
为了庆祝EDG夺冠,学学MySQL主从同步吧
大家好,我是亚索!

“八年了,有多少场比赛是不敢拿大龙而输掉的!” 恭喜EDG八年磨一冠,在今天凌晨一点左右拿下LOL全球总决赛冠军。
实在惭愧,现在还在学校,实验室任务加上生活中各种事包括娱乐(😅),导致断更很久,这一点亚索也一日三省,如何抓紧时间,多学习,多写代码,多写分享,少手游(最近可是手游排位持续上头ing,亚索在召唤师峡谷疯狂坑人🤔)。

说起娱乐竞赛,亚索感觉到不管是娱乐还是生活学习,都会遇到各种所谓的挫折困难,保持一个良好积极乐观的心态,着重于问题的原因和根本,最终都会得到一个比较好的结果,与大家共勉。
EDG夺冠,可以像过大年一样庆祝。
凌晨一点亚索就听到有童鞋在宿舍楼大声呼喊,在网上也有看到很多人实现flag,倒立洗头,表白求爱,更夸张的还有,大街上裸奔,跳l跳河...这...

亚索觉得完全就没必要了吧,还请大家时刻保持理智和清醒,不要参与一些无意义毁三观的庆祝活动叭。
正题
闲聊stop,今天主要给大家分享一下,亚索之前学习到的MySQL分库主从同步延迟问题的解决方法。
这也是后端Java面试官爱问知识之一,知识介绍均来自互联网搜集资料以及课本笔记,如有重复涉及版权问题,纯属偶然,还请私信纠正一下哈。
MySQL主从分库架构
互联网大项目都是“读多写少”的场景,如果过多“读数据”的请求落在一台数据库上,将无疑给数据库和整个系统带来不小的压力和瓶颈,所以业界普遍采用“一主多从,写主读从”的架构来提升数据库相关层面的性能,如下图所示:
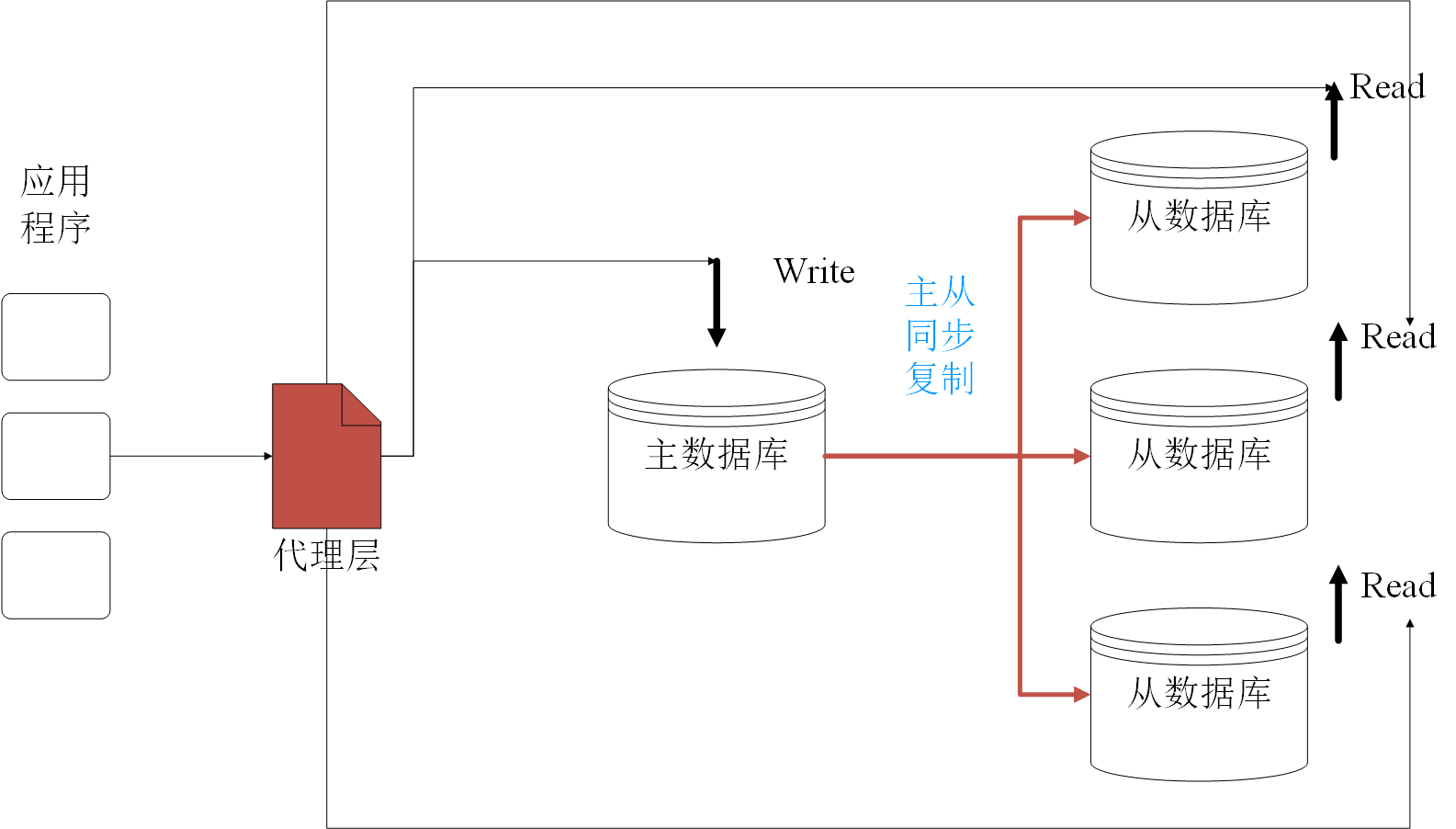
读写分离具体地有代理方式、组件方式,一般首先都要做到三步:
1、部署多台数据库,选择一台作为主库,其他作为从库;
2、确保主从数据库的一致性,数据实时同步,也就是主从复制;
3、确保系统将写请求交给主数据库处理,读请求交给从数据库处理。
- 代理方式就是在应用和数据库中间加一个代理层,所有数据请求由代理层负责处理,分离读写请求,路由到对应的数据库中。提供功能的中间件有:MySQL Router、Maxscale、MyCat、Atlas
- 组件方式目前互联网使用较多,推荐使用。直接在项目maven引入jar包即可使用。关于实现读写分离可以参见官方网站 https://shardingsphere.apache.org/document/legacy/3.x/document/cn/manual/sharding-jdbc/usage/read-write-splitting/
读写分离的实现对于提升数据库的并发非常有效,对主库更新写入的数据,为了保证读取的一致性,需要及时把数据更新到从库当中去,这就是主从复制,原理以及示意图如下:
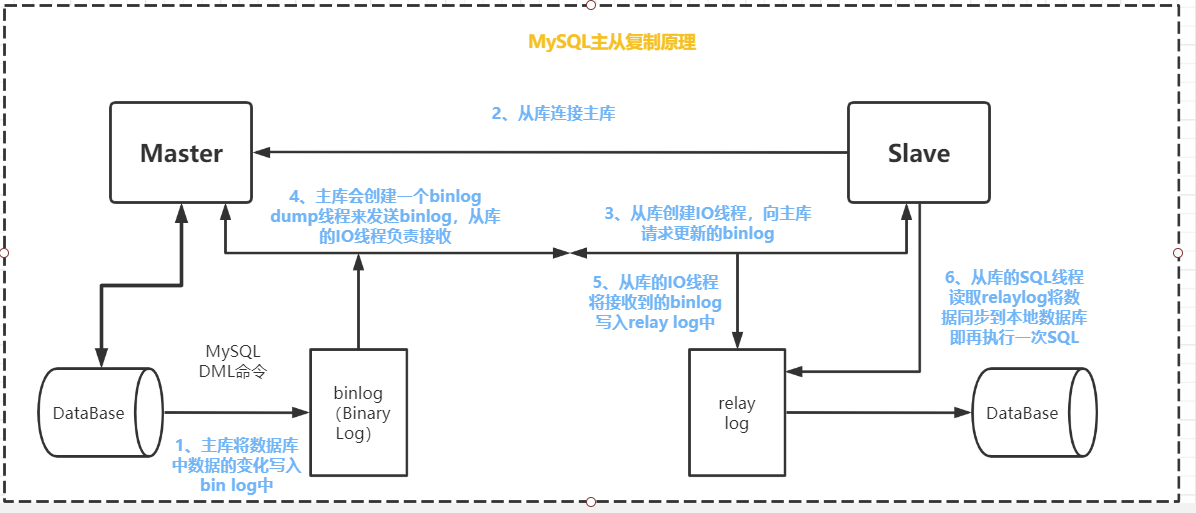
怕大家看不清图,MySQL主从复制步骤亚索再写一遍:
- 主库更新数据后,将数据库中变化的数据写入bin log日志中,写入的是DML命令语句(Data Manipulation Language)
- 从库连接主库
- 从库会创建一个IO线程,向主库请求更新的bin log
- 主库会创建一个bin log线程,来向从库发送bin log,从库的IO线程则负责接收
- 从库的IO线程将接收到的bin log写入relay log中,从库的SQL线程读取relay log将数据同步写入本地数据库(即从库),即再执行一次DML类型的SQL语句。
主从同步延迟以及解决办法
万物有利有弊,主从分库,读写分离,会带来 :
主库和从库的数据存在延迟,比如写完主库之后,主库的数据同步到从库是需要时间的,这个时间之内主库和从库的数据不一致,读取从库的数据可能就是错误的或者说旧数据。
方案一 延迟读取
简而言之就是,等主从同步延迟时间过了以后再去读取数据,只适用于数据敏感场景:
可以设计业务流程为,写请求完成之后,避免立即进行请求操作:比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
方案二 强制读主库
在主从同步延迟时间内,从库数据是过期的,此时将必须读取最新数据的请求路由给主库处理,可以采用这种方案,通过其HintManager分片键值管理器可以实现:
HintManager hm = HintManager.getInstance();
hm.setMasterRouterOnly();
方案三 半同步复制
等主从同步完成之后,主库上的写请求再返回,这就是“半同步复制”:
- 系统先对主库Master进行一个写操作
- 等主从同步完成之后,写主库的请求才返回
- 读从库,此时读到的是最新的数据
该方案较为简单,但主库的写请求返回时间会延长,吞吐量会降低。
方案四 数据库中间件
在应用程序服务层与数据库之间加一个中间件,所有数据请求均走中间件:
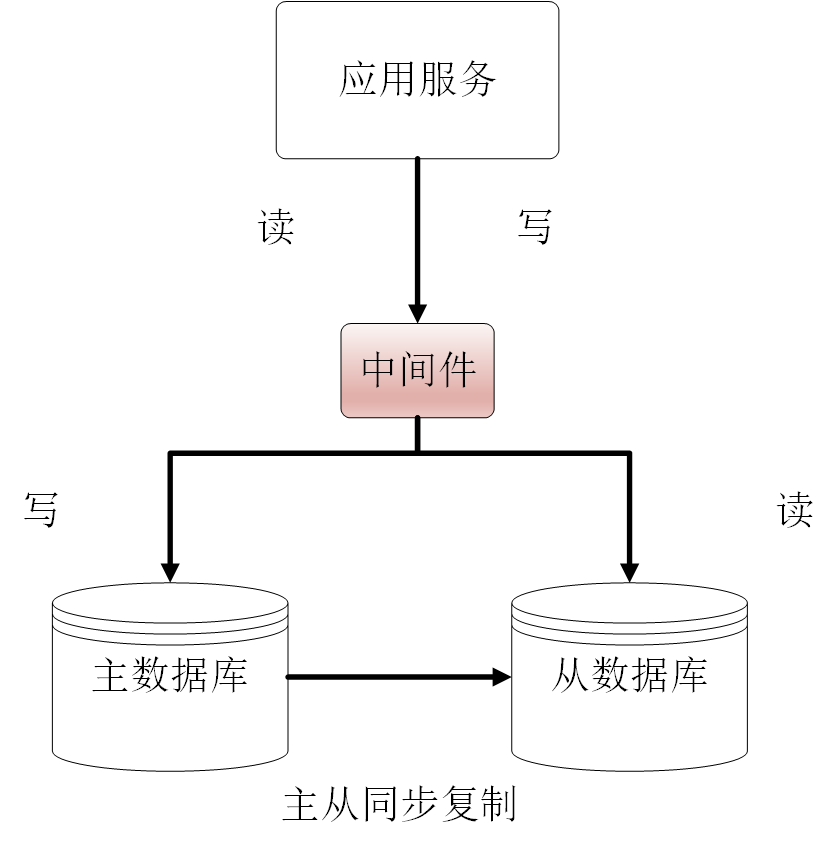
- 所有的读写都走数据库中间件,正常情况下读请求路由到从库处理,写请求路由到主库处理
- 记录所有路由给主库的key,在主从同步延迟时间内(经验时间是500ms),如果有相关key的读请求访问中间件,就把这个key的读请求交给主库处理,因为此时从库可能还是旧的错误数据。
- 在主从同步延迟时间过后,保持正常,所有读请求均路由到从库处理。
该方案基本能保证读取数据一致性,但数据库中间件的成本较高。
方案五 缓存记录写key法
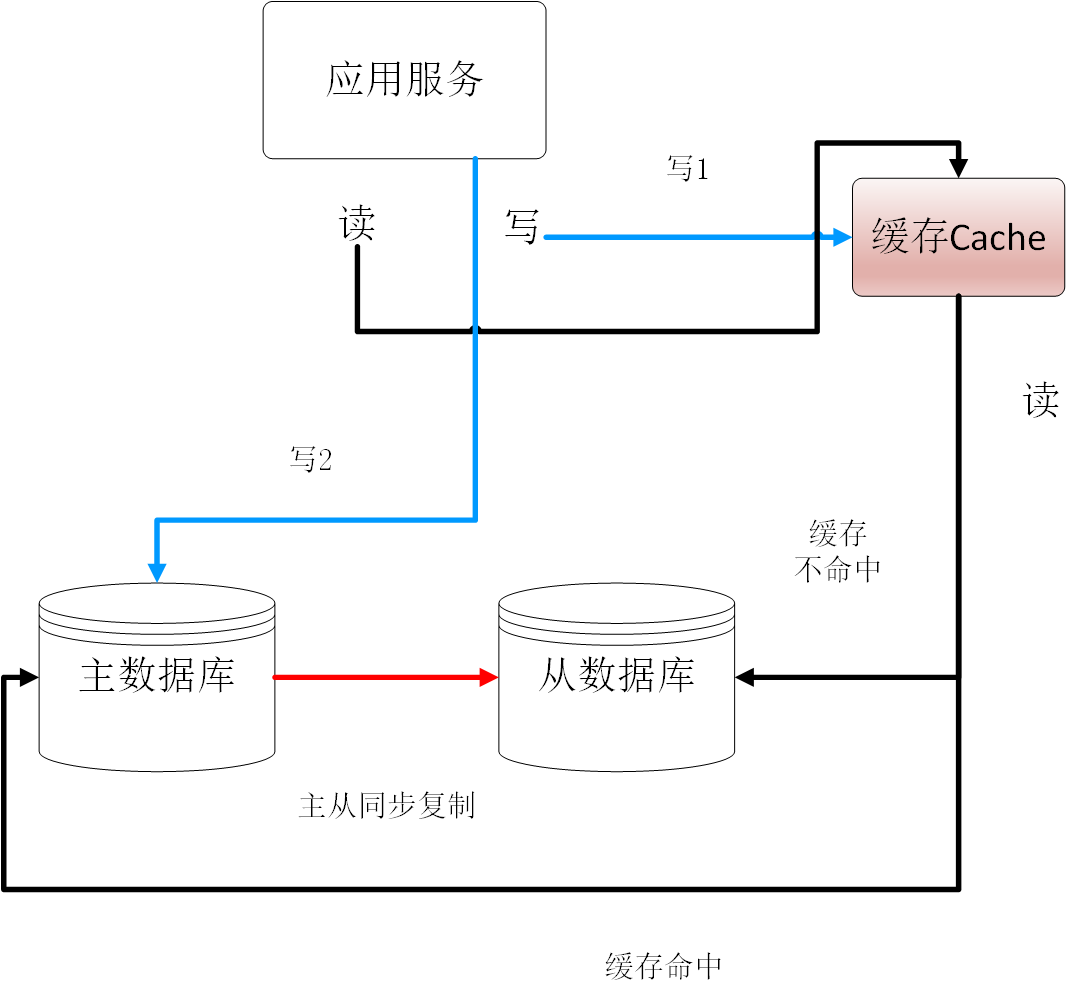
- 用缓存代替中间件,如果某个key要进行写操作,记录先写在缓存Cache里面,根据经验设置一个主从同步时间
- 写主库,执行写操作
- 读请求发生,先到缓存里查看是否有相关key的记录
- 如果有,则为缓存命中,需要将读请求路由到主库处理
- 如果没有命中,说明该key相关数据近期没有发生改变,继续将请求交给从库处理,继续读写分离。
小结
本文主要介绍了一下MySQL主从分库,读写分离,实现主从同步复制的步骤原理,以及相关问题的处理解决办法,有不足之处还请指出,在亚索日后的学习当中,如果有更好的方案和技术补充,会继续更新。
好了今天就说到这,我是亚索,关注我,大家一起学Java吧!


