【缓存】缓存穿透和缓存雪崩
版权声明:本文为CSDN博主「每天进步一点点yes」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。

二、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
1.布隆过滤
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃。还有最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
补充:
Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。添加时增加计数器,删除时减少计数器。
2. 缓存空对象. 将 null 变成一个值.
也可以采用一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
三、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力

说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
四、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
1. 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
2.数据预热
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
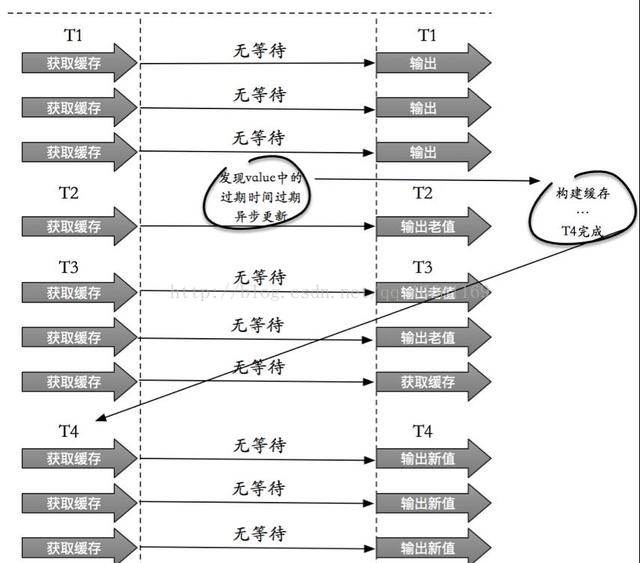
4.缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。