BI技巧丨粒度切换

白茶在很久之前,写过关于笛卡尔积的两个函数。
GENERATE函数与CROSSJOIN函数。
传送门:《笛卡尔积》
那么这两个函数之间具体的区别是什么呢?在实际用途中的区别呢?
本期白茶来解释一下二者之间的核心点:上下文传递问题。

在微软的官方介绍中并未提及两个函数的区别。
但是从语法上看GENERATE参数只能是两个,CROSSJOIN参数可以是多个。
但是实际使用上,二者还有一个核心的关键点,就是GENERATE函数可以传递第一参数的上下文,而CROSSJOIN函数不能传递第一参数上下文。
白茶将通过一组案例数据进行说明:
这是白茶随机模拟的数据,将其导入到PowerBI中,建立日期表以及模型关系如下:
编写如下度量值:
GENRATE =
GENERATE (
{ "当月", "当季", "当年" },
SUMMARIZE (
'销售明细',
'销售明细'[商品名称],
"INDEX", SWITCH ( [Value], "当月", 1, "当季", 2, "当年", 3 ),
"数据",
SWITCH (
[Value],
"当月", TOTALMTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] ),
"当季", TOTALQTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] ),
"当年", TOTALYTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] )
)
)
)
结果如下:
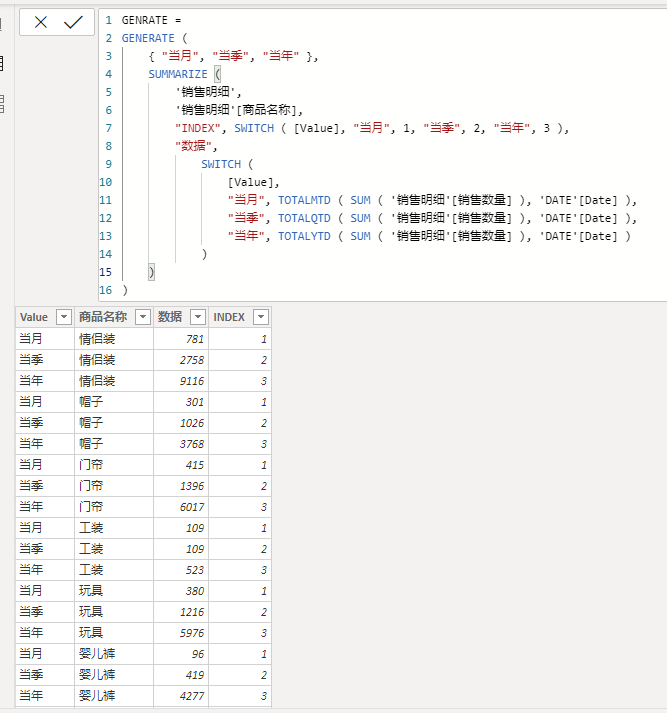
这段代码是什么意思呢?
1.首先是利用输入模式,直接输入了三个时间粒度的标识字段作为第一参数;
2.然后利用SUMMARIZE函数生成一个表,添加了“数据列”和“索引列”;
3.SUMMARIZE函数利用GENERATE函数传递第一参数上下文的功能,根据条件判定进行计算。
这样的话就对“商品名称”这一列进行了不同时间粒度的汇总。
动态效果如下:
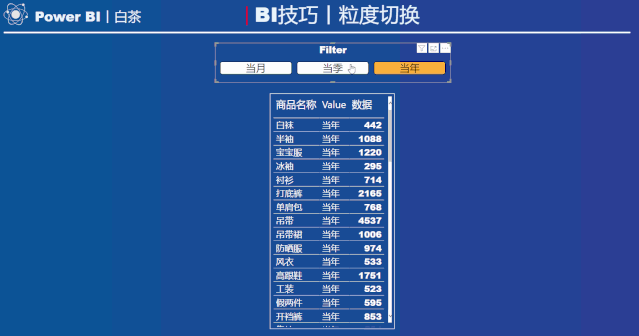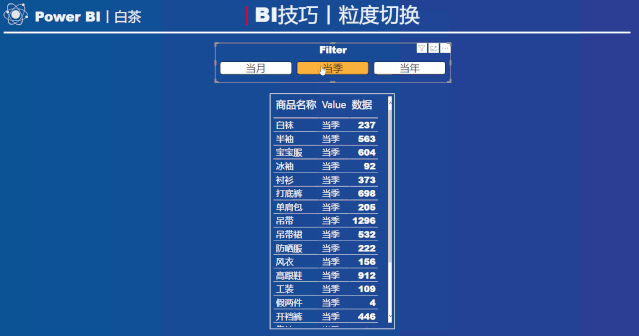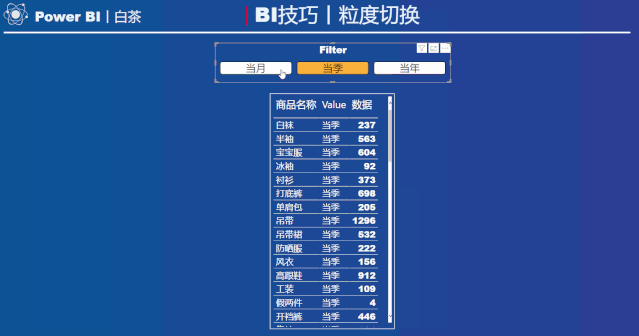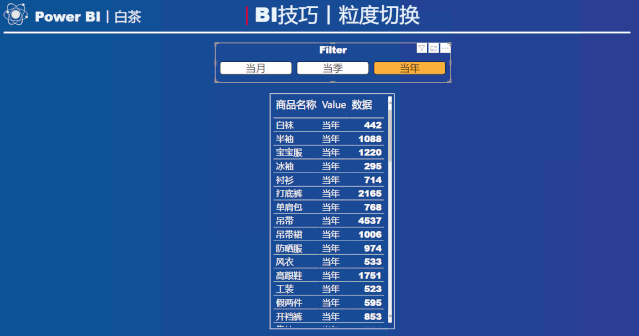
根据切片器的选择,可以在表中呈现不同时间粒度汇总的结果。
那么别忘了,还有CROSSJOIN函数呢。
输入如下代码:
CROSSJOIN =
CROSSJOIN (
{ "当月", "当季", "当年" },
SUMMARIZE (
'销售明细',
'销售明细'[商品名称],
"INDEX", SWITCH ( [Value], "当月", 1, "当季", 2, "当年", 3 ),
"数据",
SWITCH (
[Value],
"当月", TOTALMTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] ),
"当季", TOTALQTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] ),
"当年", TOTALYTD ( SUM ( '销售明细'[销售数量] ), 'DATE'[Date] )
)
)
)
与上面的代码对比,二者除了使用函数区别外,没有任何区别。
结果如下:
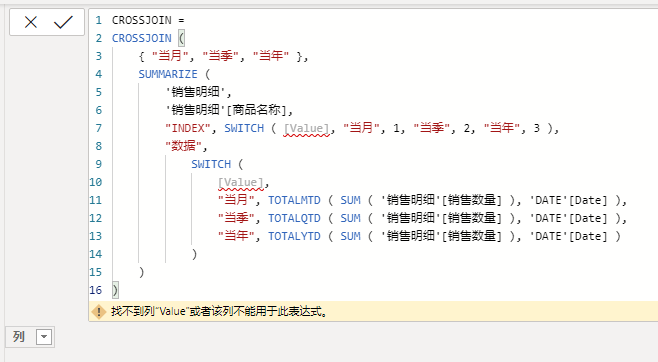
结果无法得出,白茶第一次遇到这个问题的时候,思考了很久,感觉即在意料之外,也在情理之中。
首先是GENERATE这个函数本身只有两个参数,那么进行上下文传递的时候,可以说已经被划定范围了,这样的话虽然代码计算的速度慢,但是会有结果。
而CROSSJOIN函数可以有多个参数,如果内部允许上下文传递的话,从一参,到二参,到三参等等,会导致迭代的速度变得巨卡无比,甚至无法得出结果。
可以说从性能的角度考虑,微软在设计CROSSJOIN函数的时候,就已经考虑到这个问题了,因此其不具备内部上下文传递的功能。

小伙伴们❤GET了么?
白茶会不定期的分享一些函数卡片
(文件在知识星球[PowerBI丨需求圈])

这里是白茶,一个PowerBI的初学者。
数据分析进阶之路,带你深入了解可视化技巧。

 查看17道真题和解析
查看17道真题和解析