
深度学习归一化方法[二] Normalization方法对比
论文: https://arxiv.org/pdf/1803.08494.pdf
Normalization 方法对比
1 BN方法的不足之处
BN的不足根源在于测试时使用的两个在训练阶段时维护的参数,均值 μB和修正的方差 σB.
- 当训练集和测试集的数据分布不一致的时候,训练集和测试集的均值和方差存在较大差异,最终影响模型预测精度;
- 即使训练集和测试集的数据分布相对一致,但当batch-size较小时,计算出来的均值和方差所具有的统计意义不强,同样会在预测的时候影响模型准确度.
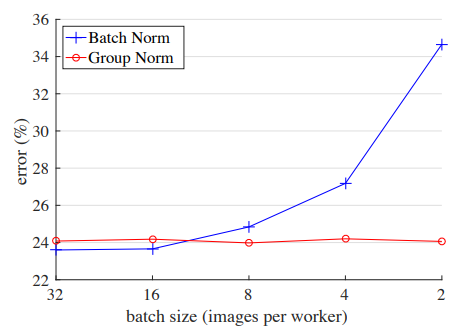
- 一般BN合适的batch-size是32,但对于图像分割,目标检测这些任务对于显存要求大,机器无法满足大batch-size的要求,往往只能设置为1-2.而随着batch-size不断变小,误差越来越大.如下图.
2 独立于batch 的归一化方法
独立于batch进行归一化的方法有 Layer Normalization, Instance Normalization 和 Group Normalization.对比BN,结合一下几张图说明每一种Normalization的归一化方法.
考虑一个Batch=3, channels number=6, H, W 的tensor.绿色表示归一化的范围.
灵魂画手 ↓↓↓↓
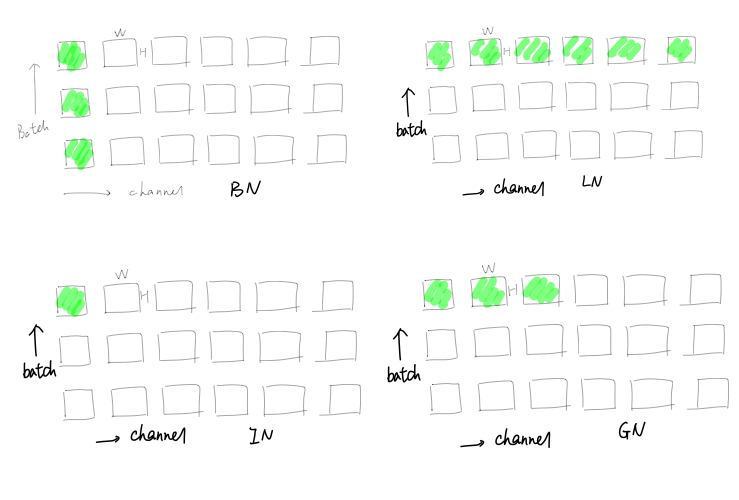
- BN:在batch,H,W的维度进行归一化,即同一个Channel的feature maps进行归一化.共操作了6(channel number)次归一化;
- LN:在Channel, H, W的维度进行归一化,即对mini-batch内的每一个样本进行归一化.共操作了3(Batch-size)次归一化;
- IN:在H,W维度进行归一化,即对每一个features map进行归一化,共操作了6*3(channels number * batch-size)次归一化
- GN:在一个样本的多个channels内分组,分成多组channels,在各组内进行归一化.图中将channels分成了两组(G=2), 因此归一化操作次数为:2*3(G*Batch-size).
3 Group Normalization
在深度学习没有火起来之前,提取特征通常是使用SIFT,HOG和GIST特征,这些特征有一个共性,都具有按group表示的特性.因此尝试在group内进行归一化.
和LN和IN的联系:
- 当分组数目为1(G=1),GN变成LN;
- 当分组数目为通道数6(G=channels number),GN变成IN
实现:
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: 输入特征,shape:[N, C, H, W]
# gamma, beta: scale 和 offset,shape: [1, C, 1, 1]
# G: GN 的 groups 数
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C//G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep_dims=True)
x = (x -mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
需要注意的是,不同于BN,GN不再需要维护归一化时的均值和方差.
用于仿射变换的 γ和 β不依赖于batch-size,对相同的通道,进行同样的仿射变换.
4 四种方法效果比较
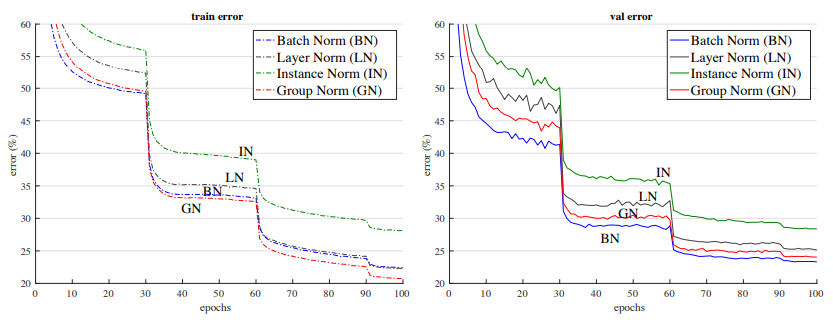
当Batch-size都为32时,BN的效果最好,GN次之:
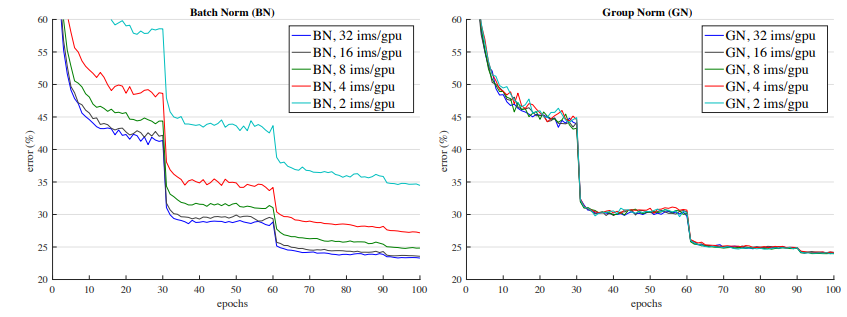
当Batch-zize变小时,GN的稳定性和效果好于BN:
当GN取不同Group,或Group内进行归一化channels数变化时:
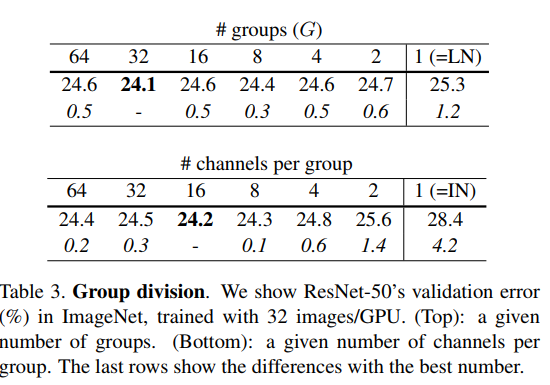
可见,当Group取32,或channels数为16时效果较好,都好于LN和IN.

