Character-level Convolutional Networks for Text Classification阅读笔记
概述
一篇比较经典的文本分类论文, 利用char-CNN结构提取特征, 而没有使用目前非常流行的词向量.
作者通过实验证明, 在数据量足够的情况下, 深层CNN网络不需要词语信息, 仅依赖字符信息就可以获得不错效果.
只利用字符信息可以有效解决拼写错误和表情符号等问题.
模型
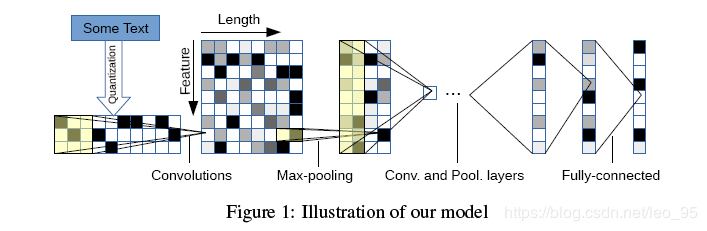
Key Modules
主要模块是一维卷积模块.
定义离散输入函数 g(x)∈[1,l]→R, 离散核函数 f(x)∈[1,k]→R,
则步长为d的卷积操作
:
之后, 进行一维的max-pooling
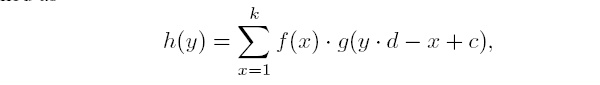
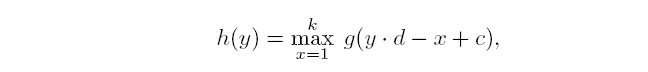
字符表
模型接受一系列编码字符作为输入,通过为输入语言规定大小为m的字符表来完成编码,然后使用1-m编码(或“one-hot”编码)量化每个字符。然后,将字符序列变换为具有固定长度 l0的这种m大小的向量的序列。
字符表一共包含以下70个字符, 其中26个英文小写字母, 10个数字还有其他一些常见标点符号.
可以发现, 作者使用的字符表并没有区分大小写, 这个是作者通过实验后做出的选择, 作者发现区分大小写后, 实验结果往往会变差.

模型设计
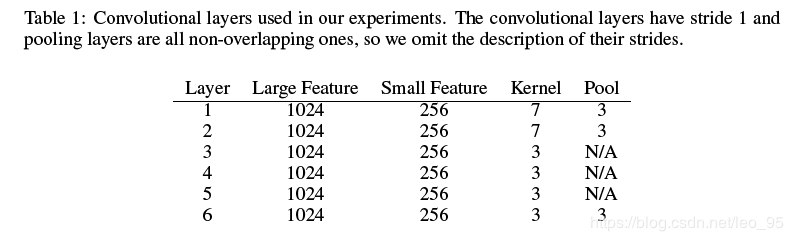
作者提出了大小两个卷积网络. 它们都有9层(6层卷积层, 3层全连接层).
输入的每个字符被表示为70维的one-hot向量. 每个输入的长度对于大模型设置为1014(也就是固定包含1014个字符, 截长补短), 小模型是256. 在三层全连接之间, 均使用dropout防止过拟合
参数利用高斯分布初始化, 其中大模型参数服从(0, 0.02)的高斯分布, 小模型服从(0, 0.05)的高斯分布.
数据增强
为了提高模型效果, 作者还采用了数据增强策略.
NLP的数据增强和CV及语音还是不太一样的. CV现在数据增强方法很多, 而且比较成熟, 比如对图像进行裁剪, 旋转等. 但是NLP数据增强相比较就复杂很多, 因为词与词之间往往存在依赖关系, 改变词序, 语义很容易就发生改变. 所以最好的数据增强方法便是人工转述改写, 但是这样工作量太庞大了.
作者使用英文近义词词典进行数据增强, 找一些同义词或短语, 随机选择数据中部分词进行替代.
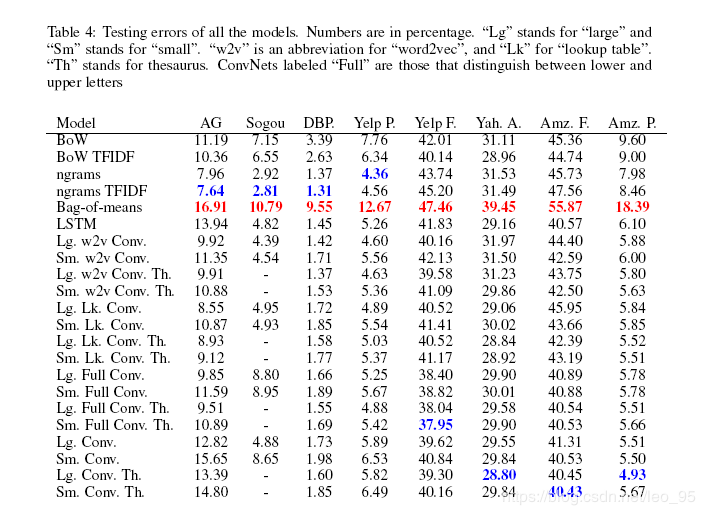
实验
参数设置
- optimizer: SGD with momentum 0.9
- lr: 初始化0.01, 之后每三个batch减半
- batch size: 128
- dropout: 0.5
比较模型
作者分别于传统方法和深度模型进行比较
传统方法
手动提取特征, 构建线性分类器.
- Bag-of-words & TF-IDF
- Bag-of-ngrams & TF-IDF
- Bag-of-means & TF-IDF
深度模型
- Word-based Convnet
- LSTM