
AutoInt:使用Multi-head Self-Attention进行自动特征学习的CTR模型
本文首发于知乎专栏 https://zhuanlan.zhihu.com/p/53462648
简介
这篇论文提出使用multi-head self attention(类似Transformer里的那个) 机制来进行自动特征交叉学习以提升CTR预测任务的精度。
废话不多说,先看下主要结构。典型的四段式深度学习CTR模型结构:输入,嵌入,特征提取,输出。这里我们重点看下嵌入和特征提取部分
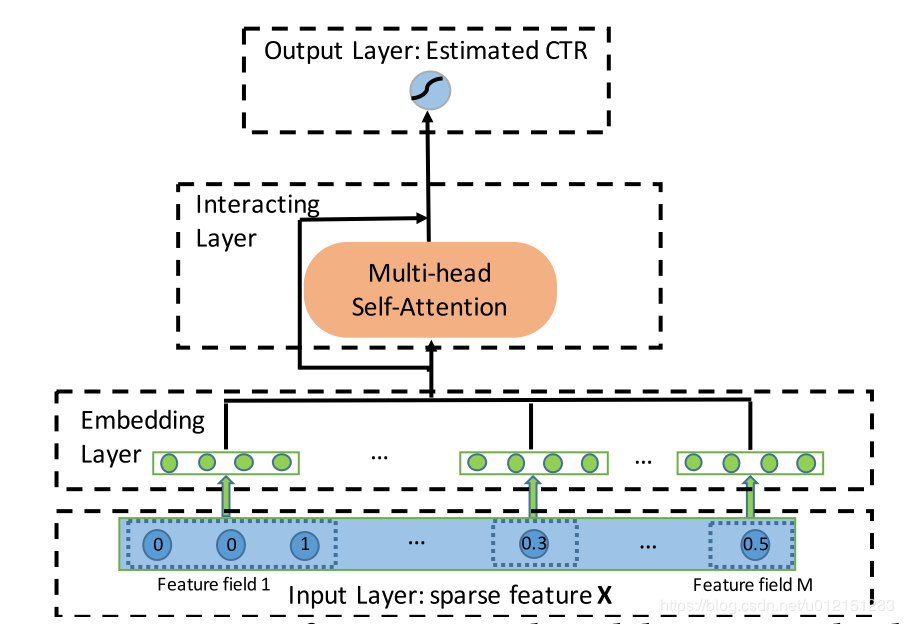
核心结构
输入和嵌入
针对类别特征,通过embedding方式转换为低维稠密向量
ei=Vixi
其中, Vi是特征组 i对应的嵌入字典(嵌入矩阵), xi是特征组特征的独热编码表示向量(通常处于节省空间的考虑,只存储非零特征对应的索引)
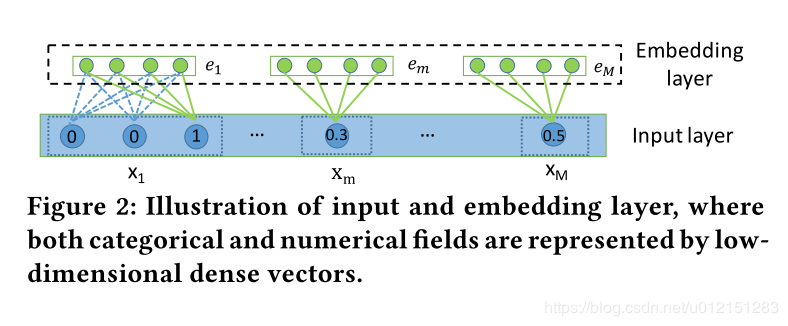
对于连续特征有,
em=vmxm
其中 vm是嵌入向量, xm是一个标量值
通常在CTR任务中我们对连续值特征对处理方式有三种:
- 进行归一化处理拼接到embedding向量侧
- 进行离散化处理作为类别特征
- 赋予其一个embedding向量,每次用特征值与embedding向量的乘积作为其最终表示
本文采取的是第三种方式,具体这三种方式孰优孰劣,要在具体场景具体任务下大家自己去验证了~
从实现的角度看第三种是比较便捷的。
InteractingLayer(交互层)
交互层使用多头注意力机制将特征投射到多个子空间中,在不同的子空间中可以捕获不同的特征交互模式。通过交互层的堆叠,可以捕获更高阶的交互模式。
下面展示在特定子空间 h下,对于特征组 m下的特征 em,交互层是如何计算与其相关的交互特征 e~m(h)的
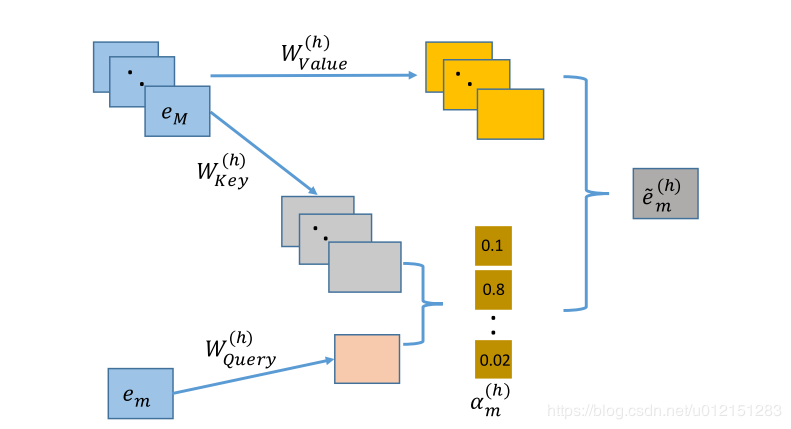
-
首先输入特征通过矩阵乘法线性变换为在注意力空间下的向量表示,对于每个特征 em在特定的注意力空间 h中,都有三个表示向量 Emh:Query=WQuery(h)em, Emh:Key=WKey(h)em, Emh:Value=WValue(h)em
-
计算 em与其他特征 ek的相似度,本文使用向量内积表示:
ϕ(h)(em,ek)=<Emh:Query,Ekh:Key> -
计算softmax归一化注意力分布: am,k(h)=∑l=1Mexp(ϕ(h)(em,el))exp(ϕ(h)(em,ek))
-
通过加权求和的方式得到特征m及其相关的特征组成的一个新特征 e~m(h)=∑k=1Mam,k(h)Emh:Value
假设有 H个注意力空间,对每个注意力空间下的结果进行拼接,得到特征 m最终的结果表示
:
e~m=e~m(1)⊕e~m(2)⊕⋯⊕e~m(H)
我们可以选择使用残差网络保留一些原始特征的信息留给下一层继续学习
emRes=ReLU(e~m+WResem)
最后,将每个特征的结果拼接,计算最终的输出值
y^=σ(wT(e1Res⊕e2Res…eMRes)+b)
我不想看数学,我想看代码:OK
下面就是核心代码啦,可以看到其实很短。
我们使用tensorflow进行实现的时候,可以充分利用矩阵运算的特性来简化实现。
先说明一些定义,att_embedding_size为注意力空间下隐向量的长度,head_num为注意力空间的个数,use_res为一个布尔变量,表示是否使用残差连接。
首先假设输入inputs的shape为(batch_size,field_size,embedding_size),四个投影矩阵(W_Query,W_Key,W_Value,W_Res)的shape均为(embedding_size, att_embedding_size * head_num)
- 通过矩阵乘法得到注意力空间下的三组向量表示
querys = tf.tensordot(inputs, self.W_Query, axes=(-1, 0)) # (batch_size,field_size,att_embedding_size*head_num)
keys = tf.tensordot(inputs, self.W_key, axes=(-1, 0))
values = tf.tensordot(inputs, self.W_Value, axes=(-1, 0))
- 为了同时在不同的子空间下计算特征相似度,需要先进行一些变换
querys = tf.stack(tf.split(querys, self.head_num, axis=2)) # (head_num,batch_size,field_size,att_embedding_size)
keys = tf.stack(tf.split(keys, self.head_num, axis=2))
values = tf.stack(tf.split(values, self.head_num, axis=2))
- 计算相似度及归一化注意力分布
inner_product = tf.matmul(querys, keys, transpose_b=True) # (head_num,batch_size,field_size,field_size)
self.normalized_att_scores = tf.nn.softmax(inner_product)
- 计算加权和
result = tf.matmul(self.normalized_att_scores, values) # (head_num,batch_size,field_size,att_embedding_size)
- 将不同子空间下的结果进行拼接
result = tf.concat(tf.split(result, self.head_num, ), axis=-1)
result = tf.squeeze(result, axis=0)# (batch_size,field_size,att_embedding_size*head_num)
- 使用残差连接保留原始信息,
if use_res:
result += tf.tensordot(inputs, self.w_res, axes=(-1, 0))
result = tf.nn.relu(result)# (batch_size,field_size,att_embedding_size*head_num)
我不想看代码,我想直接拿来用:没问题
首先确保你的python版本>=3.4,然后pip install deepctr,
再去下载一下demo数据
然后直接运行下面的代码吧!
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import AutoInt
from deepctr.inputs import SparseFeat, DenseFeat,get_fixlen_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.count #unique features for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, data[feat].nunique())
for feat in sparse_features] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
fixlen_feature_names = get_fixlen_feature_names(linear_feature_columns + dnn_feature_columns)
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2)
train_model_input = [train[name] for name in fixlen_feature_names]
test_model_input = [test[name] for name in fixlen_feature_names]
# 4.Define Model,train,predict and evaluate
model = AutoInt( dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
deepctr是个什么玩意??
请移步~
参考资料
- AutoInt:Automatic Feature Interaction Learning via Self-Attentive Neural Networks(本文贴图来自于该论文)
- Attention Is All You Need
想要了解更多关于推荐系统,点击率预测算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!
. . . . . . .

