOF重写的时候会启用AOF文件重写缓冲区,主进程处理请求后会将命令追加到AOF文件缓冲区 当子进程完成AOF文件重写后 会将AOF文件重写缓冲区的内容写到新的AOF文件中 然后再将新的AOF文件覆盖原理的AOF文件
:herb: RDB持久化机制
🍃 RDB持久化流程
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失
🍃 RDB触发方式
- 🍀save : 会阻塞主进程
- 🍀执行 bgsave 命令 : fork一条子进程完成数据快照,不会阻塞主进程
🍃 RDB持久化相关配置
stop-writes-on-bgsave-error 当Redis无法写入磁盘的话,直接关掉Redis的写操作。推荐yes
rdbcompression 压缩文件 如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐yes.
rdbchecksum 检查完整性 在存储快照后,还可以让redis使用CRC64算法来进行数据校验
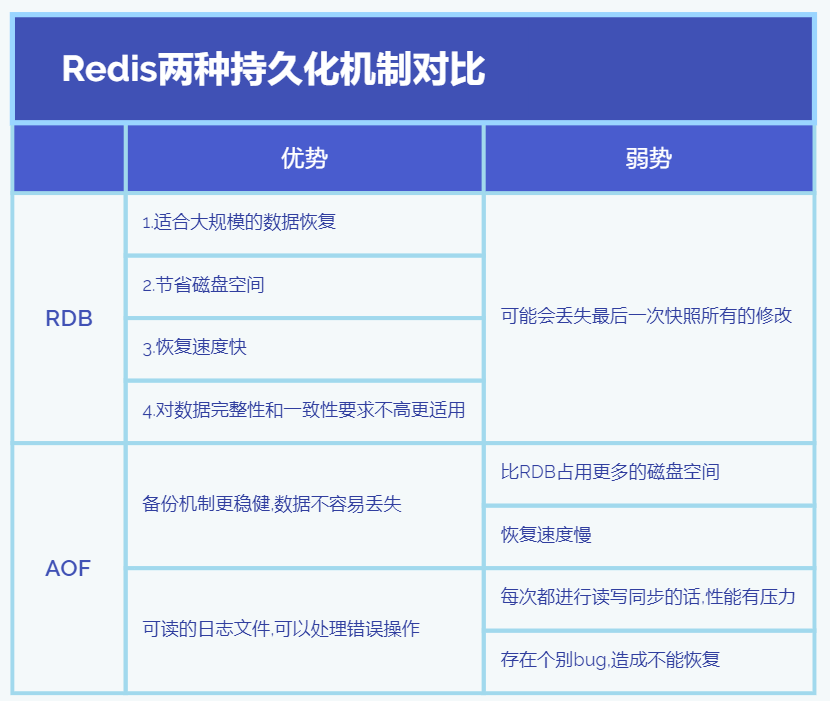
:herb:AOF持久化和RDB持久化对比

 我只想哭只想哭只想哭
我只想哭只想哭只想哭