
HashMap 面试题大全往这看 都明白了 JDK1.8
🍀java全知识点学习笔记 思维导图 面试跳槽必备 码云仓库地址 https://gitee.com/vx202158/vx202158.git 🍀
java框架学习思维导图 实用笔记 思维软件 用的是XMind 以及 MindMaster 如有错误的地方欢迎指出 及时改正 适合温习知识点 微信号 : vx202158
码云仓库地址 https://gitee.com/vx202158/vx202158.git 请点个星星 谢谢
面试第一题 : HashMap为什么要用数组和链表
1.1 hashMap中的数组
1.1.1 table

官方注释翻译:
该表在首次使用时初始化,并根据需要调整大小。分配时,长度始终是 2 的幂。 (我们还在某些操作中允许长度为零,以允许当前不需要的引导机制。
transient Node<K,V>[] table;
1.1.2 transient 关键字

可以看到 HashMap实现了 Serializable 而 transient 关键字的作用是 被修饰的属性不进行序列号
1.2 hashmap中的链表
1.2.1 Node<K,V>[ ]

可以看到 Node 是 HashMap中的一个静态内部类 实现了 Map.Entry<K,V>
HashMap中 的数组存储的元素是 Map.Entry<K,V> 且是一个单项链表(用于解决hash冲突)
第一题 回答
数组的特点 : 查询时间复杂度 O(1) 寻址容器,增删难
链表的特点 : 查询慢,增删快
了解上面的 知识后,来回答这个问题
hashMap对插入的key 进行hash运算,能快速确定应该放在数组的哪一个位置

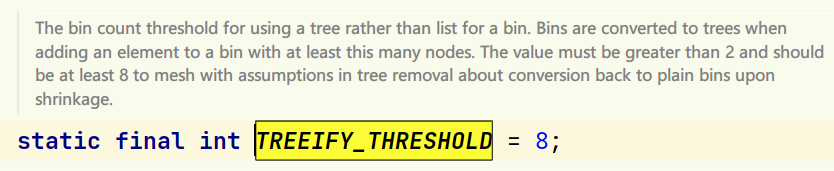
而用链表 是为解决hash冲突 但是用链表每一次都需要遍历链表,速度慢 于是在1.8中,当链表长度大于8,且数组的长度大于等于64时,会转换成红黑树(如果数组长度没有64,不会转换成红黑树,只会扩容) 当 链表长度小于等于 6 时,会退树,成为链表
转换成红黑树相关代码
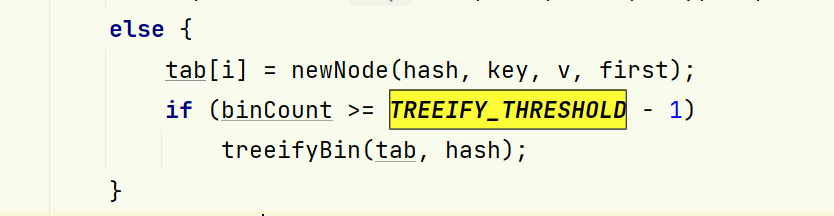
这里注意,为什么是 -1 因为binCount是从0开始计数的 if里面的这句判断代码相当于 binCount +1(新结点) >= TREEIFY_THRESHOLD
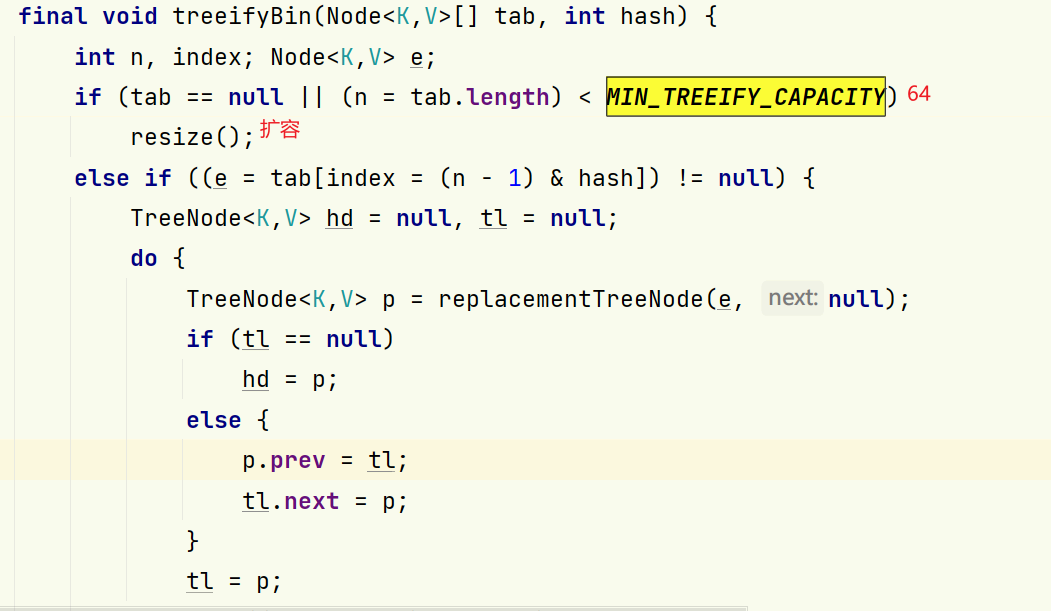

退树转换成链表相关代码


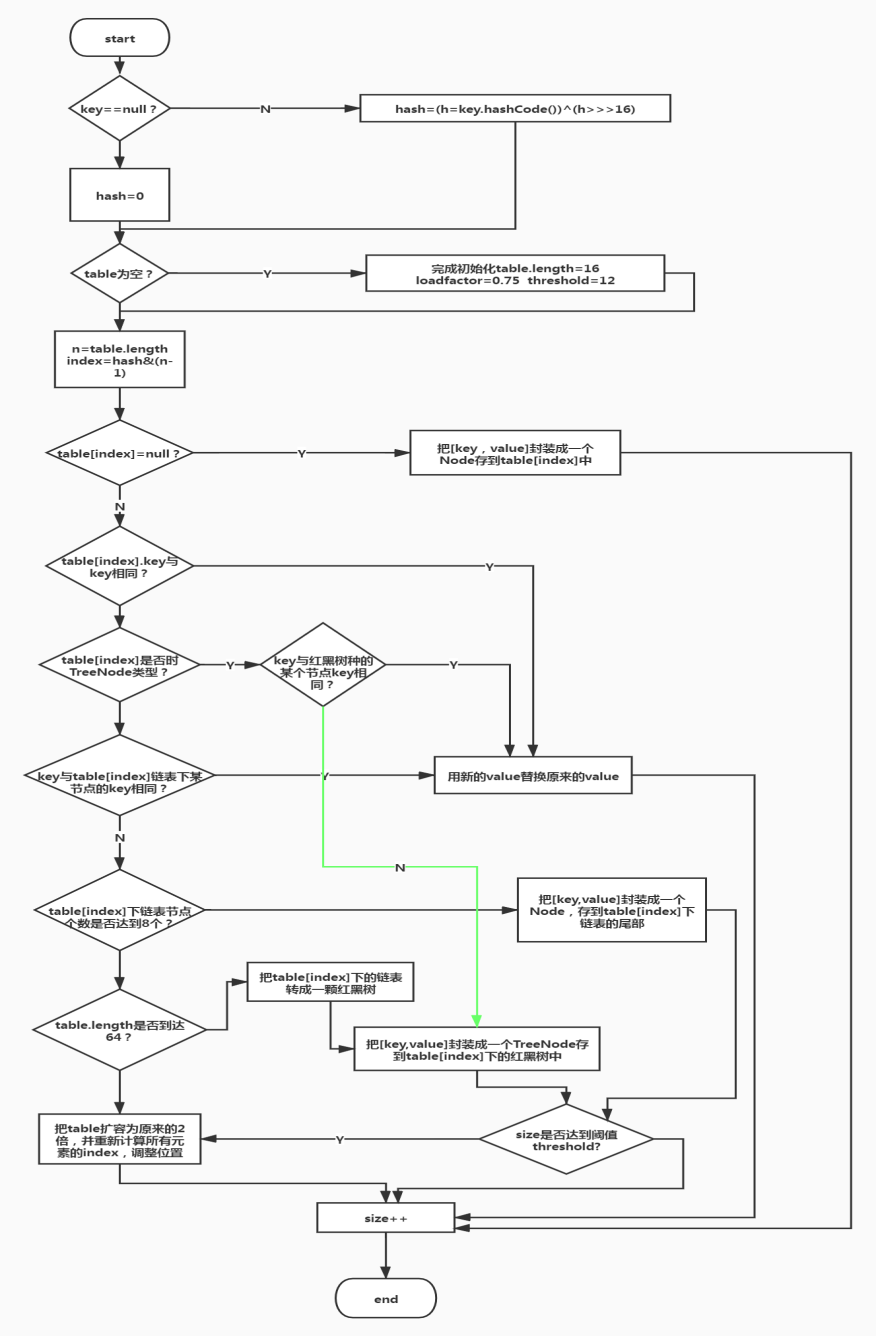
面试第二题 HashMap的put方法大致实现流程
2.1 put方法入口
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} 2.2 putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断数组table是否为null 或者长度是否为空
if ((tab = table) == null || (n = tab.length) == 0)
//如果为空或者为null 初始化(扩容)
n = (tab = resize()).length;
//如果数组table的当前索引位置上的Entry对象为null,也就是没有对象,则直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
//创建一个新的Map.Entry
tab[i] = newNode(hash, key, value, null);
//如果进入else,则说明有hash冲突
else {
Node<K,V> e; K k;
//判断两个元素是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//不相等 判断当前槽是否是红黑树
else if (p instanceof TreeNode)
//放到红黑树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果不是红黑树 循环遍历挂载的链表
for (int binCount = 0; ; ++binCount) {
//遍历链表 一直到最后结点 注意 走了这个循环 e肯定不为空
if ((e = p.next) == null) {
//创建新结点,并且让最后一个结点的next指针指向新插入的结点(尾插法)
p.next = newNode(hash, key, value, null);
//注意 binCount 从0 开始 所有当 binCount 大于等于7时,就需要树化了
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
//跳出循环
break;
}
//如果 key相等 跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//对e进行判断是否为空 如果为空 说明key相等了
if (e != null) { // existing mapping for key
//新值替换旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
//返回旧值
return oldValue;
}
}
++modCount;
// 判断创建创建新结点对象后是否需要扩容 是否达到阈值 负载因子0.75
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 
面试第三题 JDK1.7版本中的HashMap的头插法是如何实现的
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
} /**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
//Entry.下一个结点指向 table[bucketIndex] 永远在链表表头位置
next = n;
key = k;
hash = h;
}面试第四题 HashMap中的数组大小有什么特点
一定是2的n次幂
相关代码
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}面试第五题 HashMap中的数组大小为什么是2的幂次方
装逼解释: 因为2的幂次方减掉1后, 二进制的值的 低位都是1,这样就保证了和Hash值 相与【&】后结果 低位都是被保留下来的 这样就可以避免不同的Hash值传入进来 被分配到 同一个卡槽位置 去存储。
直接解释:提高效率, 降低哈希碰撞率
面试第六 题 HashMap中是如何计算数组下标的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
面试第七题 1.7中HashMap中是如何扩容的
final Node<K,V>[] resize() {
....
}达到阈值后,扩容为当前数组大小的^2 然后进行hash表数据转移
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
//新的链表长度
int newCapacity = newTable.length;
//循环遍历数组,获取每一个Map.Entry对象
for (Entry<K,V> e : table) {
//遍历链表
while(null != e) {
Entry<K,V> next = e.next;
//判断是否需要重新计算hash值
if (rehash) {
//判断当前的key是否为null,也就是table的第一个元素 如果是 赋值为0
//注意 hashmap的key和value都是可以null的
//二次hash 计算新的hash值方法
e.hash = null == e.key ? 0 : hash(e.key);
}
//根据新的hash值,重新分配位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
面试第八题 1.7中HashMap在扩容时为什么是线程不安全的
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
//新的链表长度
int newCapacity = newTable.length;
//循环遍历数组,获取每一个Map.Entry对象
for (Entry<K,V> e : table) {
//遍历链表
while(null != e) {
Entry<K,V> next = e.next;
//判断是否需要重新计算hash值
if (rehash) {
//判断当前的key是否为null,也就是table的第一个元素 如果是 赋值为0
//注意 hashmap的key和value都是可以null的
//二次hash 计算新的hash值方法
e.hash = null == e.key ? 0 : hash(e.key);
}
//根据新的hash值,重新分配位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
关键代码
for (Entry<K,V> e : table) {
//遍历链表
while(null != e) {
Entry<K,V> next = e.next;
//判断是否需要重新计算hash值
if (rehash) {
//判断当前的key是否为null,也就是table的第一个元素 如果是 赋值为0
//注意 hashmap的key和value都是可以null的
//二次hash 计算新的hash值方法
e.hash = null == e.key ? 0 : hash(e.key);
}
//根据新的hash值,重新分配位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}因为jdk 1.7 中hashMap采用的是头插法 ,在扩容的时候,需要完成元素转移,元素转移后,链表就颠倒过来了
比如 table某个下标的链表元素 为 a -> b -> c -> null 在完成元素转移后 变成 c->b ->a - null
如果多线程环境下,线程1完成了元素转移,而线程2才进入 此时将产生 结点的next指针互相应用 造成死循环
相关视频 大厂面试必问的HashMap扩容死循环问题源码分析问题,20分钟讲清楚!_哔哩哔哩_bilibili
面试第九题 1.7中HashMap的rehash是怎么实现的
for (Entry<K,V> e : table) {
//遍历链表
while(null != e) {
Entry<K,V> next = e.next;
//判断是否需要重新计算hash值
if (rehash) {
//判断当前的key是否为null,也就是table的第一个元素 如果是 赋值为0
//注意 hashmap的key和value都是可以null的
//二次hash 计算新的hash值方法
e.hash = null == e.key ? 0 : hash(e.key);
}
//根据新的hash值,重新分配位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}从头到尾,二次函数,重新分配位置
面试第十题 HashMap的modCount是什么意思
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
翻译
此 HashMap 已被结构修改的次数 结构修改是指更改 HashMap 中的映射数量或以其他方式修改其内部结构(例如,重新散列)的那些。该字段用于使 HashMap 的 Collection-views 上的迭代器快速失败。 (请参阅 ConcurrentModificationException)。瞬态 int modCount;
modCount 记录修改的次数 包括 put,add,remove
面试第十一题 HashMap的为什么会出现ConcurrentModificationException
相关代码
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}modCount 记录了修改次数
可以看到,首先将modCount 的值赋值给了一个局部变量 mc
在遍历table的过程中,如果对hashMap进行了 修改操作,那么 ++modCount
此时 modCount和mc不相等 就会抛出 ConcurrentModificationException 异常
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
//可以看到,在此处 ++modCount
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}#java求职##Java##MySQL##Linux##学习路径##校招##社招#



