
速学 - 1h掌握正则表达式
正则表达式-浅尝辄止
用途
- 字符串算法题简单解题
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"+100","5e2","-123","3.1416"和"-1E-16"都表示数值。 但是"12e","1a3.14","1.2.3","+-5"和"12e+4.3"都不是。
function isNumeric( str ) {
// write code here
const len = str.length;
if(len===1){
return !isNaN(str)
}
var reg = /^[+-]?\d*(?:[.]\d+)?(?:\d+e[+-]?\d+)?$/gi;
return reg.test(str);
} - 项目应用
密码强度验证
现在请你编写正则表达式进行密码强度的验证,规则如下:
- 至少一个大写字母
- 至少一个小写字母
- 至少一个数字
- 至少
8个字符左边为需要你的正则需要匹配的,右边的字符串是你的正则不需要匹配的。
let regExp = (?=.*[a-z])(?=.*[A-Z])(?=.*\d).{8,} | 需要匹配的 | 不能匹配的 |
|---|---|
| Admin123456 | qwe |
| pZUJLUpTL2 | 8848 |
| Tnut2eWPN1 | 123456 |
格式化时间
let time = '2019-7-24 12:6:23';
//=>改变格式
//"2019年07月24日 12日06分23秒"
//"2019年07月24日"
//"07/24 12:06"
//基于正则 let addZero=val=>val.length<2?'0'+val:val; let ary=time.split(/(?: |-|:)/g); time=ary[0]+'年'+addZero(ary[1])+'月'+addZero(ary[2])+'日';
获取一个URL传递参数
实现一个方法queryURLParameter
//正则表达式
let url = 'http://www.zhufengpeixun.cn/index.html?1x=1&name=zhufeng&teacher=aaa#box';
function queryURLParams(url) {
//获取每一部分信息
let result = {},
reg1 = /([^?#=&]+)=([^?#=&]+)/g,
reg2 = /#([^?#=&]+)/g;
url.replace(reg1,(n,x,y)=>result[x]=y);
url.replace(reg2,(n,x)=>result['HASH']=x);
return result;
}
let paramsObj = queryURLParams(url);
console.log(paramsObj); 等等
一个好的正则表达式可以省去几十上百行代码
基础
1、匹配
正则表达式写在//之间,使用正则表达式来匹配文本
//后面会有修饰符如//gims
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
|---|---|---|
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
2、匹配
字符组([])
- 允许匹配一组可能出现的字符,如[./-+Rp]
- [0-9]、[a-z]、[A-Z]
*转义\ *
[0-9\-]
^取反
- [^0-9]
快捷匹配数字和字母
快捷方式 描述 \w 与任意单词字符匹配,任意单词字符表示 [A-Z]、[a-z]、[0-9]、_\d 与任意数字匹配 \W 不与任意单词字符匹配,任意单词字符表示 [A-Z]、[a-z]、[0-9]、_\D 不与任意数字匹配
匹配空白
\s快捷方式可以匹配空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。- \S表示快捷取反
单词边界
\b匹配的是单词的边界,例如,
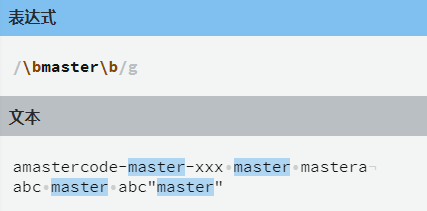
开始和结束
^指定的是一个字符串的开始,$指定的是一个字符串的结束
任意字符
.字符代表匹配任何单个字符,它只能出现在方括号以外。值得注意的是:
.字符只有一个不能匹配的字符,也就是换行符(\n),不过要让.字符与换行符匹配也是可以的,以后会讨论。
可选字符
?符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现零次或一次
重复
在一个字符组后加上
{N}就可以表示在它之前的字符组出现N次。{M,N},M是下界而N是上界。有时候我们可能遇到字符组的重复次数没有边界,例如:
闭区间不写即可表示匹配一个或无数个。
速写:
+等价于{1,},*等价于{0,}。

进阶
分组
- 分组有一个非常重要的功能——
捕获数据

- 分组的回溯引用

发现 \1 表示的就是第一个分组,如果有第二个分组,之后用\2表示,在这里第一个分组匹配的是 font 所以\1 就代表font
或者条件
分组的同时还可以使用 或者(
or)条件

非捕获分组
(?:表达式),从而不捕获数据,还能使用分组的功能案例:将其中的
年月日全都提取出来。20200102
2020-01-02
2020-1-2
2020.01.02
2020 01 02
2020 1 2
2020/01/02(\d{4})[-./\s]?(\d{1,2})[-./\s]?(\d{1,2})
断言
- 正向先行断言:
(?=表达式),指在某个位置向右看,表示所在位置右侧必须能匹配表达式

- 反向先行断言
(?!表达式)的作用是保证右边不能出现某字符。

- 正向后行断言:
(?<=表达式),指在某个位置向左看,表示所在位置左侧必须能匹配表达式

- 反向后行断言:
(?<!表达式),指在某个位置向左看,表示所在位置左侧不能匹配表达式

综上:正向表示有,反向表示无。先行往右看,后行往左看
推荐学习
快速入门推荐:https://www.codejiaonang.com/#/course/regex_chapter1/0/0
详细内容推荐网道JS:https://wangdoc.com/javascript/stdlib/regexp.html
测试正则网址:https://regexr-cn.com/
JS中的正则表达式
var reg = /xyz/g;
var reg2 = new RegExp('xyz',g); 实例属性
RegExp.prototype.ignoreCase:返回一个布尔值,表示是否设置了i修饰符。RegExp.prototype.global:返回一个布尔值,表示是否设置了g修饰符。RegExp.prototype.multiline:返回一个布尔值,表示是否设置了m修饰符。RegExp.prototype.flags:返回一个字符串,包含了已经设置的所有修饰符,按字母排序。
上面四个属性都是只读的。
var r = /abc/igm; r.ignoreCase // true r.global // true r.multiline // true r.flags // 'gim'
另一类是与修饰符无关的属性,主要是下面两个。
RegExp.prototype.lastIndex:返回一个整数,表示下一次开始搜索的位置。该属性可读写,但是只在进行连续搜索时有意义,详细介绍请看后文。RegExp.prototype.source:返回正则表达式的字符串形式(不包括反斜杠),该属性只读。
var r = /abc/igm; r.lastIndex // 0 r.source // "abc"
实例方法
RegExp.prototype.test()
正则实例对象的test方法返回一个布尔值,表示当前模式是否能匹配参数字符串。
/cat/.test('cats and dogs') // true 上面代码验证参数字符串之中是否包含cat,结果返回true。
如果正则表达式带有g修饰符,则每一次test方法都从上一次结束的位置开始向后匹配。
var r = /x/g; var s = '_x_x'; r.lastIndex // 0 r.test(s) // true r.lastIndex // 2 r.test(s) // true r.lastIndex // 4 r.test(s) // false
上面代码的正则表达式使用了g修饰符,表示是全局搜索,会有多个结果。接着,三次使用test方法,每一次开始搜索的位置都是上一次匹配的后一个位置。
带有g修饰符时,可以通过正则对象的lastIndex属性指定开始搜索的位置。
var r = /x/g; var s = '_x_x'; r.lastIndex = 4; r.test(s) // false r.lastIndex // 0 r.test(s)
上面代码指定从字符串的第五个位置开始搜索,这个位置为空,所以返回false。同时,lastIndex属性重置为0,所以第二次执行r.test(s)会返回true。
注意,带有g修饰符时,正则表达式内部会记住上一次的lastIndex属性,这时不应该更换所要匹配的字符串,否则会有一些难以察觉的错误。
var r = /bb/g;
r.test('bb') // true
r.test('-bb-') // false 上面代码中,由于正则表达式r是从上一次的lastIndex位置开始匹配,导致第二次执行test方法时出现预期以外的结果。
lastIndex属性只对同一个正则表达式有效,所以下面这样写是错误的。
var count = 0;
while (/a/g.test('babaa')) count++; 上面代码会导致无限循环,因为while循环的每次匹配条件都是一个新的正则表达式,导致lastIndex属性总是等于0。
如果正则模式是一个空字符串,则匹配所有字符串。
new RegExp('').test('abc')
// true RegExp.prototype.exec()
正则实例对象的exec()方法,用来返回匹配结果。如果发现匹配,就返回一个数组,成员是匹配成功的子字符串,否则返回null。
var s = '_x_x'; var r1 = /x/; var r2 = /y/; r1.exec(s) // ["x"] r2.exec(s) // null
上面代码中,正则对象r1匹配成功,返回一个数组,成员是匹配结果;正则对象r2匹配失败,返回null。
如果正则表示式包含圆括号(即含有“组匹配”),则返回的数组会包括多个成员。第一个成员是整个匹配成功的结果,后面的成员就是圆括号对应的匹配成功的组。也就是说,第二个成员对应第一个括号,第三个成员对应第二个括号,以此类推。整个数组的length属性等于组匹配的数量再加1。
var s = '_x_x'; var r = /_(x)/; r.exec(s) // ["_x", "x"]
上面代码的exec()方法,返回一个数组。第一个成员是整个匹配的结果,第二个成员是圆括号匹配的结果。
exec()方法的返回数组还包含以下两个属性:
input:整个原字符串。index:模式匹配成功的开始位置(从0开始计数)。
var r = /a(b+)a/;
var arr = r.exec('_abbba_aba_');
arr // ["abbba", "bbb"]
arr.index // 1
arr.input // "_abbba_aba_" 上面代码中的index属性等于1,是因为从原字符串的第二个位置开始匹配成功。
如果正则表达式加上g修饰符,则可以使用多次exec()方法,下一次搜索的位置从上一次匹配成功结束的位置开始。
var reg = /a/g; var str = 'abc_abc_abc' var r1 = reg.exec(str); r1 // ["a"] r1.index // 0 reg.lastIndex // 1 var r2 = reg.exec(str); r2 // ["a"] r2.index // 4 reg.lastIndex // 5 var r3 = reg.exec(str); r3 // ["a"] r3.index // 8 reg.lastIndex // 9 var r4 = reg.exec(str); r4 // null reg.lastIndex // 0
上面代码连续用了四次exec()方法,前三次都是从上一次匹配结束的位置向后匹配。当第三次匹配结束以后,整个字符串已经到达尾部,匹配结果返回null,正则实例对象的lastIndex属性也重置为0,意味着第四次匹配将从头开始。
利用g修饰符允许多次匹配的特点,可以用一个循环完成全部匹配。
var reg = /a/g;
var str = 'abc_abc_abc'
while(true) {
var match = reg.exec(str);
if (!match) break;
console.log('#' + match.index + ':' + match[0]);
}
// #0:a
// #4:a
// #8:a 上面代码中,只要exec()方法不返回null,就会一直循环下去,每次输出匹配的位置和匹配的文本。
正则实例对象的lastIndex属性不仅可读,还可写。设置了g修饰符的时候,只要手动设置了lastIndex的值,就会从指定位置开始匹配。
字符串的实例方法(match \ search \ repalce \ split)
字符串的实例方法之中,有4种与正则表达式有关。
String.prototype.match():返回一个数组,成员是所有匹配的子字符串。var s = 'abba'; var r = /a/g; s.match(r) // ["a", "a"]
String.prototype.search():按照给定的正则表达式进行搜索,返回一个整数,表示匹配开始的位置。'_x_x'.search(/x/) // 1
String.prototype.replace():按照给定的正则表达式进行替换,返回替换后的字符串。'aaa'.replace('a', 'b') // "baa" 'aaa'.replace(/a/, 'b') // "baa" 'aaa'.replace(/a/g, 'b') // "bbb"
String.prototype.split():按照给定规则进行字符串分割,返回一个数组,包含分割后的各个成员。// 非正则分隔 'a, b,c, d'.split(',') // [ 'a', ' b', 'c', ' d' ] // 正则分隔,去除多余的空格 'a, b,c, d'.split(/, */) // [ 'a', 'b', 'c', 'd' ] // 指定返回数组的最大成员 'a, b,c, d'.split(/, */, 2) [ 'a', 'b' ]上面代码使用正则表达式,去除了子字符串的逗号后面的空格。
// 例一 'aaa*a*'.split(/a*/) // [ '', '*', '*' ] // 例二 'aaa**a*'.split(/a*/) // ["", "*", "*", "*"]
上面代码的分割规则是0次或多次的
a,由于正则默认是贪婪匹配,所以例一的第一个分隔符是aaa,第二个分割符是a,将字符串分成三个部分,包含开始处的空字符串。例二的第一个分隔符是aaa,第二个分隔符是0个a(即空字符),第三个分隔符是a,所以将字符串分成四个部分。如果正则表达式带有括号,则括号匹配的部分也会作为数组成员返回。
'aaa*a*'.split(/(a*)/) // [ '', 'aaa', '*', 'a', '*' ]
上面代码的正则表达式使用了括号,第一个组匹配是
aaa,第二个组匹配是a,它们都作为数组成员返回。





