
Multiway Attention Networks for Modeling Sentence Pairs阅读笔记
文章目录
概述
对句子对进行建模应用非常广泛, 常见的任务有paraphrase identification, natural language Inference, sentence similarity, answer sentence selection等等.
目前的方法总结起来可以分为两种结构:
- 对两句话分别单独编码, 最后基于提取的特征输出结果. 这种做法最大的缺陷是在编码阶段没有任何交互, 损失了很多信息.
- 为了解决第一种结构存在的缺陷, 目前流行的做法是利用注意力机制, 增强句子对之间的交互. 这种模型结构基于matching-aggregation结构, 先利用注意力机制, 提取句子对中词与词之间的匹配信息, 再对匹配信息进行聚合操作, 用来衡量两句话的关系.
这篇文章的网络结构依然采用目前流行的matching-aggregation结构, 创新点在于使用了多种attention方程来进行匹配.
模型
包含五部分:
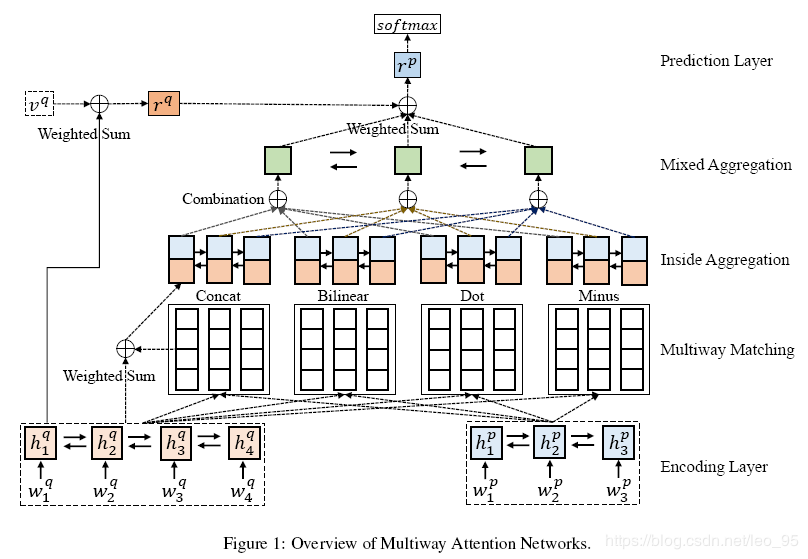
- Encoding Layer
- Multiway Matching
- Inside Aggregation
- Mixed Aggregation
- Prediction Layer
1. Encoding Layer
先将每个词表示为word embedding和contextual embedding(Elmo), 然后利用双向GRU进行编码. 对于句子q,
最终句子q表示为 htq=[htq,htq]. 句子p也做相同处理.
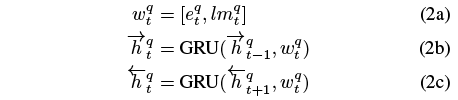
2. Multiway Matching
使用四种注意力方程:

3. Aggregation
这一部分对上一步利用注意力机制提取的匹配信息进行聚合, 分为两步:
1.inside aggregation
这一步对各个注意力方程分别进行聚合.
这里以concate attention为例
增加一个门控结构 gt来衡量当前位置聚合表示的重要性. 再利用双向GRU进行编码得到 htc=[htc,htc].
其他三种attention也都执行相同操作, 得到 htb,htd,htm.
2.mixed aggregation
这一步对所有注意力方程进行聚合.
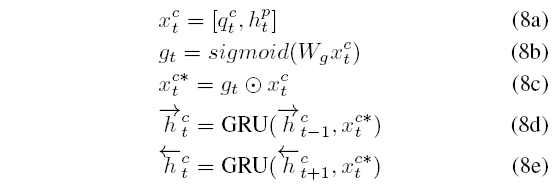
首先, 同样使用注意力机制,
再接双向GRU,
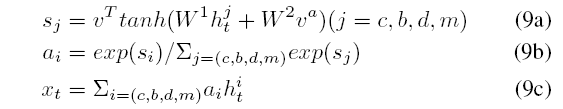
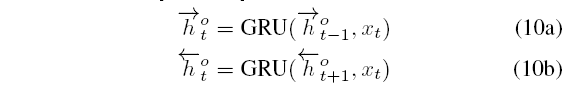
4. Prediction Layer
首先, 对句子Q做attention pooling,
之后, 利用Aggregation层得到的 ho:
最后, 将 rp输入到多层感知机分类器输出最终的分类结果.
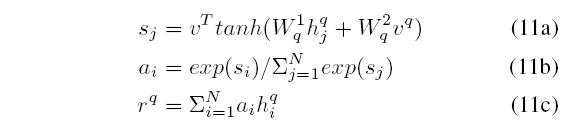
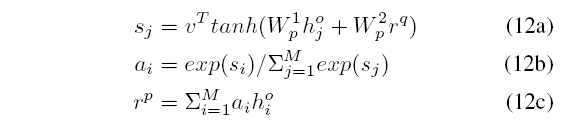
5. 实现细节
- word embedding: 300-dimensional GloVe(freeze)
- OOV: 用zero vector表示
- Hidden vector length: 150
- dropout: 0.2
- optimizer: AdaDelta
- initial learning rate: 1.0
实验
Datasets
- Quora Question Pairs
- SNLI
- MultiNLI
- SQuAD
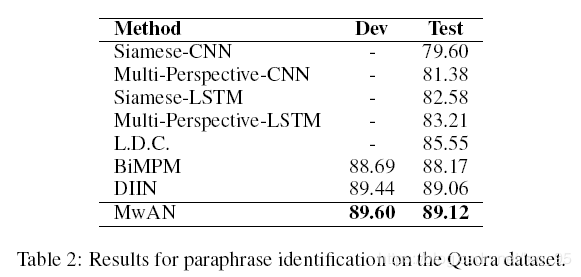
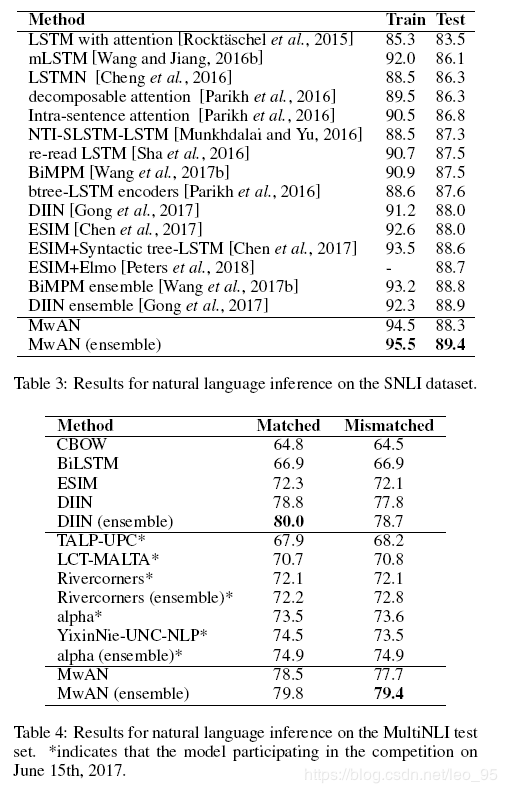
实验结果
 查看28道真题和解析
查看28道真题和解析