深度学习优化算法
参考资料
1梯度下降算法的三个变种
根据计算一次梯度更新所使用的数据量大小,梯度下降算法共分为三种:
- Batch gradient descent;(整个数据集)
- Stochastic gradient descent;(一个数据样本)
- Mini-batch gradient descent;(几个样本)
Batch gradient descent
Batch gradient descent的梯度更新公式为:
θ=θ−η⋅∇θJ(θ)
(打公式我有一个独特的窍门,嘻嘻)
式中 θ要更新的参数, η为学习率, ∇θJ(θ)是在整个数据集上损失的梯度。
优点:
- 能保证模型最后收敛于全局最小点(若损失为凸)或局部最小点(损失函数非凸)
缺点:
- 每更新一次参数需要计算出整个数据集每一个样本的推断结果并计算损失,计算量大,内存占用大
- 权重更新缓慢
- 无法在线学习
Stochastic gradient descent(SGD)
Stochastic gradient descent每次计算损失的梯度时,仅使用一个样本,公式如下:
θ=θ−η⋅∇θJ(θ;x(i);y(i))
优点:
- 考虑一种计算情况,假设数据集中每个样本都一样,Batch gradient decent用所有的数据样本来计算损失,存在严重的计算冗余,其实只要计算一个样本即可。尽管这种极端的情况不会出现,但在同一个数据集中,数据必然存在相似性,SGD相比于Batch gradient decent能减少很多计算冗余。
- 研究表明,当学习率较小时,SGD和BGD有相同的收敛点
- 在线学习
缺点:
- SGD由于其频繁的权重更新,会导致损失在下降过程中出现较大的波动。但是波动可能使损失函数跳出局部最小值,进入一个小的收敛点。
Mini-batch gradient descent
Mini-batch gradient descent则是使用数据集中的几个样本计算损失的梯度。计算公式如下:
θ=θ−η⋅∇θJ(θ;x(i:i+n);y(i:i+n))
优点:
- 减小了权重更新的方差,使得损失收敛于一个更稳定的点
- mini-batch的使用使得我们最大化利用GPU的并行计算能力
2 梯度下降算法的痛点
- 学习率大小选择困难。太小导致训练缓慢,太大则容易导致难以收敛,在(局部)最小点附近波动
- 算法中所有的参数都使用相同的学习率进行更新,但实际上对于不同的参数,可能有不同的更新需求
- 在高维的损失优化中,很难收敛到每一维数据梯度都接近于0的点,相反,很容易收敛于鞍点或局部最小点
3 各种梯度下降算法
Momentum
权重更新公式:
vtθ=γvt−1+η∇θJ(θ)=θ−vt
记进行第 t次权重更新时,梯度大小为 gt(为了方便表达),则上式变为:
vt=γvt−1+ηgt=ηgt+γ(ηgt−1+γvt−2)=ηgt+γηgt−1+γ2vt−2...=ηgt+γηgt−1+γ2ηgt−2+...+γt−1ηg1
从式中可以知道,权重更新不仅和本次计算出来损失函数的梯度有关,还和之前计算出来每一次的梯度大小有点,距离越近,贡献越大,距离越远,贡献越小( γ<1)。当 γ=0时则退化成普通的SGD。
那么,把以往的权重更新考虑进去有什么用呢???
- 若在某个维度多次权重更新方向一致,则会加速该权重的更新
- 若在某个维度权重更新方向一直发生变化,即梯度出现正负交替,多个梯度求和的结果则会减小该方向权重的变化。
但是,Momentum法存在一个缺陷。当某一维度的梯度经过多次同样的方向的权重更新后,达到了最小值。尽管在最小值处的的梯度 gt=0,但是!由于累计梯度的原因, vt−1并不为0,因此权重会铁憨憨地继续更新,但却是往损失变大的方向更新。
因此,需要给权重的更新提供一点感知下一位置的能力。请看下一个方法!
Nesterov accelerated gradient
权重更新公式
vt=γvt−1+η∇θJ(θ−γvt−1)θ=θ−vt
对比Momentum法,二者在权重更新时,都由两项组成:
- 累计动量项: γvt−1
- 损失梯度项:
η∇θJ(θ−γvt−1)(Nesterov);
η∇θJ(θ)(Momentum)
二者的区别在于损失梯度项。对于Momentum,是当前位置的梯度损失;对于Nesterov是下一近似位置的梯度损失,正是该项,赋予了该优化方法感知下一刻的能力。
考虑以下这个场景:某一维度的权重经过多次的更新后,累计动量项已相对较大,且接近了最小点,权重再次更新后会导致损失反而变大。看看二者的表现:
- Momentum:计算当前位置损失的梯度(仍与之前的梯度相同),结合累计动量项,更新权重,最终导致损失反而变大
- Nesterov:计算下一位置的近似梯度(过了最小点之后,此时的梯度与之前相反),结合累计动量项,更新权重。由于损失梯度项变为相反值,一定程度上减少了权重更新的幅度,缓和甚至避免了损失的回升!
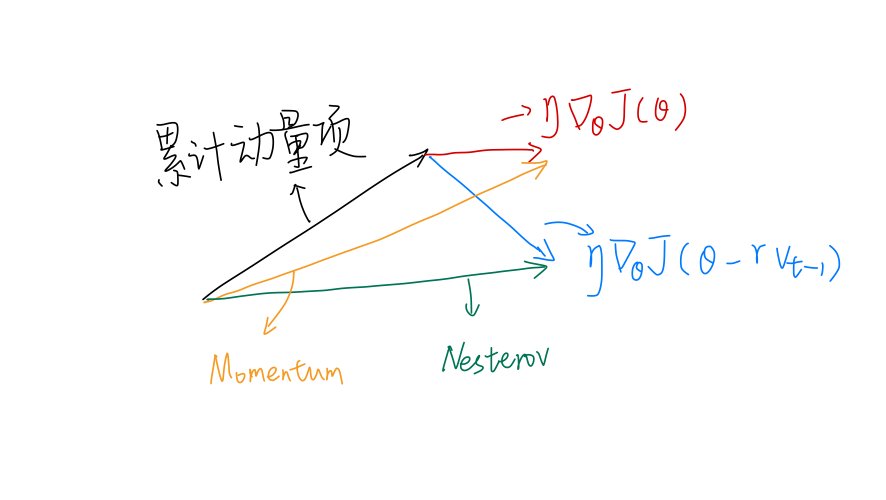
考虑一个二维权重的更新,水平方向和垂直方向,假设垂直方向的权重已接近最优值,也即权重再增大会导致损失不减反增。
Momentum的损失梯度项(红色)垂直方向的分量接近0,但累计动量项仍有很大的垂直分量,两个分量合成后(黄色),垂直方向的权重仍进行了很大的权重更新。
Nesterov的损失梯度项是下一位置的近似梯度,由于下一位置梯度和当前相反,因此垂直分量向下。两个分量合成后,垂直方向的分量抵消了一部分,最终垂直方向的权重更新不大。
Adagrad
权重更新公式:
θt+1,i=θt,i−Gt,ii+ϵ η⋅gt,i
式中:
- θt+1,i是 t+1时刻 i方向的权重;
- Gt,ii是对角阵 Gt对角上第 i个元素,该元素大小为 θi以往每一次梯度的平方和;
- ϵ=10−8,避免除0
Adagrad方法旨在对不同参数,在不同时刻使用不同的学习率。
对于频繁发生更新(梯度不为0)的权重,其学习率会被调整得较小;而对于更新不频繁的权重,其学习率则会被调整得较大。
但随着训练的进行,梯度的平方和越来越大,导致最终学习率被调整得很小,导致训练收敛困难。
Adadelta
Adadelta旨在处理Adagrad学习速率单调递减的情况。不是使用所有梯度的平方和,而是使用梯度平方的调和均值(与常规均值不一样),定义如下:
E[g2]t=γE[g2]t−1+(1−γ)gt2
相应地,权重变化值变成
Δθt=−E[g2]t+ϵ ηgt
将分母用均方根(RME,先平方、取平均、再求平方根)表示(此处并不是严格的平方根,因为所取的平均是经过调和的):
Δθt=−RMS[g]tηgt
与以往不同,此处是对参数的平方进行更新:
E[Δθ2]t=γE[Δθ2]t−1+(1−γ)Δθt2
同样可以的到参数更新的均方根:
RMS[Δθ]t=E[Δθ2]t+ϵ
参数更新的均方根反应了以往参数更新的幅度大小,可用来代替学习率,于是,权重更新规则变为:
Δθt=−RMS[g]tRMS[Δθ]t−1gtθt+1=θt+Δθt
无需设置学习率
RMSprop
RMSprop同样是为了解决Adagrad学习率单调递减的情况。和Adadelta初始想法一致,采用权重梯度平方和的均值来调整学习率。更新规则如下:
E[g2]t=0.9E[g2]t−1+0.1gt2θt+1=θt−E[g2]t+ϵ ηgt
Adam
Adam同样是一个调整学习率的优化方法。除了记录梯度的历史平方和,还记录了梯度的指数平均值:
mtvt=β1mt−1+(1−β1)gt=β2vt−1+(1−β2)gt2
将式子展开:
mt=β1mt−1+(1−β1)gt=(1−β1)gt+β1((1−β1)gt−1+β1mt−2)=(1−β1)gt+(1−β1)β1gt−1+β12mt−2...=(1−β1)(gt+β1gt−1+β12gt−2+...+β1t−1g1)
vt同理,都是在指数平均的基础上,再乘以一个缩减的系数。
通过计算偏差校正的一阶矩和二阶矩估计来抵消偏差:
m^tv^t=1−β1tmt=1−β2tvt
于是权重的更新公式为:
θt+1=θt−v^t +ϵηm^t
一般设置 β1=0.9、β2=0.999、ϵ=10−8
4 如何挑选优化器
对于调整学习率的方法,如Adagrad、Adadelta、RMSprop、Adam等,实验表明Adam的效果好于其他方法。有趣的是,不带动量SGD搭配衰减的学习率经常能找到更小值,但会耗费更多的时间,并且也容易陷于鞍点。
