
SSD算法学习及PyTorch代码分析[2]---Prior Box分析
上一篇讲了SSD算法的整体框架,这一篇分析SSD的 Prior Box 层,先验框是如何产生
SSD和YOLO不同,每一个 feature map 上的点都为一个 cell, 而YOLO是划分为 gird 。
假如 feature map 大小为 m×n 那麽会有 m×n 个 cell 。每个 cell 会生成固定 scale 和 aspect ratio 的 box 。
假如每个 cell 生成 k 个 box , 每个 box 对应类 c 个类别以及 4 个坐标偏移量。因此输出的先验框就有 m×n×k×(c+4) 个
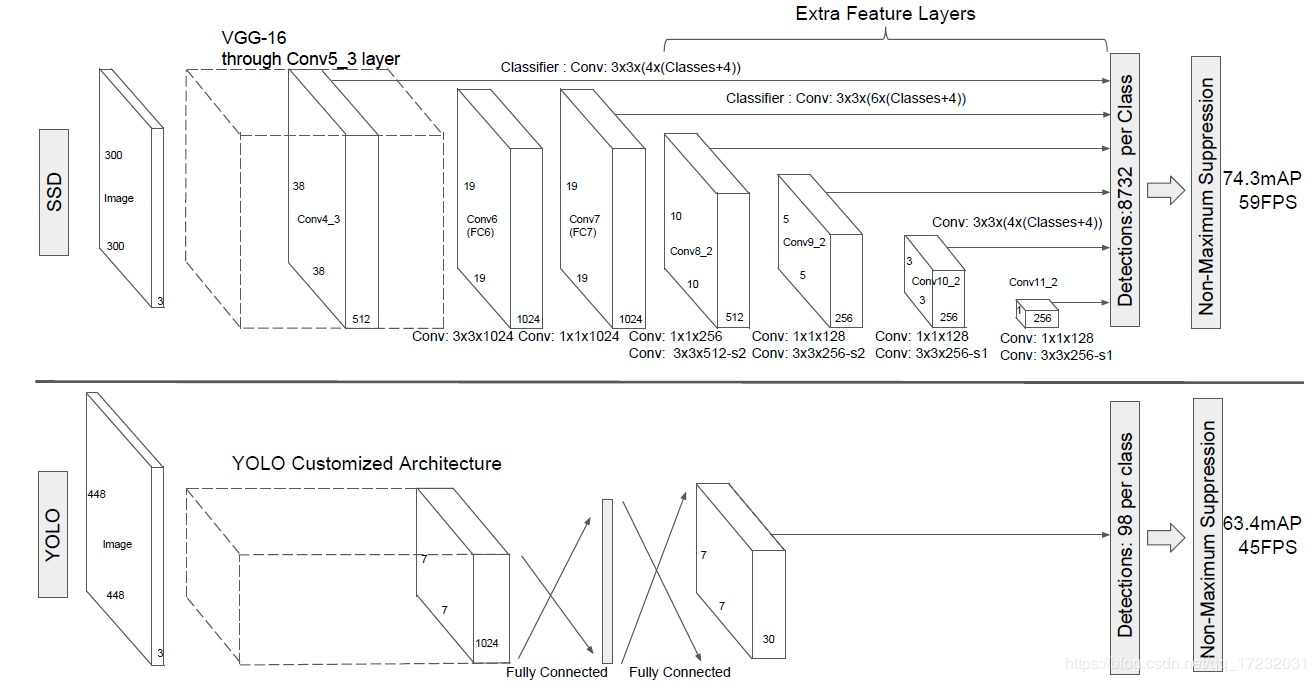
因此这里有着三个超参数(scale, aspect ratio以及 k)。
1. Scale设置
scale 有着一个线性增长的规则:
sk=smin+m−1smax−smin×(k−1)
其中, k∈[1,m] 。 sk 为先验框相对于原始图片的比例 m 为特征图个数,通过网络结构图知道有6个特征图,但是这里 m取 5,因为conv4的特征图单独设置。 smax,smin为比例最大值和最小值,论文中取得是0.9 和 0.2 。
第一个特征图单独设置:
sk=2smin
所以第一个的尺度为300×(0.2)/2 = 30 。
后面的5个特征图按照线性增长规则来。但实际操作我们先将尺度比例扩大100倍来计算,在后面再除以100还原回去。因此增长步长为
⌊m−1⌊smax×100⌋−⌊smin×100⌋⌋=17
所以第二个特征图的 sk为:
1000.2×100+17×(1−1)=0.2
依次类推,最终得到6个特征图的 sk 为[0.1, 0.2, 0.37, 0.54, 0.71, 0.88]
所以乘以图片大小得到特征图尺度为[30, 60, 111, 162, 213, 264]
2. Aspect Ratio设置
aspect ratio设置较为简单,一般取 α={1,2,3,21,31} 所以先验框的宽度和长度为:
wkα=Sα,hkα=S/α
S 为特征图尺度,其中还会设立一个特征图尺度为 S=300×sksk+1, aspect ratio为1的先验框,总共组建6种先验框 {1,2,3,21,31,1′}, 多出来的那个尺度比例 sm+1设为 100105, 那麽多出来的尺度为315 。
实际程序中,conv4_3, conv10_2, conv11_2只使用4种先验框,不使用3和1/3的先验框,所以6个特征图先验框种数有 {4,6,6,6,4,4} 所以总共的先验框有
38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
通过PyTorch代码可以看到在VOC数据集下也是这种设置方式:
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264], #特征图尺度
'max_sizes': [60, 111, 162, 213, 264, 315], #多出一个315尺度
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]], # aspect ratio
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
 查看6道真题和解析
查看6道真题和解析